








芯潮10月23日消息,今日,Arm发布两款全新主流机器学习(ML)处理器,以及最新的Mali GPU与DPU,具体包括:
1、Arm Ethos-N57与Ethos-N37 NPUs:主要用于在主流设备上加速人工智能(AI)应用,并在机器学习的性能与成本、面积、带宽与电池寿命之间达成平衡。
2、Arm Mali-G57 GPU:第一个基于Valhall架构的主流GPU,性能是前几代产品的1.3倍,可透过性能提升带来沉浸式体验。
3、Arm Mali-D37 DPU:在最小的面积内提供丰富的显示功能,以呈现全高清及2K分辨率,尤其适用于入门设备与小型显示屏幕的显示处理器(DPU)。

据悉,这套全新IP吻合Arm全面计算(Total Compute)的初衷,确保其以实际体验驱动,并针对解决未来工作负荷的负载运算挑战进行优化,能提供更高的单位面积效率、更加节能,同时提升性能、降低成本、缩短上市所需时间,为移动设备带来在机器学习处理、视觉效果和显示性能。
在今天的大会上,Arm中国CEO吴雄昂表示,经过法务严格的合规调查,Armv8以及未来的v9架构源于英国,可以继续向所有中国客户开放授权。
在产品发布后,Arm市场营销副总裁Ian Smythe、Arm机器学习事业群商业与营销副总裁Dennis Laudick等Arm高管接受芯潮等媒体的采访,就Arm全面计算的三大支柱、Arm从云端到AI边缘的布局等进行分享。

▲Arm市场营销副总裁Ian Smythe(左二),Arm机器学习事业群商业与营销副总裁Dennis Laudick(右二)
一、两款NPU:提供更强异构计算
继Arm ML处理器Ethos-N77发布后,Ethos NPU家族又添加Arm Ethos-N57与Ethos-N37 NPUs两位新成员。
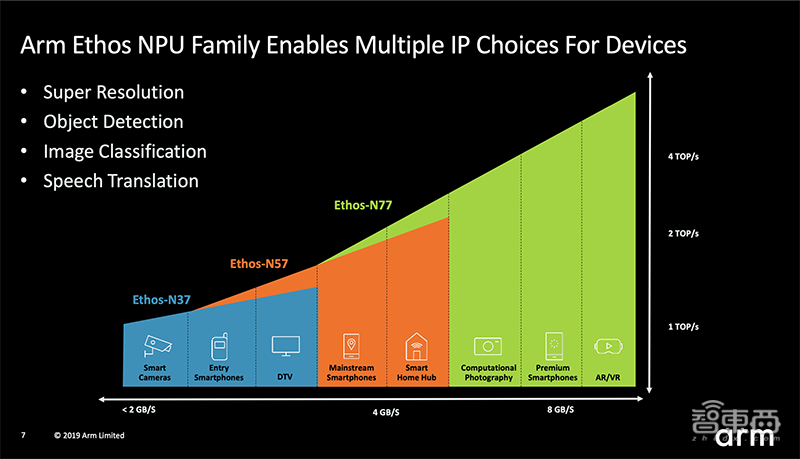
新Ethos NPUs着重对成本及电池寿命最为敏感的设计进行优化,带来更优质的AI体验。
两种新NPU的设计理念包括一些基本原则,如针对Int8和Int16数据类型的支持性优化、先进的数据管理技术以减少数据的移动与相关的耗电、通过Winograd等创新技术的落地使性能比其他NPU提升超过200%。
这些处理器采用端到端压缩技术,降低了对DRAM的要求,将系统带宽最小化1.5-3倍。
此外,Ethos-N57的功能还包括提供平衡的ML性能与功耗功率,针对每秒2兆次运算次数的性能范围进行优化。
Ethos-N37的功能还包括提供小于1平方毫米的超小ML推理处理器,并针对每秒1兆次运算次数的性能范围进行优化。

那么,同现有市场上其他厂商推出的NPU相比,Arm NPU主要聚焦于怎样的应用呢?
据介绍,Arm NPU属于通用型NPU,现在市场上机器学习大部分都默认用Arm CPU来进行处理器。今日新发布的NPU产品,将Arm CPU机器学习能力进一步提升。Arm的很多合作伙伴表示,他们并不希望去支持五花八门的处理器,而是希望标准化,这恰恰是Arm在做的事情。
二、Mali-G57 GPU:更好沉浸式体验
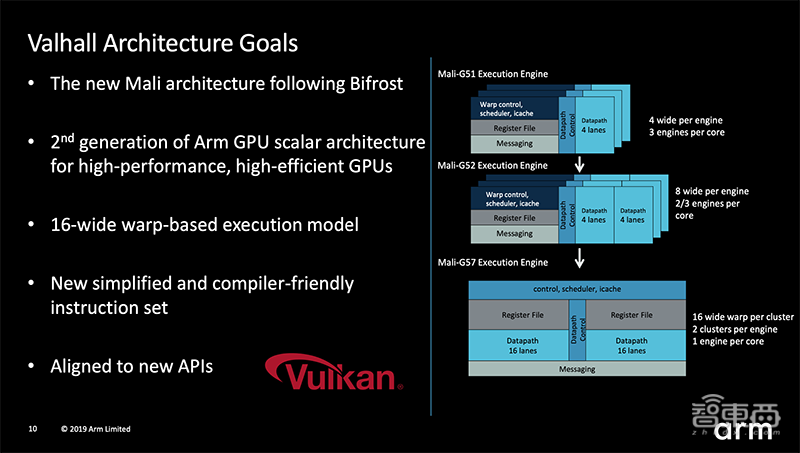
继5月推出高级Mali-G77 GPU后,今天,Arm推出第一个基于Valhall架构的主流GPU 。

Mali-G77至少有7个核心,而Mali-G57有1-6个核心,具体数量取决于配置。新推出的GPU可用于高保真游戏、媲美电玩主机的移动设备图形效果、DTV的4K/8K用户接口、更复杂的VR/AR负荷等主流市场,这也是移动市场划分最大的一部分。
相比Mali-G52,Mali-G57主要具有如下特点:
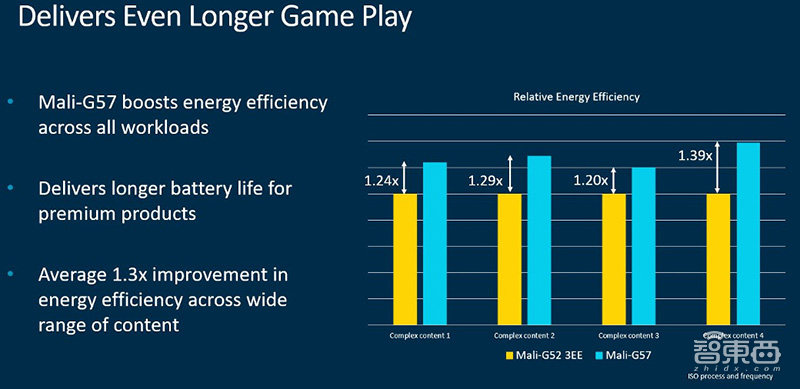
1、各种内容的性能密度达到1.3倍;
2、能效比提升30%,使得电池寿命更长;
3、针对VR提供注视点渲染支持,且设备机器学习性能提升60%。能灵活运行于不同的机器学习工作负载,能更好应用于更复杂的XR实境应用。
其中,Valhall架构作为新一代GPU的基础,扮演了重要角色。除了更好地与Vulkan等现代API保持一致外,该架构的关键功能还包括新的超标量引擎、简化的标量ISA和新的动态指令调度等。
这些使得Mali-G57的性能和能效得到有效改善,会带来更好的用户体验,比如玩每秒60帧的复杂游戏时,画面效果会更加出色。
三、Mali-D37 DPU:Arm单位面积效率最高的处理器
Mali-D37 DPU是一个在最小的可能面积上包含丰富显示与性能的新型显示处理器,采用经过优化的Komeda架构,专为主流和入门级设备设计。

对于入门级智能手机、平板电脑与分辨率在2k内的小显示屏等较低成本设备,Mali-D37 DPU能提供更好的视觉效果和性能。
Mali-D37 DPU的关键功能包括:
1、单位面积效率极高,DPU在支持全高清与2K分辨率组态下,16nm制程的面积小于1平方毫米,大约是高级Mali-DPU的36%。
2、通过减少GPU核心显示工作既包括MMU-600等内存管理功能,系统电力最高节省30%;
3、从高阶Mali-D71保留关键的显示功能,包括与Assertive Display 5结合使用后,可混合显示高动态对比(HDR)与标准动态对比(SDR)的合成内容。

四、借助软件与生态提升优势
除了研发一系列IP外,Arm也非常关注软件和生态系统。
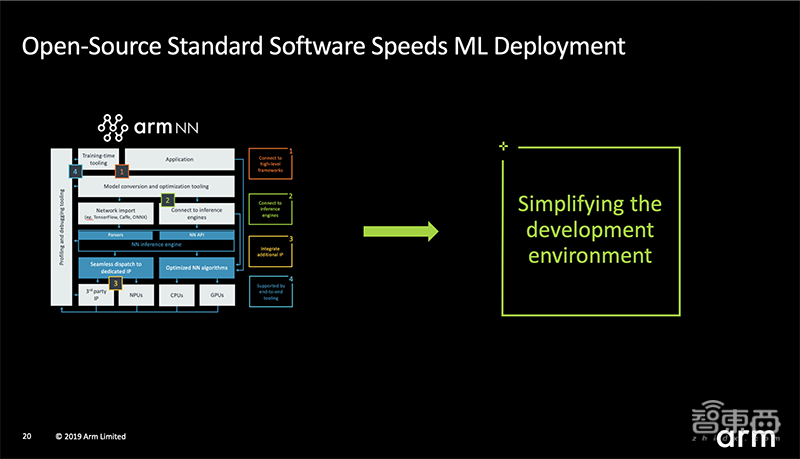
去年Arm曾推出机器学习软件Arm NN。它是Arm贡献的一个开源标准,可以与Caffe等现有机器学习框架桥接,使得开发者仍可使用首选框架和支持工具,经 Arm NN 无缝转换结果后可在底层平台上运行。
Arm Ethos处理器系列与Arm NN一起使用时,可弥补现有神经网络架构与底层CPU、GPU和NPU IP之间的鸿沟。使用Arm NN,开发人员仅需编写一次代码,即可适用于多个异构处理器。
此外,在本月美国加州圣何塞举行的Arm TechCon 2019上,Arm宣布与Unity合作,以确保3D应用程序能在使用Arm架构的硬件上流畅运行。
而Arm之所以选择Unity合作,是因为Unity是最为主要的3D内容创建引擎,90%的游戏和70%的VR都是基于Unity的。Arm希望借由合作,使得在原生开发环境中,Unity开发人员可以方便地访问Arm产品,跨Arm CPU、GPU和NPU获得最佳渲染和性能。
在采访期间,Ian Smythe强调说Arm没有开源指令集,开放的自定义指令功能可在特定CPU内核中使用,其一大优点在于允许用户使用所熟悉的开源编译器等标准软件开发工具的访问。

这样一来,第三方合作伙伴可以更快地集成和开发定制指令来加速特定应用。
而面对市场上的竞争,Arm的优势在于,可提供最为全面的指令集产品,在标准化的基础上允许开发人员做一些定制,满足部分用户定制化需求。
五、全面计算的三大支柱
Ian Smythe表示,全面计算(Total Compute)有三个支柱:性能、安全、可访问。
谈及第一个支柱性能,Ian Smythe介绍说,如今GPU、NPU、系统级IP等一些新型工作负载陆续出现,如何开发下一代CPU面临新的难题?
考虑到AI计算带来的挑战,不止是NPU本身拥有强大的处理器能力,还需要CPU、GPU等都具备处理AI应用的能力,这会带来设计上一些新的挑战,需要工程师能用和之前不同的方式来思考工程开发工作。

第二个支柱安全同样是必须重视的一环,Arm全面计算中的安全性主要基于三个层次:
1、平台安全性(Platform Security),通过透明且可获取的安全标准实现去碎片化,设计规则和标准;
2、过程安全性(In-process Security),针对薄弱环节进行侦测与保护,属于深度防御;
3、应用安全性(Application Security),在不同应用上的程序和数据受保护。
在基本层安全上,Arm会做安全启动、身份鉴别等基础工作;二是防止分支的工具,Arm会在指令集中设置一些障碍,防止跳码;三是内存标记扩展(MTE,Memory Tagging Extension),70%的操作系统崩溃或出错都是因内存访问不当所造成,因此Arm与谷歌合作共同研发内存标记扩展,来提升操作系统的安全防护水平。
在应用层,Arm与微软、谷歌等公司联合做的平台安全架构(PSA,Platform Security Architecture),主要通过编程方式的改变来防范在比较流行的应用攻击。
假设在内存中同时跑6个应用,黑客只要攻破一个,就相当于六个应用都被攻破了。于是,Arm与剑桥大学共同开发出功能架构(capability architecture),这个架构意味着如果黑客攻破内存中的一个应用,是无法攻破其他应用的。
关于可访问性,Arm目前迈出的一步是帮第三方开发人员,帮他们获得Arm CPU、GPU、NPU的能力。
六、从云端走向边缘计算
如今,在英特尔、英伟达等巨头的助力下,异构计算正大行其道,对此,Arm又有怎样的考量?
Ian Smythe表示,Arm考虑的是如何满足下一代产品的能耗以及性能跨CPU、GPU和NPU的需求。
这意味着不仅在产品设计阶段,还要在开发人员进行产品部署的运行时阶段,都能有效建立不同场景计算的组合,为做到这一点,需要统一工具链去支持CPU、GPU、NPU。

无论是Arm所专注的全面计算,还是逐渐兴起的异构计算,都聚焦于性能与能耗的平衡。Ian认为,异构计算支持这些的关键不在于打造硬件的平台,更多是能让第三方开发人员能访问到芯片级性能,因此Arm强调的是全生态系统的合作。
很多Arm的合作伙伴已经在电视、手机等产品上实现了异构片上系统(SoC)。
谈及云边端的布局,Ian Smythe也分享了对现有市场的所见所感以及Arm自身的规划。
目前,云端推理基本上都是使用CPU、GPU或专用TPU来支撑,而边缘推理基本都通过Arm CPU来做。
如果在手机上添加NPU,或者提升CPU性能,就意味着每一个设备的能力都提升,这是一个众赢的局面。
边缘端现在也在研究联邦学习,即在边缘设备上进行本地模型训练,再将训练好的模型加密上传到云端。从Arm的角度来看,即可以提升边缘端推理的性能,也可以提升边缘端训练的性能。
以前数据流向是单向的,从边缘流向云。现在,这种流动变成了双向的,如果将所有数据都放到网络核心,成本会非常高昂,因此边缘计算开始兴起。
过去一年里,Arm 推出了多个从网络终端到云端的解决方案,包括 Arm Project Trillium、Arm Neoverse、Automotive Enhanced 汽车强化处理器、Pelion 物联网平台。
为下一代基础设施技术奠定基础,Arm此前已公布其Neoverse路线图,提到将在下一代Zeus 平台中增加bfloat16支持,将能够更好利用IP开发能力支持AI计算需求,以从云端到边缘提供更加普适的计算。
Ian Smythe说,Arm提供给合作伙伴相应的架构和IP,至于合作伙伴想做什么样的平台取决于他们自身的意愿。
为了帮助解决AI从云端到边缘的过度问题,Arm还于本月宣布了一项Cassini项目,将同其生态伙伴一起针对基础设施边缘开发平台标准和参考系统,以确保跨各种安全的边缘生态系统提供云原生体验。
结语:通用AI处理器仍是当前更安全的选择
AI、物联网、5G三大技术共同推进着产业应用的演进。在这一股浪潮中,Arm看见5G改变了数据处理方式,认为它将推动网络边缘更多的创新。
而随着越来越多企业开始推出专用处理器,通用与专用之争日渐成为关乎处理器趋势的热门话题。对此,在Ian Smythe看来,目前AI市场还处于初期阶段,选用通用处理器是相对安全的做法,面对快速迭代的算法,通用处理器仍有2-3年的生命周期。
