








本文根据云天励飞处理器架构总监李炜在智东西公开课推出的《面向AI的ASIP处理器设计》上的系统讲解整理而来。本期讲解是AI芯片系列课第二季第一讲。
本次讲解中,李炜老师首先从性能、能耗、复杂度、灵活性四个方面,详细介绍了GPU、DSP、ASIC以及ASIP等几种不同类型的CNN IP方案。ASIP作为 CNN IP新“门类”,是针对某种特定的运算或者某类算法的定制,具有高性能、高灵活度、低功耗、低复杂度的特点。
此外,结合云天励飞ASIP处理器,李炜老师还从算法需求分析、软硬件切割、架构定义、指令集定义、指令集模拟器开发、ISS仿真&架构迭代优化等方面,系统讲解了ASIP处理器架构的设计流程,以及设计过程中RTL开发、验证、后端物理实现等难点和注意事项。
精华整理
李炜:大家好,我是云天励飞处理器架构总监李炜,目前主要从事针对AI处理器的架构以及微架构设计等方面的工作。今天分享的主题是《面向AI的ASIP处理器设计》,主要包括以下5个部分:
1. AI背景介绍;
2. CNN的IP方案介绍;
3. AI ASIP处理器架构设计;
4. AI ASIP处理器实现难点;
5. AI ASIP处理器配套工具链。
过去几年,深度学习在视觉识别、语音识别以及自然语言处理等方面都表现得非常出色。在不同类型的深度学习神经网络中,CNN卷积神经网络是得到最深入研究的神经网络,它由很多层组成,主要包括:
1. 卷积层(Convolutional layer),用来提取不同的特征值;
2. 池化层(Pooling layer),主要对输入的特征图进行压缩,使特征图变小,从而简化计算。另一方面能够进行特征的压缩,取特定区域的最大、最小或者平均值,从而得到新的维度、较小的特征。
3. 线性整流层(ReLU layer),主要是引入非线性。由于现实世界中的很多东西都是非线性的,因此引入非线性后,就可以逼近任何函数;
4. 全连接层(Fully-Connected layer),把所有的局部特征变成全局特征,用来计算最后每一类的得分。
除了这些层之外,卷积神经网络还包括很多其他的运算。CNN的网络结构也有很多种,常见的包括GoogleNet、AlexNet、VGG16、DensNet以及MobileNet等。这些网络都有着不同的结构,每一层所需要的运算也有所不同,并且每种网络的层数以及需要支持的各种操作也是不太一样的。
CNN的IP方案介绍
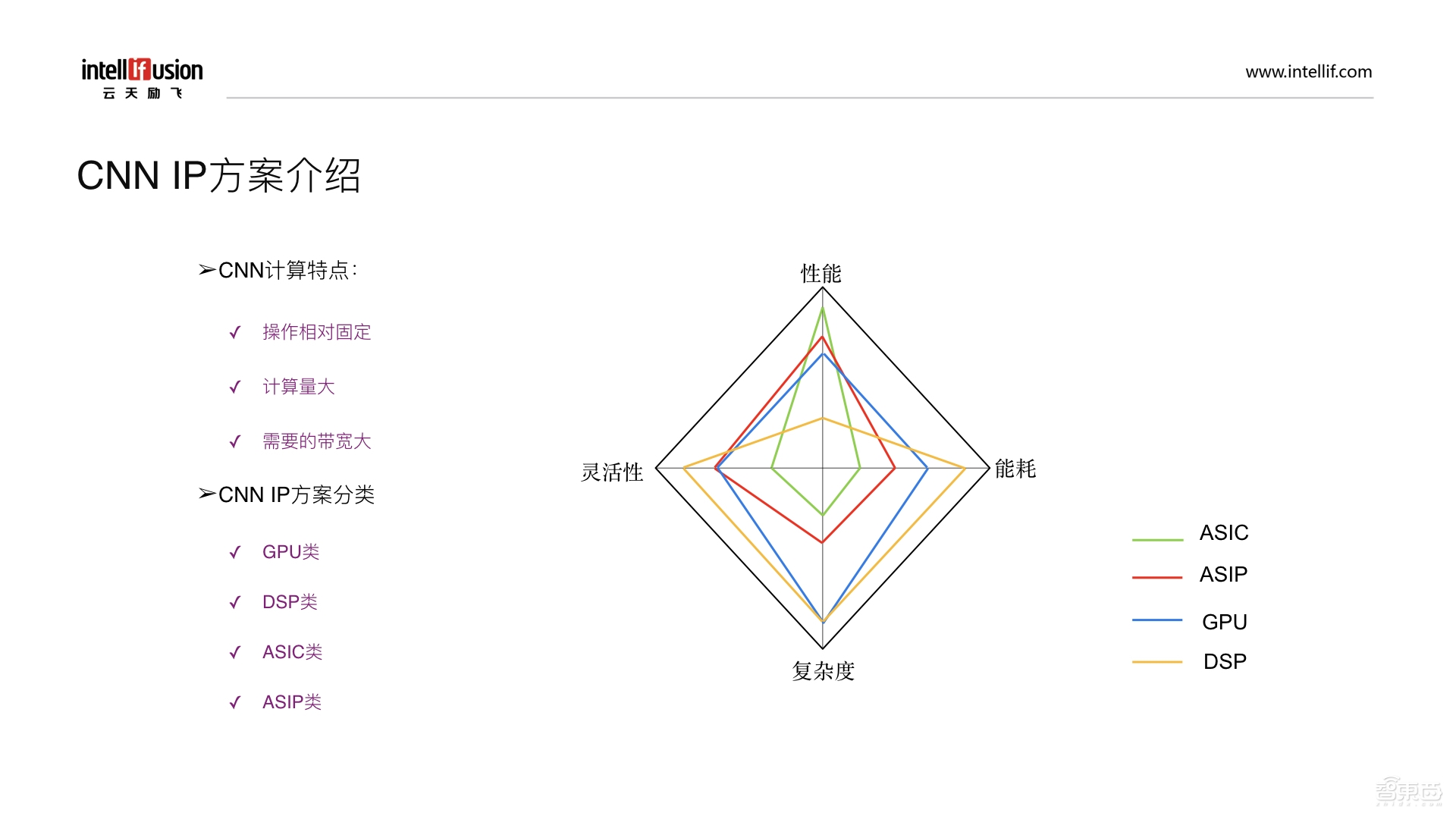
CNN计算具有操作相对固定、计算量大、需要的带宽大三个特点。目前CNN IP方案可以分为GPU类方案、DSP类方案、ASIC类方案以及ASIP类方案几种。ASIP是指针对某种特定的应用或者算法来定制的处理器。
右边这张图展示了各种方案在各个方面的特点比较,主要包括性能、能耗、复杂度以及灵活性四个方面。
首先,在性能方面,ASIC的性能是最高的,因为它是专门实现某类定制的电路算法。ASIP也是针对某种特定的运算或者是根据某类算法来定制的。它的性能要比ASIC要低一些,因为ASIP还涉及到软件编程的问题,因此它的性能要比ASIC低;接下来是GPU,性能最低的是DSP,因为DSP要通过软件编程实现所有层的计算,因此它的性能是最低的。
第二,在能耗方面,DSP的能耗是最高的,因为DSP的所有计算过程都要通过软件来实现。其次是GPU,GPU的大部分计算也是通过软件编程来实现的,因此能耗也是比较高的;再往下是ASIP,虽然它也涉及到一些指令编程,但它却做了很多定制的操作和处理,因此我们认为ASIP的能耗要比DSP低。能耗最低的是ASIC,因为它完全不需要编程,所有控制都是通过硬件状态机来控制的,因此它的能耗是最小的。
第三,在灵活性方面,我们认为能够通过软件编程来实现的架构灵活性就高,因此DSP的灵活性是最高的,其次是ASIP和GPU,灵活性最差是ASIC。
第四,复杂度方面,这里所说的复杂度不仅仅是指硬件,还有配套的工具链以及软件的复杂度,因此,我认为复杂度从高到低依次是DSP、 GPU、 ASIP和 ASIC。从硬件上来说,ASIC的控制复杂度要稍高一点,因为它是通过硬件状态机来实现的。但是从软件的角度来看,ASIC不需要软件编程,而软件只需要通过一些配置寄存器就可以了。因此综合来讲,ASIC的复杂性是最低的。
接下来跟大家介绍下各类CNN IP方案,我举了一些典型的例子,大家来可以看一下各类CNN IP方案的特点。
首先是 GPU类方案,这里以NVIDIA GPU为例。 GPU的特点包括多核并行计算,且核心数非常多,能够支撑大量数据的并行运算,并且拥有更高的访存速度和浮点运算能力。这些特点决定了GPU在深度学习领域,特别是训练方面也是非常合适的。不光是训练方面,在云端推理等可能需要计算量比较大的地方,GPU也是比较合适的。另外,NVIDIA GPU提供了比较完整的工具包,适用于现在所有主流的深度学习框架,比如对TensorFlow、Caffe等深度学习框架的支持都是比较好的。同时,NVIDIA GPU通过PCI-e接口可以直接部署在服务器中,使用起来非常方便。
接下来看一下DSP类的CNN IP方案。这里以Cadence VP6为例。DSP VP6提供的指令是比较丰富的,而且还专门针对深度学习定制了一些指令。这些深度学习定制指令主要是跑在标量和和矢量和上。标量和主要做一些程序的控制和一些简单的运算。另外,Cadence VP6还提供了一些深度学习库供大家调用,因此它是标量和加矢量和的架构。VLIW,叫作超长指令集架构,意思是在发射了一条指令后,这条指令中存在很多运算,可以把指令中不同的操作分发给各种不同的功能部件来同时运算,提高并行度。同时,Cadence VP6还是一个SIMD架构的DSP,即单指令多数据流,主要体现在它的矢量单元上。它有256个MACs,一条指令下来,它的256个MACs是一起工作的,因此它的并行性也是比较高的。

接下来是ASIC类,一个比较典型的是NVDLA,它是由NVIDIA提供的开源的深度学习平台。简单介绍一下,CSB/Interrupt interface接口是主控通过CSB来配置NVDLA中的寄存器,完成任务后,它会返回中断;DBB interface是一个memory总线接口,主要用来连接DDR; second DBB interface也是一个memory总线接口,用来连接片上SRAM。右图是NVDLA的一系列的操作单元,其中Convolution buffer用来存放Input的Feature map,Convolution core负责CONV和FC操作,Activation engine负责RELU/BN/ELTWISE等操作;Pooling engine负责POOLING操作;Local resp.norm主要负责LRN的运算,再往下是RUBIK/DMA,主要负责SPLIT/CONCAT/RESHARE等操作。

关于ASIP类,我们举两个例子。首先是寒武纪深度学习体系架构的处理器,它实际上是属于ASIP类的。ASIP是专门针对某种特定的应用或者是算法来定制的处理器。定制的处理器,自然也有自定义的指令集,它具备了ASIC的高效性和DSP的灵活性。
上面这张图简单介绍了寒武纪的硬件架构,最上面是Control Processor,可以看到有很多的虚线都是从这里出来然后发给各个单元,主要是负责给各个模块下发指令。左上角蓝颜色Nbin模块用来存储input feature map,左下角的SB模块用来存储kernel。在有了input feature map和Kernel后,就会读到它的NFU中,根据Control Processor下发的指令来做一些运算。通过NFU1、NFU2以及NFU3三级流水算出结果后会送到Buffer中,可以看到每个Buffer上有三个DMA,这些DMA主要用来搬运feature map和计算参数。
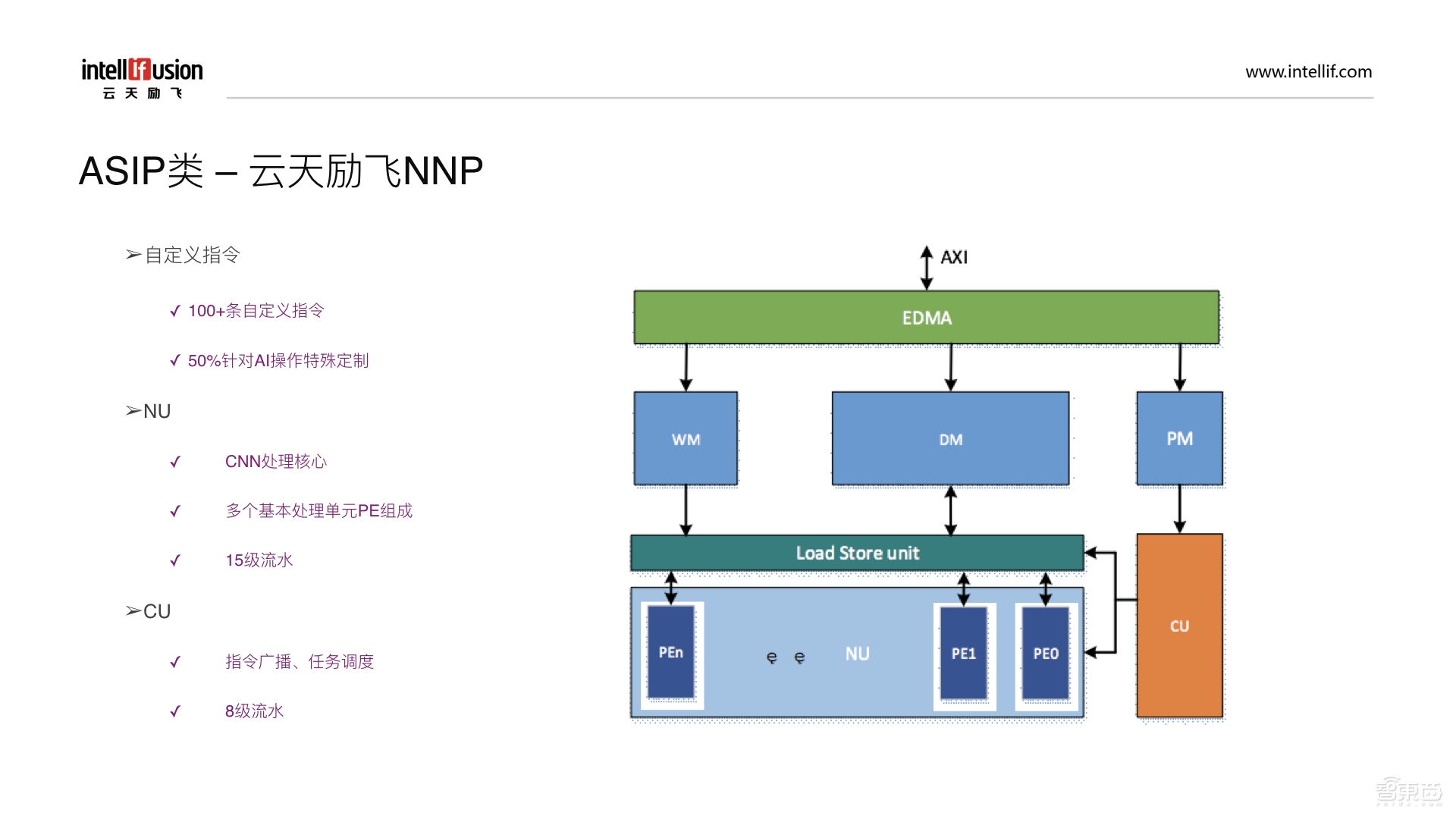
接下来介绍一下云天励飞的NNP,它也是属于ASIP类的。首先我们有一百多条自定义的指令,并且50%的操作是针对AI来特殊定制的。其中NU单元是我们CNN处理的核心,由多个基本的处理单元PE组成,同时是15级流水。同样,我们也有一个CU模块,即Control unit,和寒武纪中的Control Processor类似,用来给各个模块分发指令做任务调度,支持八级流水线。
AI ASIP处理器架构设计
接下来介绍一下面向AI ASIP处理器的架构设计流程,主要从以下几方面来介绍,分别是算法需求的分析、软硬件切割、架构定义、指令集定义、指令集模拟器开发、ISS仿真&架构迭代优化以及最后确定微架构和指令集,之后就会进入开发阶段。
需求分析,主要分为算法的需求分析和产品的需求分析两部分。AI的算法需求分析主要用来分析AI算法的基本流程,以及算法中使用的CNN模型。需要分析清楚模型中有哪些基本操作,有哪些特殊操作,这些操作是否具有通用性或者扩展性,ASIP处理器是否能够独立完成运算或需要系统中其他的模块来一起配合。产品的需求分析,主要用来确定产品的应用场景。在各种应用场景下,ASIP处理器的频率以及算力能达到多少,以及系统能提供多少带宽,在结合算法和应用后,系统需要多少带宽等等问题。在设计架构之前,必须要把这些都分析清楚才能够定义出一个比较好的ASIP处理器架构。
软硬件切割,刚才也提到,ASIP是针对特定的算法和应用定制的处理器,它兼顾了ASIC的高效性以及DSP的灵活性。ASIP也可以支持丰富的指令集,比如循环、跳转、子程序的调用指令、基本的算术运算和逻辑运算指令,还有一些专门针对CNN特殊定制的运算指令。有了这些指令,如何利用好这些基本的指令来实现软件和硬件效率的最大化是软硬件切割要考虑的问题,针对ASIP的合理的软硬件切割,可以达到事半功倍的效果。比如一些复杂的控制和状态机是可以通过ASIP指令编程来实现的。ASIP中的数据可以直接用DMA来搬运,也可以使用大颗粒度的指令来提高ASIP的编程效率以及硬件操作的效率。我们都知道,指令的颗粒度越小,编程的效率就越低,因此这对于硬件效率来说是最高的,而且对于编程也是比较友好的。
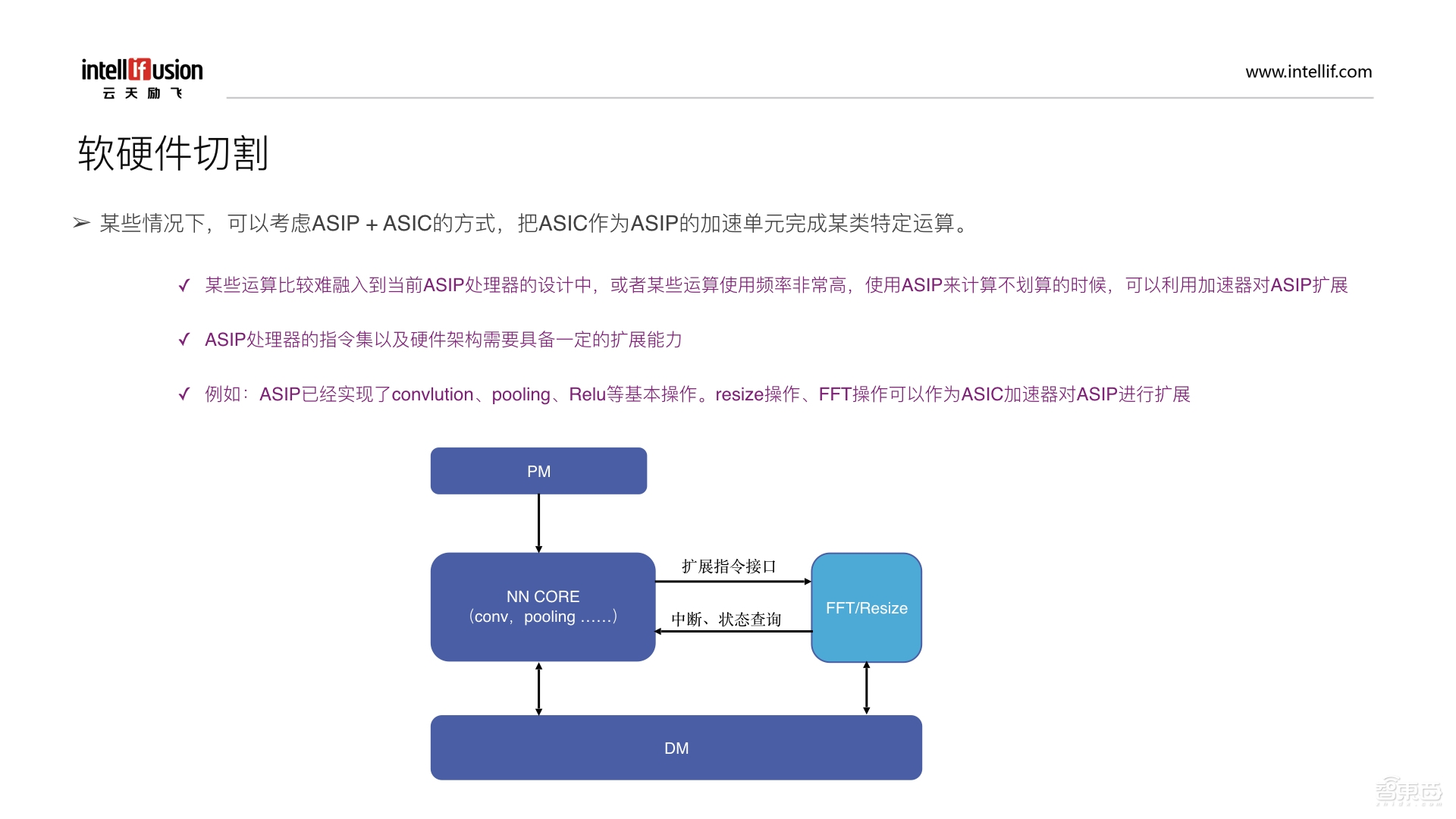
在某些情况下,我们可能要考虑采用ASIP+ASIC的方式,把ASIC作为ASIP的加速单元来完成某类特定的运算。通常来讲,如果某些运算比较难以融入到当前ASIC处理器的设计中,或者某些运算使用的频率比较高,使用ASIP来计算这些运算不划算时,就可以利用加速器对ASIP进行扩展。因此ASIP处理器的指令集以及硬件架构就需要有一定的扩展能力。比如上图,左边这部分是一个ASIP,上面是Program Memory,NN CORE可以从PM中读取指令来进行译码、convlution以及pooling等运算,最后把结果存到DM里。但有些运算可能不太适合放到NN CORE中进行,比如FFT或者resize等,这种情况下可以把FFT或者resize作为ASIC加速器对ASIP扩展的方式。因此ASIP处理器需要预留一些扩展指定接口,通过编程的方式能够驱动FFT或者resize,完成之后可以通过一些中断或者状态查询把状态反馈给NN CORE。因此,在这种情况下可以考虑利用ASIC+ASIP联合的方式来实现任务的划分。
架构定义,在软硬件切割完毕后,就可以开始定义ASIP处理器的架构了。面向AI的ASIP处理器架构设计的重点主要包括数据重用、WEIGHT重用、提高计算的并行度、提高MAC的利用率、如何减小DDR带宽、硬件扩展性、初步流水时序和后端可实现性。这些都是ASIP处理器架构设计的重点。接下来我针对其中的几点进行详细的介绍。
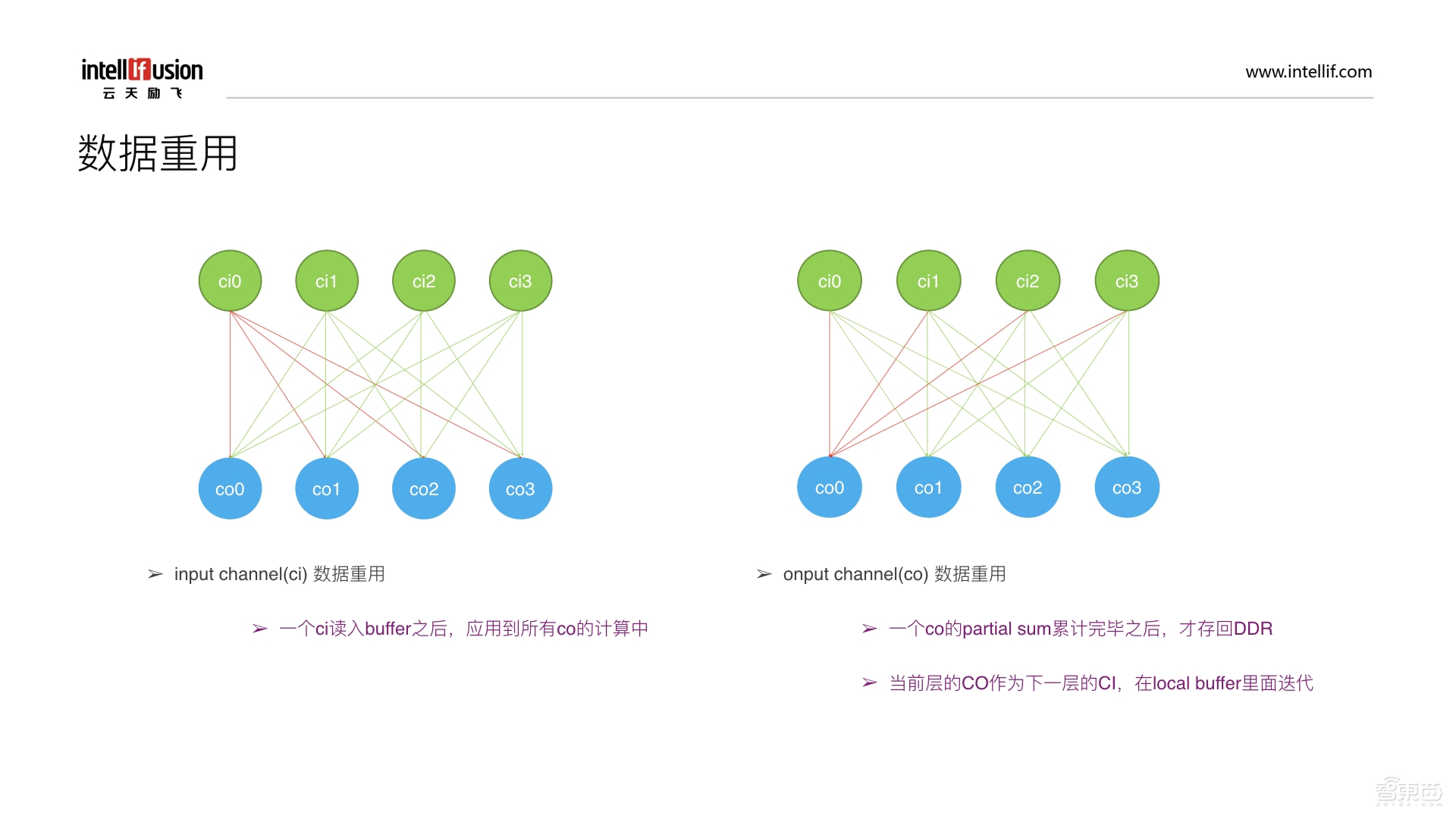
数据重用主要有两点,第一是input channel数据重用,简称Ci。一个Ci在读入buffer之后,要把它应用到所有的co计算中。如上图,ci0可以把它读入到buffer中,在co中计算有个好处,就是数据只需要读一遍,而不是每次都重复读取,直至用完丢掉即可。从而把数据充分的复用起来,减少带宽输出,提高计算效率,增加MAC的利用率。第二是output channel(co)的数据重用,在上图右边,每一个ci对co的连线都算是一个partical sum,在这种情况下,算完一个partical sum后,数据将存到内部的buffer中,而不是立刻存回DDR,需要等所有的ci把co都扫一遍,算出所有的partical sum并累加完毕后,才存回DDR。这样既能减少的带宽,也是提高MAC的利用率的一种方式。
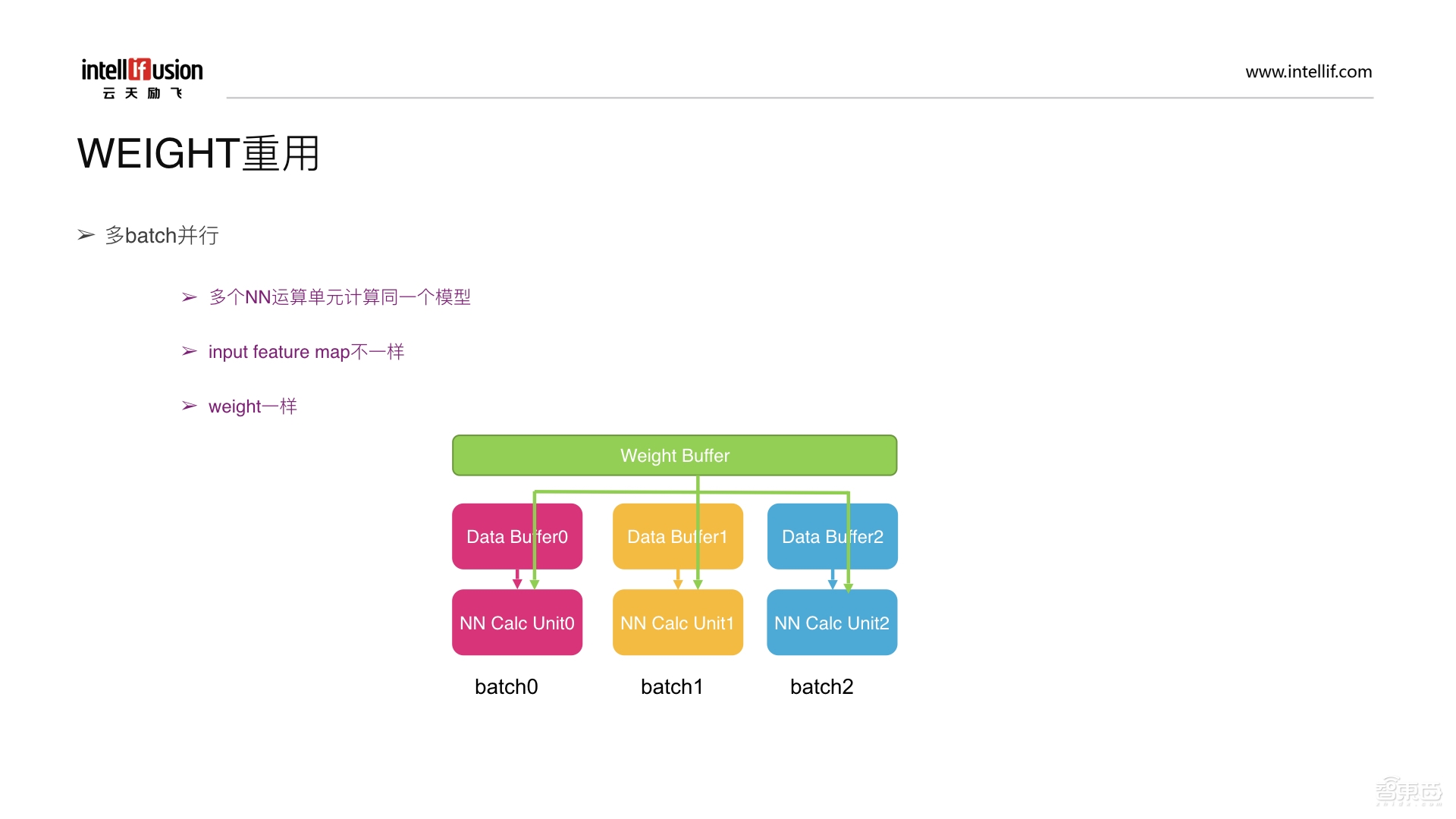
WEIGHT重用主要体现在多batch并行上。即多个NN运算单元计算同一个模型,但input feature map是不一样的,而weight是一样的。比如做人脸识别时可以同时计算多张人脸,所用的所有模型以及所用的weight都是一样的,而输入的每张人脸是不一样的。在上图中,上面的Weight Buffer从DDR中读取数据后,会把任务分发到各个计算单元中,每个计算单元都有它对应的Buffer,即Weight实际上是复用的,而多个NN计算单元输入数据是不一样的。

计算并行度,我们可以考虑同时计算多个co,同时计算多个output chaneel来提高计算并行度的。从另外一方面来考虑,可以同时计算一个co的不同的Partical sum并累加起来,也能够提高它的并行度的。还可以考虑对神经神经网络模型进行剪枝,对模型进行剪枝实际上是跳零(Skip zero),对模型剪枝后,这个模型就变小了,也就是能同时计算更多有效的运算,因为跳零的那些不需要再计算了。左边的第一张图是全连接的方式,第二张图是Ci Skip/ CO Skip,是指通过剪枝发现某个Ci所有关联的都是零,裁剪后,跳零的地方就不需要计算了,从而更加充分有效地利用MAC资源,也可以提高计算的并行度。除此之外,还可以考虑另一种方式,如最后一张图,并不是把Ci全都抠掉,只是Ci的某几条线可能不需要,对于kernel完全是零的这些运算也不需要进行计算。Ci1最左边和Ci3最右边这条线对应的kernel也是零,因此对应的co0和co2的运算也不需要了,这样通过卷积后,如果再有一套有效的方法能够把kernel全都跳过去,那么就能够充分地利用MAC资源以提高计算的并行度。
DDR带宽是ASIP处理器设计中一个非常重要的指标。有效的数据复用和Weight复用能够降低DDR对带宽的需求。刚才也提到,把数据和Weight重用起来,就不用从DDR重复读取数据,从而降低DDR对带宽的需求。另外,数据压缩也能够减少DDR对带宽的需求,经过Relu计算后,feature map里面会存在很多0值,在这种情况下,可以考虑对feature map进行压缩,这也是比较有效地降低DDR对带宽的需求的一种方式。
MAC利用率,关于处理器“能达到多少算力”,“有多少T的算力”或者“有多少G的算力”,这些都是比较虚的。抛开IO来谈MAC利用率或者算力是没有任何意义的。单纯的堆叠MAC是没有用的,IO得跟得上,MAC才能充分地利用起来,因此,IO是瓶颈。MAC单独对接MAC基本是没有什么用的,因此要想要提高MAC利用率,还是得考虑如何降低DDR的带宽。另外,数据重用、Weightt重用,降低DDR带宽、提高计算并行度都是为了提高MAC利用率。
指令集的定义,通常面向AI的ASIP指令集定义有两类指令,一类是循环、跳转、基本的算术逻辑运算等基本指令,用于控制和NN CORE调度;另一类指令是NN指令,专门用于CNN计算。在定义指令集时,要考虑指令及指令集的规整性和可扩展性,同一类指令的编码要放到一起。在规划各个指令集的比特域时,要充分考虑它的扩展性,要留有一定的余量。另外还要考虑指令的颗粒度,主要包括大颗粒度的指令和小颗粒度的指令。对于大颗粒的指令,例如定义了一条convolution指令,一条指令就能执行成千上万个cycle,这种指令的特点是效率比较高,编程也比较简洁。小颗粒度的指令是指通过更小的操作来拼成一个大的操作,比如要完成convolution指令的操作,可以通过乘法指令和加法指令编程来完成,它的特点是比较灵活,但这对编程会有一定的要求,而且功耗会大一些。
指令集模拟器(Instruction Set Simulator,ISS)是利用高级语言来编写的ASIP处理器模型,可以用python或者C++来写。这个模型可用在ASIP处理器架构设计阶段,是对处理器架构的性能仿真的工具,并且在后面可以用于RTL验证作为软件开发的参考模型。在ISS开发时,需要注意以下几点:
第一, ISS中一些重要的参数要能够灵活可配置,例如,Memory大小、Buffer大小、MAC个数以及DDR带宽等,这些都需要能够灵活配置;
第二, 要能够提供丰富的profiling能力,比如需要看到MAC的利用率、Buffer或者MAC是否饥饿,这样才能够确定出参数的最优配置,从而定好架构;
第三,ISS要能够基本反映出硬件真实的性能,以免前功尽弃。
指令集模拟器开发主要有两类:
第一, 行为模型(behavior model),只是模拟处理器的行为,并没有时序概念。这种模型主要用于ASIP处理器架构设计阶段,用于快速建模,主要是为了对处理器的架构进行评估以及调整,也可以作为后续RTL验证的参考模型。
第二, cycle accurate model,每个cycle都能够和RTL比对上,它是有时序概念的。基本上每个cycle都能和硬件完全比对得上。也就是说、它跑出来的结果和硬件跑出来的结果基本没有什么差别,这个模型主要是作为后续软件开发的参考模型,能够反映软件开发在ASIP处理器上运行的真实情况。
完成指令集模拟器开发之后,就可以做一些ISS仿真以及后续架构的优化迭代,主要有两个工作。首先是选择Benchmark,对于AI处理器来说,当前基本上没有通用的Benchmark。阿里最近发布了用于AI处理器的Benchmark—— AI Matrix。而对于AI ASIP来说,需要针对特定的应用和特定算法来定制开发自己的Benchmark。除此之外,也需要兼顾一些通用的CNN模型性能,但是就目前而言,Benchmark是需要我们自己来开发的。另外,开发好Benchmark之后,就可以利用Benchmark来进行一些ISS的架构仿真,并进行迭代。同时也要考虑定义的指令集是否完备,是否过设计,是否便于编程。通过Pooling的结果可以确认Memory和Buffer size多大比较合适,每种Benchmark下的MAC利用率,最常用的操作是否足够高效,是否还需要优化,以及频率、算力、带宽是否已经达到需求指标等,这些指标,都可以通过对Benchmark的仿真进行确认。完成这些后,基本上就能把架构确定下来了。定好架构,就能够确定指令集以及各个模块的微架构了,接下来就可以进入到真正的开发阶段。
AI ASIP处理器实现难点
接下里跟大家介绍下ASIP处理器在开发阶段中实现的难点。主要分为三个部分:
第一、在ASIP处理器RTL开发过程中的注意事项;
第二、ASIP处理器在验证过程中的难点;
第三、AI ASIP处理器后端在物理实现时的难点。
先看一下开发过程中需要注意的事项:
第一是时序,需要合理地切割流水线,以保证每一级流水时序的平衡;合理的Memory切割,以保证Memory的读写时序,同时只能慢慢地快速,不能太多,因为快速越多会对后端有影响;还要有良好的cording style。
第二是功耗,功耗主要是看Memory的划分是否合理,在不读写时把时钟关掉。同时有些Memory具有低功耗控制端口,也可以把这些利用起来做控制。clock gating工具可以自动插入或手动插入控制整个模块的clock,使clock上的功耗尽可能降低。data gating用来防止不使用的模块或者组合逻辑输入数据的翻转。
第三需要与后端进行密切的迭代,因为面向AI的ASIP处理器的计算资源比较多,包含上千个MAC,走线也是比较复杂的。这种情况下,通常我们都会遇到一些问题,如果一直到后端真正布局和布线时才发现这些问题可能就比较晚了。因此,在RTL开发过程中或者在架构设计时就需要提前来考虑这些问题,包括Memory size, Memory的块数也会直接影响到后端的floorplan、走线、DFT等。因此,ASIP处理器在RTL开发初期甚至是微架构设计时就要与后端建立良好的沟通机制,充分考虑后端的实现。
处理器的设计还需要充分考虑有效的debug机制。Debug机制分为侵入式和非侵入式两类。侵入式是指设置一个断点,当程序跑到断点处就停下来,可以单步执行或者是执行一些continue、step等指令,这些是最基本的调试指令,也可以通过JTAG来访问内部Memory以及内部寄存器,相当于会打断处理器的执行;非侵入式是指通过建立有效的trace机制,记录处理器正常运行期间发生的事件以及状态,相当于它不打断处理器的执行,通过有效的trace机制把一些需要的信息收集起来,并存成一个log,便于我们分析log进行debug。还要设计合理的profile机制,通过收集处理器运行过程中各种应用场景以及算法下的性能、宽带等信息,以便对软硬件进行优化,这是非常有用的。
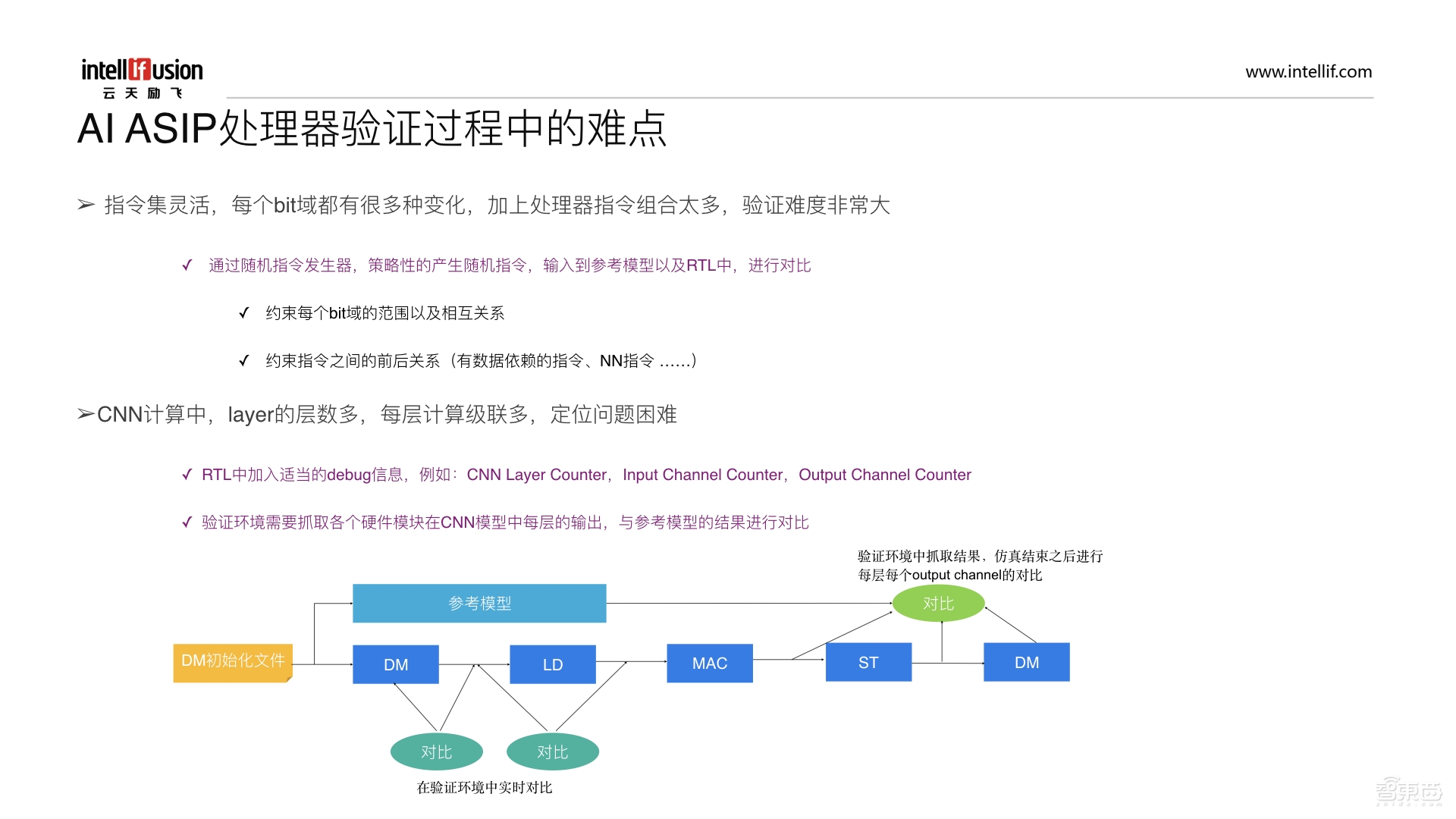
接下来介绍AI ASIP处理器验证过程中的难点。ASIP指令集非常灵活,支持各种各样的指令,每个bit域都有很多种变化,再加上处理器的指令组合比较多,因此验证难度非常大。通常的做法是通过随机指令发生器,策略性的产生随机指令,输入到参考模型以及RTL中进行对比。在产生随机指令时,要约束每条指令的bit域的范围以及相互之间的关系。另外,还需要考虑约束指令之间的前后关系,包括有数据依赖的指令、NN指令等。主要是因为行为级的参考模型是没有时序概念的,如果把这两条指令都放到参考模型中运行,最后一定会有一条先跑出来。
假如没有考虑数据依赖,可能会造成这两条指令运行出来的结果对不上的问题。为了防止这种情况发生,需要对于有数据依赖的指令进行特殊考虑。在CNN计算中,layer层数比较多,每层的计算级联也比较多,主要是由于计算一个CO需要用到多个CI的数据,进行partical sum并累加,这就可能造成定位非常困难的问题。因此需要在RTL中加入适当的debug信息,比如当运行到CNN层时加入CNN layer Counter或者Input Channel Counter。
在验证环境中需要抓取各个硬件模块在CNN模型中每层的输出,与参考模型的结果进行对比。如上图所示,在验证环境中,我们需要把一个文件初始化到Data Memory中,同时将DM初始化文件传给参考模型,参考模型会运行出一个结果,底下通过Convolution得出另一个结果。为了定位方便,需要对各个模块的输出进行对比,通过DM的结果与DM的原始数据,以及从LD单元的输入与输出都需要在验证环境中进行实时的对比,MAC计算完后的结果也需要与存入有右边DM之前以及存入到DM之后的结果进行对比。在验证环境中抓取结果,仿真结束后与参考模型追踪结果来比对。通过比对,就能知道出错的具体位置,从而帮助我们解决快速定位的问题。
接下来介绍AI ASIP处理器在物理实现上的难点及解决方案。主要包括以下几方面:
1、Memory size如果过大,可能会导致Memory timing有问题;
2、Memory碎片化严重,这会导致Floorplan、功耗、DFT等各种问题;
3、CNN计算的特点是计算比较密集的,这种计算比较密集的硬件有可能导致功耗和IR DROP等等各种问题;
4、由于MAC数较多,有可能会导致连线的异常复杂,从而导致congestion问题。
针对上面这些难点,也有相应的解决方法。针对Memory size过大的问题,可以通过Memory切割来缓解部分timing问题,切割只是一个后面的方法,要从根本上解决,还是要从架构上着手,在架构设计阶段就要考虑这个问题。同时前端要尽量避免有很多小块的Memory设计,并且要做好低功耗设计,控制clock 、Memory、计算单元的功耗,后端可以优化Power Mesh策略,后端的Floorplan可以按照数据流来摆放,这样能够缓解congestion的问题,这些都是解决后端所遇到的难点的方法。
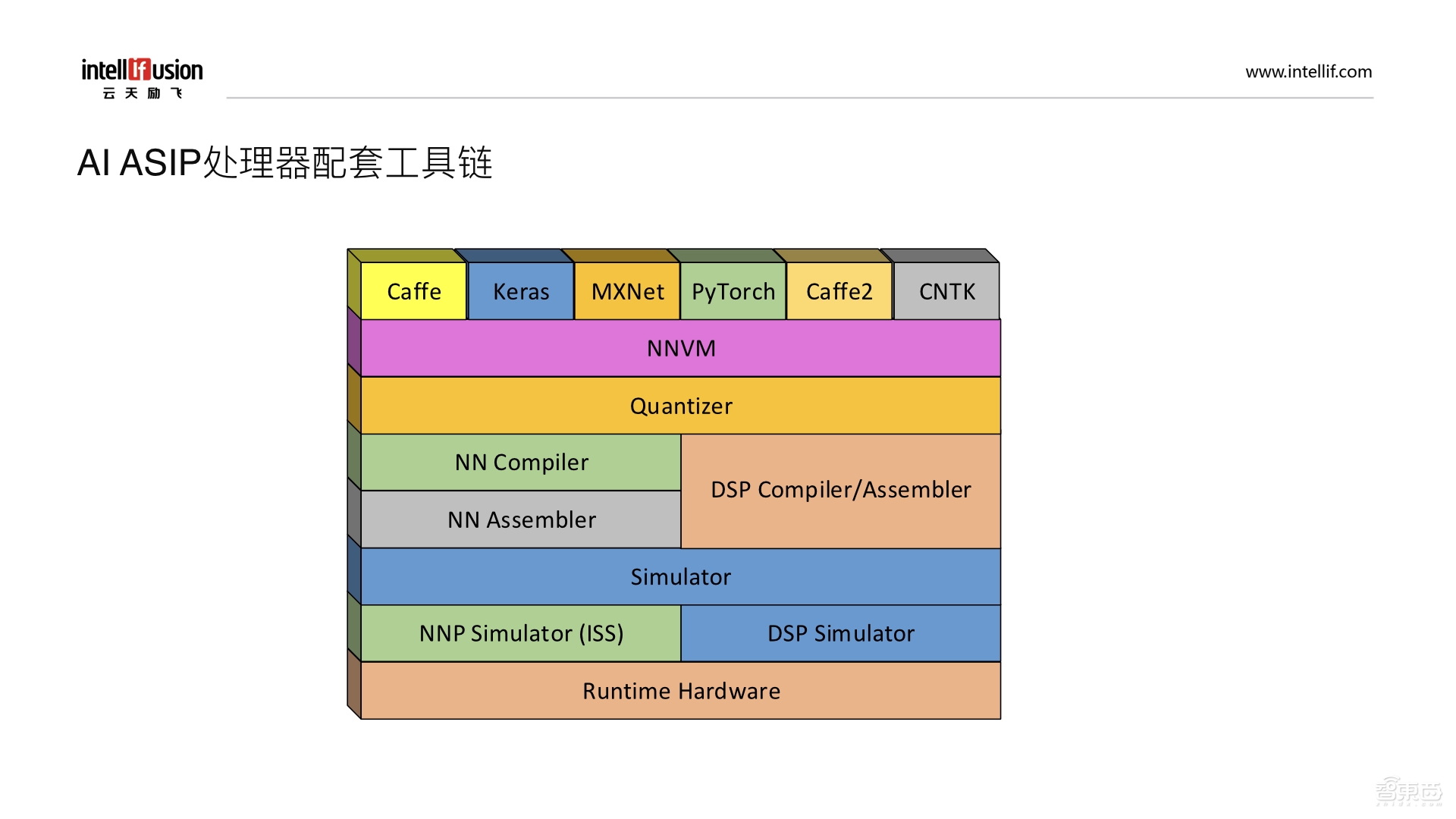
最后简单介绍一下AI ASIP处理器的配套工具链。最上层是通用的一些深度学习框架,下一层是一个中间件NNVM,作用是在通用框架下面写好一些模型和程序,然后映射到不同的硬件架构上。NNVM接下来需要进行量化(Quantizer),量化之后,有一部分工作可以映射到我们自研的NN处理器上,这时就需要有一个NN Compiler。NN Compiler用于实现高级语言到汇编语言之间的转换,接下来通过NN汇编器(NN Assembler)来实现汇编语言到机器码之间的转换。DSP也同样有一个Compiler和汇编器Assembler;再往下一层是Simulator,可以通过ISS来做性能的仿真和作为软件的参考模型,Simulator也分为NN Simulator和DSP Simulator两部分,底层就是硬件单元。
