








智东西(公众号:zhidxcom)
编 | 翰阳
译 | 维金 书聿(新浪科技)
近日,百度在国外的一场人工智能基准测试中涉嫌造假并借此击败谷歌和微软一事被吵得沸沸扬扬。如今杂音渐渐散去,当事各方也对此做出了回应,我们也得以剥离出事件的真相。
这个比赛名为ImageNet Challenge测试,用于鉴定人工智能产品的技术能力。进行测试前,参赛方需要首先用150万张标准图片对产品进行“训练”,并向ImageNet Challenge的服务器提交代码。正式测试时,其需要对10万张以前从未见过的图片进行识别测试。
由于最终的比赛结果受概率因素干扰,依据规定,每个参赛方每周只能对代码进行2次测试,而百度在测试期内对其代码展开了大约200次测试,超标4倍。百度通过类似刷票的方式提高了其人工智能产品表现的精确度。
更通俗的讲,就是按规定,1个人1天只能买1张彩票,但百度为了提高中奖率,1天买了100张彩票。
最早曝光这个事情的主办方——ILSVRC,他们通过官方邮件的方式说明了百度所涉问题的来龙去脉。
以下为ILSVRC公布的邮件全文:
ILSVRC社区成员:
从2014年11月28日至2015年5月13日,百度一个团队使用至少30个帐号向测试服务器进行了至少200次提交,远超每周只能提交两次的限制。这其中包括在短时间内极高的用量。例如,在从3月15日至3月19日的5天时间里,提交次数超过了40次。图A显示了与百度团队相关的ImageNet帐号的提交次数。图B显示了这些帐号与所有其他帐号活跃程度的对比。
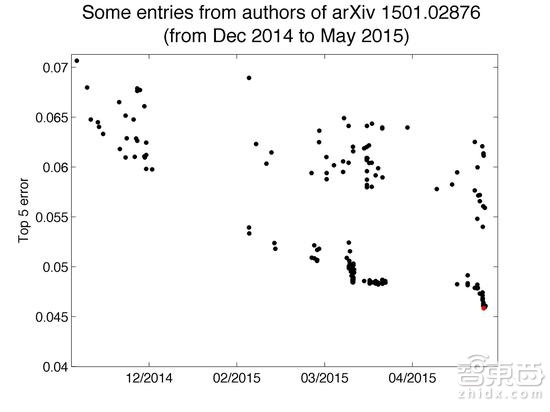
图A
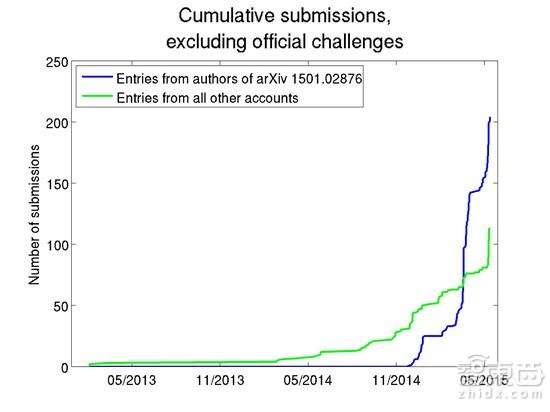
图B
这一期间获得的成果在近期的arXiv论文中进行了报告。由于违反了测试服务器的使用规定,这些结果可能无法与其他团队获得并报告的结果对比。通过在测试服务器上测试多种略有不同的解决方案,有可能会出现以下情况:1)基于测试结果,在一系列类似解决方案中选出最优方案,从而获得不大,但可能很重要的优势;2)直接基于测试数据,而不是训练和验证数据,选择进一步的研发方式。
我们于2015年5月14日注意到了这些违规,并于2015年5月17日通知了论文作者。2015年5月22日,在进行讨论,并征求我们研究社区高级顾问的意见之后,我们通知作者:
1.他们通过ImageNet测试服务器获得的结果无法与他人的结果直接对比。
2.对百度基于这些结果新提交的任何内容,我们持怀疑态度。这包括关于ILSVRC挑战任务的所有提交内容,以及共享数据集的一部分。因此,我们要求他们在未来12个月内停止向评估服务器和挑战任务提交任何内容。
我们正在与涉及此次事件的团队进行沟通。他们请求我们向整个社区转发包括以下声明在内的消息。需要指出,为了保持中立性和独立性,我们没有也不能与任何团队合作,以表述或评估结果。
目前测试服务器已经重新上线。我们期待继续在图像识别领域取得进展。
ILSVRC组织者
对此,百度当事团队承认了涉嫌舞弊的事实,并正式道歉。
以下为百度回应邮件全文:
ILSVRC社区:
近期,ILSVRC组织者联系了我们异构计算团队,并告知我们,我们超过了每周允许向ImageNet服务器进行提交的次数(在我们项目的生命周期中约为200次)。
我们对这一错误表示道歉,并将继续评估结果。我们已向研究论文《Deep Image: Scaling up Image Recognition》加入了注释,并将在了解更多情况后提供相关的更新。
我们支持ImageNet挑战的公平性和透明性,并将致力于科学发展的诚实性。
吴韧,百度异构计算团队
以上两封邮件均由新浪科技翻译。
说实话,这事儿出来是挺丢人的。不过,那么大一家公司,就为一场比赛,为何会不惜以违规手段获得更好的成绩呢?对于这个事儿,国外媒体是这样看待的。
以下内容节选自美国科技网站MIT Technology Review的评论,仍由新浪科技翻译:
百度、谷歌、Facebook等大型科技公司最近几年都投入巨资组建研发团队,专门研究深度学习技术,他们开发的机器学习软件已经在语音和图像识别领域实现了重大进展。这些公司都在不遗余力地聘请这个小领域的顶尖专家,经常会相互挖角。虽然学术界目前的人工智能标准测试数量不多,但却可以帮助这些研究团队与其他团队的成就进行对比,并向公众展开宣传。
百度通过作弊获得了不公平的优势。在这种测试中,很小的优势也会产生巨大的不同。
百度曾经表示,该公司的错误率仅为4.58%,击败了谷歌3月的4.82%。但一些专家指出,这么小的领先差距在这项测试中变得越来越没有意义。但百度和其他公司仍在努力吹嘘自己的结果,甚至不惜违反规则,足以表明在机器学习领域获得领先优势对他们而言的确意义非凡。

