








智东西(公众号:zhidxcom)
编 | CJ
导语:这篇文章介绍了谷歌大脑团队去年一年所取得的人工智能方面的成就,这是第一部分,重点介绍2017年谷歌所做的一些工作,包括一些基础研究工作,以及开源软件,数据集和机器学习新硬件的更新。
谷歌大脑负责人Jeff Dean今天发文晒出了自动机器学习、语义理解和语言生成、机器学习算法、机器学习系统等核心研究工作成绩单,全面总结谷歌大脑在2017年取得的成绩。
核心重点在于做提高我们理解力还有解决机器学习领域新问题的能力。以下是去年我们研究的几个主题。
1、自动机器学习(AutoML)
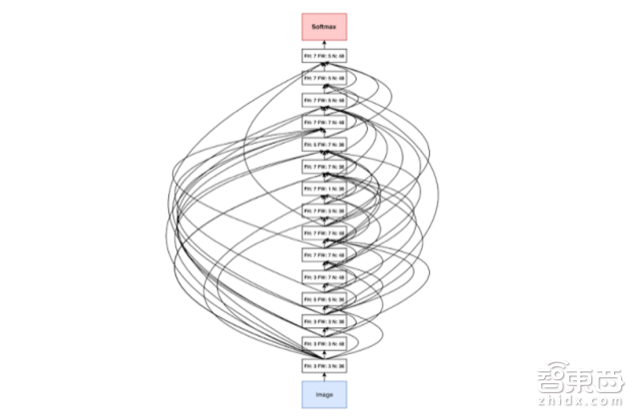
自动机器学习的目标是开发一种技术,使计算机能自主解决新出现的机器学习问题,而在这个过程中,不需要人类机器学习专家来干预每个新问题的解决。如果我们最终能建立真正智能的系统,那么这是我们需要的最基本的功能。 我们结合强化学习和进化算法开发了设计神经网络架构的新方法,这种方法经过ImageNet( 计算机视觉系统识别项目, 是目前世界上图像识别最大的数据库)的分类和检测,结果显示是目前最先进的方法。我们也展示了如何自动学习新的优化算法和有效的激活函数。我们积极地与谷歌的云人工智能团队(Cloud AI)合作,希望把这种技术带给谷歌的用户,同时也把这项研究往多个方向推进。

2、语义理解和语言生成
谷歌大脑团队开发了新的技术,能改进计算系统的语义理解和语言生成能力。这个过程中,成功减少了谷歌语音识别系统16%的相对词错误率。这项工作的一个很好的方面是,它需要许多独立的研究线索(可以在Arxiv上找到:1,2,3,4,5,6,7,8,9)。
同时谷歌大脑团队也和谷歌机器感知团队一起开发了语音-文本生成的新方法(Tacotron 2),大幅提升了生成的语音的质量。该款模型的平均意见得分(MOS, mean opinion score)达到了4.53,而一份有声读物中的专业记录的语音的MOS得分为4.58,同时,目前最好的电脑语音系统的MOS得分为4.34。

3、新的机器学习算法和方法
我们继续开发新颖的机器学习算法和方法,包括胶囊工作(capsules)(在执行视觉任务时明确寻找激活特征中的一致性作为评估许多不同噪声假设的方式),稀疏门控混合专家层( Sparsely-Gated Mixture-of-Experts)(这个方式能使得非常大的模型仍然具有高计算效率),超网络(hypernetworks)(使用一个模型的权重来生成另一个模型的权重),新型的多模式模型(new kinds of multi-modal models)(在同一个的模型中,可以执行跨音频,视觉和文本输入多任务学习 ),注意力机制(attention-based mechanisms)(作为卷积(convolutional models)和递归模型( recurrent models)的替代),符号和非符号学习优化方法,一种通过离散变量向后传播的技术,以及一些新的强化学习算法改进。
4、计算机系统的机器学习
我们对在计算机系统中使用机器学习取代传统启发法(heuristics)有很大兴趣。我们已经展示了如何使用强化学习来做计算图映射到一组计算设备上的布置决策,机器的结果要优于人类专家。在“学习索引结构的案例The Case for Learned Index Structures ”中,展示了神经网络,神经网络比传统数据结构(如b树,哈希表,布隆过滤器)要更快、更小。

5、隐私和安全
机器学习及其与安全和隐私的交互仍然是我们的主要研究重点。我们展示了机器学习技术可以以一种提供不同隐私保证的方式应用,在一篇获得ICLR 2017最佳论文奖的论文中。我们还继续调查了对抗性实例的性质,其中包括物理世界里的对抗性实例,以及如何在训练过程中大规模利用敌对实例,从而使模型在敌对实例面前更强大。
6、了解机器学习系统
虽然我们在深入的学习中看到了令人印象深刻的成果,但重要的是理解它为什么起作用,什么时候不起作用。在ICLR 2017最佳论文奖中,我们发现目前的机器学习理论框架无法解释深度学习方法现在取得的重大成果。同时,我们还发现最优化方法找到的最小值的“平坦度”并不像最初想象的那样与其良好泛化能力紧密相关。为了更好地理解深层架构下的训练是如何进行的,我们发表了一系列分析随机矩阵的论文,因为随机矩阵是大多数训练方法的起点。了解深度学习的另一个重要途径是更好地衡量他们的表现。在最近的一项研究中,我们展示了良好实验设计和严谨统计的重要性,比较了许多生成对抗网络(GAN,Generative Adversarial Networks)方法,发现许多流行的生成模型的优化处理并没有提高其性能。我们希望这项研究能够为其他研究人员提供一个可靠的实验研究的例子。
我们正在开发可以更好地解释机器学习系统的方法。并于3月份与OpenAI,DeepMind,YC Research等合作,宣布推出Distill,这是一本致力于支持人类理解机器学习的在线开放性科学期刊。它机器学习概念的清晰阐释和出色的交互式可视化工具赢得了一致好评。在第一年,Distill发表了许多眼前一亮的文章,旨在了解各种机器学习技术的内部工作,我们期待2018年更有可能。

7、机器学习研究的开放数据集
像MNIST,CIFAR-10,ImageNet,SVHN和WMT这样的开放数据集,极大地推动了机器学习领域的发展。 作为一个整体,我们的团队和Google Research在过去一年左右一直积极地为开放式机器学习研究开放有趣的新数据集,通过提供更多的大型标记数据集,包括:
YouTube-8M:使用4,716个不同类别注释的700万YouTube视频
YouTube边界框:来自210,000个YouTube视频的500万个边界框
语音指令数据集:成千上万的发言者用简短的命令语
AudioSet:200万个10秒的YouTube剪辑,标有527个不同的声音事件
原子视觉行动(AVA):57,000个视频剪辑中的21万个动作标签
开放图片:9M创意共享授权图片,标有6000个类别
有边界框的开放图像:600个类的1.2M边界框
8、TensorFlow和开源软件
纵观我们团队的历史,我们已经构建了一些工具,帮助我们在Google的许多产品中进行机器学习研究并部署机器学习系统。 2015年11月,我们开放了第二代机器学习框架TensorFlow,希望机器学习社区能够从机器学习软件工具的投资中受益。今年二月份,我们发布了TensorFlow 1.0,在十一月份,我们发布了1.4版本,包括:交互式命令式编程的热切执行,TensorFlow程序的优化编译器XLA和TensorFlow Lite,嵌入式设备。预编译的TensorFlow二进制文件现在已经在180多个国家下载了超过一千万次,GitHub上的源代码现在已经有超过1200个贡献者。
今年2月,我们举办了第一届TensorFlow开发者峰会,450多人参加了Mountain View的活动,在全球35多个国家和地区举办了超过85场的本地观看活动,观看了超过6500人的观看活动。所有的会谈都被记录下来,主题包括新功能,使用TensorFlow的技巧,或者低级TensorFlow抽象的细节。我们将在2018年3月30日在湾区举办另一个TensorFlow开发者峰会。立即注册以保存日期并保持最新消息的更新。
在十一月,TensorFlow庆祝其开放源代码项目两周年。看到一个充满活力的TensorFlow开发人员和用户群体出现,这是非常有益的。 TensorFlow是GitHub上的第一个机器学习平台,也是GitHub上的五大软件库之一,被许多公司和组织所使用,包括GitHub上与TensorFlow相关的超过24,500个不同的软件仓库。现在,许多研究论文都与开放源码的TensorFlow实现一起出版,以配合研究结果,使社区能够更容易地理解所使用的确切方法,并重现或扩展工作。
TensorFlow也受益于其他Google研究团队的开源相关工作,其中包括TensorFlow中的生成对抗模型的轻量级库TF-GAN,TensorFlow Lattice,用于处理晶格模型的一组估计器,以及TensorFlow Object Detection API。 TensorFlow模型库随着越来越多的模型不断发展。
除了TensorFlow,我们还在浏览器中发布了deeplearn.js,一个开源的硬件加速深度学习API实现(无需下载或安装任何东西)。 deeplearn.js主页有许多很好的例子,其中包括您可以使用网络摄像头训练的计算机视觉模型的“教育机器”,以及基于实时神经网络的钢琴演奏和演奏演示“演奏RNN”。我们将在2018年开展工作,以便将TensorFlow模型直接部署到deeplearn.js环境中。
9、TPUs

大约五年前,我们认识到深度学习会大大改变我们所需要的硬件种类。深度学习计算的计算量非常大,但它们有两个特殊的性质:它们主要由密集的线性代数运算(矩阵倍数,向量运算等)组成,它们对精度的降低有非常高的容忍度。我们意识到我们可以利用这两个属性来构建能够非常有效地运行神经网络计算的专用硬件。我们为Google的平台团队提供了设计输入,他们设计并生产了我们的第一代Tensor Processing Unit(TPU):一种旨在加速推理深度学习模型的单芯片ASIC(推理是使用已经过训练的神经网络,与训练不同)。这款第一代TPU已经在我们的数据中心部署了三年,并且已经被用于在每个Google搜索查询,Google翻译,Google相册中的图片,用在了AlphaGo与Lee Sedol还有与柯洁的对弈,还用在了其他许多研究和产品。六月份,我们在ISCA 2017上发表了一篇论文,显示这款第一代TPU比现代GPU或CPU同类产品快15倍–30倍,性能/功耗约为30X – 80X。


推理很重要,但加速训练过程是一个更重要的问题 – 也更难。研究人员可以更快尝试一个新的想法,我们就可以做出更多的突破。我们在5月份的Google I / O上发布的第二代TPU是一个旨在加速训练和推理的整个系统(定制ASIC芯片,电路板和互连),我们展示了单个器件配置以及多层深度学习超级计算机配置称为TPU Pod。我们宣布这些第二代设备将作为云端TPU在Google云端平台上提供。我们还公布了TensorFlow研究云计划(TFRC),该计划旨在为顶级ML研究人员提供方案,他们致力于与世界分享他们的工作,以便免费访问1000个云端TPU的集群。在十二月份,我们展示了一个工作,表明我们可以在22分钟内在TPU Pod上训练一个ResNet-50 ImageNet模型,而在一个典型的工作站上,相比于几天或更长时间,这个模型的准确度要高。我们认为以这种方式缩短研究周转时间将大大提高Google的机器学习团队以及所有使用云端TPU的组织的工作效率。

