







智东西(公众号:zhidxcom)
文 | 英特尔中国研究院
英特尔HERO是一套性能强大、配置灵活、接口丰富的异构计算平台,适合作为服务机器人和小型无人车等智能自主系统的运算核心。集成的英特尔酷睿i5/i7 CPU和,英特尔Arria 10 FPGA芯片,能够实时处理大量数据并运行多种智能算法。对于算法研究者和软件工程师,如何才能充分发挥FPGA的性能,让自己的算法在HERO平台上快到飞起?本文将告诉你答案。
一、为什么要异构计算
完成不同的任务需要采用不同的芯片架构。对于要求高并行、低时延的计算和控制任务,如视觉处理、自主定位、运动规划和控制等,FPGA可以凭借强大的并行计算能力轻松应对。而CPU作为高速的串行处理器,从大吞吐量的例行性计算中解放出来,可专注于高层次的任务规划、决策和人机交互等。二者相辅相成,组成机器人的最强大脑。
事实上,人脑也是类似的工作机制。心理学家认为人脑中有两套系统,一套是完全自动、高度并行的,随时处理大量数据,得到高层次的抽象信息,好比FPGA的功能;另一套系统是你的“意识”,接收这些抽象信息,进行思考,类似CPU。例如人在开车时,识别车道、区分车与行人等任务根本无需占用大脑的思维带宽,老司机甚至能在谈笑间变道超车。这些都得益于强大又灵活的异构大脑。
二、HERO SDK
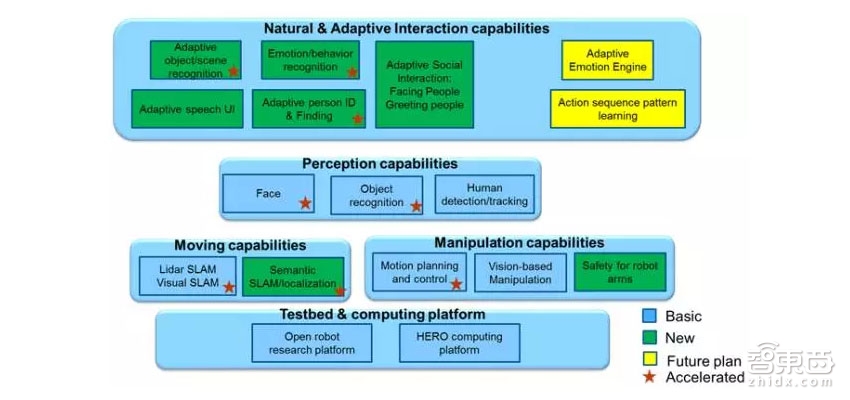
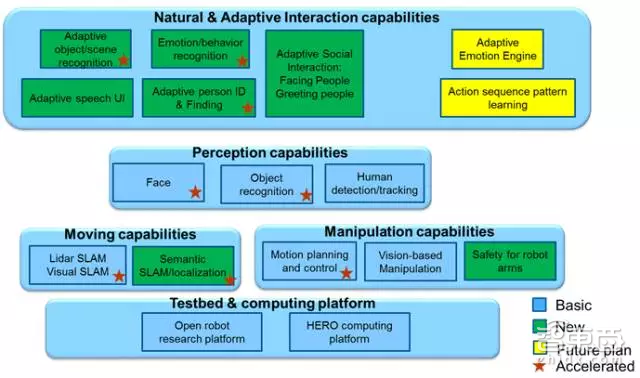
HERO SDK是与HERO平台配套的软件集合,可以帮助开发者快速打造基于HERO平台的机器人产品。HERO SDK目前包含了SLAM、智能导航、视觉重定位、运动规划、人物识别和语音交互等诸多机器人和无人车所需的功能模块。其中,SLAM、运动规划和部分深度神经网络模型已经实现了FPGA加速。整套系统基于ROS(Robot Operation System)构建,灵活便捷。FPGA逻辑设计则采用OpenCL编程模型,直接以C语言进行开发。另外,系统还配备了基于英特尔SGX技术开发的整套安全机制,确保机器人或无人车即便在被黑客远程入侵的情况下也不会做出危险动作。
三、HERO SDK的异构计算案例
下面就为大家介绍几个基于HERO SDK的异构计算案例, 看看我们是如何更好的将运动规划、定位导航应用在智能机器人上:
1、异构计算案例1:利用FPGA加速的机器人运动规划
今年9月底召开的机器人领域顶级会议IROS 2017上,尽管深度学习已成为热门话题,但排名首位的关键词仍是Motion & Path Planning。提到运动规划,目前最常用的是基于采样的算法,典型代表包括RRT、PRM及其变种。这类算法会在机器人的配置空间中随机采样,并将位置接近的有效采样点相连接,构成树状或图状结构,最终在其中找到一条连接起始点和目标点的通路。
采样法普遍面临的问题是无法确保路径的质量——采样越多,越有可能找到更短的路径,但计算所需的时间也越长。实际上,在整个路径规划过程中,绝大多数的时间用于判断采样点的有效性,这是因为有效性判断会涉及机器人自身的碰撞检测(如手和头是否相撞),以及机器人与环境之间的碰撞检测,而无论是机器人本体还是环境,一般都有非常复杂的模型。例如研究中常用的Baxter双臂机器人,仅躯干部分的模型便包含两万个三角形——这还是专为碰撞检测简化过的。而我们开发所用的Jedi双臂机器人,全身的模型包含近五十万个三角形。因此,我们首先将三角网格模型之间的碰撞检测任务选为FPGA加速的目标。
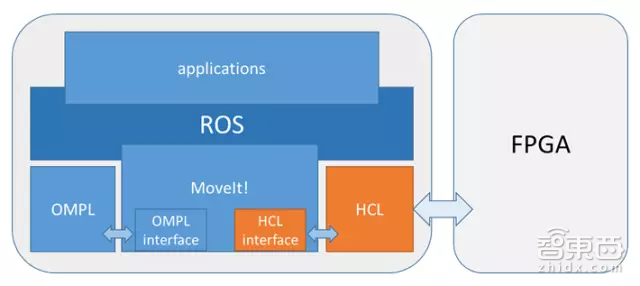
如上图所示,HERO平台采用MoveIt!作为运动规划的框架。OMPL是MoveIt!默认的规划算法库,也是开发基于采样的机器人运动规划算法的首选框架。它在规划过程中会通过虚函数接口调用MoveIt!提供的碰撞检测方法,而实际的碰撞检测则由HCL(HERO Collision Library)执行——这是专为HERO平台开发的具备FPGA加速功能的碰撞检测库,替换了MoveIt!原本使用的碰撞检测库FCL。为了充分发挥FPGA的性能,我们对OMPL和MoveIt!也做了修改,使之能够一次发起多个检测请求,从而减少CPU与FPGA交互的数量。最终针对自碰撞检测请求,HCL的处理速度达到了FCL的近两倍。

2、异构计算案例2:利用FPGA加速的SLAM算法
长期关注英特尔中国研究院的小伙伴们都知道,研究院去年以一款低成本FPGA SoC – Cyclone V为基础完成了整套激光雷达SLAM系统的设计。而如今有了HERO平台加持,开发类似系统会不会变容易?答案是肯定的!
事实上,我们采用OpenCL开发流程重新做了一版FPGA SLAM,全新设计了软硬件交互接口,以C语言重写核心计算逻辑,用emulator进行调试验证,编译为硬件逻辑并在搭载HERO平台的机器人上完成了测试。实现这一切仅需要几天时间!
经测试,新版的FPGA SLAM中通过OpenCL生成的逻辑在性能上超越了由资深硬件工程师以HDL设计的版本,比深度优化的软件版本在英特尔酷睿i5 CPU上的执行速度提高5倍之多。结合我们的FastScan技术,更快的执行速度允许我们以更高频率调用定位算法,最终使得搭载HERO平台的机器人或无人车能以更高的速度稳定行驶。

四、FPGA快速开发经验
前方高能,非战斗人员撤离!
尽管FPGA近年异常火爆,但许多软件工程师仍旧避而远之,毕竟单是复杂的传统开发流程就足以让人望而生畏。
OpenCL的出现改变了这一切。使用OpenCL,可以直接以C语言开发运行在FPGA上的kernel程序,只要一条命令便可将其编译为包含硬件逻辑的aocx文件。而在主机端,只需在C或C++程序中利用OpenCL的接口加载该文件,即可像调用普通函数一样执行FPGA逻辑并获取结果。根据我们的经验,软件工程师只需几周的磨合便可熟练掌握整套开发流程,并且能够根据可视化的硬件逻辑综合报告进行kernel代码的分析和优化。
以下为开发人员可能会关注的问题,有没有你想获取的答案?
Q:使用OpenCL开发FPGA逻辑需要建立怎样的开发环境?
A:在Ubuntu系统上,只需拷贝一份英特尔 FPGA SDK for OpenCL,并在bash中设置合适的环境变量即可,无需GUI,十分便捷。
Q:在没有FPGA硬件的机器上可以执行kernel吗?
A:在编译时设置emulator选项,即可得到软件版本的aocx文件,执行时无需FPGA硬件,非常适合功能验证和调试。
Q:编译kernel是不是要很久?
A:编译emulator的速度很快,与编译软件相当;编译硬件逻辑的时间取决于kernel的复杂度,一般需要一小时到数小时不等,但第一阶段编译完成后(通常只需要一分钟)便可得到高层次综合报告和FPGA资源使用率。
Q:如何调试kernel代码?
A:建议用emulator调试功能。编译emulator时,kernel代码中可以正常使用printf,并可以用gdb进行调试。
Q:C语言的所有特性都可以在kernel中使用吗?
A:基本都可以,全局变量和静态变量不能直接使用,但可以用OpenCL和英特尔提供的关键字指定变量的地址空间达到类似效果。
Q:调用kernel与调用普通函数有何区别?
A:首先,不能直接传递指针作为参数,需要先用OpenCL提供的接口将要访问的数据拷贝至FPGA的内存中(也可以反向拷贝),再传递相应的地址。其次,所有参数的总字节数存在限制。
Q:用OpenCL开发出的程序性能如何?
A:取决于程序的类型。对于一般的计算密集型任务,以OpenCL开发的逻辑,其性能可以轻易匹敌由经验丰富的硬件工程师用HDL设计的逻辑;而对于需要频繁访存的任务,OpenCL未必能自动提供最佳的内存管理方式,需要开发人员根据任务特点仔细调整代码。

