








3月23日起,智东西联合NVIDIA推出「实战营」第一季,共计四期。第四期于4月20日晚8点在智东西「高性能计算」系列社群开讲,由清华大学计算机系副教授都志辉、NVIDIA高级系统架构师易成二位讲师先后主讲,主题分别为《GPU加速的实时空间天气预报》和《NVIDIA GPU加速高性能计算》。
随着深度学习技术的发展,尤其是大型深度神经网络的出现,使得很多大型科学应用得以实现,但大型的科学应用程序往往由于其代码量和通信量巨大,对计算力和数据传输性能要求也非常高,NVIDIA凭借先进的GPU技术和完整的软件生态,为大型科学计算提供有力的算力和软件生态环境支持,在物理化学、分子动力学、冷冻电镜、气象、流体仿真等各个主要的HPC领域都都有广泛的应用。
本文为NVIDIA高级系统架构师易成的主讲实录,共计7581字,预计14分钟读完。在浏览主讲正文之前,先了解下本次讲解的提纲:
1,NVIDIA GPU在高性能领域的应用
2,NVIDIA Tesla Volta GPU核心架构和特点
3,NVIDIA DGX系统架构与高性能计算
4,GPU集群运维和作业调度
智东西「实战营」第一季第一期由图玛深维首席科学家陈韵强和NVIDIA高级系统架构师付庆平,分别就《深度学习如何改变医疗影像分析》、《DGX超算平台-驱动人工智能革命》两个主题在智东西旗下「智能医疗」社群进行了系统讲解。第二期由NVIDIA深度学习学院认证讲师侯宇涛主讲,主题为《手把手教你使用开源软件DIGITS实现目标检测》。第三期由西安交通大学人工智能与机器人研究所博士陶小语、NVIDIA高级系统架构师易成二位讲分别就《智能监控场景下的大规模并行化视频分析方法》和《NVIDIA DGX-2 驱动智能监控革命》两个主题在智东西旗下「智能安防」社群进行了系统讲解。
「提醒:如果希望下载每期实战营的完整课件,可以在智东西公众号(zhidxcom)回复关键词“实战营”获取。如果你希望成为讲师,可以回复关键词“讲师”,进行申请」
易成:大家晚上好,我是英伟达的系统架构师易成,前面都老师的介绍非常精彩,下面我给大家分享一下GPU和DGX在高性能计算方面的应用。
今天的分享主要包括以下四个方面:
1,NVIDIA GPU在高性能领域的应用
2,NVIDIA Tesla Volta GPU核心架构和特点
3,NVIDIA DGX系统架构与高性能计算
4,GPU集群运维和作业调度
首先NVIDIA的产品主要运用在三个领域:
1,GPU计算卡,用来做深度学习和高性能计算,属于Tesla系列,是专用的产品;
2,图形显卡,用来做电脑的图形显示和图形渲染等,属于GeForce、Titan系列,是消费级产品;
3,Tagra嵌入式产品,用于智能终端,机器人、自动驾驶等领域。

从2008年开始,NVIDIA开始发布Tesla的计算卡,最早的时候是G80、GT200架构,后来开始发布Fermi架构、Kepler架构、Maxwell架构、Pascal架构和Volta架构,早期的G80和GT200架构,可能大家比较陌生,当时的产品有C870、C1060和C1070。后面Fermi架构的产品有C2050、C2070、M2070和M2090等等;后面的Kepler架构,大家就比较熟悉了,比如K20、K40和K80这些产品;Maxwell架构主要有M10、M40和M60;Pascal架构的产品有P4、P40和P100;Volta架构只有一款产品,那就是V100,现在出了最新的为32GB显存版本。
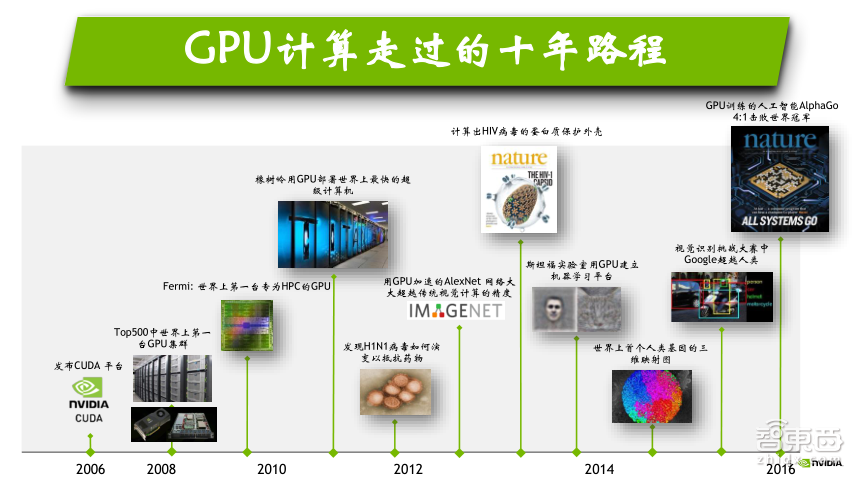
自从NVIDIA 2006年发布CUDA以来,CUDA的发展也是经过了十多年的历程,从早期的HPC计算到现在广泛应用的人工智能计算、深度学习计算,这十年里面GPU的性能从单卡不到1万亿次,发展到现在V100的125万亿次,GPU的性能越来越高,基于CUDA的软件生态环境也越来越完善。

这是目前支持GPU计算的主要应用领域。在物理化学、分子动力学、冷冻电镜、气象、流体仿真等等各个主要的HPC领域都都有广泛的应用。其中,在RELION、GROMACS、LAMMPS、NAMD等分子动力学计算的应用里,GPU计算速度要远远高于CPU的速度,目前这些大规模的计算任务很少在CPU上进行计算。

这15个软件的计算负载占世界各个超算中心负载的70%左右,这些软件现在都可以支持GPU加速计算,比如我们熟悉的ANSYS、AMBER、GROMACS、LAMMPS、NAMD,它们在物理、化学、生物、流体力学、电磁等等计算领域都有非常多的应用,而且GPU加速效果都非常好。

在CFD计算领域,包含结构化和非结构化网格的有限体积算法,非结构化的有限元算法,现在这些算法的代表软件都可以支持GPU计算。
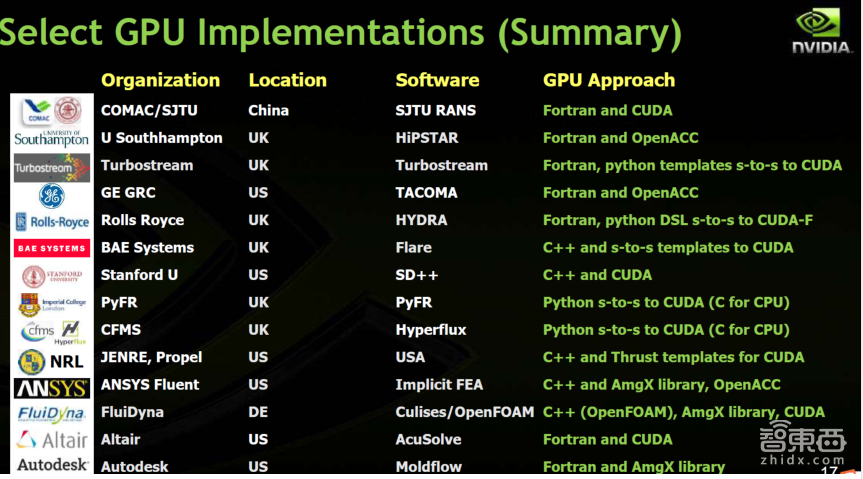
从这个图中我们可以看到,这些CFD软件很多都是使用Fortran或C语言开发,都是基于CUDA或OpenACC的方式进行GPU加速计算。

在做大规模并行计算的时候,如果采用CPU集群,随着并行的核数越来越多,并行计算通信的开销越来越大,并且效率也越来越低。当超过一定的阈值时,随着核数增加,不但没有加速,可能反而会降低计算速度。现在几千核的并行计算已经很常见,并行效率低已经成了普遍现象,成为限制CPU并行计算规模增长的一个瓶颈,而GPU计算单节点计算能力非常强,需要的计算节点数目比较少,所以并行效率会很高,以AMBER为例,一个GPU计算节点四块P100的计算速度超过了48台CPU计算节点的速度。
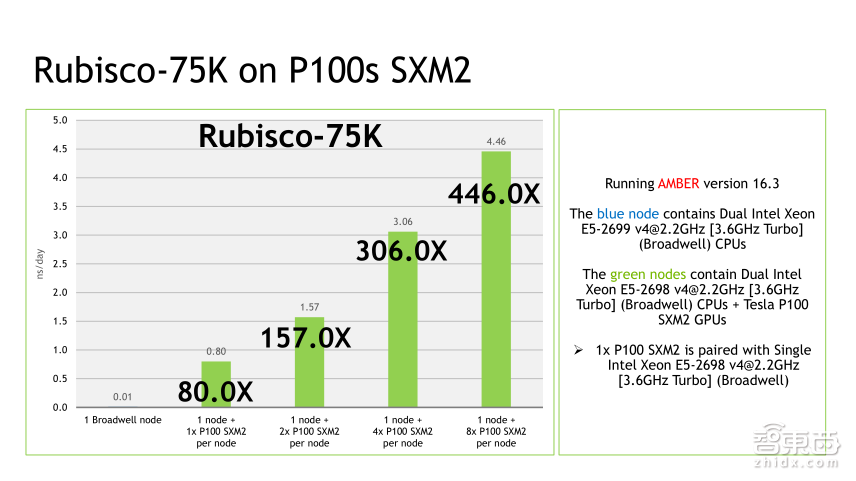
这是AMBER使用不同GPU数量时的性能测试,我们发现AMBER的扩展性非常好,接近线性的加速比,当然,GPU的加速效果和算例的规模和算例的类型也有关系。
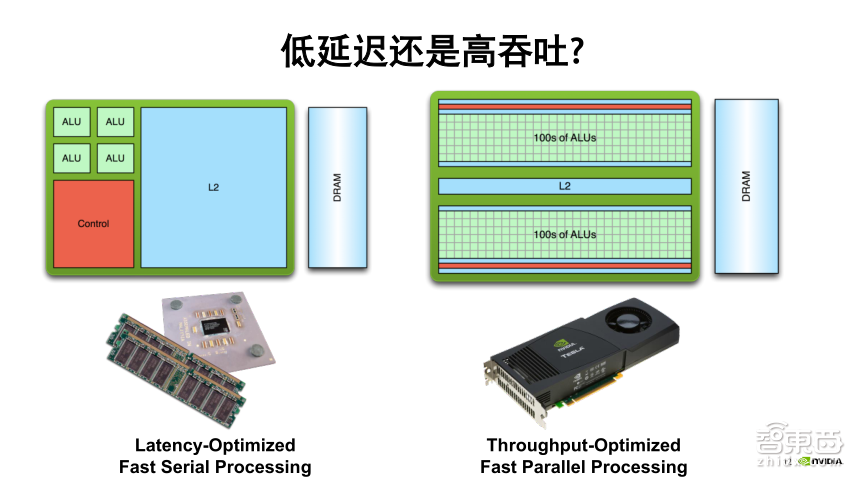
我们来看一下CPU和GPU的架构有什么不同,如上图所示,CPU是一个基于缓存优化的串行处理器,有很大比例的L2缓存,其设计之初就是着眼于降低内存访问的延迟,而GPU则是针对吞吐优化的并行处理器,和CPU比起来它有更多的计算核心,CPU把大量的晶体管集中于缓存和控制部分,而GPU将更多的晶体管集中于计算核心,这样不同的架构造成了CPU更适合做复杂逻辑判断和串行处理,而GPU更适合做大规模的并行计算。

这张图表是GPU加速模型,采用的是CPU+GPU的异构计算架构,CPU作为任务分配的处理器,执行串行类指令,而GPU作为协处理器,执行并行算法的程序指令,在将程序从CPU移植到GPU时,只需要将程序中最耗时而且可以大规模并行的那一部分程序代码加载到GPU中执行,而将其余的串行代码仍然保留在CPU中计算,这样的话就可以在很短的开发周期内得到很高的加速比。
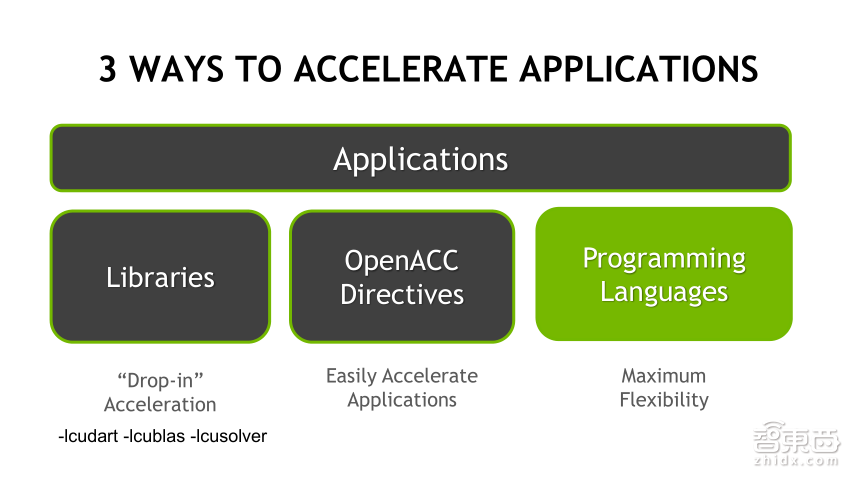
利用GPU加速通常有三种方法:
1,基于CUDA库的调用,通常我们在程序中会调用比如Intel的MKL、FFT等,我们如果使用GPU加速的话,可以使用CUDA中对应的数学库进行替代,比如cuBLAS、cuFFT等,CUDA库是由NVIDIA技术专家经过优化后,类似于GPU加速的函数接口,通常可以达到很高的计算性能和加速比;
2,基于OpenACC导语句的编程,OpenACC类似于OpenMP,如果您之前使用过OpenMP在多核CPU上开发并行程序,那么使用OpenACC编程起来会非常容易,只需要在并行代码前,通常是For循环语句之前加入导语句就可以实现GPU的自动加速;
3,使用CUDA语言编程,在学习使用CUDA语言编程会让并行程序更加灵活,通常可以达到最好的性能效果,前面都老师也介绍了他的开发经验,CUDA编程相对而言,比OpenACC更加复杂些。

现在支持GPU编程的语言非常多,我们可以选择C、C++、Python、Fortran、C#等等这些编程语言。

这里提供了一些GPU编程的学习资料,可以根据你们选择的编程语言进行选择和学习。

这是一个CUDA编程的示例,从左侧我们可以看到是一个二层循环的CPU C代码,右侧是一个基于GPU计算的CUDA C代码,我们可以看到在右侧用__global__关键字声明了函数add_matrix_gpu,叫做内核函数(Kernel函数),它告诉编译器这段代码需要加载在GPU中执行。可以看到从CPU C代码转换到CUDA C代码的过程也不是非常复杂,也不会显着增加代码的量。

这是一个OpenACC的案例,我们可以看到OpenACC相比于CUDA而言就更简单了,它只需要在循环的程序代码之前加入OpenACC的导语句就可以实现并行。
OpenACC具有可移植性强的特点,OpenACC可以支持主流的处理器架构,比如ARM、POWER和Sunway等架构。
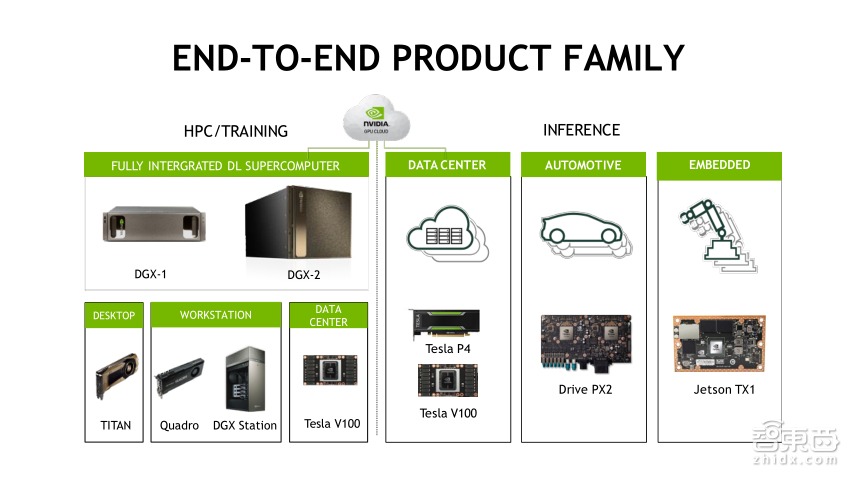
这是NVIDIA的产品线,包含深度集成的软硬体一体机DGX-1、DGX-2和DGX-Station,现在都是配置的V100最新的GPU。除此之外我们还有Titan系列的消费级显卡,Quadro系列的专业级工作站显卡,Tesla系列的V100 GPU,除此之外,还有用于深度学习Inference(推理)的P4处理器,用于自动驾驶的Drive PX2处理器,还有用于智能终端、机器人、无人机的Jetson TX1。

这是一个GPU计算平台的架构:
-底层是硬件层,包含GPU、服务器等;
-软件环境,包括操作系统、驱动、CUDA软件包、cuBLAS、cuFFT、cuDNN等函学库;
-NCCL GPU通讯库;
-应用软件层,包含深度学习软件AMBER、ANSYS等HPC软件;
-具体应用软件层,现在GPU计算的生态环境已经非常成熟,使用也非常方便。

这是NVLink和PCIe两种版本的V100 GPU,上一代的P100也有这两种形式,PCIe的GPU大家会比较熟悉。平时我们见到的Titan和GeForce系列的显卡都是PCIe的接口,NVLink版本的GPU是SXM2接口,直接扣在主板上,这种显卡需要特殊的主板才能支持。
比较下两种GPU的参数,NVLink版本的GPU参数要高于PCIe的GPU,我们看到双精度、单精度和FP16的计算性能都全部高于PCIe的性能,另外NVLink版本GPU的带宽可以达到300GB每秒,而PCIe GPU通过PCIe的总线进行通讯,只有32GB每秒。
在V100的GPU里面,采用的是HBM2 的显存,这种显存带宽达到900GB每秒,也要显著高于普通显卡或GPU的显存带宽。

这是Volta GPU的内部架构,一共有80个流处理器,5120个CUDA核心,640个Tensor Cores,Tensor Core是从V100架构开始新增加的计算核心。

上图展示了GV100核心的流处理器SM的内部架构,一个SM分为四个区,每个区包含8个FP64的核心,16个FP32的核心,16个INT32的核心,另外还有8个Tensor Cores的核心,这些核心占去了很大面积,Tensor Core库是一个混合乘加的处理器核心,可以执行4×4的矩阵混合乘加计算。
可以通过CUDA编程或者调用一些函数库,比如cuDNN、cuBLAS等直接调用Tensor Core进行计算。

前面介绍了Volta V100 GPU,下面我们来看一下DGX 服务器,这是一台DGX-1超级计算机,包含8块NVLink V100 GPU,两颗Intel Xeon处理器,512GB内存,4个100GB InfiniBand EDR网口,8TB SSD本地存储空间,一共有4个1600W电源,系统功耗是3200W,8个NVLink GPU采用立方体的结构的互联。
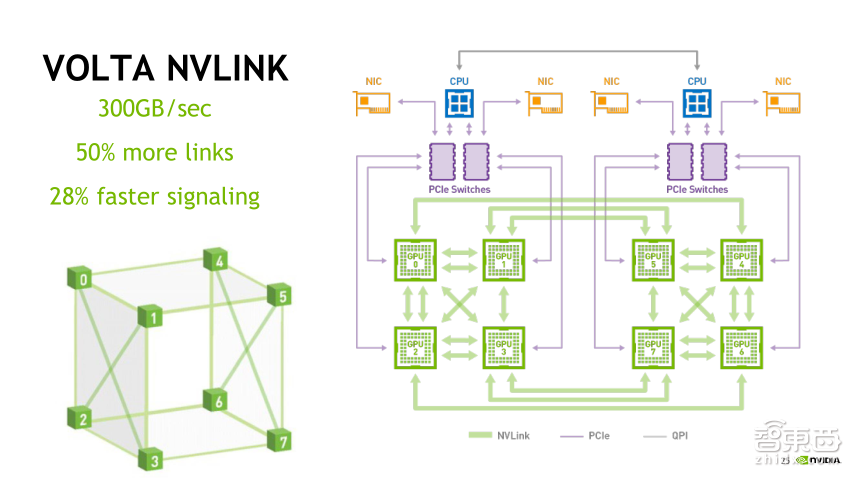
在这里我们可以详细看一下GPU的NVLink互联的方式。Tesla V100的NVLink支持的是NVLink 2.0的版本,上一代Tesla P100支持的是NVLink 1.0的协议,每个V100 GPU可以支持6个NVLink通道,每个通道的单向传输带宽可以达到25GB每秒,6个通道可以支持单向的150GB 每秒、双向300GB每秒的总带宽,NVLink 1.0版本的双向总带宽只有160GB,所以V100的NVLink速度比P100提升了将近一倍。
在这里我们可以看一下GPU的互联方式,它是采用立方体的互联方式,在图中的8个顶点为8块GPU,每块GPU之间采用图中左下角的方式互联。

这是今年3月份NVIDIA发布的新产品DGX-2。这款产品今年第三季度可以供货,DGX-2是10U标准机架式服务器,功耗10千瓦,因此对机柜的供电和散热会有一定的要求。
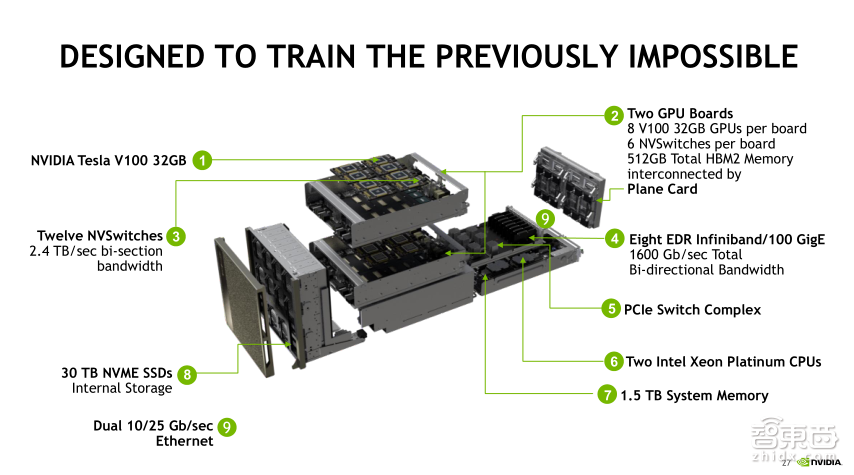
这是DGX-2的内部架构,和DGX-1相比,配置大幅度提升,首先是16块32GB的V100 GPU,12个NVSwitches,16块GPU采用全线速互联的方式,两块GPU之间总带宽都是300GB。CPU采用Intel最新的铂金版CPU,配置1.5TB主机内存,8个100GB IB网卡,30TB NVME SSD提供了更大的缓存空间。

上图展示的是DGX-2里面18端口的NVSWITCH交换机,每个端口是50GB的双向总带宽,包含20亿个晶体管,是目前速度最快的交换机。

DGX-2用12个NVSWITCH将16块GPU全部互联起来,每个GPU主板上有8个GPU,一共有两个GPU主板,每个主板上的8块GPU和6个NVSwitch互联起来,我们知道每个GPU上有6个NVLink通道,每个通道连接一个NVSWITCH,所以每个GPU会和6个NVSWITCH互联,每个GPU主板上有8个GPU,所以每个NVSWITCH会有8个NVLink通道进来,也有8个NVLink通道连接到NVBridge的背板上,也就是图中的中间桥梁部分,每个GPU主板的NVSWITCH共有48个NVLink接到背板上,因此背板的总带宽是2.4T每秒。
这里我们要了解两个概念:NVSWITCH和NVBridge,CPU和NVSWITCH相连,NVSWITCH和NVBridge相连。
只有DGX-2通过这种方式互联能够实现任意两个GPU之间的带宽可以达到300GB每秒。在DGX-1采用立方体的架构互联,并不能保证任意两个GPU之间达到300GB每秒的速度。

这是一台DGX-2和两台DGX-1的性能比较,一台DGX-2和两台DGX-1的GPU数量是相等的,但是两台DGX-1的CPU资源比一台DGX-2的资源多一倍,我们发现运行物理学、气象和深度学习的应用软件,DGX-2最少可以实现两倍的加速,这是因为更大的显存可以加载更多的数据,减少IO开销。
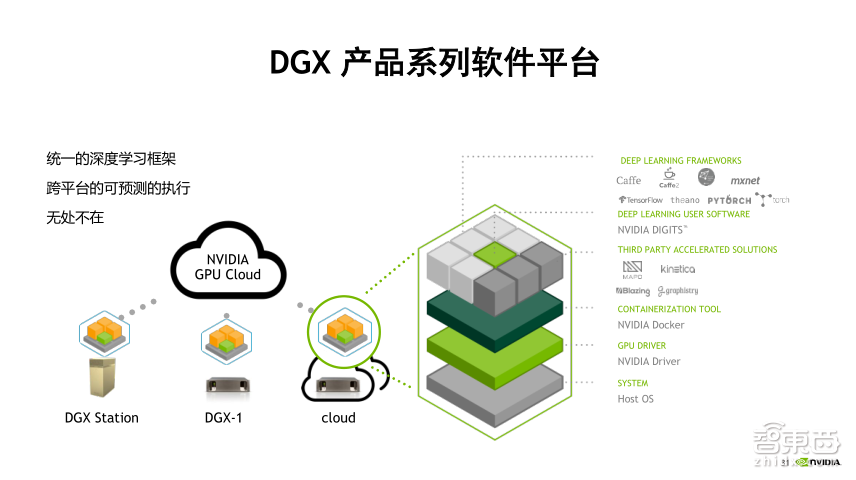
这里我想说的是容器这个工具,DGX服务器中已经集成了容器引擎nvidia-docker,也集成了一些开源的HPC软件如GROMACS、LAMMPS等。nvidia-docker容器引擎是开源的软件,大家都可以下载使用,并且可以比原生的Docker更好地调用GPU,也更稳定。
与直接在物理机上运行软件相比,使用容器省去了软件安装编译和部署的过程,避免软件依赖和兼容性的问题,节省了大量的时间,性能损失也非常小,一般容器的运行只有3%左右的损失。
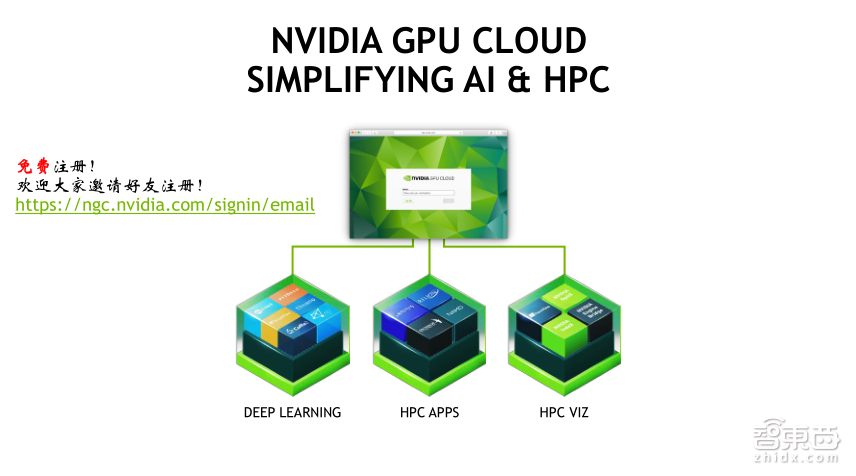
前面我们介绍了容器工具,下面我们来介绍一下如何获取相应的应用软件容器镜像。这里我们提到的是NVIDIA的NGC平台,这是一个可以免费注册的平台,在NGC平台,大家可以下载到各个深度学习框架的容器镜像,以及开源的HPC应用软件的容器镜像,比如Gromacs、LAMMPS等,以及一些可视化软件的容器镜像,欢迎大家免费下载使用。
即使你不想使用容器,这个平台也是非常有用的,可以将容器中编译安装好的软件拷贝到物理机上面运行,这样可以省去软件安装、编译的时间。
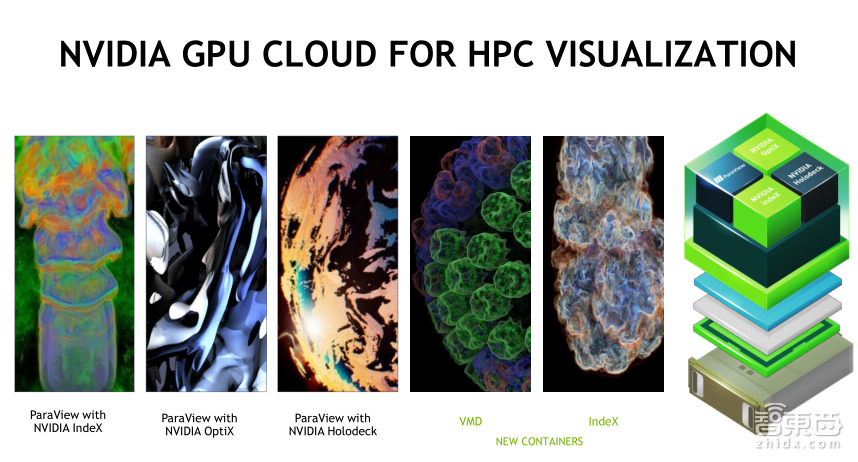
除此之外,我们还提供了可视化软件的容器镜像。可以在NGC网站下载。这个软件可以在服务器上进行HPC数据后处理操作、图形和图像渲染等。
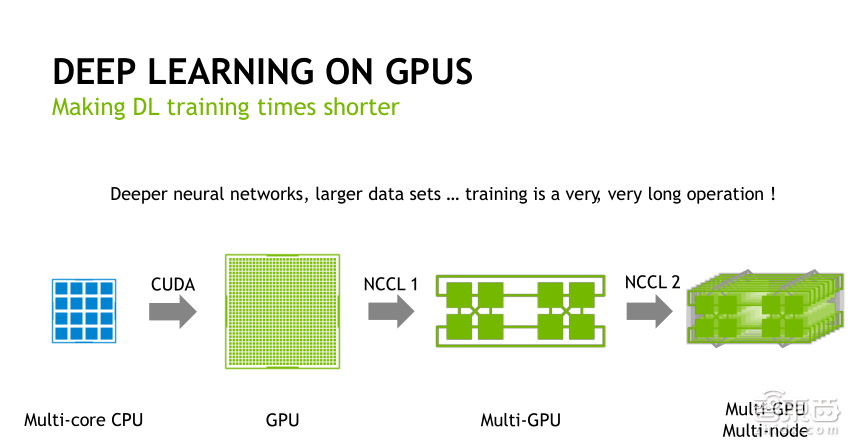
我们在HPC上进行高性能计算的时候,常常需要多块GPU并行计算,或者多台GPU服务器分布式并行计算,为了优化GPU之间的通信,我们开发了优化的集合通信函数库,即NCCL软件库。现在在NGC网站上提供下载的容器镜像已经集成了NCCL软件库,大家可以去使用。如果大家要自己开发或者编译GPU计算软件,建议去集成NCCL软件库。

这里介绍一些集群管理和作业调度的软件,这些软件都可以支持GPU的作业调度,它们可以按照GPU来实现调度,而不仅仅是按节点来调度,其中很多都是商业软件,但Slurm软件是开源的,使用也非常广泛,Slurm除了可以调动HPC应用软件之外,也可以调度Docker容器镜像。

简要介绍一下GPU的虚拟化。因为HPC计算过程中基本分为前处理、计算、后处理三部分,其中前处理和后处理一般需要图形界面来操作,对图形显示的性能要求比较高,比如我们做CAE仿真和CFD计算的时候,这些软件都可以支持GPU加速计算,我们在计算之前需要做前处理,需要画网格,计算完成后需要做后处理,对结果数据进行分析,这些前处理和后处理过程都需要很强的GPU渲染能力。
为了能够在数据中心进行前处理和后处理,通常可以使用GPU虚拟化的方式在数据中心创建远程虚拟桌面,将一块GPU虚拟成8块或者16块VGPU,分配给不同的人使用,GPU虚拟化也可以用来做深度学习和GPU计算的教学使用。
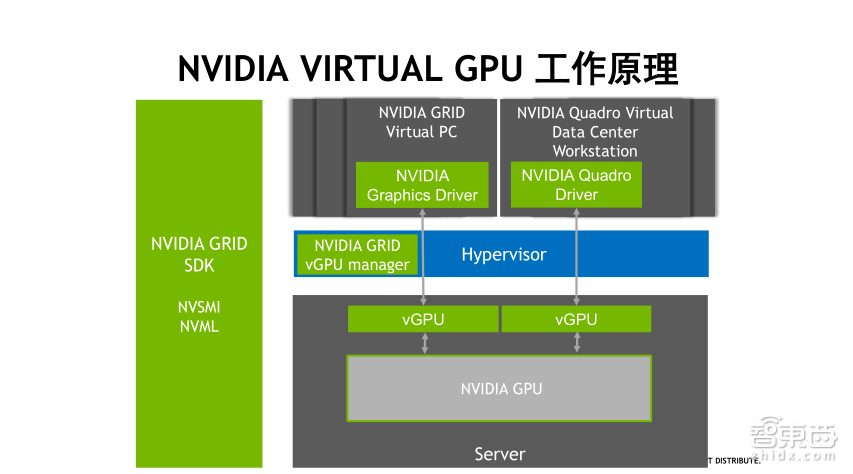
上图展示了是GPU虚拟化的基本原理,首先通过软件将一块GPU虚拟成多个VGPU。将每个VGPU分配给不同的虚拟机使用,用户可以在每台虚拟机里面安装需要的图形处理软件,现在一块GPU最多可以虚拟成32个VGPU。

这里给大家分享一些CUDA和OpenACC的开发学习资料,对快速掌握CUDA和OpenACC编程非常有帮助。
最后跟大家分享一些OPENACC程序性能调试的工具,除此之外,我们在CUDA软件包里面还有一个NVVP工具也可以用来做程序的性能分析调试等。
谢谢大家,我的分享结束了。
另外,易成老师在Q&A环节还回答了以下5为用户的问题:
问题一
鹿业涛-墨迹天气-气象工程师
空间天气预报在GPU的加速给地面天气预报以什么样的借鉴,特别是天气模式的GPU加速方面能提高多少?
易成:实际上空间天气预报和地面天气预报算法是类似的,也是适合GPU加速计算的,但是天气预报的程序主要是基于Fortran开发的,一般比较大,也比较老,移植起来难度比较大,最近nvidia正在协助国家气象局,使用CUDA/OpenACC方法进行这方面的移植。不同的气象模式加速效果不同,以WRF为例,可以达到3倍左右的加速。
问题二
陈星强-北京心知科技-数据科学家
1、是否可以将传统的动力学模型完全移植到GPU上进行加速运算,能够加速几倍?
2、cuda编程支持fotran吗?
易成:1,我们现在已经把大量传统的HPC计算软件移植到GPU上计算,比如一些分子动力学软件,物理化学软件,如Amber,NAMD,Gromacs,VASP等,还有一些CFD软件,结构力学计算软件,如ANSYS,fluent,现在都可以在GPU上加速计算。加速效果各个软件各有不同,比如amber,relion,GPU加速可以达到20倍以上;有些软件加速效果会差一些,比如CFD软件,一般只能达到3-7倍,具体算例的加速效果和算例的规模也有关系。所有能在CPU上运行的程序,都能移植到GPU上计算,考虑到GPU计算时间和IO时间各自所占的比率,如果IO时间占的比率较大,我们会让他留在CPU上计算;如果GPU计算时间比率比较大,移植到GPU上就会有较大的加速效果
2,现在CUDA支持的语言很多,正如我PPT中所说,包括C/C++,Fortran,Python等
问题三
蔺子杰-北京工业大学-高性能计算方向硕士研究生
1,在利用GPU做异构并行的时候,PCIE等通信接口会严重影响性能。这个问题有什么好的解决办法吗?
2,GPU板卡不能针对我的问题提供足够使用的内存。这个问题有什么好的解决办法吗?
3,目前存在CPU到GPU的代码转换器。请问这种转换的代码,效率如何?
易成:1,我们在做多GPU计算时,会涉及到GPU之间的通讯,在P100以前,我们只能通过PCI-E通信,从P100开始,nvidia 推出了nvlink版本的GPU,GPU之间通过nvlink通信。现在V100采用的nvlink2.0,双向总带宽可以达到300GB/s,远高于现在PCI-E 3.0的32GB/s的双向总带宽。这样就能很好解决这个瓶颈问题
2,今年nvidia推出的32GB的V100,可以很大程度上缓解GPU显存不足的问题。另外,可以通过多GPU并行计算,提升GPU总的显存量,将数据分配到多个GPU中,同时进行计算
3,目前还没有发现很好的用于CUDA与C/C++/Fortran之间代码转换的工具,这种工具目前应该是效果不理想。
问题四
曾桃元-DELLEMC-全球解决方案高级顾问
1,GPU并行计算环境,2、4、8、16块V100的GPU卡并行性能是否几何倍数提升,是否有性能对比数据?
2,NVIDIAGPU环境,对深度学习的计算框架,做了哪些优化,比如具体CUDA开发环境是否有对DL有优化?
易成:1,GPU并行计算的扩展性和软件、算例都有很强的关系,对于DeepLearning应用,是很明显的近似线性加速效果的,扩展性非常好;对于amber,relion,加速效果也是非常好的,接近线性的加速,当然也和算例大小规模有关。
2,现在对于每一个深度学习框架软件,nvidia都发布了一个对应的docker image镜像,会支持最新的GPU功能和最新的CUDA版本,这些镜像里面的深度学习框架软件会自动调用cuDNN,cuBLAS,NCCL等nvidia发布的深度学习相关的库,会较好的支持tensor core,fp16等新特性。
另外,nvidia发布了一个nvidia版本的caffe,即nvcaffe,会对开源的caffe做一些优化,比如增加ImageDataLayer并行化,提升训练精度,支持RNN,Deconvolution,SSD层等等,其他的框架也有一些优化,可以参考nvidia发布的相关框架的release notes。
https://docs.nvidia.com/deeplearning/dgx/#nvidia-optimized-frameworks
问题五
李敏-中科院软件所-高性能计算与并行计算方向博士
1,我们都知道nvidia的GPU的架构和产品都更新的很快,接触的比较少的人,可能都不是特别了解其发展,易老师可否帮忙梳理一下,尤其是一些关键技术出现的架构。
2,可否介绍一下,cuda对于任务并行的支持情况?如果想实现任务的并行,目前有哪些方法?
易成:1,正如我在PPT介绍的一样,nvidia GPU经过了10多年的发展,从早期的G80,GT200架构的GPU,到2010年发布fermi架构,这是一个较大的飞跃,第一个完整的GPU计算架构,也确定了基本的GPU架构路线,后来陆续发布的Kepler架构,Maxwell架构,Pascal架构,Volta架构。早期G80,GT200对应的GPU产品有C870,C1060,C1070等,fermi架构,常见的产品有C2050,C2070,M2070,M2090等,Kepler架构大家应该比较熟悉了,有K20,K40,K80等;Maxwell架构有M10,M40,M60等,Pascal架构有P4,P40,P100,Volta架构只有一款,就是V100。前面有人问这些架构有什么区别?不同的架构首先制程不同,比如V100采用的是10nm制程,其次是fp64,fp32,int32核心的主频和核心数不同,V100增加了tensor core 核心,这也是架构的不同,另外,L1,L2 cache,register寄存器数量,不同架构也是不同的。
2,GPU的并行包括thead级别,即GPU线程的并行;更高层次是kernel级别的并行。Thead并行体现在,我们在执行一段程序代码时,可以使用单指令多线程(SIMT)来管理和执行线程,支持成百上千的线程并发执行,这里只有一个kernel在运行。如果要实现多个kernel并行,可以通过stream来实现了,可以通过MPS多进程服务,以前叫Hyper-Q,来实现多个stream的调度,不同的stream实现不同的任务。如果只是想在一个GPU上运行多个GPU应用,比如同时提交amber,Gromacs作业,这个也是可以的。如果GPU的利用率不高,这样做没问题,如果GPU利用率已经是100%,运行多个作业会导致计算速度变慢。如果使用slurm调度,它只会给空闲的GPU资源分配任务。
