








智东西(公众号:zhidxcom)
编 | 年年
导语:Nvidia训练出世界最大语言模型MegatronLM,模型使用了83亿个参数,比Bert大24倍,比OpenAI的GPT-2大5倍。
智东西8月14日消息,据外媒报道,Nvidia今天宣布,它已经训练出了世界上最大的语言模型MegatronLM,该模型使用了83亿个参数,比Bert大24倍,比OpenAI的GPT-2大5倍。
Nvidia还宣布其打破了BERT模型的最快训练时间记录,通过使用优化的PyTorch软件和超过1,000个GPU的DGX-SuperPOD,Nvidia能够在53分钟内训练出行业标准的BERT模型。
除此之外,Nvidia还通过运行Tesla T4 GPU和针对数据中心推理优化的TensorRT 5.1,成功将BERT推理时间降至了2.2毫秒。
一、世界最大语言模型MegatronLM比Bert大24倍
Nvidia今天宣布,它已经训练出了世界上最大的语言模型MegatronLM,这是这家GPU制造商旨在推进会话式AI的一系列更新中的最新版本。
为了实现这一壮举,Nvidia利用模型并行性,用一种技术将神经网络分割成多个部分,创建出了MegatronLM模型,该模型使用了83亿个参数,比Bert大24倍,比OpenAI的GPT-2大5倍。
Nvidia同时还宣布打破了BERT的最快训练记录,通过使用优化的PyTorch软件和超过1,000个GPU的DGX-SuperPOD,Nvidia能够在53分钟内训练出行业标准的BERT模型。
Nvidia深度学习应用(applied deep learning)副总裁Bryan Catarazano在与记者和分析师的一次谈话中说:“如果没有这种技术,训练这些大型语言模型可能需要数周时间。”
Nvidia还表示它已经实现了最快的BERT推理时间,通过运行Tesla T4 GPU和针对数据中心推理优化的TensorRT 5.1,BERT推理时间能够降至2.2毫秒。
Bryan Catarazano表示,当用CPU进行推理时,BERT推理最多需要40毫秒,而许多会话式AI系统今天会在10毫秒内完成。
▲MegatronLM代码已经在在GitHub上开源
Nvidia已经将MegatronLM代码在GitHub上开源,以帮助人工智能从业者和研究人员探索大型语言模型的创建,或使用GPU进行速度训练或推理。
二、53分钟训练BERT
2018年10月,谷歌正式推出了基于双向 Transformer 的大规模预训练语言模型“BERT”,并在短期内刷新了当时11 项 NLP 任务的最优性能记录。
BERT能高效抽取文本信息并应用于各种 NLP 任务,所以非常适合语言理解任务,如翻译,问答,情感分析和句子分类等。
Nvidia本次用带有92个DGX-2H节点的NVIDIA DGX SuperPOD在短短53分钟内就成功训练BERT-Large,这创造了新的记录。
为了实现这个新纪录,Nvidia用了1,472 个V100 SXM3-32GB 450W GPU和每个节点8个Mellanox Infiniband计算适配器以自动混合精度( Automatic Mixed Precision)运行PyTorch以加快处理数量和速度。
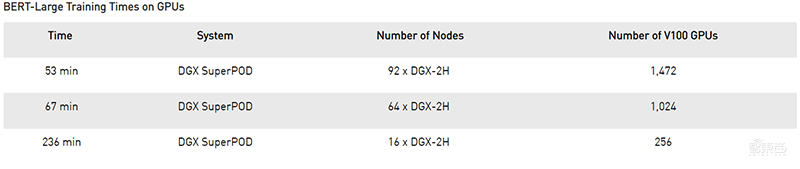
▲不同数量的GPU训练BERT-Large的时间
相比之下,对于只能访问单个节点的研究人员来说,使用16个V100的DGX-2服务器训练BERT-Large需要3天。
结语:MegatronLM模型促进NLP发展
让计算机理解人类语言及其所有细微差别并做出适当反应一直是AI研究人员追求的方向,但在现代AI技术的到来之前,建立具有真正NLP功能的系统是不可能的。
随着BERT和具有10亿多参数的GPT-2模型等大型语言模型的出现,我们看到了高难度语言理解任务实现的可能,而Nvidia本次发布的MegatronLM模型更是将NLP处理提高了一个台阶。
更重要的是,新的模型可能会减少像亚马逊Alexa、Google Assistant和百度Duer这样的语音助手交互延迟时间,这对于语音交互实际的发展有非常大的推动作用。
文章来源:Venturebeat、Nvidia
