









智东西(公众号: zhidxcom)
编 | 智东西内参
深度学习(DL)是人工智能(AI)的一个热门研究领域。足够多的例子证明,深度学习能够发现高维数据中的复杂规律,可应用于科研、商业和军事等领域。如今,深度学习正在携手大数据、GPU计算共同引爆AI革命。
从打败世界围棋冠军的AlphaGo开始,人工智能声名鹊起,活跃在智慧医疗、自动驾驶、语音助手等诸多领域,逐渐浸入人们的生活。以智慧医疗为例,通过用海量来自行业的真实数据进行训练,人工智能可以快速高效地完成症状预判、预测潜在的药物分子活性、癌症早筛等任务,真正惠及于民。
而做出这一切成就的前提是拥有海量的数据和强大的算力。过去的半导体行业依赖于摩尔定律的推动,而GPU的出现为AI计算带来了新的动力。近十年来,GPU的长足发展,使之在通用计算方向拥有彪悍的数据处理能力,极大拓展了AI的应用范围。
不过,构建一个AI平台不仅需要搭建包含许多GPU等硬件的服务器,还有诸多挑战:
1、深度学习需要用海量数据以更好的完成特征提取,当数据量不断增大,传统硬件方案显得力不从心。
2、深度学习在软件设计方面耗费的实践价值可达数十万美元,而开源软件需要数月时间才能变得稳定;
3、深度学习开发者需要方便易用的框架、库、驱动程序等复杂组件;
4、深度学习在上述软件堆栈方面需要大量的人才进行编写和维护。
为应对这些挑战,尽可能满足开发者的需求,NVIDIA推出了其吞吐量可媲美250台CPU服务器的深度学习超级计算机——NVIDIA DGX-1,专为深度学习和高性能计算而设计。
本期的智能内参,我们推荐英伟达搭载Tesla V100 GPU的NVIDIA DGX-1系统架构白皮书,结合DGX-1在具体行业的应用,解读英伟达DGX-1的系统架构、性能优势,以及为相关AI企业和研究人员提供参考。如果想查阅此白皮书《搭载Tesla V100 GPU的NVIDIA DGX-1系统架构 》,可直接点击左下方的“阅读原文”下载。
以下为智能内参整理呈现的干货:
一、加速模型训练的神器
人工智能(AI)可以是什么?英伟达在其系列视频《我是人工智能》中说,AI是医生,辅助Sigma Technologies 公司更早、更有效地检测和识别肺癌;AI是可靠的司机,帮助卡车制造商 PACCAR 实现车队的自动驾驶;AI是创作者,打造出从广告片直到剧情片等一系列具有惊人创意和情感的艺术作品;AI是辛勤的农夫,助力收割机Agrobot,旨在革新农业的未来;AI也是保卫者,协助肯尼亚政府追踪斑马的行动轨迹以使其免遭灭绝。
英伟达DGX-1超级计算机,能够做到让上述各行各业个开发者们均能方便快捷地享受到AI带来的便利。
1、医疗行业
由美国麻省综合医院创立的机构CCDS的数据科学家拥有从全球各地不断汇入的海量医学影像,从16年12月收到第一代DGX-1 AI超级电脑开始,到现在CCDS已经开发出数十种深度学习训练算法,在放射学、心脏病学、眼科学、皮肤病学和精神病学等领域开展工作。
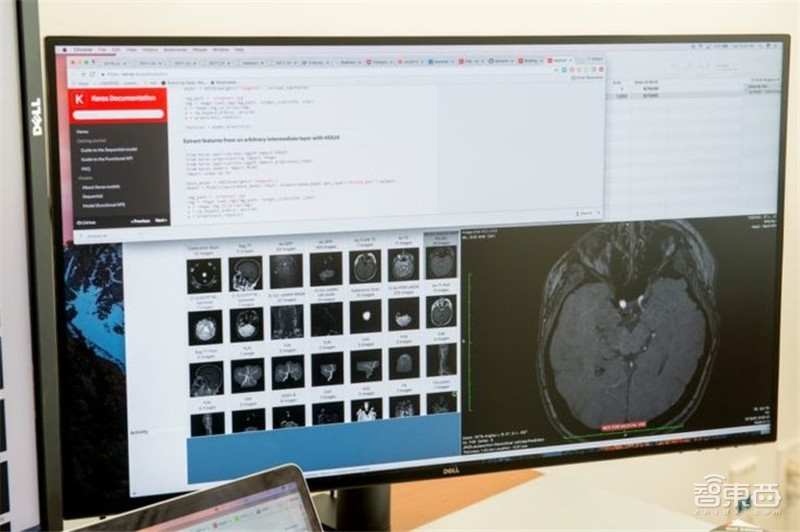
▲DGX系统协助CCDS数据科学家执行各种AI研究计划
将庞大的并行计算阵列引入临床设备非常困难,但NVIDIA Tesla系列GPU的强大算力使得紧凑的并行计算模块成为可能。在GPU上运行2001年研究所用的数据集时,其系统性能可以提升到每秒13至14帧。据该小组研究,NVIDIA的GPU比当时最新多核CPU至少快了70倍,而且对于较大规模的体纹理数据性能更为突出。
2、转舵AI的汽车行业
自动驾驶技术以超越人类的准确度和即时决策能力,有望改变人类旅行、货物运输以及城市设计,其市场2025年的估值为400亿美元,商机相当庞大。
自动驾驶需要高性能、低能耗的 AI 运算硬件。而为自动驾驶汽车提供高度精确感知系统的关键是快速开发和训练深度神经网络模型,以迅速收集和处理信息,即时决策来规避安全风险。
由沃尔沃汽车和供应商 Autoliv 共同创立的合资企业Zenuity拥有丰富的深度学习经验,Zenuity清楚地知道,要处理指数级增长的感测数据,深度学习训练平台不仅需要具有突破性的性能,还要能让研究人员迅速测试模型,缩短开发周期,避免把时间浪费在设计打造软硬件以及排查故障上。
最终,Zenuity选择了DGX-1深度学习平台,Zenuity深度学习部门经理Benny Nilsson 表示:“DGX-1无疑是AI和深度学习领域的黄金标准”。

▲Zenuity自动驾驶汽车
3、实时视频检测与分析
深度学习技术的兴起,也为视频内容分析提供了新的途径。目前深度学习计算框架更多运行在单个节点上,多节点之间的扩展性较差,深度学习模型主要依赖于单精度运算,可在有限空间中承载更大的模型。而NVIDIA DGX-1的强悍参数使它足以胜任庞大的深度学习任务。
中科院自动化研究所模式识别国家重点实验室也利用NVIDIA DGX-1来为实现实时的视频超分辨率而提速。所谓视频超分辨率,即是从低分辨率视频中恢复高分辨率视频,相比基于CPU的计算,DGX-1将速度提升超过50倍,并达到实时处理的效果。
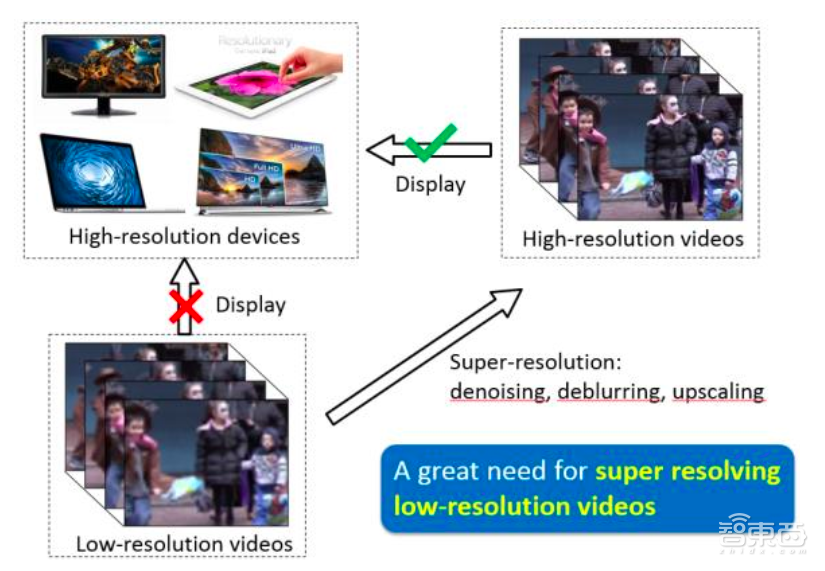
▲中科院自动化研究所模式识别国家重点实验室的视频超分辨率研究
4、网易全产业链AI
受益于DGX-1的性能优势,网易得以更快、更准确的训练模型,优化翻译引擎的响应速度,支持智能化服务新玩法的落地。未来,除了音乐和游戏业务外,网易在包括云计算、教育、新闻、电商等全产业链业务都将加持AI技术。
网易感知与智能中心的技术专家刘东认为,中心大量使用GPU来进行深度学习训练,DGX-1带来主要的好处是加速模型训练,此前在单节点上进行中等规模的数据集训练可能需要1个月的时间,现在使用DGX-1大约7-10天就会有结果,也就是说能试验更多的算法,产品更新也会更快。
二、高性能背后的秘密,DGX-1系统组件详解
前面说了那么多NVIDIA DGX-1深度学习超级计算机的应用,它为何有如此强大的算力呢?
顾名思义,DGX-1是一个专为深度学习打造的集成系统,能够为几百上千层神经网络提供高性能计算(HPC)能力。
在DGX-1问世时,NVIDIA创始人兼CEO黄仁勋曾说过,3000人花了3年才研发出这样一款深度学习超级计算机,足见其研发难度之高。
每台DGX-1配有8块NVIDIA Tesla系列V100 GPU加速器,其性能相当于250台传统CPU服务器,其使用的高性能NVLink GPU互联技术大大提高深度学习训练的扩展性。
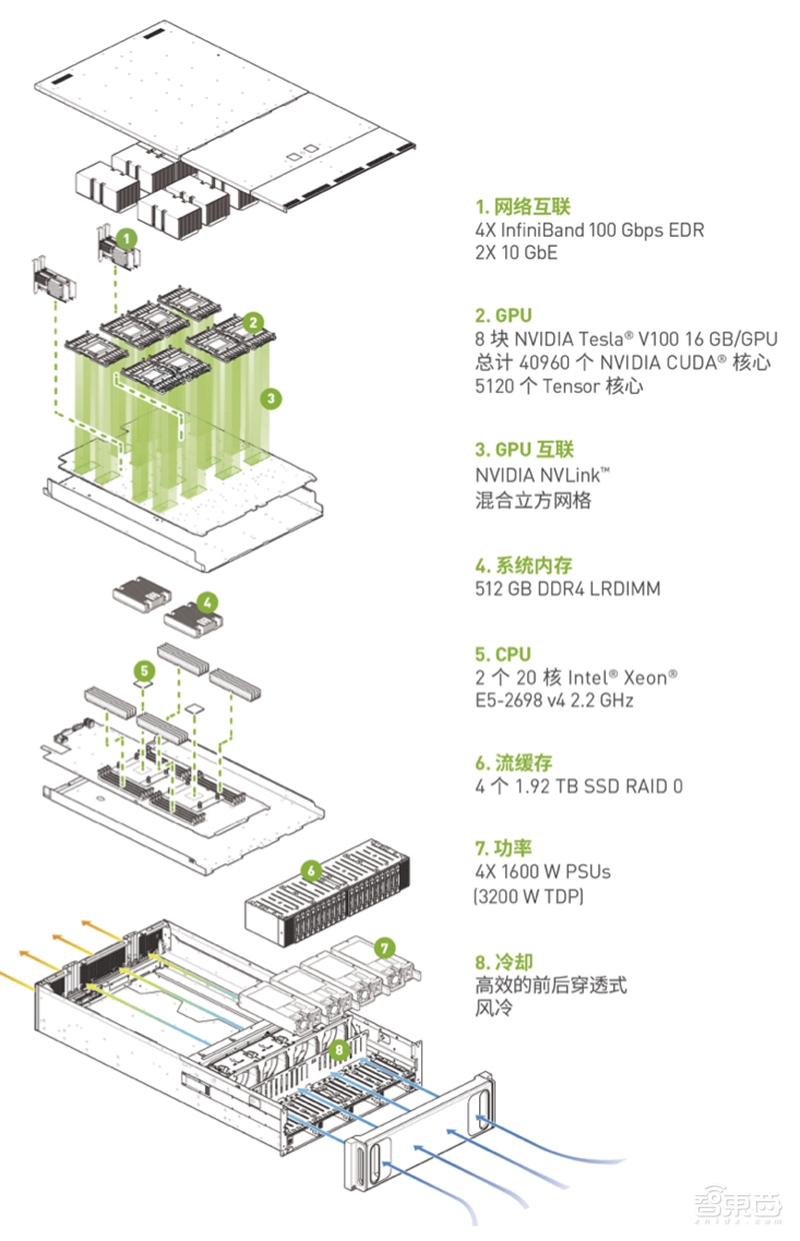
▲搭载V100的DGX-1系统组件
搭载Tesla V100的NVIDIA DGX-1主要有如下几个组件:
1、 NVIDIA Tesla V100
Tesla V100是NVIDIA最新款加速器,Volta架构是NVIDIA第一款专为AI打造的Tensor核心技术的GPU架构,为DGX-1提供了更高的AI和HPC计算能力。每个V100加速器配有的GV100 GPU包含80个流多元处理器(SM)。

▲Tesla V100加速器
2、NVIDIA NVLink技术
每个Tesla V100拥有6个NVLink连接,分别具有50GB/秒的双向带宽,双向总带宽每秒达300GB。当扩展到所有8个GPU时,NVLink的优势最大,其总体性能优势比PCle高出约30%。
3、双路Intel Xeon CPU
DGX-1内置了两块CPU,用于开机、存储空间管理和深度学习机构协调。
4、QUAD EDR IB
DGX-1配有4个QUAD EDR IB(扩展数据速率InfiniBand)端口,兼具高频带宽与低延迟特性,总双向通信传输速率达到每秒800GB。
5、三个机架单位的封闭式设计
为了节省电量,DGX-1采用三个机架单位的封闭式设计,可置入精巧的机架空间。
三、DGX-1的亮点黑科技
除了拥有出色的硬件设计外,DGX-1还拥有专门针对深度学习的系统软件和强大软件库,经过和NVLink以及8个GPU的配合,DGX-1能为生产和研究领域提供灵活的深度学习应用开发和部署平台。
借助集成的NVIDIA深度学习软件堆栈和DGX-1云管理服务,DGX-1可以在短短一天的时间开始深度学习任务,同时将设置工作减至最少,使得用户无需花费数月的时间来集成、配置和排除硬件软件故障。
这里,我们将详解Tesla V100采用的NVLink技术和 DGX-1 软件两大亮点。
1、NVLink
考虑到通信运营成本较高,开发者必须通过计算重叠数据传输或通过 PCIe 互联仔细编排GPU 访问以大幅提升性能。随着GPU 运行速度越来越快,以及GPU/CPU 比率不断攀升, 更高性能的GPU 互联技术为用戶提供了更灵活的通信调度,亦需要其来正确平衡更高的GPU 吞吐量。这项挑战促使了NVLink 高速互联技术的问世。
NVLink是NVIDIA打造的世界上第一个灵活可扩展的高速GPU互连方案,该技术可实现NVIDIA GPU 与同代GPU 或 支持NVLink 的CPU 以及节点内其他设备之间的连接。
NVLink 使用NVIDIA 全新高速信号互联技术(NVHS)。NVHS 通过差分对传输数据,速率高达25 Gb/ 秒。其中8 个差分连接组成“ 子链路” (子链路负责一个方向的数据传输),两个 子链路(一个子链路对应一个方向)组成一个“ 链路” (一个链路可连接两个处理器, 如GPU 到GPU 或 GPU到CPU)。单个链路支持端点间高达50 GB/ 秒的双向带宽。多个 链路可整合至一起,以实现处理器间更高的带宽。Tesla V100 采用的NVLink 可支持多达6 个链路,实现理论上的最大双向总带宽,即300 GB/ 秒。
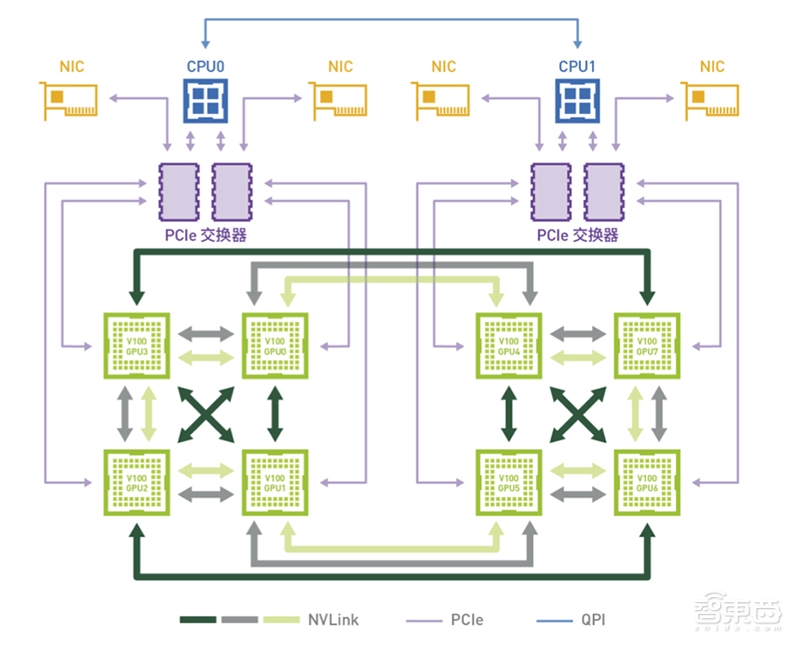
▲DGX-1采用8-GPU的混合立体互联网络拓扑
2、DGX-1软件
目前已有可以大规模运行深度学习的DGX-1 软件。其主要目标是让从业者能够在DGX-1 上 部署深度学习框架和应用程序,同时将设置工作减至最少。该平台软件的设计理念为最大限度地减少服务器上安装的操作系统和驱动程序,并通过由NVIDIA 维护的DGX Container 注册表在Docker容器内配置全部应用程序和SDK 软件。DGX-1 的可用容器包括多个经优化的深度学习框架、第三方加速解决方案及NVIDIA CUDA 工具包。
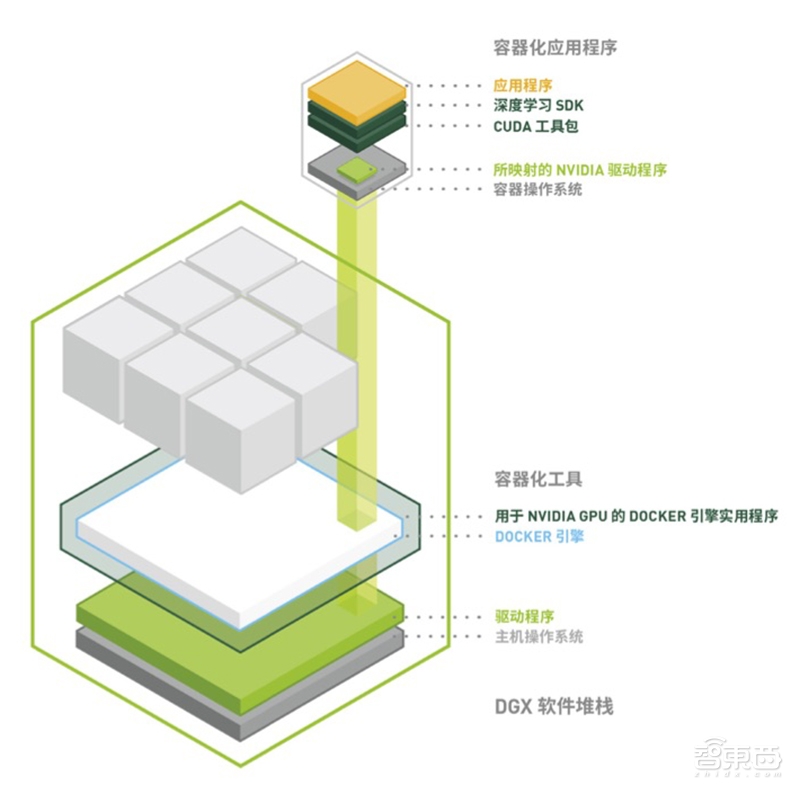
▲DGX-1深度学习软件堆栈
此软件架构具有很多优势:
(1)每个深度学习框架都位于单独的容器内,所以每个框架都能使用不同版本的库。
(2)系统易于维护,且由于应用程序并非直接安装于操作系统上,所以操作系统镜像非常干净。
(3)可无缝提供安全更新、驱动程序更新及操作系统补丁。
智东西认为,在深度学习蓬勃发展的今日,英伟达专为深度学习打造的超级计算机DGX-1可以说是应运而生。DGX-1不仅是一个硬件强大的超级计算机,更是深度学习应用的综合解决方案平台,为开发者提供了强大的开发工具,大大降低开发门槛。
DGX-1适用于数据中心环境的大规模部署。它可以为深度学习任务带来惊人的运算力,强力地推动人工智能或深度学习的发展,能够在智慧医疗、金融等诸多领域大显身手,引领人工智能的浪潮。
如今,智慧医疗、科学计算等行业的一些公司或研究机构已经成为了DGX-1的用户,这也反映出了这些行业对算力的迫切需求,未来,随着深度学习的快速普及,行业对DGX-1这类的AI超级计算机的需求会更加强烈。
如果想查阅此白皮书《搭载Tesla V100 GPU的NVIDIA DGX-1系统架构 》,可直接点击左下方的“阅读原文”下载。
