








智东西(公众号:zhidxcom)
文 | 寓扬
3月15日,由智东西主办,AWE和极果联合主办的AI芯片创新峰会,在上海成功举办!本次峰会报名参会的观众覆盖了近4500家企业,到会观众极为专业,其中总监以上级别占比超过62%,现场实际到会人数超过1800位。
大会现场,20位人工智能及AI芯片业界翘楚共聚一堂,系统的探讨了AI芯片在架构创新、生态构建、场景落地等方面的技术前景和产业趋势。

▲百度主任架构师欧阳剑
作为AI芯片的积极布局者与应用者,百度在2018年7月发布AI云端芯片“昆仑”,备受行业关注。作为百度主任架构师,欧阳剑带来主题为《百度昆仑让计算更智能》的演讲。
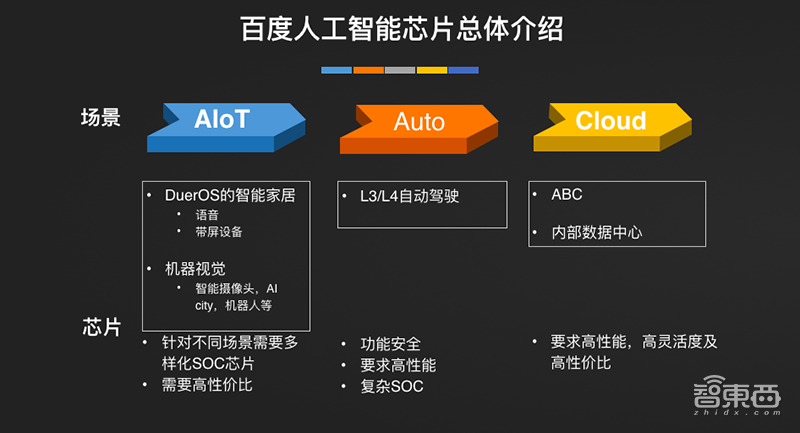
他从百度自身的业务需求和实践经历谈道,百度内部有非常多的应用场景,包括AIoT、自动驾驶、智能云等,不同场景对芯片的需求不同,这就意味着要走普适AI计算的道路。而通用灵活性、计算能力、能耗效率是普适AI计算的三大挑战。
百度在过去7、8年时间里已经做了很多AI架构的积累,最早在2010年就开始用FPGA做AI架构的研发,2011年开展小规模部署上线,2015年打破几千片的部署规模,2017年部署超过了10000片FPGA,百度内部数据中心、自动驾驶系统等都在大规模使用。
而FPGA之后,专用芯片是继续提升计算性能的必由之路。百度选择自研AI芯片,并于2018年发布了百度“昆仑”,它采用三星14m工艺的芯片,有很高的内存带宽,算力更是达到260Tops。
欧阳剑称,这个芯片是非常通用非常灵活的,芯片既可以做训练也可以做推理,XPU的功能架构也在百度内部很多应用中得到验证,相对而言,它是一款全功能的AI芯片。今年“昆仑”会在百度内部大规模使用。
附百度主任架构师欧阳剑演讲实录
欧阳剑:各位朋友,早上好!我叫欧阳剑,是百度的主任架构师,感谢智东西的邀请,今天有机会跟大家分享一下过去好多年我们关于AI处理器、芯片的工作。题目是“让计算更智能”,这也是我们的使命,通过芯片来解决问题。
大家都知道人工智能的发展离不开三要素:优秀算法、海量数据、超强计算。我们都知道计算是人工智能很重要的动力,过去很多年百度在计算方面做了很多工作,包括最早大规模部署了GPU、FPGA以及大规模开展AI芯片的工作。
人工智能正在变成非常“普适”的计算,从数据中心拓展到边到端。像在自动驾驶领域,不能把数据只放在云上,也不能把计算只放在云上,智慧家居、智慧交通、智慧城市一样如此。
过去的计算模式是有一个集群,几万台机器,所有的机器、计算都放在那里,尽管今天DataCenter的计算仍然很重要,但现在已经从DataCenter拓展到端,拓展到边缘的地方,这是在新计算模式下对芯片架构、计算架构提出的不一样的挑战。
既然今天是普适AI计算的时代,挑战在于通用灵活性、计算能力、能耗效率三方面达到非常好的平衡,任何一点不好,你的架构就只能用在某一场景,而非用在普适AI的计算上。把这三点做好以后,架构可以用在智能云、智能驾驶、智慧交通、智能家居以及百度内部搜索、Feed流等很多场景上。百度有多样化的场景,驱动着我们做芯片架构的时候做出普适AI芯片的架构。
“昆仑”的使命是让“计算更加智能”,解决三个问题:1.高计算能力;2.高能耗效率;3.高灵活通用。高计算能力就是人工智能发展的驱动力;高能耗效率不论在数据中心、边、端都是永恒关注的问题;同时人工智能算法在快速迭代,一定要保持芯片架构系统有非常高的灵活性和通用性,否则会“拖后腿”。
接下来我会给大家讲一下三点:第一百度人工智能大业务介绍;第二百度人工智能芯片架构的积累和迭代;第三总结。
百度的业务包括云和端,像智慧家居、智能驾驶、云等,有两个系统:1.百度大脑,为业务提供了强有力的算法、数据支持;2.百度智能云ABC Cloud为业务提供了强大的云服务、计算服务。
跟大家分享一下人工智能芯片的介绍,去年百度在开发者大会上分享了“昆仑”芯片,但实际上百度在过去7、8年时间里已经做了很多AI架构的积累。百度有很多场景,包括AIoT、自动驾驶、智能云,在这样的场景下对芯片的需求是不一样的。AIoT场景要求非常低功耗、场景分散零碎、芯片需要性价比高;汽车场景要求安全、高性能、复杂SoC;云要求非常高性能以及高灵活度、高性价比。这是做普适AI芯片架构需要面临非常大的挑战。
根据过去几年总结出来的经验来看,大家都知道“摩尔定律”是一年半性能上一倍、成本下一倍,现在处理器的发展速度大家都在说像“挤牙膏”,每一年只提高10%或者20%,但AI时代的摩尔定律非常高,基本每两年就有量子级的提高要求,包括数据的提高、模型复杂度的提高。
面临这么大的鸿沟,专用处理器是必经之路,过去很多年百度在探索一条适合百度发展的AI处理器之路。2011年左右在做基于FPGA的架构处理器器,Google和百度在同一时间投入AI架构器的研究,只不过大家的选择路径不一样,我们选择的是AI FPGA的方案,但在架构积累方面有很多共同的地方。基本上在2013年FPGA实现了性能AI处理器,2017年达到10 tops性能的AI处理器。2018年发布了百度的“昆仑”,性能一下达到了260,比之前工作效率提高30倍。
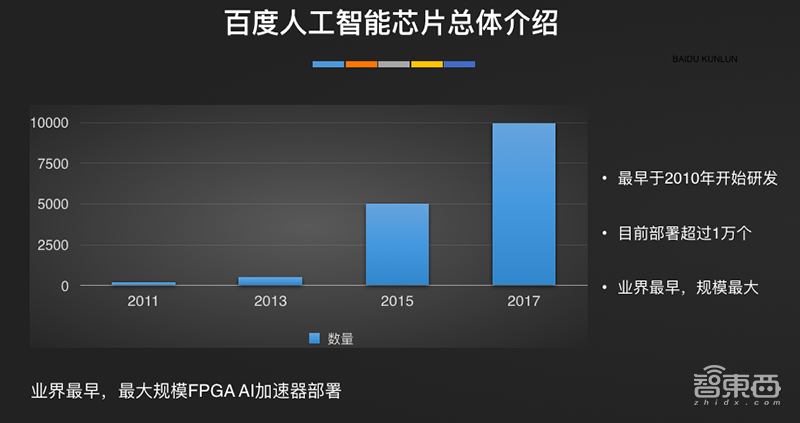
百度是业界最早、规模最大用FPGA来做AI架构的公司,最早在2010年就开始研发,2011年开展小规模部署上线,2015年打破几千片的部署规模,2017年部署超过了10000片FPGA,百度内部数据中心、自动驾驶系统等都在大规模使用。
百度跟Google都在2010、2011年的时候做AI处理器的研究和探索,尽管最开始选择的路径和Google不一样,但在架构探索、架构理解上是异曲同工。百度作为互联网公司在Hot Chips大会上发表过3篇论文,是国内在发表论文最多的单位。
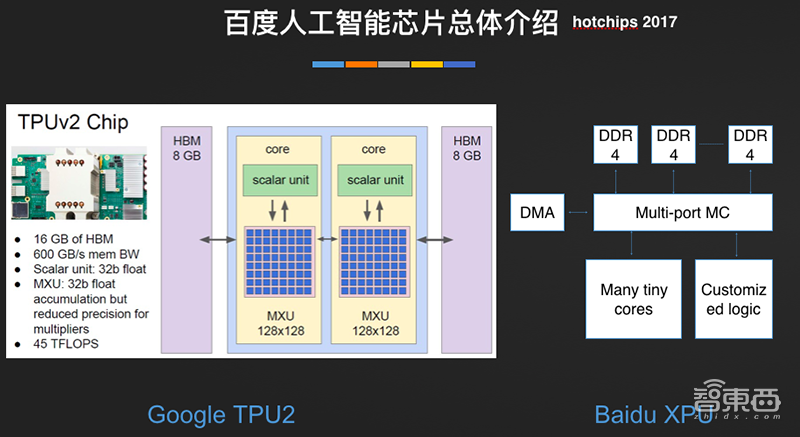
百度跟Google的工作有些相似的地方,2014年提出了“SDA加速器”的概念(软件定义的加速器),这也是比较常用的概念。加速器的架构跟Google TPU V1上所讲的架构是比较相象,固定流水线,每一级都把任务固定好。在百度的架构里会有一些数据缓存来提高数据的复用,会有比较大的计算阵列,也是大家常用的方法。
GoogleTPU的架构和我们差不多,有很大的片内Buffer来缓存数据,提高数据的复用,有很大的计算阵列,这是非常固定的流水线架构,很经典的方法。这个架构对训练、多样化端的场景远远不够,因为缺点就是通用性、灵活性不够。
2017年提出了XPU的架构,这个架构不一样地方是极大地提高了编程的灵活性和通用性,分成两部分,一部分是Customized Logic,其实就是可编程的编列加上可编程的向量计算。同时还增加了Many tiny cores,这是保持非常好编辑性的处理器,结合可以解决越来越复杂的需求。Google在2017年也分享了TPU2的架构,架构和XPU的架构也有很多异曲同工的地方,有M层很大的编列,这就是变量计算的小处理器。基本上XPU以及TPU2的理解都是类似的。XPU架构有很好的通用性、灵活性、高性能,在百度内部会用在智能云、自动驾驶、AIoT等,证明在不同场景下都做的很好。
2017年底2018年初我们觉得要走上另一条路,要做芯片,出发点大家都能想的到,因为做FPGA的AI计算也做的不错,但我们想再提高量级怎么做?就是做芯片。
“昆仑”芯片是三星14m工艺的芯片,有很高的内存带宽,达到了260tops性能,这个芯片是非常通用非常灵活的,芯片既可以做训练也可以做推理。这是全功能的AI芯片,因为XPU的功能架构真正在内部很多应用里都得到验证,在线上部署过,包括图像、语音、自然语言处理、自动驾驶、推荐等,我们有信心说这是比较全功能的架构。

百度在自动驾驶上有很多业务,大家都知道自动驾驶是移动超级计算节点,我们会把“昆仑”放到自动驾驶领域进行应用,在自动驾驶方面还需要功能安全,我们会利用XPU强大的计算能力加上和车相关的东西,包括RTDS、高精地图、感知、传感器等。
给大家简单总结一下,百度有超过8年AI加速器和处理器研发和大规模部署的经验,上线部署了超过10000片基于FPGA的AI加速器,经过很多代的架构积累和探索,从最早的SDA到后来的XPU到昆仑我们有很多经验。刚才我给大家分享了架构的积累、迭代和Google的架构有很多一致的地方,这说明互联网公司在这一块儿对架构的认知、芯片的认知都是有一致性的。
我们认为XPU是普适的AI计算架构,可以用在云端、自动驾驶、边缘计算,具有很高的计算能力、高通用性、灵活性。“昆仑”是基于XPU架构的AI处理器,去年发布了“昆仑”消息,今年“昆仑”会在百度内部大规模使用。百度“昆仑”,让计算更智能。谢谢大家!
