








报告来源:苹果公司
编译:网易科技编译
智东西(公众号:zhidxcom)授权转载
日前,苹果发布了其首份关于人工智能(AI)的学术论文——“通过对抗网络使用模拟和非监督图像训练”(Learning from Simulated and Unsupervised Images through Adversarial Training),其中主要描述了在计算机视觉系统中提高图像识别的方法,而这或许也标志着苹果公司研究的新方向。
查看这篇论文的英文原版,请在智东西(公众号:zhidxcom)回复“苹果AI论文”下载。
下面就是这篇报告的全文:
摘要
随着图形技术不断进步,利用合成图像训练机器学习模型变得越来越容易,这可以帮助避免注释图像的昂贵支出。然而,通过合成图像训练机器学习模型可能无法达到令人满意的效果,因为合成图像与真实图像之间毕竟存在区别。为了减少这种差异,我们提出“模拟+无监督”学习方法,即通过计算机生成图像或合成图像来训练算法的图像识别能力。
事实上,这种“模拟+无监督”学习需要将无标注的真实图像数据与已经注释的合成图像相结合。在很大程度上,它需要依赖生成式对抗网络(GAN)的新机器学习技术,它可通过两个神经网络相互对抗以生成更加真实的图像。我们对标准GAN算法进行了多处关键性修改,以保留注释、避免伪影以及稳定性训练:自正则化(self-regularization)-局部对抗性损失-使用精炼图像升级鉴别器。
我们发现,这个过程可以产生高度逼真的图像,在质量上和用户研究方面都已经获得证实。我们已经通过训练模型评估视线水平和手势姿态,对计算机生成图像进行定量评估。通过使用合成图像,我们的图像识别算法已经取得了巨大进步。在没有使用任何标准真实数据的情况下,我们在MPIIGaze数据集中获得了最高水平的结果。
引言
随着最近高容量深度神经学习网络的崛起,大规模标注训练数据集正变得日益重要。可是,标准数量庞大的数据集成本非常高,而且相当耗费时间。为此,使用合成图像而非真实图像训练算法的想法开始出现,因为注释已经可实现自动化。利用XBOX360外设Kinect评估人体姿势以及其他任务,都是使用合成数据完成的。
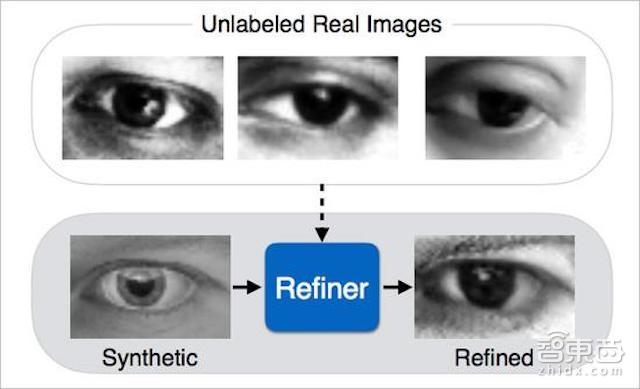
(图1:“模拟+无监督”学习:通过计算机生成图像或合成图像来训练算法的图像识别能力)
然而,由于合成图像与真实图像之间存在差距,使用合成图像训练算法可能产生很多问题。因为合成图像通常不够真实,导致神经网络学习仅仅能够了解到合成图像中的细节,并不能完整地识别出真实图像,进而也无法为算法提供精确的学习。一种解决方案就是改进模拟器,可是增加真实性的计算往往非常昂贵,渲染器的设计也更加困难。此外,即使最顶级的渲染器可能也无法模仿真实图像中的所有特征。因此,缺少真实性可能导致算法过度拟合合成图像中不真实的细节。
在这篇论文中,我们提出“模拟+无监督”学习的方法,其目的就是使用未标注真实数据的模拟器提高合成图像的真实性。提高真实性可更好地帮助训练机器学习模型,而且无需收集任何数据,也无需人类继续标注图像。除了增加真实性,“模拟+无监督”学习还应该保留注释信息以用于训练机器学习模型,比如图一中的注视方向应被保留下来。此外,由于机器学习模型对合成数据中的伪影非常敏感,“模拟+无监督”学习也应该产生没有伪影的图像。
我们为“模拟+无监督”学习开发出新的方法,我们称之为SimGAN,它可以利用我们称之为“精炼器网络(refiner network)”的神经网络从模拟器中提炼合成图像。图二中展示了这种方法的概述:第一,黑盒子模拟器中生成合成图像,然后利用“精炼器网络”对其进行提炼。为了增加真实性,也就是“模拟+无监督”学习算法的首要需求,我们需要利用类似生成式对抗网络(GAN)来训练“精炼器网络”,进而产生判别网络无法区分真假的精炼图像。
第二,为了保留合成图像上的注释信息,我们需要利用“自正则化损失”弥补对抗性损失,在合成图像和精炼图像之间进行修改。此外,我们还利用完全卷积神经网络,在像素水平方面进行操作,并保留全局结构,而非整体修改图像的内容。
第三,GAN框架要求训练2个神经网络进行对抗,它们的目标往往不够稳定,倾向于产生伪影。为了避免漂移和产生更强的伪影,导致甄别更困难,我们需要限定鉴别器的接收区域为局部接收,而非整张图片接收,这导致每张图像都会产生多个局部对抗性损失。此外,我们还引入提高训练稳定性的方法,即通过使用精炼图像而非当前“精炼器网络”中的现有图像升级鉴别器。
1.1相关工作
GAN框架需要2个神经网络竞争损失,即生成器与鉴别器。其中,生成器网络的目标是在真实图像上绘制随机向量,而鉴别器网络的目标则是区分生成图像与真实图像。GAN网络是由古德弗罗(I. Goodfellow)等人首先引入的,它可以帮助生成逼真的视觉图像。自从那以来,GAN已经有了许多改进,并被投入到有趣的应用中。
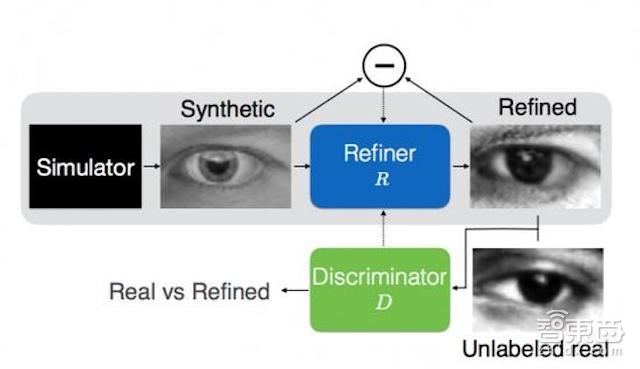
(图2:SimGAN概观:我们利用“精炼器网络”提炼模拟器产生的输出图像,并最大限度地减少局部对抗性损失,并进行自正则化。对抗性损失可以欺骗鉴别器网络,从而令其将合成图像误认为真实图像。而自正则化则会最大限度减少合成图像与真实图像的差异,包括保留注释信息,并让精炼图像被用于训练机器学习模型。“精炼器网络”与鉴别器网络也会交替升级。)
王(X. Wang)与古普塔(A. Gupta)利用结构化GAN学习表面法线,然后将其与Style GAN相结合,以生成天然的室内场景。我们提议使用对抗性训练进行递归生成模型(recurrent generative model)训练。此外,最近推出的iGAN能够帮助用户以交互模式改变图像。刘(M.-Y. Liu)等人开发的CoGAN结合GAN可多模态联合分布图像,无需要求应对图像的元组,这有利于开发出联合发布解决方案。而陈(X. Chen)等人开发的InfoGAN是GAN信息理论的扩展,允许有意义的陈述学习。
恩杰尔·图泽尔(Oncel Tuzel)等人利用GAN解决人脸图像超高分辨率问题。李(C. Li)和王(M. Wand)提议Markovian GAN进行有效的纹理合成。洛特尔(W. Lotter)等人在LSTM网络中利用对抗性损失进行视觉序列预测。于(L. Yu)等人提议SeqGAN框架,利用GAN强化学习。许多近来的问题都显示出与生成模型领域相关的问题,比如PixelRNN可利用RNN的softmax损失预测像素顺序。生成网络侧重于使用随机噪声矢量生成图像,与我们的模型相比,其生成的图像没有任何标注信息,因此也无法用于训练机器学习模型。
许多努力都在探索使用合成数据进行各种预测任务,包括视线评估、RGB图像文本检测与分类、字体识别、对象检测、深度图像中手部姿态评估、RGB-D场景识别、城市场景语义分割以及人体姿态评估等。盖伊登(A. Gaidon)等人的研究表明,利用合成数据训练深度神经网络,可以提高其表现。我们的工作是对这些方法的补充,我们使用未标记真实数据提高了模拟器的真实性。
嘉宁(Y. Ganin)与莱姆皮茨基(V. Lempitsky)在数据域适应设置中利用合成数据,了解合成图像与真实图像域的变化过程中保持不变的特征。王(Z. Wang)等人利用合成和真实数据训练层叠卷积码自动编码器,以便了解其字体检测器ConvNet的低级表示形式。张(X. Zhang)等人学习多通道编码,以便减少真实数据与合成数据的域的转变。与经典域适应方法相反,它采用与特定的特征以便适应具体的预测任务,而我们可通过对抗性训练,弥合图像分布之间的差距。这种方法使我们能够生成非常逼真的图像,可以用于训练任何机器学习模型,并执行潜在的更多任务。
2. “模拟+无监督”学习
模拟+无监督学习的目标是使用一组未标记的真实图像yi ∈ Y,学习可提炼合成图像X的refiner Rθ(x),其中θ属于函数参数。让我们用X?表示精炼图像,然后会得出X?:θ= R(X)。在“模拟+无监督”学习中,最关键的要求就是精炼图像X?,以便于其看起来更像真实图像,同时保留来自模拟器的注释信息。为此,我们建议通过最大化减少两个损失的组合来学习:
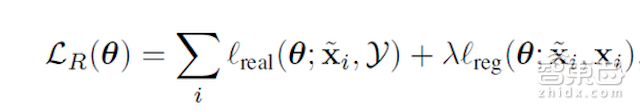
其中,xi是e ith合成训练图像,X是相应的精炼图像。第一部分是真实性成本,即向合成图像中增加真实性的成本。第二部分则代表着通过最小化合成图像精炼图像的差异保存注释信息的成本。在下面的章节中,我们会展开这个公式,并提供优化θ的算法。
2.1 对抗性损失
为了向合成图像中添加真实性,我们需要在合成图形和真实图像的分部之间建立起联系。在理想情况下,精炼机可能无法将给定的图像分类为真实图像还是高度精炼图像。这就需要使用对抗性的鉴频器,网络Dφ,它可训练分辨图像到底是真实图像还是精炼图像,而φ是鉴别器网络参数。对抗性损失训练refiner networkR,它负责欺骗D网络,令其将精炼图像误认为是真实图像。利用GAN方法,我们建造了2个神经网络参与的极限博弈模型,并升级“精炼器网络”Rθ和鉴别器网络Dφ。接下来,我们更精确地描述这种模型。鉴别器网络通过最大限度地减少以下损失来更新参数:
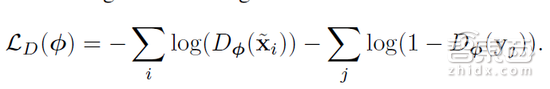
这相当于两级分类问题产生的交叉熵误差,其中Dφ(.)输入的是合成图像,而1 ? Dφ(.)则是真实图像。至此,我们实现了Dφ作为ConvNet的最后输出层,样本很可能是精炼图像。为了训练这个网络,每个小批量随机抽取的样本都由精炼合成图像和真实图像组成。对于每个yj来说,交叉熵的目标标签损耗层为0,而每个x?i都对应1。然后通过随机梯度下降(SGD)方式,φ会随着小批量梯度损失而升级。在我们的实践中,真实性损失函数使用训练有素的鉴别器网路D如下:
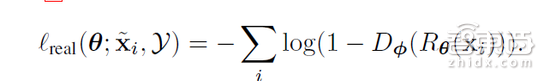
通过最小化减小损失函数,“精炼器网络”的力量促使鉴别器无法分辨出精炼图像就是合成图像。除了产生逼真的图像外,“精炼器网络”应该保存模拟器的注释信息。举例来说,用于评估视线的学习转变不该改变凝视的方向,手部姿势评估不应该改变肘部的位置。这是训练机器学习模型使用配有模拟器注释信息的精炼图像的必要组成部分。为了实现这个目标,我们建议使用自正则化,它可以最大限度地减少合成图像与精炼图像之间的差异。

(算法1)
(图3:局部对抗性损失的图示。鉴别器网络输出wxh概率图。对抗损失函数是局部块上的交叉熵损失的总和。)
因此在我们的执行中,整体精炼损失函数(1)为:
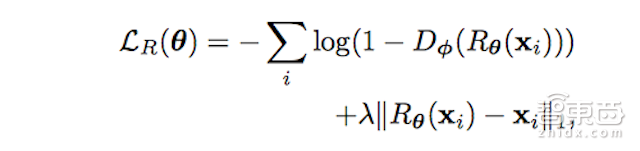
(4)在||.||1是L1常模时,我们将Rθ作为一个完全卷积的神经网络,而无需跃进或池化。在像素级别上修改合成图像,而不是整体地修改图像内容。例如在完全连接地编码器网络中便会如此,保留全局结构合注释。我们通过交替地最小化LR(θ) 和LD(φ)来学习精化器和鉴别器参数。在更新Rθ的参数时,我们保持φ固定不变,而在更新Dφ时,则要保持θ不变。我们在算法1中描述了整个训练过程。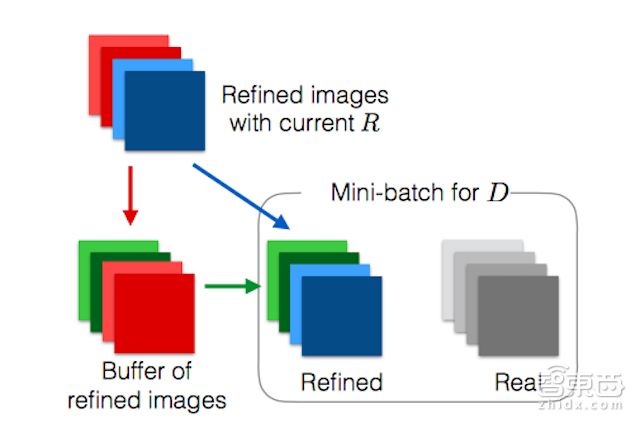
(图4:使用精细图像历史示意图。相关信息请参阅文本描述。)
2.2本地对抗损失
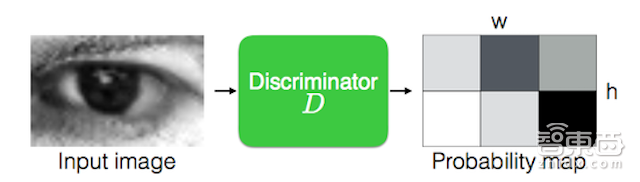
精炼网络另一个关键要求是,它应该学习模拟实际图像特性,而不引入任何伪影。当我们训练强鉴别器网络时,精炼网络倾向于过度强调某些图像特征以欺骗当前鉴别器网络,导致偏差和产生伪影。关键是任何我们从精化图像中采样的本地补丁都应该具有与真实图像相类似的统计。由此我们可以定制本地鉴别器网络对本地图像补丁进行分类,而不是定义全局鉴别器网络。
这不仅限制了接受域,还因此限制了鉴别器器网络的容量,并且为每个图像提供更多样本以供学习鉴别器网络。同时由于每个图像由多个实际损失值,它还改善了精炼网络的训练。
在我们的执行中,我们将鉴别器器D设计成一个完全卷积网络,输出伪类w × h概率图。在后者中w × h是图像中本地补丁的数量。在训练精炼网络时,我们将w×h本地补丁的交叉熵损失值求和,如图3所示。
2.3 使用精化图像的历史记录更新鉴别器器
对抗训练的对抗训练的另一个问题是鉴别器器网络只关注最新的精细图像。 这可能导致(i)与对抗训练分歧,以及(ii)精炼网络重新引入鉴别器已经忘记的工件。在整个训练过程中的任何时间由精炼网络生成的任何精细图像对于鉴别器器来说都是伪造的图像。因此,鉴别器应该有能力将这些图像识别为假。基于这一观察,我们引入了一种方法,通过使用精细图像的历史来提高对抗训练的稳定性,而不仅仅是在当前小批次中小修小改。我们对算法1稍作改进,增加对先前网络产生的精细图像的缓冲。设B为此缓冲的大小,设b为算法1中使用的迷你批次大小。
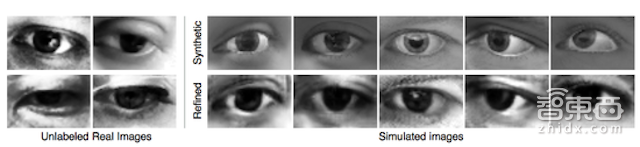
(图5:SimGAN输出的图像示例。左为MPIIGaze采集的实拍图像,右为优化后的UnityEye合成图像。从图中可以看出精细合成图像中的皮肤纹理和虹膜区都更近似真实而非合成图像。)
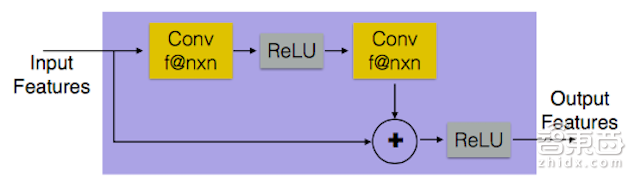
(图6:带有两个nxn卷积层的ResNet块,每个都都具有f特征图。)
在鉴别器器训练的每次迭代中,我们通过对来自当前精炼网络的b/2图像进行采样,以及从缓冲区采集额外b/2图像,从而更新参数φ。保持缓冲区B大小固定,在每次迭代之后,我们使用新产生的精细图像随机替换缓冲区中的b/2样本。该过程在图4中标示出。
3.实验
我们使用MPIIGaze [40,43]上的外貌估计数据集和纽约大学的手势数据集 [35]来评估我们的方法。我们在所有实验中使用完全卷积的精炼网络与ResNet块(图6)。
3.1基于外貌的注视估计
注视估计是许多人机交互(HCI)任务的关键因素。然而,直接由眼睛图像进行估计是有挑战性的,特别是在图像质量不佳时。例如智能手机或笔记本电脑前置摄像头采集到的眼睛图像。因此,为了生成大量注释数据,最近几次方法[40,43]用大量合成数据训练它们的模型。在这里,我们展示使用SimGAN生成的精细合成图像训练显著提高了任务的表现。
注视估计数据集包括使用眼睛注视合成器UnityEyes生成的1200万样本,以及来自MPIIGaze数据集的21,000实拍样本。MPIIGaze的图像样本都是在各种照明条件不理想情况下捕捉到的图像。而UnityEyes图像都是在同一渲染环境下生成。
定性结果:图5展示了合成生成的眼睛注视图像以及经过处理的实拍图像。如图所示,我们观察到合成图像的显著质量改进:SimGAN成功捕获皮肤纹理,传感器噪点以及虹膜区的外观。请注意,我们的方法在改善真实性的同时保留了注释信息(注视方向)。
‘视觉图灵测试’:为了定量评估精细图像的视觉质量,我们设计了一个简单的用户研究,要求受试者对图像是属于实拍或是合成进行区分。每个受试者被展示50张实拍图像和50张合成图像。在试验中,受试者不断观看20个真假混杂的图像,最终受试者很难分辨真实图像和精细图像之间的差异。在我们的总体分析中,10个受试者在1000次试验中正确率只有517次(p=0.148),跟随机选差不多。表1展示了混淆矩阵。相比之下,当使用原始图像和实拍图像进行测试时,我们给每个受试者展示10个实拍和10个合成图像,这种情况下受试者在200此实验中选对了162次(p≤10-8),结果明显优于随机选择。

(表1:采用真实图像和合成图像进行的“视觉图灵测试”。平均人类分类精度为51.7%,表明自动生成的精细图像在视觉上已经达到以假乱真的程度。)
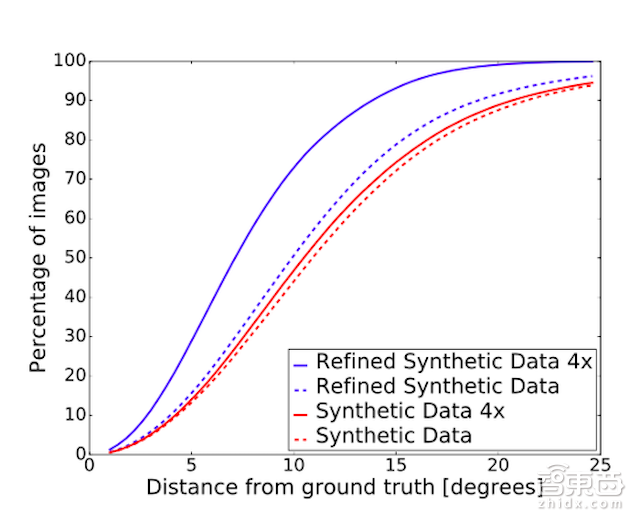
(图7:使用MPIIGaze实拍样本进行的眼睛注视估计的定量结果。曲线描述了不同测试数量下系统预估的误差。图示中使用精细图像而不是合成图像能显著提高系统表现。)
定量结果:我们训练了一个与[43]类似的简单的卷积神经网络(CNN)来对眼睛的注视方向进行预测。我们在UnityEyes上训练,并在MPIIGaze上进行测试。图7和表2比较了CNN分别使用合成数据以及SimGAN生成的精细数据的不同表现。我们观察到SimGAN输出训练的表现有很大的提高,绝对百分比提高了22.3%。我们还发现训练结果和训练数据呈正相关——此处的4x指的是培训数据集的100%。定量评估证实了图5中观察到的定性改进的价值,并且表明使用SimGAN能使机器学习模型有更好的表现。表3展示了同现有技术的比较,在精细图像上训练CNN的表现优于MPIGaze上的现有技术,相对改善了21%。这个巨大的改进显示了我们的方法在许多HCI任务中的实际价值。
实施细节:精炼网络Rθ是一个残差网络 (ResNet) 。每个ResNet块由两个卷积层组成,包含63个特征图,如图6所示。大小为55×35的输入图像和3×3的过滤器进行卷积,输出64个特征图。输出通过4个ResNet块传递。最后ResNet块的输出被传递到1×1卷积层,产生对应于精细合成图像的1个特征图。
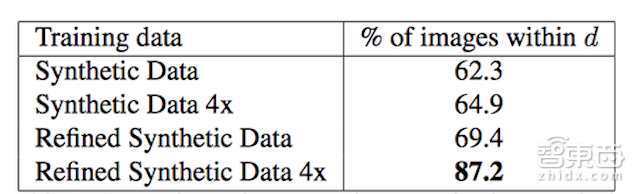
(表2: 使用合成数据和SimGAN输出进行训练的比较。在无需监督真实数据的情况下,使用SimGAN输出的图像进行训练表现出22.3%的优势。)
(表3: SimGAN与MPIIGaze现有技术进行比较。R=真实图像,S=合成图像。误差是以度为单位的平均眼睛注视估计误差。对精细图像的训练带来了2.1度的改进,相对现有技术提高了21%。)
鉴别器器网络Dφ包含5个扩展层和2个最大合并层,分别为:(1)Conv3x3,stride = 2,特征映射= 96,(2)Conv3x3,stride = 2,特征映射= 64,( 3)MaxPool3x3,stride = 1,(4)Conv3x3,stride = 1,特征映射= 32,(5)Conv1x1,stride = 1,特征映射= 32,(6)Conv1x1,stride = 2,(7)Softmax。
我们的对抗网络是完全卷积的,并且已经被设计为使Rθ和Dφ中的最后层神经元的接受域是相似的。我们首先对Rθ网络进行1000步的自正则化损失训练,Dφ为200步。然后对于Dφ的每次更新,对应在算法中更新Rθ两次。即Kd被设置为1,Kg被设置为50。
眼睛注视估计网络同[43]类似,不过略作修改以使其更好地利用我们的大型合成数据集。输入是35×55的灰度图,通过5个卷积层,然后是3个完全连接的层,最后一个编码三维注视向量:(1)Conv3x3,特征图= 32,(2)Conv3x3 ,特征映射= 32,(3)Conv3×3,特征映射= 64,(4)Max- Pool3x3,stride = 2,(5)Conv3x3,特征映射= 80,(6)Conv3x3, MaxPool2x2,stride = 2,(8)FC9600,(9)FC1000,(10)FC3,(11)Eu- clidean loss。所有网络都使用恒定的0.001学习速率和512批量大小进行训练,直到验证错误收敛。
3.2关于深度图像的手势图像模拟
下一步,我们将用这宗方法对各种手势的深度图像进行模拟。在研究中,主要使用了纽约大学所提供的NYU手势数据库,其中包含72757个训练样本以及使用3台Kinect相机所采集的8251个测试样本,其中每个测试样本包括一个正面手势图像以及两个侧面手势图像。而每一个深度图像样本都对手势信息进行了标记,从而生成了合成图像。图10展示了手势数据库中的一个样本。我们对数据库样本进行了预处理,利用合成图像从真实图像中提取了相应的像素点位。在使用深度学习网络ConvNet进行处理之前,每个图像样本的分辨率大小被统一调整为224*224,背景值设置为零,前景值设置为原始深度值减2000。(此时假设背景分辨率为2000)。

图10:NYU手势数据库。左图为深度图像样本;右图为处理后的合成图像。
定性描述:图11显示了“生成对抗网络”( SimGAN)对手势数据库的计算结果。由图可知,真实深度图像的噪声已经边缘化,且分布不连续。SimGAN能够有效对原有图像噪声进行学习并模拟,从而产生出更加真实精细的合成图像,且不需要在真实图像上做出任何标记或注释。

图11: NYU手势数据库的精细测试图像示例。左图为真实图像实像,右图上为合成图像,右图下为来自苹果生成对抗网络的相应精细化输出图像。
实际图像中的主要噪声源是非平滑的边缘噪声。 学习网络能够学习模拟真实图像中存在的噪声,重要的是不需要任何标记和注释。
- 定量分析:
我们采用一种类似于Stacked Hourglass人体姿态算法的CNN仿真算法应用于真实图像、合成图像以及精细化合成图像处理,与NYU手势数据库中的测试样本进行对比。通过对其中14个手关节变换进行算法训练。为了避免偏差,我们用单层神经网络来分析算法对合成图像的改进效果。图12和表4显示了关于算法对手势数据库进行处理的定量结果。其中由SimGAN输出的精细化合成图像显著优于基于真实图像进行训练而产生的图像,其更为逼真,比标准合成图像高出了8.8%,其中仿真 模拟输出的注释成本为零。同时要注意的是,3X代表图像训练选取了所有角度。
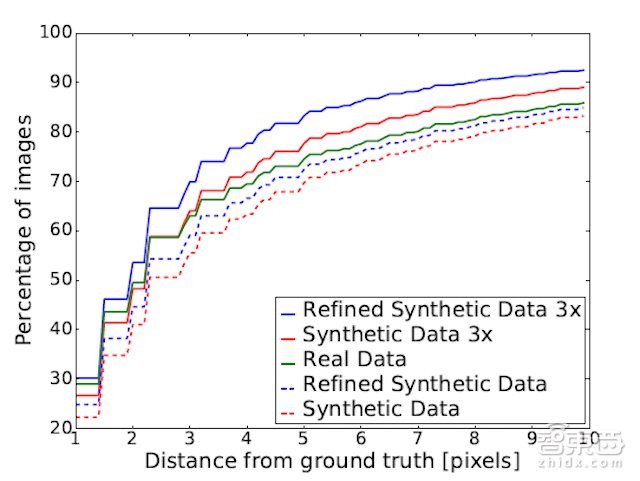
图12:手势估计的定量结果,关于NYU手势测试集的真实深度图像。
图表显示图像与背景之间函数的累积曲线。可见,SimGAN输出的精细化合成图像显著优于基于真实图像进行训练而产生的图像,其更为逼真,比标准合成图像高出了8.8%。 重要的是,我们的学习网络不需要对真实图像进行标记。

表4:通过训练生成各种手势图像的相似度。
Synthetic Data为一般网络训练产生的合成图像,Real Data为真实图像,Refined Synthetic Data为生成对抗网络SimGAN输出的精细化合成图像。3X表示对真实图像进行多角度模拟。
实现细节:关于手势图像判别的架构与眼睛图像相同,但输入图像分辨率为224*224,滤波器大小为7*7,残差网络值为10。判别网络D如下:
(1)Conv7x7,stride=4, feature maps=96, (2) Conv5x5, stride=2, feature maps=64, (3) MaxPool3x3, stride=2, (4) Conv3x3,stride=2, feature maps=32, (5) Conv1x1, stride=1, feature maps=32, (6) Conv1x1, stride=1, feature maps=2,(7) Softmax。
首先,我们会对R网络进行自我规则化训练500次,随后引入D网络训练200次;随后,每更新一次D网络,就相应将R网络进行两次更新。在手势估计中,我们采用Stacked Hourglass Net人体姿态算法输出大小为64*64的热点图。我们在网络学习中引入[-20,20]的随机数据集来对不同角度的图像进行训练。直至验证误差有效收敛时,网络训练结束。
3.3对抗训练的修正分析
首先我们比较了本地化对抗训练以及全局对抗训练的图像偏差。在全局对抗中,判别网络使用了完全连接层,从而使整个图像相对于更加精细。而本地化对抗训练则使得生成的图像更为真实,如图8所示。
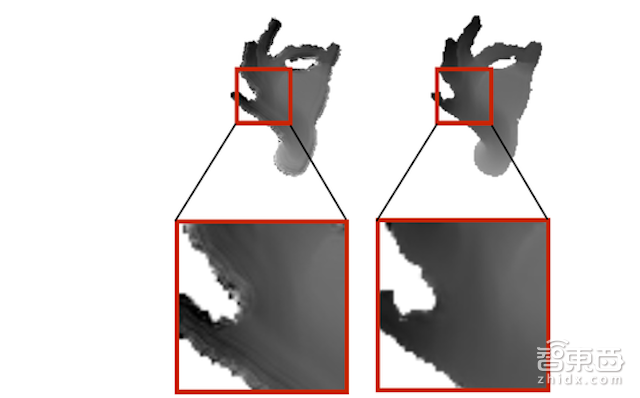
图8:左为全局对抗训练结果,右为本地化对抗训练结果。
显示了全局对抗训练与本地化对抗训练的结果偏差。左图生成的图像更精细但不真实,右图生成的图像相对真实度更高。
接下来,在图9中,显示了使用反复训练的历史精细化图像对判别网络进行更新,并将其与标准对抗生成的合成图像进行比较的结果。如图所示,使用反复训练的历史精细化图像刻产生更为真实的阴影,譬如在标准对抗训练中,眼睛角落里没有阴影。
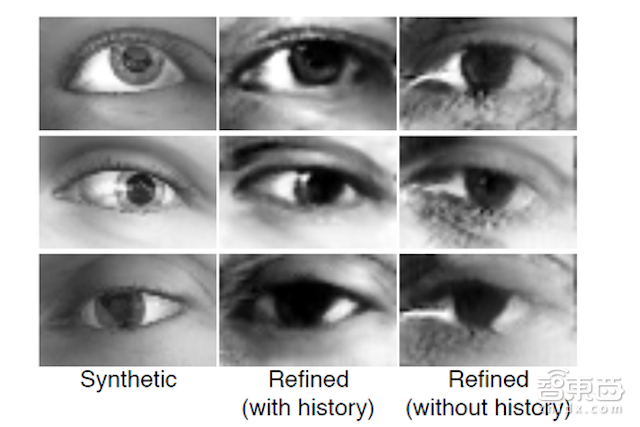
图9:使用历史精细图像对判别网络进行更新的结果。
左图: 标准合成图像;中图:使用历史数据对判别网络进行更新后的图像结果;右图:使用近期历史数据对判别网络进行更新的图像结果。如图所示,使用反复训练的历史精细化图像刻产生更为真实的阴影。
4 结论以及下一步工作
在文中,我们提出了一种“模拟+无监督”的机器学习方法,能够有效提高模拟图像的真实感。我们描述了一种新的生成对抗网络SimGAN,并将其应用于未经标注的真实图像,获得了最好的结果。下一步,我们将继续探索为合成图像建立更为逼真的精细图像,同时研究如何对视频进行处理。
智东西语

看完上面的苹果论文全文是不是还是一脸懵逼的状态?除非专业研究人员,应该不会看懂论文中的这些复杂公式,不过这都不重要,这篇论文的表面意思很好理解,苹果通过合成的图像来训练机器的图像识别功能,据说效果还不错。
这篇论文公开的另一个深层次意义则是源于这月初在西班牙举办的人工智能领域大会NIPS上,苹果AI研发部门负责人Russ Salakhutdinov宣布,苹果将会允许自己的AI研发人员公布自己的论文研究成果,并积极加入到AI学术圈的讨论当中。这篇算是一个开头,不过一向保密的苹果这次表现得如此开放,也是有其私心的,希望通过加强交流,网罗更多人工智能方面的人才加入苹果才是真实目的。

