








智东西(公众号:zhidxcom)
编 | 心缘
昨日,在清华大学主楼举办的第三届未来芯片论坛为AI芯片界献上一份大礼——《人工智能芯片技术白皮书(2018)》(以下简称《白皮书》)!

该白皮书集成了中国工程院院士尤政、清华大学微电子所所长魏少军等21位国内外高校顶级研究学者和产业界资深专家,融入10余位IEEE Fellow的智慧结晶,首次整合国际化学术和产业资源联袂发布,是未来芯片技术高精尖创新中心的倾力之作。
《白皮书》首次对“AI芯片”这一概念提出了得到广泛认可的定义,解决了目前行业大热但尚无统一定论的问题——究竟什么是AI芯片?
对此,《白皮书》集中探讨了通用芯片、端侧芯片和神经形态计算芯片三类AI芯片,对AI芯片从技术趋势到产业趋势做了全面解读,不仅高屋建瓴地对AI芯片领域的创新成果和产业现状进行全盘梳理,客观阐述AI芯片存在的技术难题,还就未来风险提出预判,并首次提出了“AI 芯片基准测试和发展路线图”。
尽管此前AI芯片趋于火热,并没有从技术的内涵、脉络、标准以及发展趋势等方面进行深入专业阐述的研究报告,《白皮书》的发布填补了这一空白。
因此,智东西对《白皮书》进行抽丝剥缕,提炼和解读了对行业最有价值的六大干货,包括三类AI芯片的应用场景、三大趋势、基准测试和发展路线图、两类瓶颈、四大存储技术和五类新兴计算技术,力求帮助产学界相关人士更为清晰的看到AI芯片目前的发展全貌以及未来趋势。

一、围绕云端和边缘计算,三类AI芯片加速进行时
尽管如今科技界几乎无人不知AI芯片,但目前关于AI芯片的定义还没有一个严格和公认的标准。
《白皮书》在“AI芯片的关键特征”一章中开篇引用业界对AI芯片的宽泛定义:“只要面向人工智能(AI)应用的芯片都可称之为AI芯片”。
紧接着,该文直接点明探讨的三类AI 芯片:
(1)经过软硬件优化可以高效支持 AI 应用的通用芯片,例如 GPU。
(2)二是侧重加速机器学习算法的芯片,这也是目前 AI 芯片中最多的形式。
(3)三是受生物脑启发设计的神经形态计算芯片。”
在对当下谈到AI芯片就不得不谈的新型计算范式、训练和推断、大数据处理能力、数据精度、可重构能力以及软件工具进行清晰的阐述后,该文直指AI芯片主要面向的云端和边缘两大目标领域。
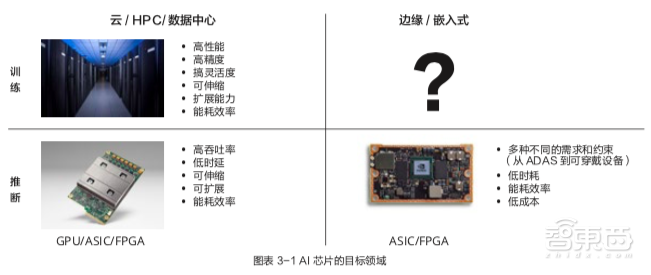
1、云端AI计算:大厂云集,FPGA崛起
在云端,通用GPU如英伟达的GPU芯片被广泛应用于深度神经网络(DNN)训练和推理,相比CPU可实现10-100吞吐量,是当前AI训练领域使用最广泛的平台。
此外,许多公司开始设计专用芯片以达到更高效率,比如谷歌打造了使用专用架构ASIC芯片Google TPU,能高效支持云端训练和推理。此外,我国百度、阿里、华为也分别宣布自研云端AI芯片。

科技巨头纷纷跨界造芯,芯片巨头和芯片创企自然也不甘其后。英特尔推出Nervana神经网络处理器 (NNP),Graphcore、Cerebras、Wave Computing、寒武纪及比特大陆等创企也纷纷加入战场。
因为既支持大规模并行的硬件设计,比GPU推断的延时和功耗更低,又能很好支持不同的数值精度,适合低精度推断, 具有可编程能力的FPGA在云端推断也逐渐占据一席之地。赛灵思、英特尔等厂商推出了专门针对 AI 应用的FPGA硬件和软件工具。
2、边缘AI计算:自动驾驶和手机战场火热
随着AI应用生态的爆发,人们对许多AI应用有了更高需求。针对高度需要低延迟、带宽和隐私的应用,如自动驾驶、可穿戴、移动手机等五花八门的终端应用场景,芯片厂商和终端厂商都开始发力。
在自动驾驶领域,英特尔MobileEye芯片和英伟达NVIDIA Drive P系列可以支持半自动驾驶和完全自动驾驶。在智能手机方面,已有苹果、华为、高通、联发科和三星等大厂推出手机AI芯片。
另外,地平线、寒武纪等创企纷纷入局终端AI芯片,包括ARM、Synopsys等传统的IP厂商也开始为智能摄像头、无人机、工业和服务机器人等物联网设备开发专用IP产品。
3、云和端的配合
目前云和边缘设备在AI应用往往是配合工作,通常是在云端训练神经网络,然后在云端或边缘设备上进行推断。边缘设备能力在增强,云的便捷也在向数据源头靠拢,未来数据本地化处理是大势索取,云和边缘设备以及连接他们的网络可能会构成一个巨大的 AI 处理网络。
4、“仿生电脑”神经形态芯片
在GPU、FPGA、ASIC芯片在市场上得到越来越多应用的同时,一种模拟生物脑的电子芯片——神经形态芯片正在兴起,《白皮书》特意将其单独放在一章进行详细介绍。
神经形态计算的算法模型大致可分为人工神经网络 (Artificial Neural Network, ANN)、脉冲神经网络 (Spiking Neural Network, SNN) ,以及其他延伸出的具有特殊数据处理功能的模型。 其中ANN是目前机器学习特别是深度学习使用的主要模型。
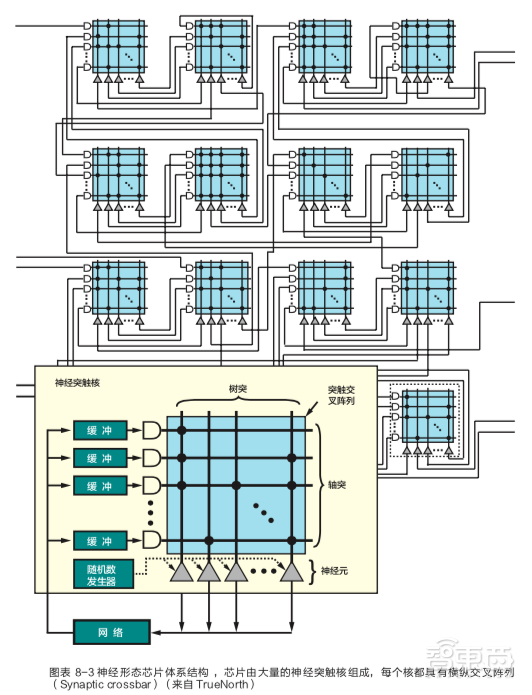
神经形态芯片有受生物脑启发的众核结构、事件驱动,采用数据流的方式表 达神经网络的连接关系,具有低功耗、低延迟、高速处理、时空联合等特点,可实现任意神经元间可缩放、高并行的神经网络互联,在智能城市、自动驾驶的实时信息处理、人脸深度识别、语音识别等领域都有出色的应用。
目前神经形态芯片在传统 CMOS 工艺下的物理结构较为成熟,但对于可以仿真大规模神经网络而言存在散热问题、互联和同步问题、过于单一的神经形态算法等带来的挑战。
对基于忆阻器交叉阵列的神经形态芯片而言, 它们既存在交叉阵列的规模、突触的连接方式和漏电流的控制等物理结构问题,在算法方面同样面临挑战,目前SNN相关算法还在研究阶段,该算法取得新的进展还需时间。
二、AI芯片架构设计趋势
《白皮书》第五章针对目前AI芯片架构设计的趋势进行总结和梳理,总要包括三个方面:一是云端AI计算对存储、性能和灵活性的需求提升,二是边缘设备将能耗效率推向极致,三是软件成为定义AI芯片能力的关键。
1、云端训练和推断:大存储、高性能、可伸缩
英伟达V100 GPU和谷歌Cloud TPU是目前云端商用AI芯片的标杆,从中看到云端AI芯片在架构层面的几个发展趋势:
(1)存储的需求(容量和访问速度)越来越高。
(2)处理能力推向每秒千万亿次(PetaFLOPS),并支持灵活伸缩和部署。
(3)专门针对推断需求的 FPGA 和 ASIC。
2、边缘设备:提高效率到极致
相比云端应用,边缘设备的应用需求和场景更为复杂,目前边缘设备AI芯片的关键任务是提高“推断”效率,衡量 AI 芯片实现效率的一个重要指标是能耗效率TOPs/W。
当前有效的方法主要有如下几点:
(1)降低推断的量化比特精度,《白皮书》称这是最有效的方法。
(2)结合一些数据结构转换来减少运算量。
(3)减少对存储器的访问,这也是缓解冯·诺伊曼“瓶颈”问题的基本方法。
(4)应用各种低功耗设计方法。
(5)从整个系统的角度考虑架构的优化,各部件协同作用以达到最佳效率。
3、软件定义芯片
软件是实现不同AI任务的核心,因此AI芯片必备的特性是能实时动态改变功能来配合软件的计算芯片,可重构计算基数也因此被公认为是突破性的下一代集成电路技术和非常适合AI芯片设计的技术。
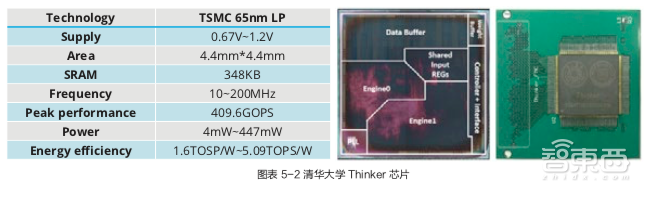
例如清华大学微电子所设计的AI芯片 Thinker通过三个层面的可重构计算技术来配合软件,这三个层面分别是计算阵列重构、存储带宽重构和数据位宽重构。
三、AI芯片基准测试和发展路线图
对于产学界来说,客观的评估方法和发展路线图都不可或缺,然而当前AI芯片领域有着越来越多的研发团队,却缺乏统一权威的相关标准。
这是《白皮书》最重磅的新内容,放在最后一章压轴出场。《白皮书》第九章开篇写道,在AI芯片开发热潮中,客观评估AI芯片的基准测试(Benchmark)和可靠预测A芯片发展路径的路线图(Roadmap)都是必不可少的重要工作。
基准测试旨在提供客观评估和比较不同AI应用的芯片。针对目前已经出现的用来实现不同形式的神经形态计算和机器学习加速的各种材料、器件和体系结构,清楚定义一组性能要求和量化参数,对于进行基准测试和指导研究方向非常重要。
另外,一个基于技术、设计或应用的共性明确路线图不仅可以提供衡量技术发展的指标,还有助于确定研究差距和关键挑战。
《白皮书》认为,普适的“最佳”器件、架构或算法很难找到,一些新兴器件可能在非布尔架构中表现得更好。对基准测试和路线图的探讨必须考虑到 与计算本身相关的能量、性能和准确度、工艺进步和创新引入未来的芯片对硬件平台性能的改变、新AI算法的不断引入等各种因素。
为了应对这些挑战,《白皮书》提出人们需要收集一组架构级功能单元,确定定量和定性的优值 (Figures of Merits, FoM)并开发测量 FoM 的统一方法,并对为AI芯片开发统一的基准测试方法提出许多详细的建议。
四、AI芯片的两大技术挑战
AI算法和应用的快速发展对AI硬件产生更高的需求,但在当前的技术框架下,AI芯片还存在着一些瓶颈。《白皮书》第四章对当前AI芯片主要存在的两大困境进行分析,并给出一定的解决思路。
1、冯诺依曼瓶颈
提高 AI 芯片性能和能效的关键之一在于支持高效的数据访问。在AI芯片实现中,基于冯·诺 伊曼体系结构,提供运算能力相对简单易行,但由于运算部件和存储部件存在速度差异,访问存储器的速度跟不上运算部件消耗数据的速度,形成长期困扰计算机体系结构的冯·诺伊曼“内存墙”问题。
《白皮书》对此提出两种解决思路:一是通过减少神经网络的存储需求等方式减少访问存储器的数量;二是尽量拉近存储设备和运算单元的“距离” 以降低访问存储器的代价。
2、CMOS工艺和器件瓶颈
构建计算系统的基础是CMOS技术的芯片,但目前CMOS器件的横向尺寸接近几纳米,层厚度只有 几个原子层,会导致显著的电流泄漏,降低工艺尺寸缩小的效果,而且其纳米级晶体管的能耗非常高,很难实现密集封装。
另外,越来越多的数据对存储提出跟高要求,目前DRAM技术已接近极限,是NAND闪存,DRAM和 非易失存储技术的主力NAND闪存都是独立于计算核心的,和计算核心进行数据交换的时间和能耗代价非常大。目前能够和计算核心紧耦合的片上存储器的唯一方案是SRAM,其容量为兆级。
在计算架构和器件层面,需要具有生物系统优点而规避速度慢等缺点的器件和材料。近年来, 可以存储模拟数值的非易失性存储器兼具存储和处理数据能力,可以破解传统计算体系结构的一些基本限制,有望实现类脑突触功能。
五、AI芯片中四类存储技术
数据访问是提高AI芯片性能和能效的关键要素,因此AI芯片对存储技术提出越来越细化的需求。《白皮书》第六章不仅介绍了AI芯片中常用的三类存储技术,还就新兴非易失存储(NVM)技术进行答疑解惑。
1、AI友好型存储器
近期,因为AI和大数据处理对高带宽、大存储容量的内存需求,GPU、FPGA和ASIC等面向数字神经网络的加速器迫切需要AI友好型存储器,
2、片外存储器
由于高密度的单元结构特点,DRAM和NAND闪存通常被用作具有相对较大容量的片外存储器。最近,三星已经开发出 96 层 3D NAND。
3、片上(嵌入式)存储器
中期,基于存内计算的神经网络可以为规避冯·诺依曼瓶颈问题提供有效的解决方案,其中SRAM因为能连接逻辑和存储器电路,且与逻辑器件完全兼容,已成为不可或缺的片上存储器。
4、新兴存储器
最后,新兴NVM技术将提供更好的存储速度和低功耗,能显著改善用于商业和嵌入式应用的 AI 友好型存储器。基于忆阻器的神经形态计算可以模拟人类的大脑,是AI芯片远期解决方案的候选之一。
六、五大新兴计算技术
尽管成熟的CMOS器件已经被用于许多新的计算范例,但新兴器件有望在未来更好地显著提高系统性能并降低电路复杂性,解决上述种种瓶颈。
《白皮书》第七章就对近内存计算、存内计算、基于新型存储器的人工神经网络、生物神经网络和对电路设计的影响五点来探讨,给读者关于AI芯片前沿计算技术的启发。
1、近内存计算
近存储器计算可以通过将存储器层置于逻辑层顶部而进一 步实现高性能并行计算。
2、存内计算(In-memory Computing)
最新进展已证明存内计算具有逻辑运算和神经网络处理的能力,可显著降低功耗和延迟。
3、基于新型存储器的人工神经网络
铁电存储器(FeRAM)、相变存储器(PCM)等新兴非易失性存储器件可用于构建待机功耗极低的存储器阵列,它们都可能成为模拟存内计算的基础技术,既能实现数据存储功能,又能参与数据处理。
4、生物神经网络
一种更具生物启发性的方法是采用脉冲神经网络等,更严格地模拟大脑的信息处理机制。IBM TrueNorth和最近宣布的英特尔Loihi展示了使用CMOS器件的仿生脉冲神经网络硬件实现。虽然这种技术还处于早期阶段,但它代表了AI芯片的一个很有前景的长期方向。
5、对电路设计的影响
模拟电路操作也 给外围电路的设计带来了新的挑战,使得实现高精度模拟状态编程需要消耗更多周期和能效,因此编程电路和算法的优化尤为重要。另外优化尺寸大小、在很大的测量范围内精确测量电流值也是需要解决的问题
结语:AI芯片身肩重担,道阻且长
AI芯片是AI技术发展的基石,是推动整个半导体领域技术进步的重要力量,不过目前AI芯片尚处于“婴儿期”。
今年的AI芯片被炒到一个高潮,国内的百度、阿里,国外的谷歌、苹果、微软、脸书、亚马逊全部官宣进入战场,各家AI算法创企和传统半导体企业纷纷宣布跨行造AI芯片,这些努力会将AI芯片的发展推向一个全新的高度。
没人知道现在探索的道路究竟是否是最正确的道路,也没人知道AI芯片的泡沫何时破裂、多少公司会在竞争中溃败,但在愈发激烈的竞争一定会加速AI芯片以及AI算法的发展,为整个人类社会的发展带来福音。
