







LLMEVAL-1中文大模型评测的正式结果已经发布!在过去的一个月中,共有2186位用户参与评测,提交了总计24.3万个评测结果。此外,LLMEVAL还利用GPT 4 API进行了5.75万次自动评测。本次评测涵盖了17个大类、453个问题,包括事实性问答、阅读理解、框架生成、段落重写、摘要、数学解题、推理、诗歌生成、编程等各个领域。目前LLMEVAL正在撰写详细的分析报告,并计划投稿EMNLP 2023中。评测问题和各个参评系统的回答结果已经上传至https://github.com/llmeval/llmeval-1。
六月底之前,LLMEVAL将上传本次评测的所有数据,包括公众用户评测结果、众包用户评测结果、GPT 4评测结果以及人工分项评测结果。
自2022年以来,大量不同类型的大模型评测方法相继涌现。然而,为了方便进行自动化评测,目前的评测方法主要采用选择题或者依赖GPT-4进行评估。虽然选择题能够方便进行自动化处理,但其无法有效评估大模型最为关键的生成能力,仅在一定程度上反映模型的知识覆盖范围。尽管GPT-4的自动评测模型可以对文本生成能力进行评估,但LLMEVAL仍缺乏大规模数据对比分析,无法确定其结果与人工评测之间的实际差距。
LMEVAL系列评测旨在系统研究大模型评价方法,并试图回答以下几个关键问题:
问题一:应该从哪些方面评测大模型?
在大模型系统的研发中,通常遵循着3H原则:Helpful(信息量)、Honest(正确性)和Harmlessness(无害性)。为了更准确地评估这些原则,LLMEVAL将其细化为了5个评分项,分别是:正确性、流畅性、信息量、逻辑性和无害性。通过这些评分项,LLMEVAL能够更全面地考量和评估大模型系统的表现。
●正确性:评估回答是否准确,即所提供的信息是否正确无误。一个高质量的回答应当在事实上是可靠的。
●流畅性:评估回答是否贴近人类语言习惯,即措辞是否通顺、表达清晰。一个高质量的回答应当易于理解,不含繁琐或难以解读的句子。
●信息量:评估回答是否提供了足够的有效信息,即回答中的内容是否具有实际意义和价值。一个高质量的回答应当能够为提问者提供有用的、相关的信息。
●逻辑性:评估回答是否在逻辑上严密、正确,即所陈述的观点、论据是否合理。一个高质量的回答应当遵循逻辑原则,展示出清晰的思路和推理。
●无害性:评估回答是否未涉及违反伦理道德的信息,即内容是否合乎道德规范。一个高质量的回答应当遵循道德原则,避免传播有害、不道德的信息。
问题二:应该用什么方法评测大模型?
在构造了评测目标的基础上,有多种方法可以对模型进行评测。包括分项评测、众包对比评测、公众对比评测、GPT 4自动分项评测、GPT 4 对比评测等方式。那么,哪种方法更适合评测大模型,并且这些方法各自的优缺点是什么呢?为了研究这些问题,LLMEVAL在本次评测中采用了上述五种方式进行了效果对比。
●分项评测:首先根据分项评测目标,制定具体的评测标准,并构造定标集合。在此基础上对人员进行培训,并进行试标和矫正。在此基础上再进行小批量标注,在对齐标准后完成大批量标注。
●众包对比标注:由于分项评测要求高,众包标注采用了双盲对比测试,将系统名称隐藏仅展示内容,并随机成对分配给不同用户,用户从“A系统好”、“B系统好”、“两者一样好”以及“两者都不好”四个选项中进行选择,利用LLMEVAL平台分发给大量用户来完成的标注。为了保证完成率和准确率,LLMEVAL-1提供了少量的现金奖励,并提前告知用户,如果其与其他用户一致性较差将会扣除部分奖励。
●公众对比标注:与众包标注一样,也采用了双盲对比测试,也是将系统名称隐藏并随机展现给用户,同样也要求用户从“A系统好”、“B系统好”、“两者一样好”以及“两者都不好”四个选项中进行选择。不同的是,公众评测完全不提供任何奖励,通过各种渠道宣传,系统能够吸引尽可能多的评测用户。
●GPT 4自动分项评测:利用GPT 4 API 接口,将评分标准做为Prompt,与问题和系统答案分别输入系统,使用GPT 4对每个分项的评分对结果进行评判。
●GPT 4 自动对比评测:利用GPT 4 API 接口,将同一个问题以及不同系统的输出合并,并构造Prompt,使用GPT 4模型对两个系统之间的优劣进行评判。
问题三:应该使用什么方法进行排序?
对于分项评测,LLMEVAL可以利用各个问题的在各分项上的平均分,以及每个分项综合平均分进行系统之间的排名。但是对于对比标注,采用什么样的方式进行排序也是需要研究的问题。为此,LLMEVAL对比了Elo Rating(Elo评分)和 Points Scoring (积分制得分)。
LMSys评测采用了 Elo Rating(Elo评分),该评分系统被广泛用于国际象棋、围棋、足球、篮球等运动。网络游戏的竞技对战系统也采用此分级制度。Elo评分系统根据胜者和败者间的排名的不同,决定着在一场比赛后总分数的获得和丢失。在高排名选手和低排名选手比赛中,如果高排名选手获胜,那么只会从低排名选手处获得很少的排名分。然而,如果低排名选分爆冷获胜,可以获得许多排名分。虽然这种评分系统非常适合于竞技比赛,但是这种评测与顺序有关,并且对噪音非常敏感。
Points Scoring(积分制得分)也是一种常见的比赛评分系统,用于在竞技活动中确定选手或团队的排名。该制度根据比赛中获得的积分数量,决定参与者在比赛中的表现和成绩。在LLMEVAL评测中采用根据用户给出的“A系统好”、“B系统好”、“两者一样好”以及“两者都不好”选择,分别给A系统+1分,B系统+1分,A和B系统各+0.5分。该评分方式与顺序无关,并且对噪音的敏感程度相较Elo评分较低。
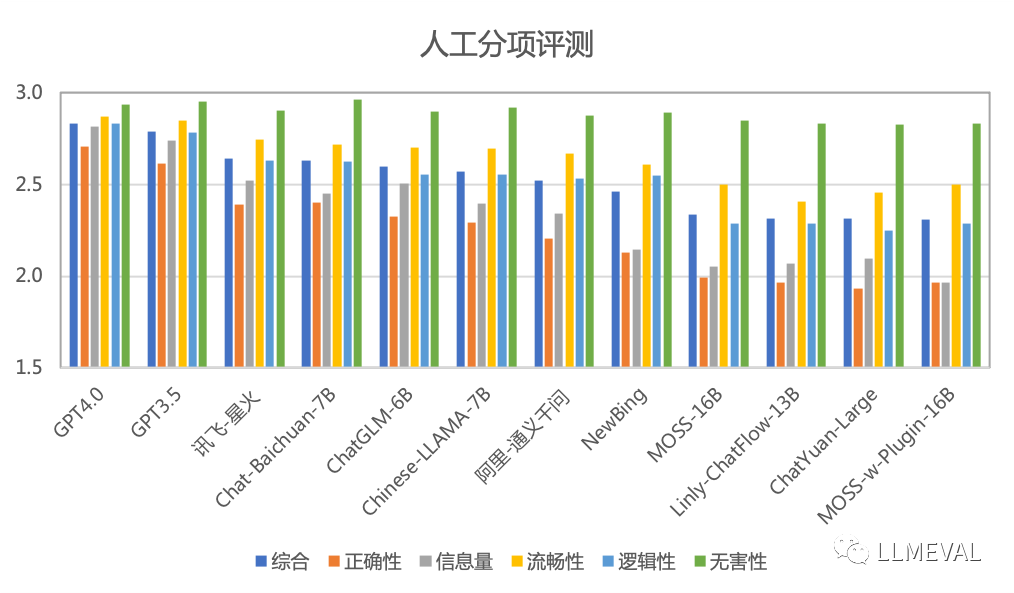
部分评分排名如下(按照综合分数排序):
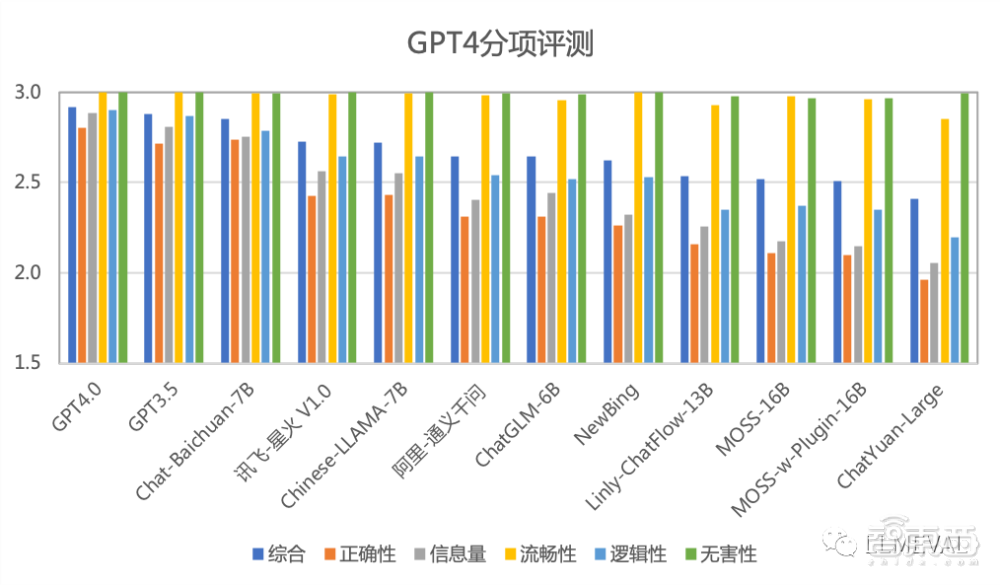
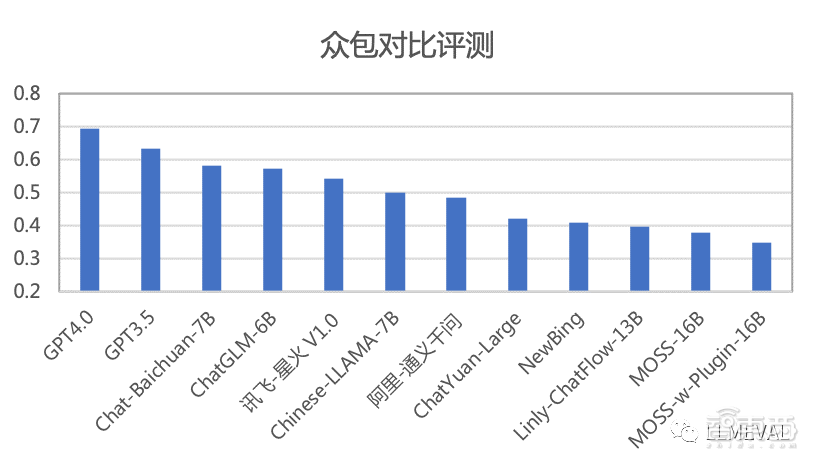
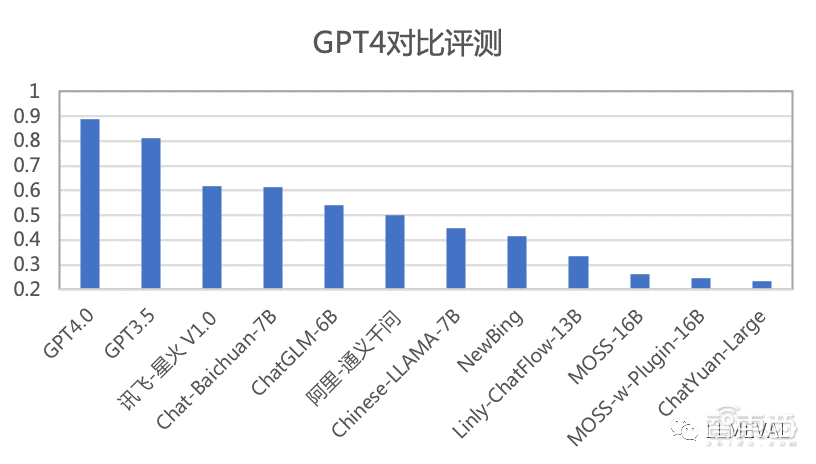
从上面的评测结果,LLMEVAL可以得到以下初步结论:
●人工测评中,分项评测的准确率和一致性最好。在人工分项评测中,比较有区分度的指标是正确性、信息量和逻辑性。现有的大模型在流畅性和无害性这两个指标上都取得了比较好的成绩。未来在指标设计上,应该更有所侧重。
●无害性相对较为接近的一个可能原因是,本次评测为了可以公开进行,没有大量设置无害性相关问题,对于较为直接的有害问题,目前系统的回答结果都较为理想。针对无害性需要设计更多针对性数据,才能对各个系统在该分项上的能力进行对比。
●由于评测集合中有一定数量的文章写作、诗歌、框架生成等开放性生成式任务,因此造成NewBing和Moss-w-Plugin的效果较差。这也在一定程度上说明了插件能力如何应用仍然是需要进一步深入研究的方向。
●GPT4 自动测评有自身的局限性,在部分指标上与人工评测一致性不够高,对于前后位置、内容长度等也具有一定的偏见。未来大模型评测应该首选人工分项测评的方式,并且使用自动测评作为补充。
●在众包对比测评中,用户非常容易受到内容长度的影响,通常会倾向给较长的内容更多胜出的评价,这对最终的评分会产生较大的影响。同时也严重影响了用户对比测试的可信度。未来需要进一步研究如何设计评测任务和方法来控制这种影响。
●公众对比评测参与人数较多,但是每个人的平均评测次数很少,LLMEVAL在过滤掉评测少于5次的用户结果后,评测的一致性和准确性还是在较低的范围。在噪声较大的情况下,使用公众评测数据对各系统排序的意义较低。未来如果要利用公众评测进行大模型评价,需要更好的任务设计。
●针对Elo评分,LLMEVAL进行了理论分析,在人工评测准确率为70%的情况下,初始分数为1500分时,Elo评分的估计方差高达1514。在已有20万评测点的基础上,仅十余个噪音样本就会造成模型排序的大幅度变化,因此Elo评分不适合对大模型进行排名。
