








智东西(公众号:zhidxcom)
译 | 连然
百度,和谷歌一样,不只是一个搜索引擎巨头。
像谷歌一样,百度也在探索自动驾驶,并在机器学习,深度翻译,照片识别和神经网络上拥有重大科研项目。这些项目充满了大数据运算的挑战,很少有公司能够在自己的数据中心管理如此多的信息。
在寻求身为未来世界核心的大数据的过程中,百度已经吸引到世界上领先的大数据和云计算专家来帮助自己管理数据的爆炸式增长,建立基础设施以满足其数以亿计的客户和新业务的需求。可以看出,百度对于I/O和数据的流量高峰冲击是很看重的。
百度还支持了一个来自加州大学伯克利分校新的开源项目Alluxio (曾名为Tachyon)。
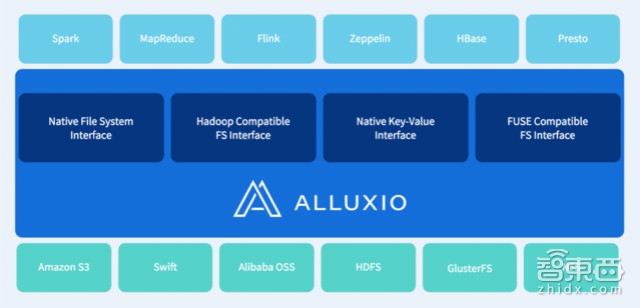
Alluxio得到了来自从全球巴克莱银行到阿里巴巴的大数据先驱、英特尔和IBM的工程师和研究员的广泛关注。近日,Alluxio发布了1.0版本,可以像可编程接口一样为大数据应用和底层的存储系统提供惊人的记忆能力。
ReadWrite与百度的高级架构师shaoshan Liu谈论了Alluxio生产和运行的相关问题。

ReadWrite: 当你投身于Alluxio的时候,你遇到了什么需要解决的问题?
Shaoshan Liu:如何管理数据的规模并快速提取有意义的信息一直是一个挑战。我们想要为关键查询提升数据吞吐性能。
由于查询量巨大,每次查询需要花费几十分钟甚至几小时——产品经理需要等待数小时才可以进入下一个查询。更令人沮丧的是,修改查询系统需要重新运行一次全过程。大约一年前,我们意识到对于特设的查询引擎的需要,于是我们开发了新的特设规格:查询引擎需要管理PB级数据并可以在30秒内完成查询数据的95%。
我们将Spark SQL切换为我们的查询引擎,许多用例已证实其相对Hadoop MapReduce的优势表现在延迟方面。我们很高兴Spark SQL能将平均查询时间下降到几分钟内。但它并没有完全达到我们想要的水平。虽然Spark SQL确实帮助我们实现了平均查询速度的4倍提升,但每个查询仍需花大约10分钟才能完成。
经过更深层次的发掘,我们发现了问题所在。由于数据分散分布在多个数据中心,有很大的可能是:数据的查询需要到达远程数据中心以提取数据——这应该是在用户运行查询时遇到延迟的最大原因。
但是可以想到的是,解决方法并不会像将计算节点带到数据中心那样简单。
RW:所以突破如何?
SL:我们需要一个记忆中心存储层来提供高性能、高可靠性并对PB规模数据进行管理。我们开发了一个使用Spark SQL作为计算引擎的查询系统,Alluxio则作为内存中心的存储层——我们进行了为期一个月的压力测试。在测试中,我们使用了百度内部的查询标准,将6TB的数据从远程数据中心传送出来,并对数据进行了额外的分析。
测试结果是惊人的。Spark SQL单独运行的时候,完成一次查询需要100—150秒;使用Alluxio,其中的数据可能会冲击本地或远程Alluxio节点,需要10-15秒。 如果所有的数据存储在Alluxio本地节点,那么平均只需要花费五秒钟——这意味着30倍的速度提升。基于这些结果和系统的可靠性,我们围绕 Alluxio和Spark SQL建立了一个完整的系统。
RW:这种新的模式是如何在生产中进行的?
SL:在系统的开发过程中,我们使用典型的百度查询来衡量其性能。使用原来的Hive 系统,需要花1000多秒完成一个典型的查询;使用Spark SQL—only系统,需要花300秒;但使用我们新的Alluxio 和Spark SQL系统,只需要花10秒。我们实现了速度的100倍提升,并满足了我们在设置这个项目时的提出交互式查询要求。
在过去的一年中,该系统已经在集群中部署超过200个节点,提供有由Alluxio管理的两个PB级空间,使用了Alluxio的一个高级功能(分层存储)。这个特征允许我们利用存储层次的优势,例如将内存作为顶级,SSD作为第二梯队,硬盘则作为最后一层;将所有这些存储介质相结合,我们就能够提供两个PB级的存储空间。
除了性能改进,更重要的是其可靠性。在过去的一年中,Alluxio一直在数据基础架构内稳定地运行,很少出现问题。这给了我们很大的信心。
事实上,我们正准备对Alluxio进行大规模部署。首先,我们安排了1000个 Alluxio工作集群来验证Alluxio的可扩展性。在过去的一个月里,该集群已运行稳定,并可提供超过50 TB的RAM空间。据我们所知,这是世界上最大的Alluxio集群。
(本文原载于ReadWrite)

