












智东西(公众号:zhidxcom)
编 | 云鹏
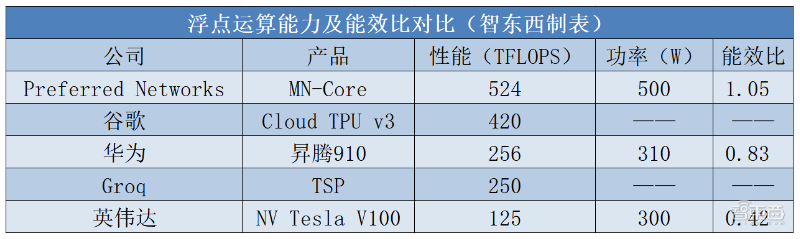
智东西11月25日消息,日本AI创企Preferred Networks(PFN)在美国科罗拉多州丹佛市举行的2019全球超级计算大会上展示了定制AI训练芯片MN-Core,可以在500W的功耗基础上实现524TFLOPS算力,计算功率效率达到了1.05 TFLOPS / W,超过NV Tesla V100、华为昇腾910等AI芯片的能效比。
PFN成立于2014年,总部位于日本东京,目前已筹集了约1.3亿美元,其中日本丰田(Toyota)公司投资了9,660万美元。PFN主要致力于通过深度学习技术为边缘和物联网提供算力支持。此次展示的MN-Core基于台积电12nm工艺制造。以下是对WikiChipFuse相关报道的原文编译。
一、MN系列超级计算机已迭代两次
在全球超级计算机大会中PFN的展位上,我们会见了东京大学名誉教授Kei Hiraki。Hiraki教授一直参与PFN的MN-Core的开发。Hiraki解释说,PFN已经开发了一系列专用超级计算机,以加速其自己的应用程序的研发,这些应用程序使用大量的计算能力来进行深度学习。
该公司于2017年推出了首个AI超级计算机MN-1。该系统具有1,024个Nvidia Tesla P100 GPU,可达到1.39 PFLOPS和9.3PFLOPS的峰值计算量。当时,MN-1在工业超级计算机的TOP500上在日本排名第一,在世界排名第十二。
在2018年7月,PFN通过添加512个额外的Tesla V100 GPU增强了MN-1。较新的系统MN-1b将深度学习(张量)的计算能力提高到56 PFLOPS。
今年早些时候,PFN推出了迄今为止最大的超级计算机MN-2。该系统于2019年7月投入运行,该系统将V100 GPU的数量增加了一倍,并从PCIe卡切换为SXM2模块。
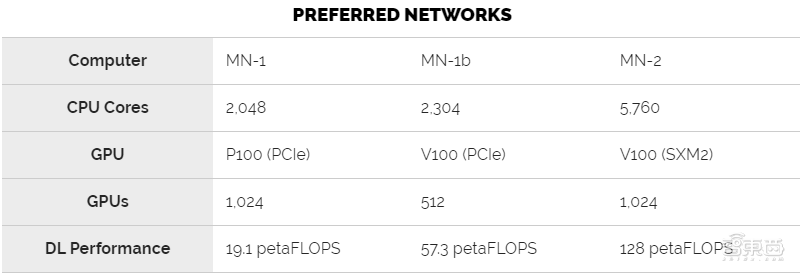
▲历代PFN超级计算机
二、MN-Core兼顾高性能与低功耗
PFN下一代超级计算机更加有趣。Hiraki教授解释说,PFN决定开发自己的专有深度学习加速器,以实现更高的性能,更重要的是实现更高的电源效率。
他们设计的是500瓦芯片,Hiraki表示这是在可能的冷却极限内进行的。该芯片本身在一个多芯片封装中包含四个内核。内核是根据公司自己的设计,以台积电12nm工艺制造。

▲MN-Core
在上面的芯片照片中,芯片上刻有单词“ GRAPE-PFN2”。尽管尚不清楚刻制的原因,但似乎有些体系架构源自GRAPE-DR。还需要指出的是,PFN团队的成员以前曾在GRAPE-DR物理协处理器(physics coprocessor)项目中工作,包括Hiraki教授。
MN-Core封装尺寸比较大,为85*85mm。内核面积也非常大,达到756.7mm²。在500 W功耗时,该芯片的算力为524TFLOPS。这为他们提供了1.05 TFLOPS / W的计算功率效率,这正是他们的目标。
该体系结构类似于GRAPE协处理器(coprocessor)的体系结构。尽管对各个区块进行了调整以用于训练任务,但各个区块的名称都很相似,并且总体操作非常相似。
MN-Core有DRAM I / F,PICe I / F和4个L2B区块。每个L2B中有8个L1B和1个区块存储器(block memory)。一级区块包括16个矩阵算术区块(MAB)以及其自己的区块存储器。矩阵算术单元(matrix arithmetic units)和4个处理元件(PE)组成一个MAB。每个芯片总共有512个MAB。
各个PE将数据传递给MAU,PE包含一个ALU并实现了PFN专门使用的许多自定义DL功能。PE的基本数据类型操作是16位浮点数,通过组合多个PE可以支持更高精度的操作。
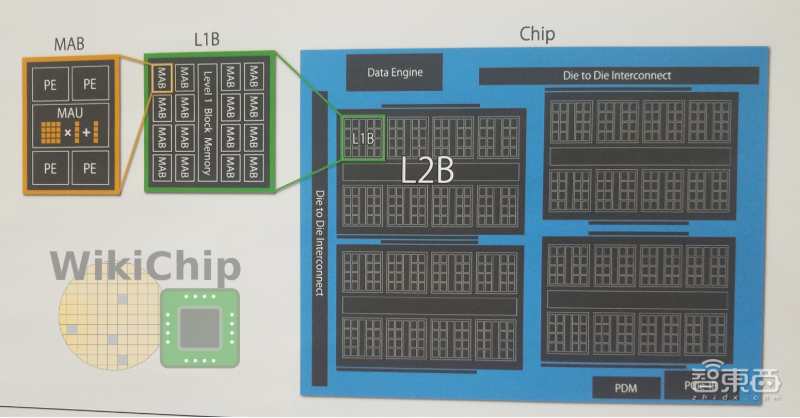
▲MN-Core内部架构图
三、2 EFLOPS算力超算MN-3将使用MN-Core
MN-Core芯片本身位于MN-Core板上,后者是一种PFN设计的基于PCIe的定制加速器板。Hiraki教授表示,芯片功耗为500W,0.55 V,有1000 A电流流经电路板,而封装对设计构成了重大挑战。
该板本身是x16 PCIe Gen 3.0卡,其中集成了MN-Core芯片,32 GiB内存以及定制设计的散热器和风扇。PFN估计该卡的功耗约为600瓦。

▲搭载MN-Core的板卡
在MN-Core服务器(一个7U机架式机箱)上安装了四个MN-Core板。每个服务器中都有一个双插槽CPU。四个板使它们每秒可以达到2 PFLOPS的半精度浮点运算。
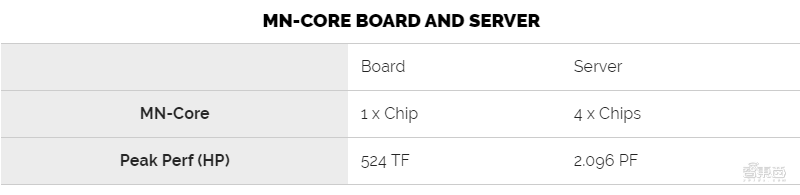
▲MN-Core板卡和服务器规格
PFN计划在每个机架(rack)上堆叠其4台服务器。他们的下一代超级计算机MN-3将基于MN-Core。

▲MN-3超算概念图
PFN目前没有出售这种芯片的计划。MN-Core芯片和他们的超级计算机将专门用于自己的研发。
PFN预计MN-3拥有约300个机架,可用于4800个MN-Core板。这相当于每秒2 EFLOPS的算力。在功耗方面,PFN估计该机器的功率为3.36 MW,对于这种性能而言这是非常低的。例如,拥有1.88 EFLOPS算力的IBM Summit超级计算机功率为13MW。MN-3计划于2020年投入运营。
目前Google和Amazon等超大规模用户(hyperscalers)为自己的云服务器开发了自定义神经处理器(custom neural processors)。类似的趋势正在行业中出现,诸如Preferred Networks之类的公司设计了自己的NPU。
他们的目的都是相同的——通过设计和研发自己芯片,以便拥有独特的,与众不同的技术优势。目前,只有少数几家AI硬件初创公司推出了AI推理芯片,而没有一家初创公司交付AI训练芯片。这种专业训练芯片的缺乏,给可以制造超越当前顶级训练GPU能效比的AI芯片的公司带来了独特的机遇。
随着越来越多的企业进入AI训练芯片领域,整个市场格局可能将会发生变化。
结语:AI芯片自研——掌握技术优势的核心
此次PFN推出的MN-Core AI训练芯片,无论在绝对算力还是能效比方面都处于全球领先行列,不过该公司准备将这项成果掌握在自己手中,用于后续研发,之后是否会商用还未表态。
提高芯片的算力和深度学习推理能力是当下的大趋势,MN-Core的推出丰富了当下相对匮乏的AI训练芯片市场,为大规模超算提供了一种新的解决方案。
无论是谷歌、华为、英伟达、英特尔,都将自研AI芯片作为重点发力方向之一,唯有掌握“核心”,才能掌握核心技术优势。AI芯片算力市场,亟待更多新力量加入。
原文来自:WikiChipFuse
