







智东西(公众号:zhidxcom)
编 | 云鹏
智东西12月5日消息,据外媒报道,阿里巴巴浙江大学研究中心和史蒂文斯理工学院(Stevens Institute of Technology)的研究人员近日推出了一种提升AI阅读唇语准确率的方法——“Lip by Speech(LIBS)”。
该方法利用视频中的语音信息作为辅助线索,减少了AI对视频中无关帧的关注,使其注意力更加集中。据研究人员称,使用该方法的AI在两个唇语阅读基准测试中,字符错误率分别降低了7.66%和2.75%。
一、图像语音相结合解读唇语

▲面部图像识别的过程示例
实际上,能够从视频中读唇语的AI和机器学习算法并不是什么新鲜事物。早在2016年,谷歌和牛津大学的研究人员就详细介绍了一种系统,该系统可以以46.8%的精度注释视频素材,优于专业读唇语人员12.4%的精度。但是,即使是最先进的系统也难以解决唇部运动的“一语多义”问题,从而使唇语识别的准确率一直无法超越语音识别。
为了追求唇语阅读性能更加强大的系统,阿里巴巴浙江大学研究中心和史蒂文斯理工学院的研究人员设计了一种方法,称为“Lip by Speech(LIBS)”。该方法利用从语音识别器中提取的特征信息作为补充线索。他们说,利用该方法的系统在两个基准测试中都达到了业界领先的准确性,在字符错误率方面分别降低了7.66%和2.75%。
LIBS和其他类似的解决方案可以帮助那些听障人士观看缺少字幕的视频。据估计,全世界有4.66亿人患有失能性听力障碍(disabling hearing loss),约占世界人口的5%。根据世界卫生组织的数据,到2050年,这一数字可能会超过9亿。
二、LIBS方法是怎样应用的?
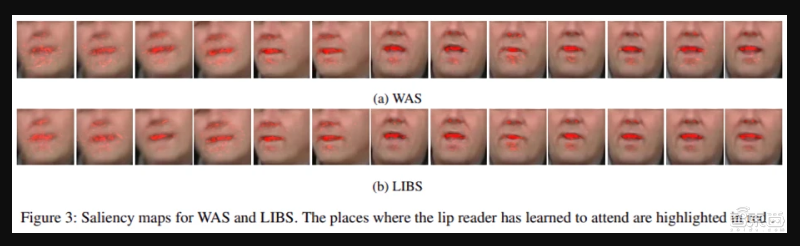
▲WAS与LIBS方法唇语解读标记范围的对比
LIBS会以多种规模等级,从有声视频中提取有用的音频数据,包括序列级(sequence level)、文本级(context level)和帧级(frame level)。然后,将这些提取的数据与视频数据通过他们之间的对应关系对齐,最后利用一种筛选(filtering)技术来优化(refine)提取的数据。
LIBS的语音识别器和唇语阅读器这两部分均为一种“基于注意力的序列到序列的(attention-based sequence-to-sequence)”体系结构,这种体系结构可将一段音频或视频序列的输入信息转化为带有标签和注意价值(attention value)的输出信息。
研究人员通过上述方法在LRS2数据集上对系统进行训练,LRS2包含来自BBC的45,000多个口头句子,同时也在CMLR上训练,CMLR是现有的最大中文普通话口语语料库,具有来自中国网络电视台的10万多个自然句子(包括3,000多个中文字符和20,000个词组)。
三、“帧级知识提取”是关键
该团队指出,由于LRS2数据集中的某些句子过短,该系统难以在LRS2数据集上实现“合理的”结果。但是,一旦对最大长度为16个单词的句子进行了预训练,解码器就可以利用文本级的知识,提高LRS2数据集中句子结尾部分的质量。
研究人员在论文中写道:“LIBS减少了对无关帧的关注”,“帧级知识的提取(frame-level knowledge distillation)进一步提高了视频帧特征的可分辨性,使注意力更加集中。”
结语:AI唇语识别市场仍具有较高增长潜力
目前AI唇语识别在基准测试中的准确率仍然在50%左右,现实应用价值还有待于准确率的进一步提升。此次新提出的LIBS方法为这一领域的研究提供了更好的思路,一种视频语音相结合的研究思路。
金融身份识别、嘈杂环境下的语音识别辅助、听障人士的辅助交流等领域均为AI唇语识别的重要应用场景。期待国内外科技巨头在该领域有更多新的突破。
文章来源:Venturebeat
