










智东西(公众号:zhidxcom)
编 | 十四
GTC CHINA 2017大会上,英伟达创始人兼CEO黄仁勋表示,AI已无处不在,两股力量正推动计算机领域的未来。第一、摩尔定律已终结,设计人员无法再创造出可以实现更高指令集并行性的CPU架构;第二、深度学习正在引领软件和计算机领域的变革。深度学习、大数据和GPU计算的结合引爆了AI革命。
本期的智能内参,我们推荐英伟达基于最新Volta架构的NVIDIA Tesla V100 白皮书,结合智东西市场观察,盘点面向人工智能/深度学习的计算平台战场,解读Tesla V100加速器和Volta GV100 GPU架构,以及给需要提升计算力的AI企业带来的利益。如果想收藏本文的报告全文(NVIDIA-Volta架构白皮书),可以在智东西(公众号:zhidxcom)回复关键词“nc215”下载。
以下为智能内参整理呈现的干货:
30亿美金研发投入 GV100剑指AI
AI芯片也被称为AI加速器或计算卡,即专门用于处理人工智能应用中的大量计算任务的模块(其他非计算任务仍由CPU负责)。当前,AI芯片主要分为 GPU(既渗透数据中心,横扫DL训练端,亦是DL推理端大头) 、FPGA (可编程,适用于迭代升级、各类场景化应用)、ASIC(终端AI利器)。
德勤TMT最新报告显示,2016年面向深度学习(DL)售出的GPU芯片数量约为10万到20万;预计2018年面向DL应用售出的GPU将达50万片,FPGA约20万片,ASIC约10万片;2020年,DL加速器市场规模或达45亿到91亿美元。

▲德勤2017年TMT报告预计全球深度学习芯片市场
份额最高的GPU市场龙头,就是英伟达,其次是AMD;而目前,数据中心/HPC和DL加速器方面,英伟达几乎占据了绝对优势。可以说,在过去的几年,尤其是2015年以来,人工智能大爆发就是由于英伟达公司的GPU得到广泛应用,使得并行计算变得更快、更便宜、更有效。
2017年5月GTC 2017大会上,英伟达发布了面向高性能计算的新一代Volta架构加速器,Tesla V100。Tesla V100加速器采用12nm FFN工艺,搭载新款图形处理器GV100,拥有5120 CUDA、640个Tensor内核,分PCle和SXM2两版,双精度浮点运算能力分别可达7 TFLOPS和7.8 TFLOPS,单精度则为14 TFLOPS和15.7 TFLOPS。(翻译一下就是:堆了很多运算器,性能,特别,凶残。)
Tesla V100没有公开售价,不过典型的服务器大概要100万元。

▲Tesla V100中的新技术
截至目前,阿里云、百度和腾讯等企业均已在其云服务中部署Tesla V100,华为、浪潮和联想等原始设备制造商也已采用Tesla V100来构建新一代加速数据中心。
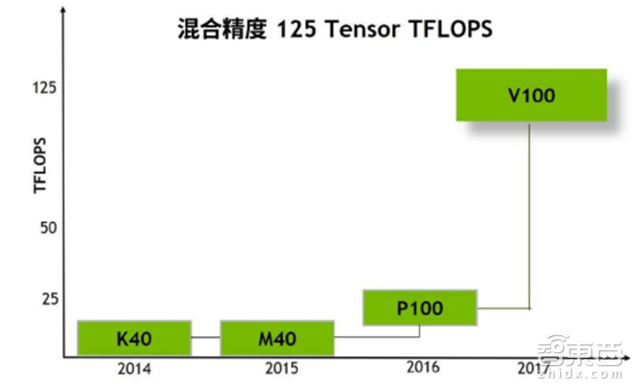
▲Tesla V100配备全新Tensor核心后深度学习运算能力达125Tensor TFLOPS
Tesla V100不仅仅是数据中心/HPC加速器,更针对深度学习算法和Caffe2、MXNet、CNTK、TensorFlow等框架新版本进行了设计,新的流多处理器(SM)架构提供独立、并行整数和浮点数据通路,配备全新Tensor核心,运算能力达125 Tensor TFLOPS,单精度矩阵-矩阵乘法比Tesla P100快1.8倍,混合精度矩阵-矩阵乘法比Tesla P100快9倍。据称,Tesla V100由数千名工程师经数年开发,研发投入相当于30亿美金。
Tesla V100软硬件架构解读

▲Tesla V100的正面与背面
Tesla V100采用与Tesla P100相同的SXM2主板外形,大小为140×78毫米,主要区别在于GPU由GV100代替了GP100。SXM2主板支持NVLink和PCIe 3.0连接功能,包含可为GPU供应各种所需电压的高效电压调节器,额定为300瓦热设计功耗(TDP)。工作站、服务器和大型计算系统中可应用一个或多个Tesla V100加速器。
从架构来看,Tesla V100不仅仅堆了更多更密集的运算单元以实现超强计算性能,也打通了更多的链路来实现资源更为高效的利用,降低功耗,并配套以CUDA 9提供了更为灵活的调度。下文提供一些Tesla V100架构思路以供启发。
GV100:堆了84个SM 640个Tensor核心
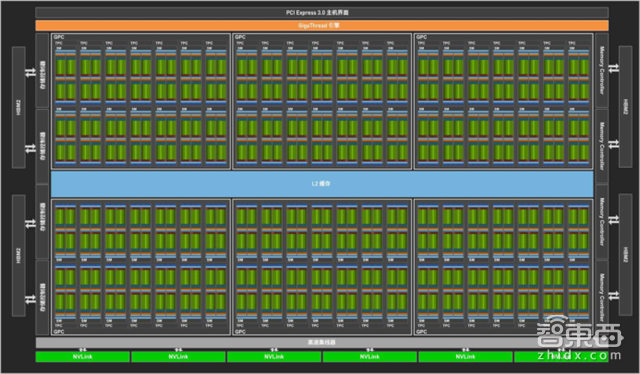
▲含84个SM单元的完整Volta GV100 GPU
与上一代Pascal GP100 GPU一样,GV100 GPU由6个GPU处理集群(GPC)和8个512位内存控制器组成,每个GPC拥有7个纹理处理集群(TPC),每个TPC含2个流多处理器(SM)。
含84个SM的完整GV100 GPU,总共拥有5376个FP32核心,5376个INT32核心、2688个FP64核心、672个Tensor核心以及336个纹理单元。每个HBM2 DRAM堆栈由一对内存控制器控制。完整的GV100 GPU总共包含6144KB的L2缓存。
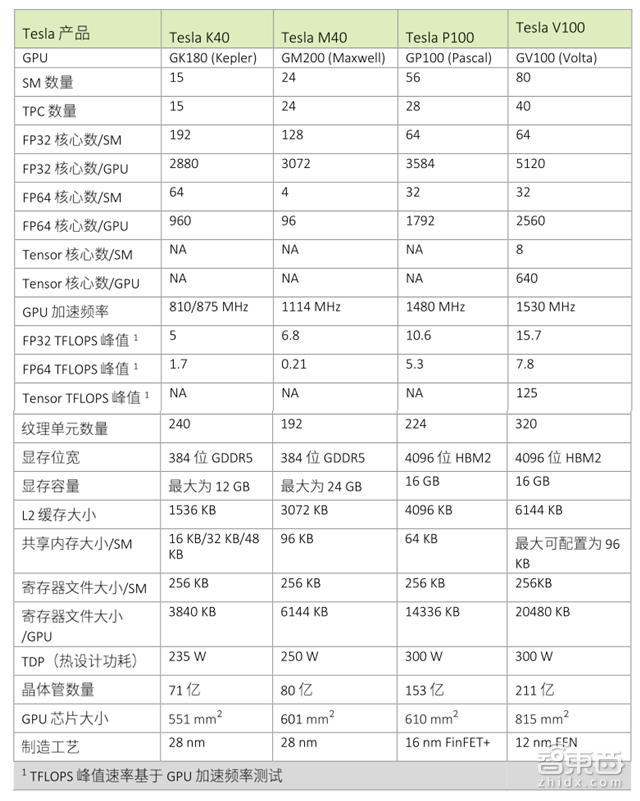
▲NVIDIA Tesla系列各GPU比较
GV100新增的流多处理器(SM)架构提供了性能、能效和可编程方面的重大改进,主要特性包括:
1、 新增专为深度学习矩阵算法构建的混精度Tensor核心,相较GP100在同一功率电路下训练可提升12倍TFLOPS;
2、在通用计算工作负载中的能效提高50%;
3、L1数据缓存性能大幅提升;
4、新增SIMT线程模型,可消除之前的SIMT和SIMD处理器设计中存在的限制。

▲Volta GV100流多处理器(SM)
Tensor核心:大型神经网络训练的关键
Tesla V100包含640个Tensor核心,可为训练和推理应用提供125 Tensor TFLOPS:每个SM有8个核心,SM内每块处理器(分区)有2个,每个Tensor核心每时钟执行64次浮点FMA运算。
Tensor核心及其关联的数据路劲经自定义设计,可以较高能效大幅增加浮点计算吞吐量。每个Tensor核心都在4×4矩阵中运行,并执行以下计算:
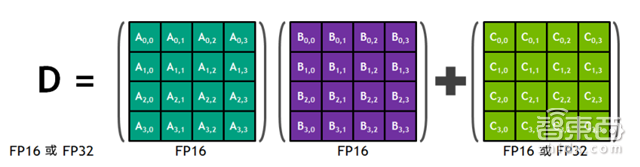
▲Tensor核心执行矩阵乘积累加运算,D=A×B+C
其中,A、B、C和D为4×4矩阵,矩阵乘法输入A和B为FP16,而累加矩阵C和D可以是FP16或FP32矩阵。特别指出的是,与无法同时执行FP32和INT32指令的Pascal GPU不同,Volta GV100 SM包含单独的FP32和INT32核心,允许以完整吞吐量同时执行FP32和INT32运算,并且还可增加指令发送吞吐量。

▲Tensor核心中的混合精度乘积累加运算
事实上,Tensor核心会用于执行更大型的二维或更高维的矩阵运算,这种运算都是由这些较小元素构建而成。
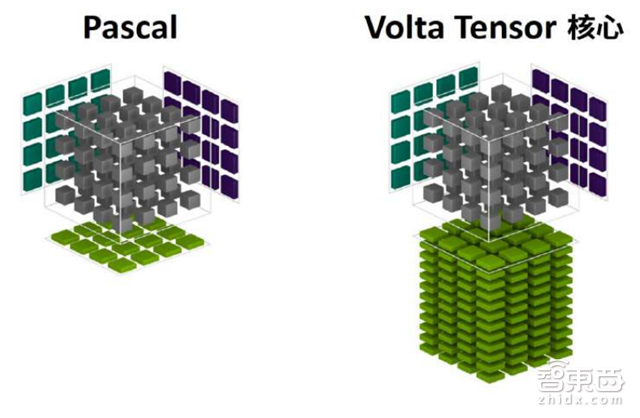
▲Pascal和Volta 4×4矩阵乘法运算
Volta Tensor核心可在CUDA 9 C++ API中存取并作为线程数级矩阵运算公开。该API公开专门化矩阵负载、矩阵乘积累加和矩阵存储运算,以高校使用CUDA 9 C++程序中的Tensor核心。此外,cuBLAS和cuDNN库也已经更新,以提供新的库接口将Tensor核心用于深度学习程序和框架。
L1数据缓存和性能共享
将数据缓存和共享内存功能整合进单一内存块中,可为两种类型内存访问提供出色的整体性能,带来更低延迟和更高带宽。整合后的容量可达128KB/SM,比GP100数据缓存大了七倍以上,不使用共享内存的程序可将其作为缓存,纹理单元也可使用该缓存。
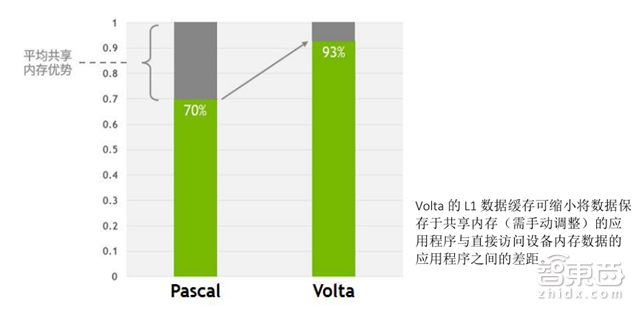
▲Pascal与Volta数据缓存的比较
计算能力7.0
GV100 GPU支持新的Compute Capability7.0,详情参见下表。
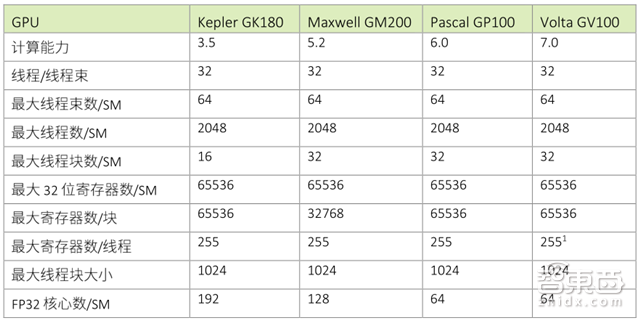
▲GK180、GM200、GP100和GV100计算能力对比
NVLink:第二代高速互联
NVLink最早于2016年随Tesla P100加速器和Pascal GP100 GPU一起推出,是英伟达的高速互联技术。Tesla V100引入了第二代NVLink,可以提供更高的链路速度(从20GB/s增加到25GB/s)以及每个GPU更多的链路(从4条增至6条),并在CPU主控、缓存一致性和可扩展性方面实现改进。

▲“配备V100的DGX-1”中使用的混合立体网络NVLink拓扑
优化HBM2内存架构
Tesla P100是首个支持高带宽HBM2内存技术的GPU架构。Tesla V100的HBM2更快、更高效:HBM2内存由内存堆栈(与GPU位于同样的物理包)组成,每个堆栈使用四个存储器晶片,从而获得最大为16GB的GPU内存,与传统GDDR5设计相比,可显著节省能耗和占用空间,从而允许在服务器中安装更多GPU。
此外,Tesla V100 HBM2内存子系统支持通过纠一位检二位(SECDED)纠错码(ECC)来保护数据,为已受数据损坏影响的计算应用程序提供更高可靠性。这在大型集群计算环境中尤为重要,因为其中的GPU需处理非常大的数据集亦或长时间运行应用程序。

▲V100上HBM2内存加速与P100的对比
复制引擎支持多处理器数据传输
英伟达GPU复制引擎可在多个GPU间或GPU与CPU间传输数据。之前的复制引擎需要固定(不可分页)源内存区域和目标内存区域,而新的Volta GV100 GPU复制引擎可为没有映射至分页表的地址生成分页错误,然后内存子系统可处理分页错误,并将地址映射至分页表,之后复制引擎便可执行传输。目前,此功能可用于ATS系统中。
CUDA:通用并行计算架构的改进
▲基于CUDA平台的深度学习创新时间线
CUDA是英伟达建立的并行计算平台和编程模型,为开发者提供基于英伟达GPU的开发环境,以便其使用C和C++扩展构建大规模并行应用程序。Volta架构的改进将进一步增强CUDA应用程序中并行线程的功能,使CUDA平台的能力、灵活性、生产力和可移植性实现下述提高:
1、独立线程调度优化
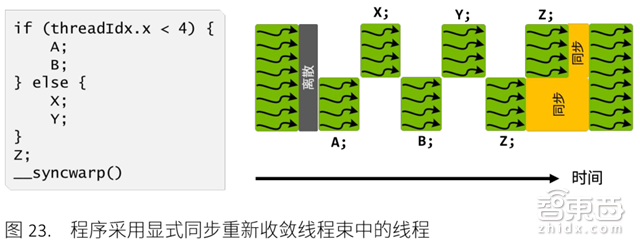
▲Volta独立线程调度功能:可交错执行离散分支中的语句,帮助执行精细并行计算
Volta GV100是首款支持独立线程调度的GPU,允许GPU执行任何线程,从而程序中的并行线程之间实现更精细的同步与协作。
Pascal和早期英伟达GPU均以SIMT形式执行含32个线程的线程组,虽然减少跟踪线程状态所需的资源数量,重收敛线程以最大化并行性,但离散去相同线程束或不同执行状态的线程无法互相发送信号或交换数据,从而产生不一致性。
Volta调度优化器通过在所有线程之间实现等效并发(通过无饥饿现象算法,确保所有线程对争用资源拥有相应的访问权限,将同一线程束中的活动线程一并分组到SIMT单元,以子线程数粒度进行离散和重新收敛,执行相同的代码),避免了上述问题。
2、多进程服务

▲Pascal中的基于软件的MPS服务和Volta中硬件加速MPS服务对比
多进程服务(MPS)是Volta GV100架构的一项新功能(Pascal的CUDA MPS是一个CPU进程),专门用于在单一用户的应用程序中贡共享GPU。
Volta MPS可为MPS服务器的关键组件实现硬件加速,使MPS客户端将工作直接提交至GPU中的工作队列,降低提交延迟并增加总吞吐量(特别是用于高效推理部署),从而提升性能并改进隔离(服务质量和独立地址空间),增加MPS客户端的最大数量,将其从Pascal上的16个增加为Volta上的48个。
3、统一内存寻址和地址转换服务
CUDA 6曾推出有限形式的统一内存寻址,以简化GPU编程,该功能在Pascal GP100中通过硬件页面错误和更大的地址空间得到改进。Volta GV100中,全新的存取计数器功能可追踪GPU存取其他处理器内存的频率,帮助确保内存页面移动至访问页面最频繁的处理器的物理内存。此外,Volta还通过NVLink支持地址转换服务(ATS),为GPU提供对CPU内存的完整访问权限。
4、协作组

▲协作组在粒子模拟中的应用
并行算法中,线程通常需要通过协作来执行集群计算。构建这些写作代码需要对协作线程进行分组和同步。因此,CUDA 9引入了协作组,用于组织线程组的全新编程模式。协作组编程元素由以下元素组成:
1、专为深度学习矩阵算法构建的全新混合精度FP16/FP32 Tensor核心;
2、表示协作线程组的数据类型;
3、CUDA启动API定义的默认组(例如,线程块和网格);
4、将现有组划分为新组的运算;
5、同步组中所有线程的障碍运算;
6、检查群组属性以及特定于组的集合运算。
协作组以子线程块和多线程块粒度显示定义线程组,并且可以执行集合运算,让开发者以安全、可支持的方式通过灵活同步功能针对硬件快速进行各种优化;协作组还实现了抽象化,让开发者能够编写灵活、可扩展的代码,该代码可在不同的GPU架构中安全运行,包括扩展至未来GPU功能;Volta独立线程调度也以任意交叉线程束和子线程数粒度,为线程组实现更灵活的选择和划分;Volta同步真正实现了每线程操作。
推荐GV100的理由
GPU比CPU拥有更多的运算器,只需要进行高速运算而不需要逻辑判断,其海量数据并行运算的能力与深度学习需求不谋而合,也成为了高性能计算进一步发展的主流方案。而GV100,作为GPU界占据绝对优势的英伟达的新力作,具备了以下特点:
1、运算能力超强
GV100堆了84个SM、640个Tensor核心,相较GP100在同一功率下训练可提升12倍的TFLOPS。相应的,Telsa V100运算能力达125 Tensor TFLOPS,可以说是深度学习上游训练端的一个大杀器。
截至目前,Telsa V100已经用于英伟达首款深度学习和分析专用工作站DGX Station;阿里云、百度和腾讯等企业均已在其云服务中部署Tesla V100;华为、浪潮和联想等原始设备制造商也已采用Tesla V100来构建新一代加速数据中心。
2、新架构提升效能
Volta新增流多元处理(SM)架构,使用新的分区方法来提升SM利用率和整体性能。
全新的Volta SM的节能效率相较上一代Pascal产品提升50%,在同一功率电路下可显著提高FP32和FP64的性能;专为深度学习设计的Tensor核心在训练方面可提供高达12倍的TFLOPS峰值,推理方面可提供6倍的TFLOPS峰值。相比之前几代的GPU,GV100支持同时运行更多的线程、线程束和线程块,实现了性能、效能、可编程性方面的重大改进。
3、开发生态成熟
CUDA因统一而完整的开发套件,丰富的库,以及对英伟达GPU的原生支持而成为开发主流,目前已开发至第9代,开发者人数超过51万。CUDA工具包9.0版包含新的API以及对Volta功能的支持,并可以实现更轻松的编程。Caffe 2、MXNet、CNKT、TensorFlow等深度学习框架新版本以及其他框架皆可发挥出Volta的强大性能,缩短训练时间并获得更高的多节点训练。
4、有19439家合作组织
剽悍的硬件配上成熟的CUDA开发环境,英伟达已经形成,并正在巩固自己的AI生态。据称,在深度学习方面与英伟达有合作的组织已有19439家,覆盖金融、汽车、教育、互联网等各类领域。
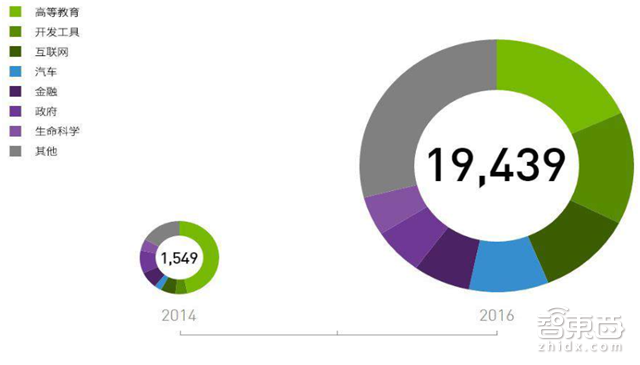
▲在深度学习方面与英伟达有合作的组织

▲英伟达GPU平台
智东西认为,Tesla V100的架构设计中,我们看到了英伟达强大的硬实力积累(堆运算器的能力),以及“并行思维”的启发(分类、同步等),结果就是非常凶残的浮点运算能力。而对于企业而言,浮点运算能力、功耗和成本是选择GPU的三个主要考量,再加上面对AI新蓝海的野心,所以我们会看到诸如百度这样,既和英伟达哥俩好,又跟AMD搞GPU技术联合实验室。毋庸置疑的是,AI芯片战已经打响,传统芯片商、新入玩家已经开始在占山头了(云端/数据中心、终端)。
深度学习上游训练端来看,GPU是当仁不让的第一选择,而英伟达先发的构架升级以及广泛成熟的开发生态环境优势明显,占据了绝对优势。目前来看,英伟达数据中心GPU的主要竞争对手有GPU市场占有率第二的AMD、手握FPGA的英特尔和手握TPU的谷歌。
深度学习的下游推理端来看 ,除了主流的GPU芯片之外,还包括CPU、FPGA( Xilinx、英特尔Altera、Lattice 及 Microsemi等)、ASIC (英特尔Nervana Engine、Wave Computing数据流处理单元、英伟达的DLA、谷歌TPU、寒武纪NPU等),竞争态势中英伟达依然占大头。但随着AI的发展,FPGA的低延迟、低功耗、可编程性和ASIC的特定优化和效能优势将满足一些特定方向的需求。
下载提醒:如果想收藏本文的报告全文,可以在智东西(公众号:zhidxcom)回复关键词“nc215”下载。
智能内参
权威数据·专业解读 读懂智能行业必看的报告
在智东西回复“智能内参”查看全部报告

