19
19
智东西7月20日消息,根据英特尔官方消息,英特尔通过AI硬件组合及开放的软件环境,服务Meta发布的Llama 2模型。在Llama 2发布之际,英特尔分享了70亿和130亿参数的Llama 2模型的初始推理性能测试结果。
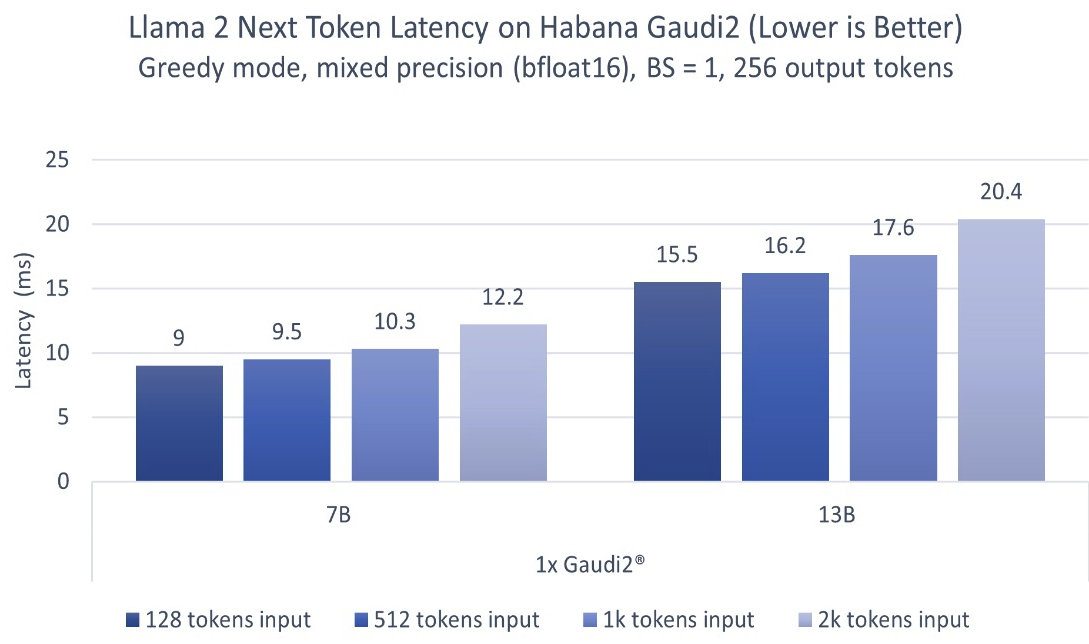
这些模型在英特尔AI产品组合上运行,包括Habana Gaudi 2深度学习加速器、第四代英特尔至强可扩展处理器、英特尔至强CPU Max系列和英特尔数据中心GPU Max系列。其中,Habana Gaudi2在近期发布的MLPerf基准测试中,对于128至2000输入token,在70亿参数Llama 2模型上的推理延迟范围为每token 9.0-12.2毫秒,而对于130亿参数模型,范围为每token 15.5-20.4毫秒。