








智东西(公众号:zhidxcom)
编译 | 周炎
编辑 | 云鹏
智东西8月3日消息,今天,Meta发布了一款开源AI工具AudioCraft,该工具可以帮助用户根据文本提示创作音乐和音频。
Meta称,这款开源AI工具综合使用了AudioGen、EnCodec和MusicGen等大模型,不仅可以生成各种模拟音频效果,还能减少音损。用户使用该AI工具,可在输入文本内容后,生成高质量、逼真的音频和音乐。
目前来看,由于生成任何类型高保真度的音频都需要对不同尺度的复杂信号和模型进行建模,音乐在某种程度被看作是最具挑战性的音频类型。Meta通过自我监督音频表示学习的方式(self-supervised audio representation learning)以及许多分层或级联模型(hierarchical or cascaded models)来生成音乐,这样将原始音频输入到系统中,就可捕获信号中的远程结构(long-range structures),同时生成音频。
与此前的AI工具相比,AudioCraft背后的模型经过授权音乐库的训练,避免了版权风险;其次,由于接受公共音效训练,它可以生成包括狗叫、脚步声在内的各种模拟音效;最后它简化了音频生成模型的整体设计,同时开源的形式也有助于其他人开发自己音乐模型。但目前来看,AudioCraft仍然代替不了人类生成复杂且优秀的音乐作品。
一、经2万小时授权音乐训练,压缩文件大小比MP3格式小10倍
从目前Meta的介绍来看,Audiocraft背后使用三种模型中,MusicGen接受过Meta拥有的和特别授权的音乐库进行训练,可以从文本提示生成音乐。
今年6月初,这个名为MusicGen的开源AI模型由Meta推出。据悉,这是一种深度学习语言模型。它接受了2万小时的音乐训练,其中包括大约40万个录音、文本描述及元数据等。
 ▲AI模型MusicGen背后的论文基础,来源:Meta AI博客
▲AI模型MusicGen背后的论文基础,来源:Meta AI博客
此外,另一款模型AudioGen接受过公共音效训练,可从文本提示生成音频,比如模拟狗叫或脚步声。从Meta的介绍来看,AudioGen是一个来自Meta和耶路撒冷希伯来大学的研究团队的AI模型,可以通过输入文本来生成音频,亦可以扩展现有音频。AudioGen可以区分不同的声音对象,并在声学上将它们分开。
 ▲Meta展示AudioGen文本转音频效果,来源:Meta AI博客
▲Meta展示AudioGen文本转音频效果,来源:Meta AI博客
最后要说的就是EnCodec编解码器,此前,由于需要对原始音频信号中极长的序列进行建模,原始信号生成音频对研究人员来说存在巨大挑战。以一个几分钟的音乐曲目为例,它在通过44.1Hz的标准质量采样后,会形成数百万个时间步(timesteps)。
相比之下,在Llama和Llama 2等大模型的加持下,用户输入的文本可被处理为子词(sub-words),这样每个样本仅会产生几千个时间步。
因此,Meta团队使用基于深度学习的音频编解码器(neural audio codec)EnCodec,该编码器由AI驱动,可以从原始信号中学习离散音频标记(autoregressive language models),从而为研究人员提供了音乐样本的新固定的“词汇”(vocabulary)。研究人员可以在这些离散的音频标记上训练自回归语言模型,最后,研究人员可使用EnCodec的解码器将标记转回音频空间时生成的新标记及新音乐。

▲编解码EnCodec背后的论文基础,来源:Meta AI博客
据悉,EnCodec可以在音频质量没有损失的前提下,将音频压缩到比MP3格式还要小10倍的程度。这主要得益于EnCodec中带有残差矢量量化瓶颈(residual vector quantization bottleneck),该瓶颈可以生成多个具有固定词汇的并行音频标记流,由于不同的标记流可以捕获不同级别的音频波形信息(audio waveform),所以研究人员可从所有音频流中重建高保真度的音频。
二、推动模型开源,Meta称AudioCraft生成复杂音乐仍存在困难
Meta在公告中还演示了MusicGen和AudioGen工作的流程图,并表示将让这些模型开源,让研究人员和从业人员可以用自己的数据集训练适合自己的模型,并帮助推进人工智能生成音频和音乐领域的发展。
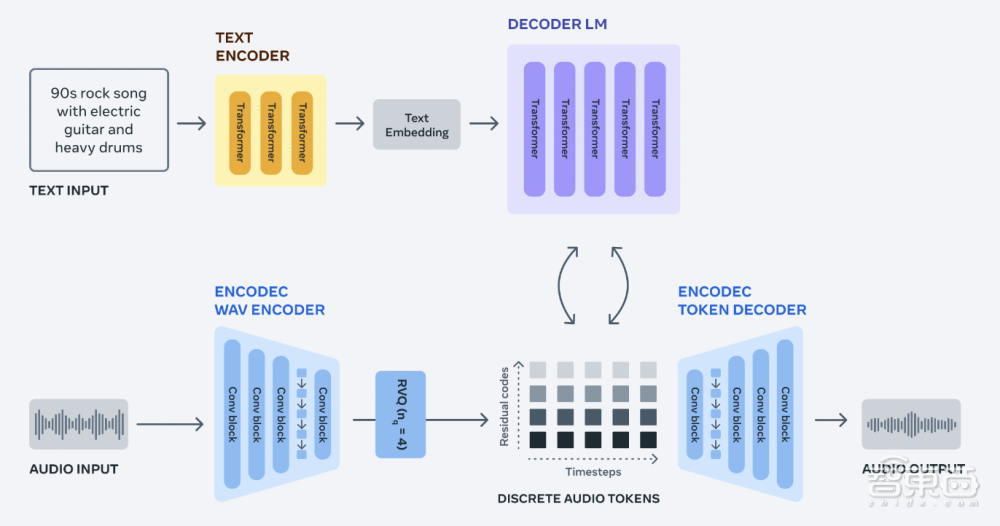 ▲MusicGen和AudioGen工作的流程图,来源:Meta AI博客
▲MusicGen和AudioGen工作的流程图,来源:Meta AI博客
与其他音乐模型相比,AudioCraft系列模型不仅能够生成长期一致的高质量音乐和音频,还简化了音频生成模型的整体设计,使得该工具简单易用。Meta认为,MusicGen可以变成一种新型的乐器,就像最初出现的合成器一样。
当然,Meta也指出,使用AudioCraft创作复杂而又优秀的音乐还是比较困难的,因此它选择将AudioCraft开源,以使用于训练它的数据多样化。
今年早些时候,谷歌也发布了名为MusicLM的音乐生成模型,并于5月向用户开放。今天,Google Labs还在官网中介绍了知名音乐家Dan Deacon正在使用该模型创作音乐。除此之外,目前比较常见的音乐模型还有Riffusion、Mousai和Noise2Music等。
结语:巨头“押注”音乐大模型,音乐创作或受到影响
从目前的公告信息来看,AudioCraft不仅可以根据用户的文本提示生成音乐,还可以对音频进行无损压缩。同时开源的形式也有助于更多人参与相关音乐模型的构建,从推动更高质量的音乐创作的生成。
随着,Meta和谷歌两大巨头“押注”音乐大模型,音乐的创作或受到生成式AI影响。但正如Meta所指出的,生成式AI生成复杂的音乐还有很长的路要走。
