








智东西(公众号:zhidxcom)
文 | 心缘
技术变革从来都不是轰轰烈烈,当你猛然惊觉,世界已经被深度学习这个人工智能近年发展最迅猛的技术搅得天翻地覆。
10月17日,由百度主办的2019年中关村论坛·AI时代的深度学习技术与应用创新论坛在北京举行。
百度、清华大学、马里兰大学、英特尔、联想等国内外知名院所和企业的专家学者齐聚,共同探讨深度学习技术前沿和未来产业发展趋势。
在本次论坛期间,百度首度发布了《百度大脑AI技术成果白皮书》,展示百度大脑过去一年的技术演进。百度AI技术平台体系执行总监、深度学习技术及应用国家工程实验室副主任吴甜还现场解密了飞桨的四大领先技术,全方位展示这一标准化、自动化、模块化的深度学习平台所取得的一系列成果。
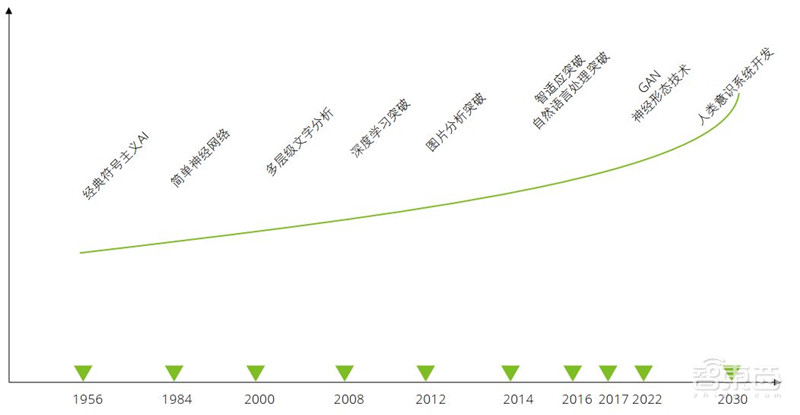
▲人工智能技术发展历史
过去60年间,人工智能发展经历了人工规则、机器学习与深度学习三大典型阶段。2012年前后,深度学习算法在计算机视觉和语音识别领域陆续取得飞跃式突破。在算力、数据、算法三驾马车的驱动下,深度学习掀起了第三次人工智能热潮。这场新的变革牵手物联网,重塑了千千万万硬件设备的内核,不仅是科技公司追逐的焦点,也日益成为各类传统行业创新求变的必然选择。
从百度飞桨这个国内开源深度学习框架的“扛把子”身上,我们可以看到国内深度学习发展历程的缩影,看见深度学习技术和应用的演进,看见它给中国人工智能产业带来的变局,同时也探讨中国在深度学习技术研发与落地中面临的危与机。
一、三年占据政策高地,开启国内AI新时代
今年已经是人工智能连续第三年出现在政府工作报告中,也是政府工作报告首次提出“智能+”概念。
根据国务院规划,2020年中国人工智能核心产业规模将达到1500亿元,并在此后十年将继续保持高速发展。目前我国这一数值已破千亿人民币,达到这一目标成功在即。另据今年智博会上副总理透露的数据,据初步统计,2018年与人工智能相关的产业规模可能已经超过5000亿元人民币,正在成为重要的新经济增长点。
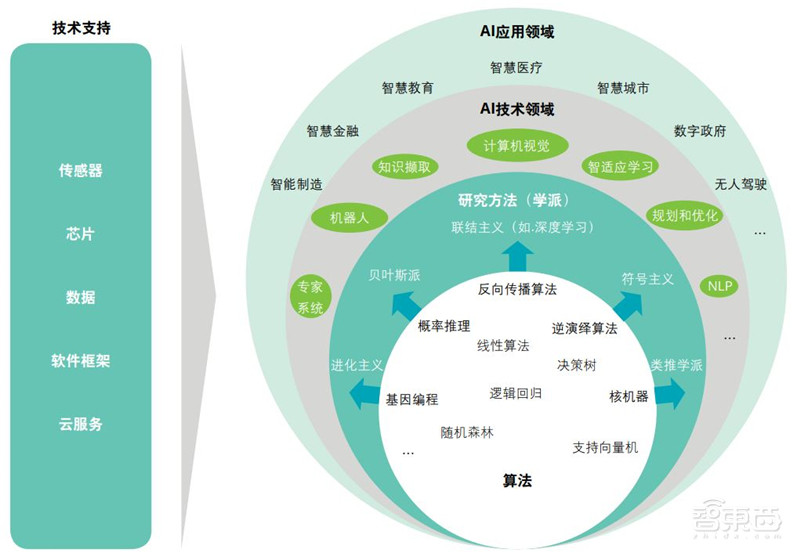
结合近些年我国人工智能的发展情况来看,国家对人工智能的规划聚焦在技术研发和产业发展两方面。
我国投入人工智能研发的起步时间较早,在学术界从1977年就开始有相关研究的基础。
在产业界,百度从2008年就开始建设大规模机器学习基础设施、模型、工具及实验平台,于2012年百度就成功将深度学习DNN模型应用到语音识别、OCR任务中,并在2013年打造出深度学习框架飞桨(PaddlePaddle)的原型Paddle,2016年,百度正式开源PaddlePaddle,使其成为中国首个也是国内唯一开源开放、功能完备的深度学习框架。
百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰曾将深度学习框架比喻为“智能时代的操作系统”,认为在智能时代,深度学习框架起到下接芯片、上承各种应用的作用。

▲百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰
如今我国人工智能已经走过萌芽阶段,逐渐走入快速落地期。深度学习框架正作为人工智能时代的基础设施,逐渐与产业深度融合与渗透,对人们的生产及生活方式产生深远影响。
二、开源深度学习框架,催化人工智能应用爆发
深度学习框架在人工智能发展史中地位举足轻重。北京市经济和信息化副巡视员姜广智表示,与计算芯片相结合的深度学习框架,将形成主导产业生态的核心技术体系。
然而目前世界上主流的TensorFlow、Caffe、PyTorch、MXNet等框架均掌握在谷歌、Facebook、亚马逊等国外科技巨头手中。 目前唯有百度飞桨突出重围,在全球开源深度学习框架排行榜上争得一席之地。
截至10月18日,百度在Github上的star数达到10055,forks数达到2686,代码更新次数达到25480次。
国外框架虽然好用,但很长一段时间都没有中文的相关文档与资料,数据安全等隐患也一直存在。另外在语言理解方面,国外企业很难对中文NLP做到足够深入的研究。
百度飞桨的出现,不仅为国内开发者们提供了一种新的选择,也使得百度自身在人工智能方面掌握了自主权。百度飞桨的7月全新升级的持续学习语义理解框架ERINE2.0,在共计16个中英文任务上效果超越了谷歌BERT和XLNet,截至目前已累计学习超过13亿知识。
今年7月国际知名数据分析公司IDC发布的《中国深度学习平台市场份额调研》显示,百度深度学习平台在中国深度学习平台领域综合市场份额排名第三,仅次于谷歌和Facebook,领衔国内平台。
其基于飞桨的服务平台EasyDL具有很高的市场认可度,用户认知度达46.4%,高频使用率达32.7%。

▲百度AI技术平台体系执行总监吴甜介绍飞桨产业级深度学习开源开放平台
作为百度人工智能应用的基石,百度飞桨在技术上有灵活高效、支持超大规模深度学习模型训练、支持多端多平台部署的高性能推理引擎等四大特点。
百度飞桨支持100多种主流模型,同时开源开放了超过200个预训练模型。截至目前,仅在其定制化训练化平台上就吸引超过6.5万企业用户,发布了16.9万个模型。
深度学习框架同样是推动产业落地的关键一环,在与应用的结合上百度做了大量的工作。百度飞桨有很多模型不仅在国际竞赛上取得好成绩,而且经过了产业验证,涵盖视觉、自然语言处理、推荐等主流应用任务。同时考虑到国内与日俱增的开发需求,对在其平台上的模型开发与部署的易用性和高效性持续进行优化。

基于这一框架,百度在内部将人工智能融入到自己的各业务当中,带动自身业务增值,比如百度地图通过飞桨将用户出行时间预估的准确率从81%提升到86%;在外部广泛应用于工业、农业、服务业等,服务150多万开发者,既壮大百度自身的人工智能生态系统,又助力各行各业的产业与人工智能融合创新。
三、重塑整个世界的深度学习
大部分人感受到的深度学习技术,或是随处可“调戏”的Siri、Cortana、小度,或是动动嘴皮就能操控各种智能设备,或是机器翻译在手走遍天下都不怕,或是越来越快的打字速度、越来越省力的文字识别和图片识别,或是越来越拯救手残党和小白的智能修图和美颜,或是去政府、银行办事更加方便,或是无人车、无拥堵的蓝图正成为可能。
而除了这些生活中带给人们的点滴便利外,深度学习框架所提供的技术支撑,正通过与实体经济深度融合,给各产业带来巨大的经济增值空间和机遇。
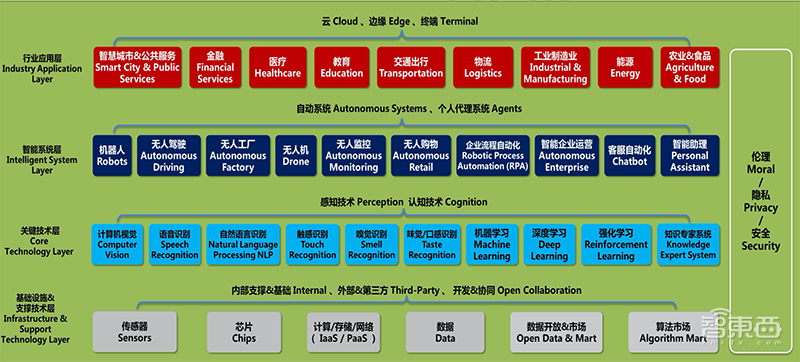
▲人工智能产业生态圈全景图
1、催生新型企业及就业机会
深度学习落地潮催生了数百家人工智能初创公司,提供人脸识别、语音识别、机器翻译等新兴服务及解决方案。大量数据标注公司也拔地而起,提供了更多低门槛的就业机会。
根据iiMedia Research(艾媒咨询),中国人工智能领域在2017年共融资634亿元,在2018年共融资1311亿元,增长率超过100%。
2、带动上游半导体创新
产业智能化的快速推进,致使对大规模深度学习计算的需求激增,云、边、端等不同场景的算力需求令越来越多的半导体厂商、创业新秀及跨界玩家涉足人工智能芯片,CPU、GPU、FPGA、ASIC、神经拟态芯片等不同类型的计算单元开始发挥活力。
百度也作为跨界者加入这一战局,除了打造自研AI芯片昆仑为飞桨提供专属算力外,还于今年宣布飞桨与华为麒麟NPU合作,加强在端侧的软硬结合布局。
3、使能下游硬件升级
深度学习也催生了一些新型硬件设备,全新的品类有翻译笔、转录机、人脸识别验证机等,经智能化改造的品类有智能音箱、智能电视、智能灯泡、机器人等。
近年全球智能音箱市场大幅上增长,中国市场增长最快,国内形成阿里巴巴天猫精灵、小米小爱音箱和百度DuerOS家族三足鼎立之势。
4、挖掘传统行业红利
互联网流量红利争夺的主战场在线上,而深度学习正通过与传统行业资源的重组,将这一战场扩展到线下的红利。
放眼望去,智能化潜在的存量市场宽阔无边。医疗、金融、保险、农业、零售、出行、家居、教育……几乎只要与人的活动相关的场景,都存在极大可以优化的空间。
另外在云计算领域,公有云平台已成为低成本获取人工智能的重要渠道。全球以及国内公有云市场的领导者同样也是人工智能市场的领导者。
四、我国深度学习发展的优势与短板
产业要做到长足可持续发展,还需回归对技术本身的重视。在人工智能落地应用如火如荼开展的同时,我们不妨沉下心来,审视一下我国深度学习研究和产业建设上的优势与劣势。
总的来看,我国深度学习发展在数据采集与标注、理工科人才培养、落地应用等方面的优势都很明显。借助开源框架,我国多家机构或开发者在深度学习技术研究领域的国际性赛事或评测中夺冠,并在与产业的结合中验证了深度学习技术所带来的降本增效。
例如,百度在飞桨助力下多次在ICME人脸106关键点检测比赛、多目标追踪挑战MOT等国际竞赛中夺冠,还曾刷新斯坦福大学DAWNBench四大世界纪录,这些夺冠的模型也均在飞桨上开源。
同时人工智能技术被用于反哺数据标记和芯片设计工具,有效提高数据处理效率,优化芯片设计流程,为人工智能发展奠定更好的基础条件。
这些使得我国在技术层和应用层都走在国际前列,但正如前文所述,在以深度学习平台为代表的基础层领域,我国发展较迟,除了在国际上拿得出手的开源深度框架寥寥无几,在基础理论和技术的研究上也扎根不深。
尽管我国研究机构及企业在偏应用的人工智能技术上达到国际前列,但就现在而言,我国在重大的原创基础理论和技术成果上还相对欠缺,情感识别、自动驾驶、小数据学习等前沿技术还需持续研究和探索,距离真正的落地应用也还有很长的路要走。
五、下一步,人工智能的小目标
谈了这么多过去和现状,我们也应思考我国人工智能的下一步怎么走。
在本次论坛中,北京市科委党组织成员、副主任许心超在致辞中谈到了北京下一步在人工智能领域整体要进行的几项工作,这些方向对于产业以及其他地区的政策规划同样有借鉴意义。

▲北京市科委党组织成员、副主任许心超
第一,前瞻布局,引发人工智能范式变革的基础理论和共建共性技术的变革,思考下一步怎么做、如何做。
第二,支持发展开源算法框架的标准化,形成合力,百度在国内这一领域属于业界先锋,明年旷视也要进行开源框架,需探索如何形成合力去做。
第三,支持开展人工智能基准测试和软硬件适配研究。
第四,推动应用场景开放和数据开放。一个是给政府,一个是给资源,在交通、医疗、科技冬奥等方面加大人工智能的应用,为大家提供更好的应用场景。
另外,人工智能相关法律法规的建立已到了提上日程的时机。
早在2017年国务院印发的《新一代人工智能发展规划》中就强调,要“建成更加完善的人工智能法律法规、伦理规范和政策体系”。在今年的多个人工智能大会开幕式上,多位国家干部曾强调要重视法律法规建设。

▲2017年国务院印发《新一代人工智能发展规划》节选内容
今年大洋彼岸的西方国家陆续出台了多个人工智能相关法令,前不久,深圳市人工智能行业协会同多家企业发布《新一代人工智能行业自律公约》,旨在构建人工智能道德伦理体系。随着下一步政策及计划的开展,相信我国用以保障人工智能健康发展的法律法规已经在路上。
结语:在自身的土壤下成长出茁壮根系
回望过去几年,国内人工智能产业发展欣欣向荣,以百度飞桨为代表的国产开源深度学习技术体系已经初步具备支撑人工智能产业发展的能力。
变革正在加速,但离实现真正的人工智能强国还有距离。
诚如中国工程院院士、清华大学自动化系教授戴琼海所言,中国深度学习领域发展既要在世界开源精神中汲取养分并积极贡献,也要注重在自身的土壤下成长出茁壮根系。
开源为人工智能创业者提供了源源不断的养料,但我们不应只顾眼前的便利而忽略了长远的考量。在市场繁荣发展的同时,我国的基础理论技术和基础设施建设的根基并不牢固。
这需要百度以及更多国内人工智能产业链从业者,更加重视基础研究的推进、核心技术体系的搭建,以实现深度学习等技术的自主可控,为争夺人工智能技术的国际话语权、跻身创新型大国和经济强国奠定基础。
