








智东西(公众号:zhidxcom)
文 | 心缘
智东西7月12日消息,第35届机器学习国际大会ICML 2018在7月10日至15日期间登陆瑞典斯特哥尔摩。ICML官网上提前公布了最佳论文名单,来自MIT和UC Berkeley的研究人员摘得最佳论文的桂冠。复旦大学大数据学院副教授黄增峰独立署名的论文《Near Optimal Frequent Directions for Sketching Dense and Sparse Matrices》和来自DeepMind、斯坦福大学的两篇论文共同位居最佳论文亚军行列。

▲ICML 2018举办场地
ICML源于1980年卡内基•梅隆大学举办的机器学习研讨会,如今它已成为代表学术界机器学习最高水准的国际顶级会议。今年ICML 2018共入围621篇论文,我国腾讯、清华、北大等研究机构也在论文入选排行榜上占据一席之地。

▲ICML 2018官网公布最佳论文和最佳论文亚军名单
一、最佳论文(Best Paper Awards)
1、《Obfuscated Gradients Give a False Sense of Security: Circumventing Defenses to Adversarial Examples 》
作者:来自麻省理工大学(MIT) 的 Anish Athalye ,来自加州伯克利大学(UC Berkeley)的 Nicholas Carlini 和 David Wagner。
简介:如果在一张图片添加干扰,可能就能骗过分类器。为了抵御对抗样本的攻击,使得神经网络在受到迭代攻击时不受对抗样本干扰,研究人员在寻找强大的对抗样本防御器,使其在面对基于优化的攻击之下,可以实现对对抗样本的鲁棒性防御。

摘要:我们确定一种混淆梯度(Obfuscated gradients)现象,它会给对抗样本的防御带来虚假安全感。尽管引发混淆梯度的防御似乎能抵御基于迭代优化的攻击,但我们发现依赖于此效果的防御方法可能会被绕过。我们将描述和展示我们所发现的三种类型混淆梯度效果的防御特征,并针对每一种混淆梯度开发了可以克服问题的攻击技术。在案例研究中,通过在ICLR 2018上检验未经证明的白盒安全防御,我们发现混淆梯度是一种常见现象,9种防御方法中有7个都依赖于混淆梯度。在每篇论文所考虑的原始威胁模型中,我们的新攻击成功完全攻克6种防御,部分攻克1种防御。
论文下载:http://proceedings.mlr.press/v80/athalye18a/athalye18a.pdf
补充材料:http://proceedings.mlr.press/v80/athalye18a/athalye18a-supp.pdf
2、《Delayed Impact of Fair Machine Learning》
作者:来自加州伯克利大学电子工程与计算机科学部的 Lydia T. Liu、Sarah Dean、Esther Rolf、Max Simchowitz 和 Moritz Hardt。
简介:机器学习模型常受数据影响而存在偏见问题,本文以借贷问题为背景,探索静态公平性准则等长期影响,分析和探讨如何使机器学习算法更加公正的对待各个群体,保护弱势群体并获得长期收益。

摘要:研究者们主要在静态分类的场景下研究机器学习的公平性准则,但没有关心这些决策随着时间推移会如何改变潜在群体。传统观点认为,公平性准则可以更好保护受不公平群体的长期利益。我们研究静态公平性准则如何与利益指标之间相互作用,例如利益变量的长期增长、停滞和下降。我们证实了即使在一阶反馈模型中,常规的公平性准则通常也不会促进随着时间的推移而有所改善,并且对于那些在无约束的目标不会导致损害的情况,公平性限制反倒可能会造成伤害。我们完整描述了三个标准的公平性准则的延迟影响,对比了这些准则行为表现出可量化的不同行为。此外,我们还发现自然形式的测量误差放宽了有利于公平性准则发挥作用的制度。我们的结果显著体现了评估公平性准则的测量和时间建模的重要性,也提出了一系列新挑战和权衡取舍问题。
论文下载:http://proceedings.mlr.press/v80/liu18c/liu18c.pdf
补充材料:http://proceedings.mlr.press/v80/liu18c/liu18c-supp.pdf
二、最佳论文亚军(Best Paper Runner Up Awards)
1、《Near Optimal Frequent Directions for Sketching Dense and Sparse Matrices》
作者:来自复旦大学大数据学院的副教授黄增峰。

▲复旦大学大数据学院副教授黄增峰
简介:该论文讨论的在线流(online streaming)算法可在只有协方差误差非常小的情况下,从大型矩阵抽取出最能近似它的小矩阵。

摘要:给定一个n×d维的大型矩阵A,我们考虑计算一个ℓ×d维的概要矩阵(sketch matrix)B,它的维度明显小于但仍然很接近矩阵A。我们对最小化协方差误差感兴趣。考虑到流模型中的问题,其算法只能在有限的工作空间中输入通过一次。而流行的Frequent Directions算法(Liberty,2013)和它的变体实现了最优空间和误差权衡。然而,是否可以改善运行时间仍然是一个悬而未决的问题。在本文中,我们几乎解决了这个问题的时间复杂度。尤其是,我们提供了新的空间优化算法,运行时间更短。此外,除非可以显着提高矩阵乘法的最新运行时间,否则我们算法的运行时间是近似最优的。
论文下载:http://proceedings.mlr.press/v80/huang18a/huang18a.pdf
补充材料:http://proceedings.mlr.press/v80/huang18a/huang18a-supp.pdf
2、《The Mechanics of n-Player Differentiable Games》
作者:来自DeepMind的David Balduzzi、Sebastien Racaniere、James Martens、Karl Tuyls、Thore Graepel和和牛津大学的研究者 Jakob Foerster。
简介:深度学习在训练过程保证梯度下降收敛于局部最小值,但当产生对抗式网络时,收敛于一个极值会造成损失。对此,本文研究新技术用于理解和控制可微分多万家博弈中的动态机制。

摘要:支撑深度学习的基石是保证目标函数能利益梯度下降收敛于局部最小值。不幸的是,这种保证在某些情况下会失效,比如生成对抗性网络(GAN)中会存在多个交互损失。基于梯度的方法行为在博弈中没有得到很好的理解, 随着对抗性和多目标架构的激增,这方面的研究变得越来越重要。在本文中,我们开发了新技术来理解和控制一般博弈中的动态表现。其中关键成果是将二阶动态分解为两个项。第一项与潜博弈(potential game)有关,可以根据隐式函数简化梯度的下降而减小;第二部分涉及到哈密尔顿博弈,这是一种遵循守恒定律的新博弈,类似于经典力学的守恒定律。其分解手段启发了辛梯度调节(SGA)算法,这是一种在一般博弈中寻找稳定固定点的新算法。基础性实验表明,SGA与最近提出的用于寻找GAN局部纳什均衡的算法不分伯仲,同时适用于一般博弈并保证收敛性。
论文下载:http://proceedings.mlr.press/v80/balduzzi18a/balduzzi18a.pdf
补充材料:http://proceedings.mlr.press/v80/balduzzi18a/balduzzi18a-supp.pdf
3、《Fairness Without Demographics in Repeated Loss Minimization》
作者:来自斯坦福的Tatsunori Hashimoto、Megha Srivastava、Hongseok Namkoong、Percy Liang。
简介:通常机器学习系统只考虑最大化整体的准确率,导致模型无法识别少数群体,这会造成少数群体在整体数据中的流失。该论文研究的是在不知道用户分布的情况下,如何保证重复损失最小化的算法公平性。

摘要:训练平均损失方面的机器学习模型(例如,语音识别器)遭受着表征差异问题,少数群体(例如非母语人士)在训练目标中承载较少的权重,并因此往往受到更高的损失。更糟糕的是,随着模型准确性对用户保留的影响,少数群体的数量会随着时间的推移而减少。在本文中,我们首先展示经验风险最小化(ERM)的方法加重了表征差异问题,甚至可能使最初公平的模型也变得不公平。为了缓解这种情况,我们开发了一种基于分布式鲁棒优化(DRO)的方法,该方法可以最大限度地降低所有分布的最坏风险,使其接近经验分布。我们证明了这种方法符合罗尔斯分配正义,可控制每个时间步骤的少数群体风险,同时该方法仍然没有认清群体标识。我们证明DRO可以组织样本表征差异的扩大,这是ERM做不到的,我们还展示了该方法在现实世界文本自动完成任务上对少数群体用户满意度的提高。
论文下载:http://proceedings.mlr.press/v80/hashimoto18a/hashimoto18a.pdf
补充材料:http://proceedings.mlr.press/v80/hashimoto18a/hashimoto18a-supp.zip
三、国内外研究机构参与论文入选情况
与其他人工智能相关会议情况相似,今年的投稿数再创新高,达到2473篇,比去年ICML投稿数足足多了797篇。今年5月23日,ICML公布入选的论文榜单,有621篇论文突破重围,几乎比去年的434篇入围数量超了接近一半。根据对所有论文关键词做出的词云,神经网络架构、强化学习、深度学习、优化、监督学习、在线学习、生成模型、统计学习理论等词汇在投稿和入选论文中出现的频率都遥遥领先。
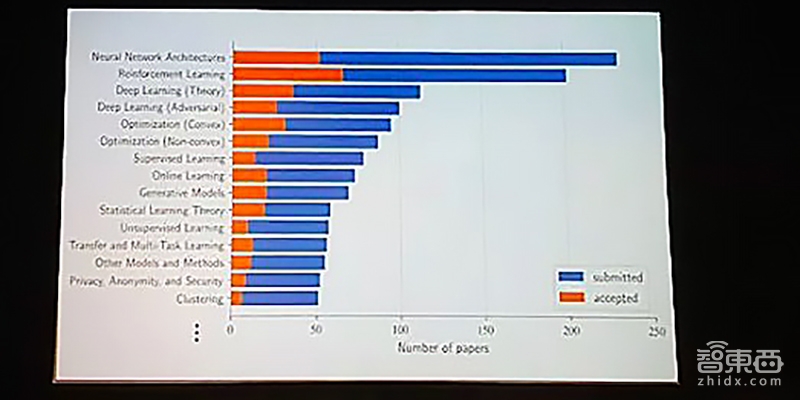
▲ICML 2018现场PPT
下图为621篇论文中位居前25名的一作论文所属机构。单看第一作者,谷歌以49篇稳居冠军宝座,UC伯克利大学、麻省理工大学(MIT)、斯坦福大学分别以22、21、20篇紧随其后。根据图中列出的25个机构,有23个都是学术机构,仅有谷歌和微软研究院属于企业研究机构。我国只有清华挤入一作论文排行榜单。
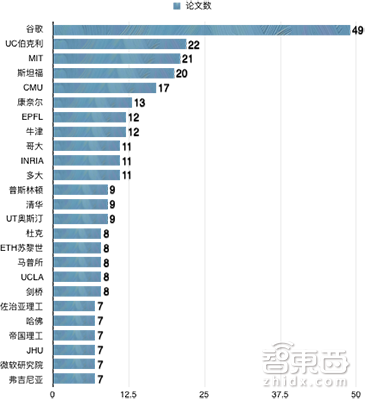
▲ICML 2018各机构一作论文入选情况
下图为国内学术机构和企业机构参与ICML 2018入围论文的总篇数。
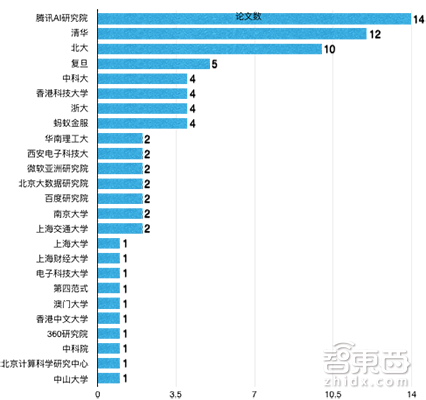
▲ICML 2018国内机构论文总篇数(包含非一作)入选情况
从图中可以看出,国内学术机构以清华和北大独领风骚,复旦、中科大、香港科技大、浙大位居第二梯队。而企业机构以腾讯AI研究院表现最为卓越,不仅有6篇一作入围,在全球企业中仅此于谷歌和微软,参与的论文总数更是高达14篇,超过了清华和北大。另外,阿里巴巴的蚂蚁金服有4篇入选,百度研究院有2篇入选,第四范式有1篇入选。
从整体来看,无论是国际上还是国内,学术机构的贡献占ICML论文数量的大头。不过,位居前列的企业机构,如谷歌、微软以及我国的腾讯和阿里,在参与论文总数上的成绩均超过多数高校研究机构。

