








本文根据中天微资深设计经理、智能语音平台负责人劳懋元,在「智东西公开课」的超级公开课中天微专场第1讲《轻量级的RISC架构如何实现端测智能语音应用》 上的系统讲解整理而来。
从2015年起,智能语音芯片已经演进了三代。时至今日,CPU+DSP+NPU架构逐渐成为智能语音专用芯片未来的趋势。但中天微探索出通过轻量级的RISC架构来实现端侧的智能语音应用。为了解决RISC在做一些人工智能或者深度神经网络应用时存在的算力不足的缺陷,中天微提出融入DSP的并行计算能力,即在一个短流水级的CPU基础上,把DSP 128位宽的SIMD并行处理能力融进来,使得新款CPU能够被应用在智能语音等轻量级人工智能上。这是一个有些另类的创新路径,中天微也希冀得到更大范围的认可和采用,从而更快地搭建起以智能语音为核心的人工智能生态。
主讲环节
劳懋元:今天主要从四个方面来分享:首先,从对市场的观察和理解切入,之后会慢慢深入到对智能语音芯片的理解以及我们所取得的一些成绩;其次,从技术原理本身出发,RISC中的一些细分,以及在重的架构和轻的架构之间如何去取舍;最后分享一下智能语音TURNKEY方案。
一、智能语音市场现状分析
从市场的角度来看,谈到智能音箱,时间点要回溯到2015年下半年。当时Amazon推出了第一款智能音箱Echo,从此拉开了整个智能音箱的序幕。当时间过渡到2016年,智能音箱有了进一步的发展,第二大势力Google就出现了,推出了Google Home。市场资料表明,到目前为止,国外市场上,Amazon和Google基本上是七三开的两强局面。相对来说,国内在技术研发上会稍微滞后一些。整体爆发出现在2017年,俗称“百箱大战”,几十将近一百个智能音箱纷纷出现。到今年上半年,阿里巴巴推出了一款新的比较小巧的智能音箱,叫做天猫方糖,直接把智能音箱的价格杀到了89元的低价区间。同样,大家也能看到,小米也有类似低价的智能音箱出现。从2018年开始,整个市场的趋势不是以量取胜,而是逐渐开始低价渗透,以及开始比拼各家生态的打造。从最新的市场统计来看,目前全球范围主要有四家,分别是Amazon、Google、阿里巴巴以及小米。
看完智能音箱的发展史,我想跟大家探讨一些问题:
第一,相比于传统音箱,智能音箱还是音箱吗?还是更准确地说是人工智能助手,或者是未来智能家庭的总控,亦或者是互联网企业称之为的流量入口?
第二,智能音箱是否代表着整个智能语音未来的市场?是不是也会像手机、平板或者PC这种单一品项的一种状态?
我认为不是的。智能语音其实是一种交互方式,可以被应用在各种类型的设备当中。从我个人对市场的判断来说,它才是一个真正意义上的超级大饼,会涉及到更多的细分领域。因此,对智能语音这项技术的研究以及成熟方案的推动是非常有意义的。这也是中天微从2016年年初就建立团队投入资源,并且持续两年半的时间一直在做这件事情的初衷。
接下来跟大家分享一些除了智能音箱,其他搭载着智能语音功能的产品。首先是家电,不管是大家电还是小家电都会带有语音功能,比如空调、微波炉或者油烟机等产品也陆续出现。今年上半年,阿里巴巴也推出了真正远场智能语音的电视机;第二,在儿童玩具市场上,不管是儿童故事机或者是一些称之为儿童陪伴型的机器人玩具,我们也能看到智能语音交互的方式。它让孩子与玩具之间有一个非常好的互动;第三,在穿戴式设备上,比如儿童手表、智能手表等都加装了语音交互功能,使得小孩子用语音操作变得更加方便;第四,一些母婴类的摄像头上也加装了这样的功能。
除了以上四个之外,还有很多领域正在做进一步的尝试,去创造一些新的场景,以及在怎样的一个场景之下会使用到智能语音交互的方式,我们可以期待和预期到在未来会有更多的一些产品出现。这也是我前面说的超级大饼。
简单总结一下,智能语音是一种崭新的人机交互方式,更贴近于人类自然的一种交流方式,会带来一场可以称之为交互方式的升级,亦或者是产品的升级,并且波及到的产品领域和范围,将会远远超过之前所有的产品。
二、智能语音芯片不同架构解读
现在从技术的角度来展开一下,先回顾一下几个技术点。
首先是RISC,精简指令集计算机的缩写。既然有一个叫做精简指令集,对应的一定有一个叫做复杂指令集。比较广为人知的如Intel或者AMD x86型CPU都是复杂指令集的,而中天微的C-SKY CPU或者ARM CPU都是精简指令集的CPU。
RISC诞生于上世纪80年代,从名字可以看出,既然叫精简指令集,那么指令数量就比较少。它的特点是指令的格式、执行周期是一致的,一般都采用流水线技术;从存储架构上来说,一般会用冯诺依曼架构。冯诺依曼架构可以简单理解为,它会把程序段跟数据段都存在同一个地方,本身的计算核心是算术逻辑单元ALU。有几个比较知名的地方,首先是斯坦福大学,另外一个是加州大学伯克利分校,他们在RISC方面有着非常大的贡献。特别值得提到的是加州大学伯克利分校,有一位非常著名的教授叫做David Patterson。他是RISC体系的创始者,在上世纪80年代就已经在做RISC项目。最近非常火热的RISC-V是在2010年开始研发的新项目,希望能够做成一个开源的指令体系,背后也有非常多国内外一些大企业在积极推动。中天微最近也发布了第一款基于RISC-V指令集的CPU核。另外,大家比较熟悉的还有MIPS、 IBM的Power PC。
讲完RISC,我们再来聊一下DSP。很多电子专业毕业的人,在学生时代都学过一门课叫做DSP——数字信号处理。该技术也是诞生于上世纪80年代。数字信号处理的特点是把自然界的模拟信号转成数字信号,再通过专门的数字信号处理器去进行一些复杂的处理。因此,它的出现主要是针对一些快速实时性数字信号的处理。同样,它也是采用流水线技术,强调计算能力,所以会使用一些如SIMD这样的存储技术,会用哈佛结构把数据和程序分开。在这个领域中,大家比较熟悉的可能是德州仪器、Freescale以及Motorola等这些企业,现在能提供DSP IP的也有两家,一家是CEVA,一家是Tensilica。
相对于前两者来说,NPU(神经网络处理器)是一个比较新的概念。AI也是这两年突然变得非常火热,很多人开始去研究神经网络,甚至去设计神经网络处理器。我们也非常幸运能够处在这样的一个时代,刚好赶上了神经网络发展这一波浪潮。神经网络处理器到目前为止,还没有一个非常准确的定义,包括体系架构或者指令架构,目前来说是百花齐放,没有一个统一的标准。大家比较熟悉的,如Google和NVIDIA。Google推出了TPU,NVIDIA一直把GPU技术用在神经网络的一些训练以及推断上。国内现在比较出名的有寒武纪,麒麟970中也用了寒武纪的NPU;还有地平线,在智能驾驶,语音方面也有非常独到的成绩。因此,目前国内从事神经网络以及相关技术研究的企业也是非常的多,NPU最终会变成一个什么样的统一标准,大家可以拭目以待。
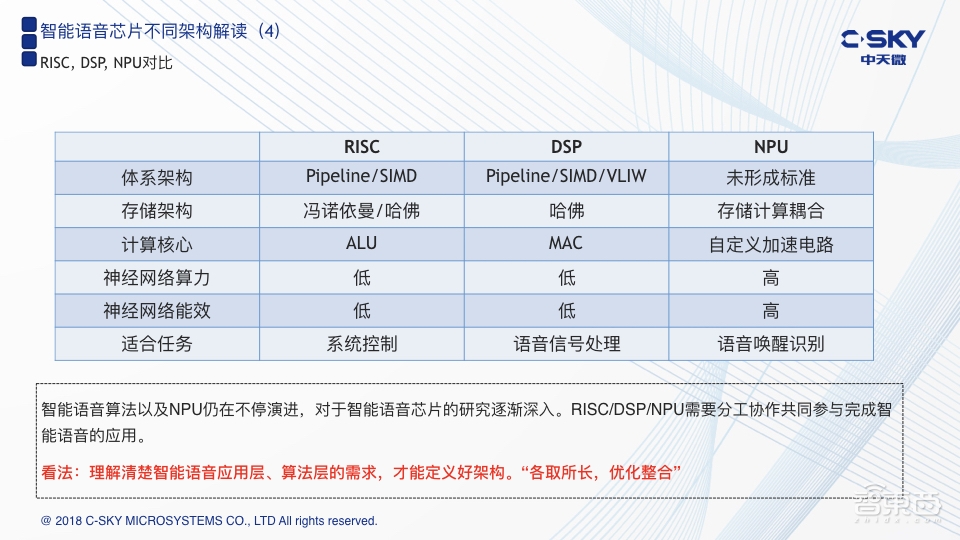
接下来我们简单地用一张表格从体系架构、存储架构、计算核心以及今天将要讲的神经网络算力和神经网络能效五个维度来对比一下这三种技术。可以看到传统的RISC或者DSP在处理神经网络相关的应用时都会表现出一些缺陷和不足。这也是为什么我们要去研究神经网络,根据神经网络的特点去定制研发新的CPU的原因。在这里,我想跟大家分享一下,在如今这个时代,在要去做一些神经网络或者人工智能相关应用时,出发点应该是从算法和应用出发去理解,这才是一个真正的以软件驱动硬件,以算法驱动硬件的时代。另外,RISC、DSP、NPU各有优缺点,只有把它们各取所长、优化整合才能发挥出最大的效率。
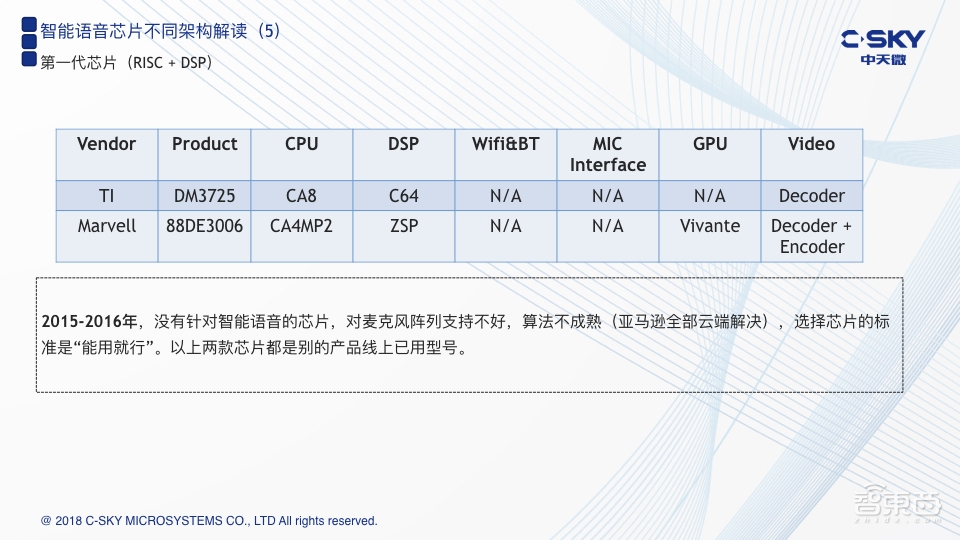
前面可能讲得会比较理论一些,接下来就结合实际的芯片产品来做分析。
智能语音芯片,从产品的出现到现在,我认为可以分为三代:第一代要追溯到2015年,也就是Amazon刚发布Echo以及Google刚发布Google Home时用的芯片,上图中也罗列出来了,包括TI多媒体处理器以及Marvell的一款处理器,基本上是CPU搭配DSP的架构。CPU一般是ARM Cortex A系列的产品。而对于DSP来说,由于TI在DSP上有非常深的积累,它会把自己C64系列的DSP放在里面,而Marvell当时用的应该是芯原的ZSP系列。同时,它们都没有集成WI-FI和蓝牙;从麦克风接口的角度来说,当时也不具备。另外,由于它们之前都是用在多媒体应用领域,所以里面有GPU硬件单元。回顾那个时代,当时是没有一颗真正针对智能语音的芯片,主要是因为当时这个东西很新,很多技术都是不成熟和不完善的,很多问题大家都没有彻底地去理解,因此拿一颗在以往的产品上已经被成熟应用的芯片直接过来做相应的开发。我认为,当时选择芯片的标准就是能用就行,只要能够把它想要跑的一些应用软件程序都能跑起来,就可以了。
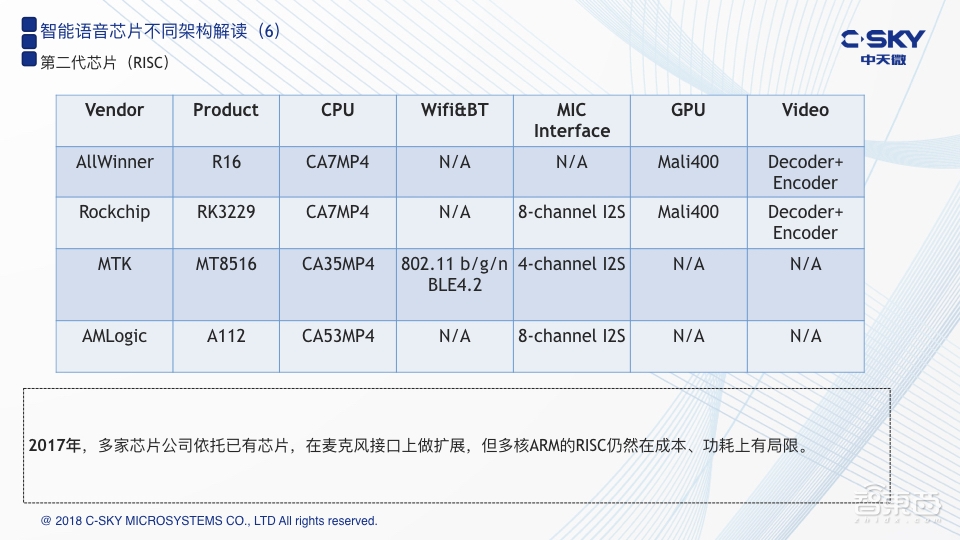
我认为,第二代芯片出现在2017年。对于第二代芯片,大家看到的基本上都是一个多核的CPU架构,此时国内的一些芯片类企业也提供了自己相应的产品,比如全志科技、台湾的联发科以及晶晨半导体等。这里所列的几颗芯片都是目前在智能音箱产品当中被应用的解决方案,对比前面一代,可以看到它把DSP去掉了,取而代之的是一个比较强的多核架构。
另外,在麦克风的接口上也加入了一些处理,联发科甚至把无线连接的部分WI-FI和蓝牙也放了进来。之所以要在麦克风阵列中做一些处理,是因为目前在实际的产品端,已经被证明远场的智能语音交互必须用到多麦克风阵列。相比之下,传统的芯片在音频麦克风接口上来说,要么是量不够,要么所支持的麦克风类型不够。大家都知道,麦克风也要分为很多种,包括模拟麦克风、数字麦克风、传统的柱状体麦克风以及现在比较流行的MEMS麦克风。Amazon的Echo是一个7+1的麦克风阵列,目前主流的一些音响类产品也是六个麦克风或者四个麦克风,最少也要两个麦克风。因此对于这些芯片在接口问题上就提出了新的要求。而他们也首先把麦克风接口的问题解决了,但是这样来看,其实还是一个比较偏向于AP级的芯片方案。这样带来的问题可能是,它的处理能力以及存储能力并没有问题,而在成本以及功耗上就会有一定的局限性。假设我们要把这样的芯片应用到一些不插电,仅利用电池供电的一些低功耗嵌入式产品当中,它就存在着非常大的阻力。
接下来是我所定义的第三代芯片,也就是真正的智能语音芯片开始出现了。
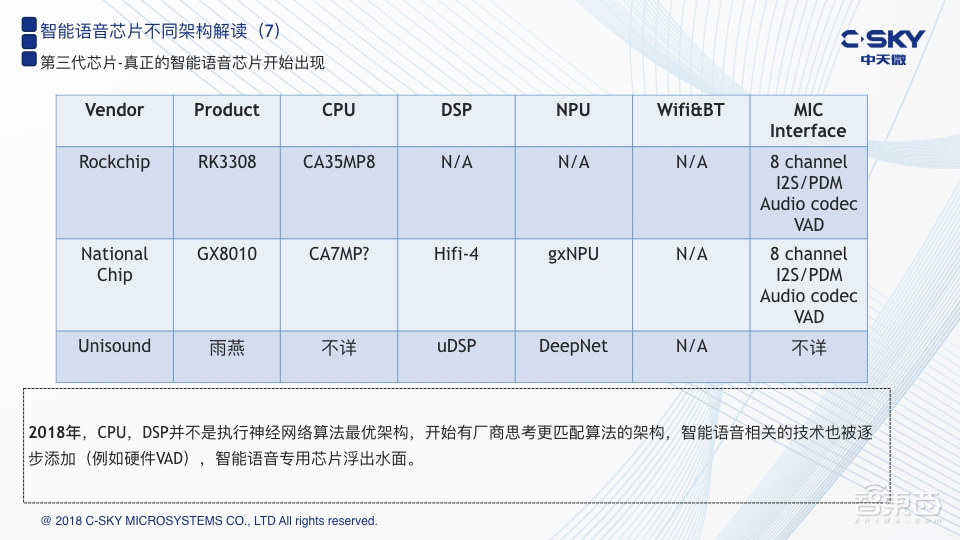
目前来说,上图列出的是目前已知的三款,第一款是瑞芯微的RK3308。相比第二代芯片,RK3308加入了一个新的功能,就是语音检测VAD,是用纯硬件的方式去实现的,技术点在智能语音交互当中是非常关键,特别是对于低功耗待机情况下的语音监听是非常重要的特点。
第二款是杭州国芯的GX8010。GX8010比较复杂一些,有一个CA7的CPU,有一个Hifi-4的DSP,以及国芯自己的NPU。这是第一次在芯片中出现了NPU。另外,它也继承了第二代芯片的特点,把麦克风的接口以及VAD的功能也加了进来。
另外还有一家是北京的云知声。云知声最近也一直在做市场的推广,让更多的人知道他有一颗“雨燕”芯片,里面也是由一个CPU+DSP+自定义的NPU的架构。因此,从2018年开始,有更多企业开始认真地深入地去思考智能语音。这也就是前面我讲到的那几个点,由于它里面会涉及到人工智能的一些算法,而NPU被引入进来弥补CPU或者DSP在神经网络计算方面算力不足和能效比较低的缺点,我相信这也会逐渐成为未来的趋势。其实NPU技术在图像类和视觉类很早就已经被应用起来了,但是应用在智能语音是2018年才起来。
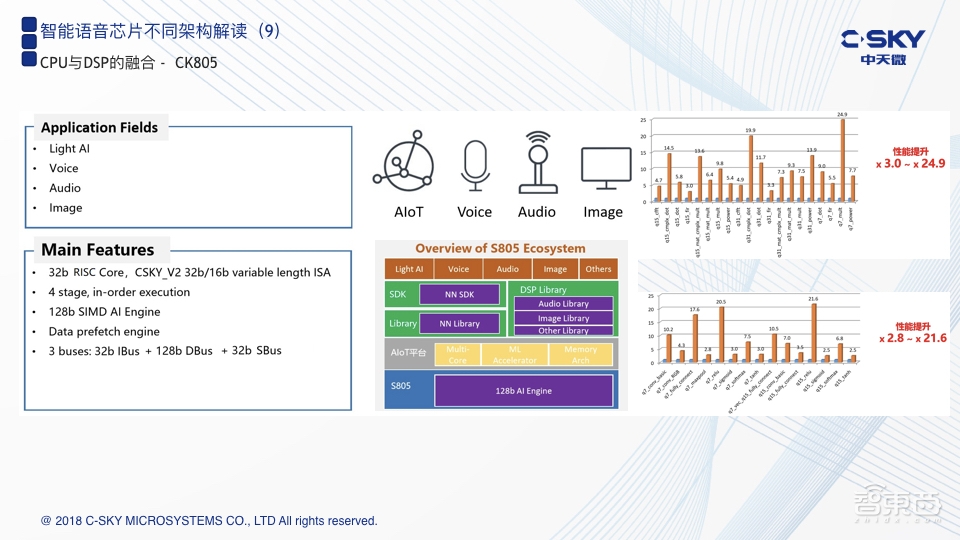
接下来,我想介绍一下中天微在这方面的一个创新点。前面也提到,中天微是一家作为RISC指令集架构CPU的企业,RISC在做一些人工智能或者深度神经网络应用时会存在一些算力不足的缺陷,如何解决这个问题?我们的一个创新点在于把DSP的一些并行计算能力融入进来。可以理解为,在一个短流水级的CPU基础上,把DSP 128位宽的SIMD并行处理能力融进来,使得新的CPU能够被应用在一些轻量级的人工智能上。比如,语音就是一个非常好的切入点,一些简单的图像处理也可以在该架构上被运行起来。除了最基本的核,我们在上层的配套方面,比如开发工具、基础的算法库,以及中间件或者应用层的配套上,也都有一个完整的生态。
最右边的两张图是做了非常直观的对比,上面一张图是一些通用的DSP计算函数效率的对比,实际的测试结果已经是我们友商的3倍到24倍;下面这张图更多的是聚焦在神经网络相关的一些基本函数的执行效率上,也可以看到已经达到了友商的2.8倍-21.6倍,即CK805的核目前已经能够去取代一些重量级的DSP。相对于普通RISC架构的MCU核,它的算力已经有了非常大的提升,同时这个核也是智能语音平台的基础所在。
三、RISC架构的重与轻
进入这部分探讨之前,我先抛三个问题:
1.如果现在你是一个设计者,要去做智能语音应用,如何去选择你的处理器的核心部分?直接去选用一个高性能核,还是去选择一个多核的架构?
2.对应的存储需要多大,是否一定要去搭配一个DDR去实现?
3.图像显示是不是也是必须的?
在直接给出答案之前,我想先解释一些事情。首先,这是一个应用和算法决定硬件的案例,智能语音本质是一种人机交互的方式,相当于我们最开始在PC时代用的是键盘和鼠标;到了手机时代,逐渐开始使用触摸屏;而下一个时代的交互方式我们有理由相信是智能语音,因为说话是人类最自然的一种交互方式。很多人都说智能语音是AI,我对这句话是持保留态度的。之所以会跟AI挂上钩,是因为智能语音用到了一些神经网络的技术,特别是在语音的唤醒和识别算法中,逐渐有更多神经网络的算法融入其中。
2012年左右,深度学习迎来了一波技术上的升级爆发,用神经网络去做语音识别和唤醒时,其整体识别率突然出现了突破性的增长,这也奠定了智能语音产业化和商业化的基石,现在,在信号处理部分也有一种趋势,把神经网络的技术也融进去,能够得到更好的应对复杂场景的能力。
其中最重要的一点是算法,算法包含了两部分:
第一部分是语音信号处理。语音信号处理,指的是需要把你说的话非常清晰地提炼出来给到机器,具体包含去噪(NS)、去回声(AEC)、波束成形(BF)、自动增益控制(AGC)以及以软件断点检测(VAD)。这快相对会比较传统一些,因为它在很多声学的产品当中很早就已经被应用起来了;
第二部分是语音唤醒和识别,也是智能语音的核心所在。它能够让机器真正听懂人说的话,而解决这个事情也会碰到很多问题,主要存在以下几个难点:
第一,它需要的是远场的处理。先解释一下远场,有远场就一定有近场。之前手机上出现的,比如苹果的siri这样的语音助手,拿着手机并按住去录音,让机器能够识别听懂你说的话,一般来说距离在十公分左右的场景,我们称之为近场;而远场更加类似于人与人之间的交流方式,距离在5米左右,要在这样距离的场景下把话听清楚,就是远场语音要解决的问题,这就涉及到了多麦克风阵列。
第二,传统处理器架构的神经网络算力不够以及执行效率非常低。即便是8核的多核架构的芯片,甚至每个核的主频都是在1G赫兹以上的强CPU,也会出现执行效率非常低的问题。
第三,语音本身虽然看起来很简单,但实际上是非常复杂的,在不同的场景会发生不同的变化。人类的耳朵是一个非常先进的系统,不管是在安静的场景下,或者是非常复杂嘈杂的环境下,都能够非常快速地做出自适应,并且能够去听懂目标对你说的话。而机器不一样,机器是非常死板的,在安静条件下或者在嘈杂环境下,即便是同一套硬件,用同样的算法,也会得到不同的效果。这是一个非常难的地方,也是为什么神经网络技术会被逐渐用到智能语音应用中的原因。
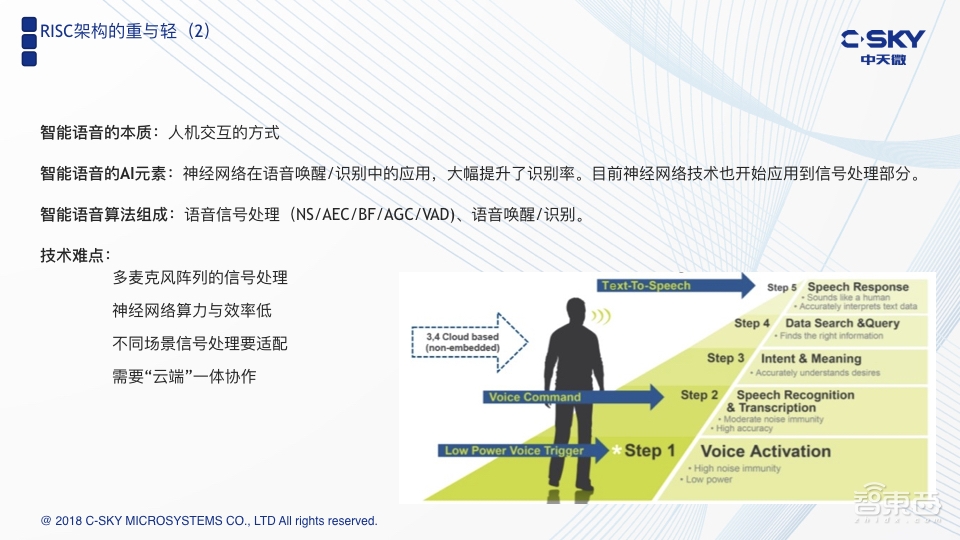
最后一个难点,它跟以往的产品有一个不同的地方,即完整的智能语音是需要云端一起来协作的。以大家非常熟悉的智能音箱为例,比如天猫精灵,当你说,“你好,天猫”这句话时,天猫精灵对这句话的识别是在设备端上解决的,并没有把这句话传到云端上,当你接下去问的问题较为复杂时,比如“我想听周杰伦的歌”,“今天天气怎么样?”这些比较复杂一点的问题,都会被传到云端,然后在云端的识别引擎上去做深度的语义识别,提取出说话者表达的真正含义,再去调动对应的服务。因此,真正完整的智能语音,一定是云端一体合作的结果。
右下角这张图阐述了真正智能语音的含义,分为四步。一般来说,第一步和第二步都会在端设备上去做,而第三步和第四步都是要放在云上去做。目前有一个很显著的问题,很多产品开发者是比较欠缺在云端联云的开发能力。
接下来我们回过头来再看刚才提的三个问题。

对于第一个问题,类似于智能音箱产品,我称之为是比较重一点的产品,由于要跑安卓或者Linux操作系统,以及大量APP,选择高性能多核是合理的,并且可以以高频换算力的方式去满足神经网络的需求。类似于故事机的低功耗低成本嵌入式产品,一般跑的是实时RTOS操作系统,而本身用的处理器是MCU级别的处理器,在这个核的基础上去升级智能语音是有可能的。但是,它的主频比较低,且强调低功耗,我认为 MCU级别的核配上NPU或者是一些专门的算法加速电路,就能提供核心性能。
第二个问题是回答存储的问题。既然我们选了一个比较轻的核,那么与之搭配的往往是SRAM/PSRAM/SDRAM这些功耗比较低,速率比、带宽也比较低的存储介质。从我们实际的算法评估上来看,当语音算法需求做到定点化之后,它的峰值带宽是可以控制在100MB/s的量级的。
第三个问题是关于图像的问题。先说智能音箱,目前有一种趋势,从去年下半年到今年上半年,已经有带屏的智能音箱产品出来,国外的Amazon和Google也有类似的产品。当产品在被人使用的过程中,会逐渐地发现在某一些的应用场景,不能仅是满足于听到。为了有更好的用户体验,还希望能够同时看到,比如购物,你可以对智能音箱说“天猫精灵,我想买一件衬衫”,但是这时你一定是希望能够看到这件衬衫的颜色以及款式,从而更好地去做判断。有了这样的场景需求,才会出现需要图像显示去平衡的要求。对于更多的嵌入式产品来说,我们认为也可以做适当的轻量化,首先我们不需要放GPU,可能只是去支持一个简单的屏显就可以了。
综合以上三点,就是所谓的“核之轻”、“存储之轻”以及“显示之轻”。这也是中天微做智能语音平台和智能语音解决方案的出发点之一。
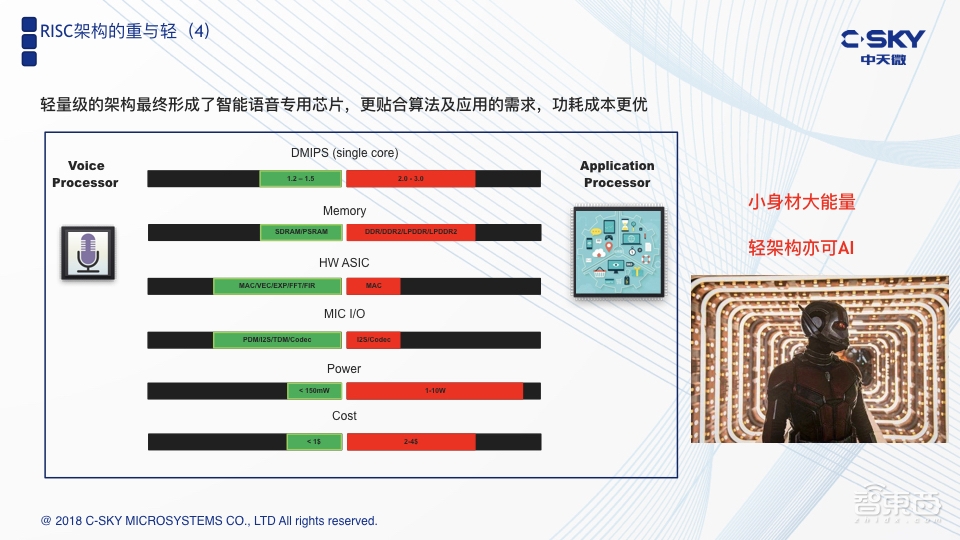
这张图是专门的智能语音芯片与传统的应用处理器之间的对比。上面也提到了,我们是用一个短流水技术的MCU级别CPU来实现的,Memory上我们用SDRAM取代DDR;在硬件加速上,为了更好地解决神经网络算力不够的问题,我们要增加不少的硬件加速,这里可以以硬件加速的方式实现,也可以以NPU的方式去实现。从本质上来讲都是为了解决同一个问题,就是神经网络的加速。
首先,神经网络中主要存在大量矩阵运算,矩阵运算就牵涉到乘累加,这恰恰又是RISC或者DSP的痛点之一。在RISC和DSP中的乘累加单元非常少,一般也就是1到2个,因此首先要增加乘累加的能力,其次是在神经网络中会用到很多的非线性函数,对于CPU或者DSP处理来说也是非常消耗资源的;
其次,信号处理部分的主要运算也集中在FFT和FIR滤波上,也完全可以用硬件去做加速;
再有,是在IO接口方面,前面也提到这是一个麦克风阵列,同时麦克风也有很多类型,必须在接口上面做充分的支持。
最后,还需要考虑是否添加Codec,从而更好地去支持麦克风阵列,传统的芯片在接口方面也是比较欠缺的。
基于以上几个特点,我们最终得到的效果主要体现在功耗上。因为本身是一个非常轻量级的架构,得到的效果就是实测结果。图上可以看到我们的动态功耗是在150mW,相比于之前的第一代和第二代芯片以及大部分第三代芯片已经是有了非常显著的提升。从成本的角度来说,也会是这些芯片的1/2。
当大家把整个智能语音的本质理解清楚之后,特别是能充分理解清楚算法的具体计算之后,你就会有信心去相信一个非常轻量级的架构,是完全能够去应对端侧的智能语音。所以称之为小身材也有大能量,即便是一个轻架构亦可以AI。
四、智能语音TURNKEY之路
接下来将为大家介绍智能语音的TURNKEY。现在我们可以先假设自己是一个产品开发者,这时你一定会烦恼很多问题,包括“怎么解决麦克风阵列问题”、“如何选择麦克风”、“需要什么算法”、“算法资源从什么地方获得”等等一系列的问题,都会让你非常的苦恼,感觉无从下手。
要把智能语音这件事情做好,离不开三方面的因素:
第一,需要一个很好的硬件载体,会涉及到芯片公司;
第二,由于核心是算法,所以又会涉及到算法公司;
第三,需要上云端操作,又会涉及到互联网公司。
只有有机地整合这三大块,你才能够真正地把智能语音做到产品化。
通过过去两年半的研发和积累,中天微想要带给大家的是一套解决方案,我们称这个平台为“云音”。我们希望它以一站式的方式,让大家以最快速度为自己的产品赋予智能语音交互的能力。“云音”包含了CPU、芯片、算法以及上云的所有配套开发工具。通过这样的方式,搭配麦克风阵列和无线连接,你就可以非常快速地搭建出一整套智能语音产品。
对于“云音”平台,我们定位为以下三点:
第一,它是为服务于我们自己的CPU研发而开发的。正是由于发现了这个问题的本质,我们才推出了CK805这样一个混合型的CPU,而这个平台就是我们CPU在人工智能领域生态的拓展之一;
第二,它是一个非常完整的云端一体的解决方案,重点面向的是低功耗设备,这主要是因为我们技术路线上选择的是一个轻量级的架构;
第三,我引用了马总提到的一个概念,叫做“普惠”,我们希望提供给业界合作伙伴的是一种普惠的智能语音解决方案。

最后这张图是实际成果的展示。现阶段我们也能提供一套完整的开发套件给大家,包含芯片以及麦克风模组等整个开发的平台。同时,我们也非常有勇气展示给大家我们实验室中实测的数据。这是在跑双麦算法时,它实际的运行功耗是166毫瓦。通过这些,我们想要证明利用轻量级的RISC架构实现端测的智能语音应用是完全可行的。
在这里总结一下我个人做了两年半的心得。现在很多人试图去混淆智能语音的概念,他们认为智能语音本身没有那么复杂,比如可能认为在芯片上通过提升频率和提升整个处理单元的主频,就可以把语音算法集成进去,并快速地形成一个产品。我个人对这样的方式是持保留态度的,这就显示出你并没有真正地去读懂智能语音这件事情。实际上,智能语音中涉及到的一些算法和计算,是值得用一个专用的方式去解决的,而不是仅仅使用非常简单的一种插件的方式就能够被赋予到已有的产品中。对于判断最终语音交互的方式非常简单,就是人的直接感受。人感受的好与坏,直接能够决定这个产品的成功与否,因此简单地在已有的东西上去增加语音算法,并不是一个很好的解决方案。
往期课件
「智东西公开课」专注于新兴技术应用案例讲解,旗下有「超级公开课」和「主题系列课」两条产品线。
「主题系列课」已经陆续推出「智能家居系列课」、「自动驾驶系列课」和「AI芯片系列课」;
「超级公开课」侧重邀请在全行业或者垂直领域有巨大影响力的大公司、上市公司或独角兽进行专场讲解,目前已先后推出大疆、亚马逊、NVIDIA、优必选、京东、海尔、中天微、IBM、腾讯共计22场企业专场讲解。
如需获取往期课件,可以扫描下方二维码关注”智东西公开课“服务号,回复“课件”自行选择下载。

