








芯东西(公众号:aichip001)
作者 | ZeR0
编辑 | 漠影
芯东西2月21日报道,在OpenAI推出又一爆款力作AI视频生成模型Sora后,连带着偏上游的AI芯片赛道热度一点即着。
创始成员来自谷歌TPU团队的美国存算一体AI芯片公司Groq便是最新赢家。这家创企自称其自研AI推理引擎LPU做到了“世界最快推理”,由于其超酷的大模型速度演示、远低于GPU的token成本,这颗AI芯片最近讨论度暴涨。连原阿里副总裁贾扬清都公开算账,分析LPU和H100跑大模型的采购和运营成本到底差多少。

就在Groq风风火火之际,全球最大AI芯片公司英伟达陷入了一些振荡。今日英伟达官宣将在3月18日-21日举办其年度技术盛会GTC24,但其股市表现却不甚理想。受投资者快速撤股影响,英伟达今日股价降低4.35%,创去年10月以来最大跌幅,一日之间市值缩水780亿美元。
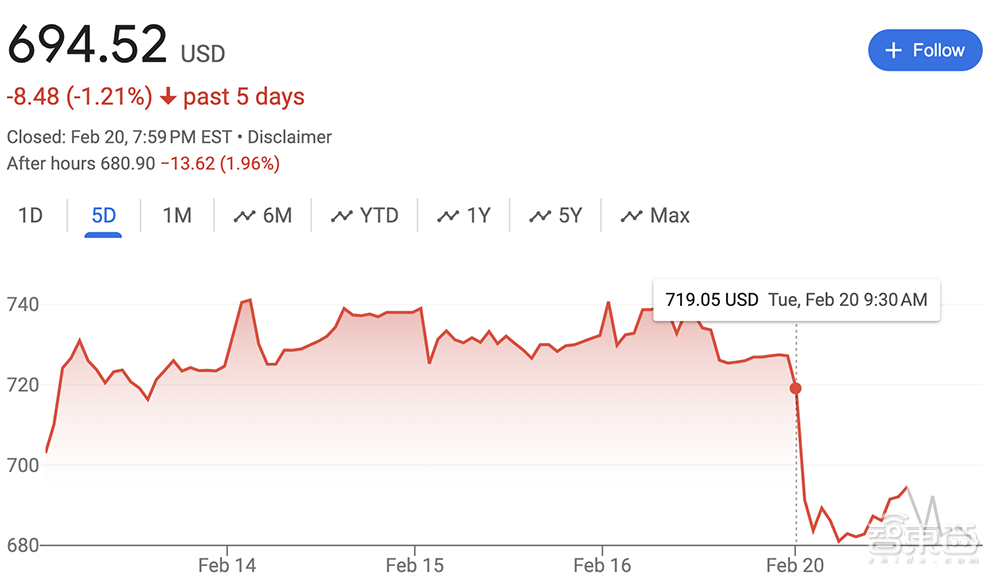 ▲英伟达太平洋时间2月20日股价出现显著下跌
▲英伟达太平洋时间2月20日股价出现显著下跌
Groq则在社交平台上欢欢喜喜地频繁发文加转发,分享其合作伙伴及网友们对LPU的实测结果及正面评价。一些积极观点认为,LPU将改变运行大语言模型的方式,让本地运行成为主流。
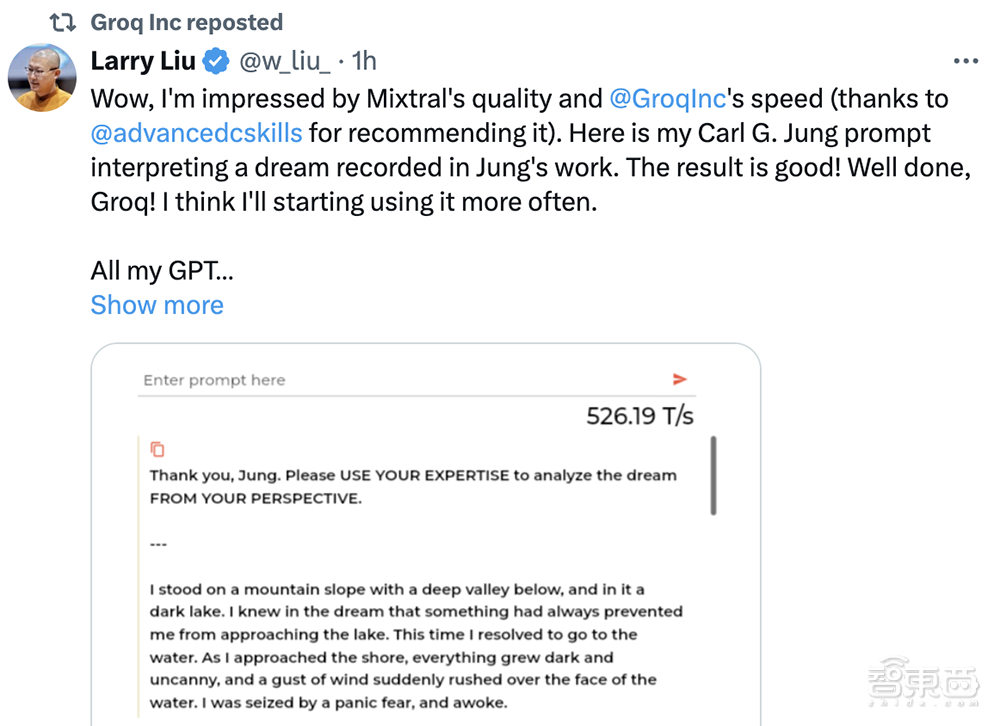
根据Groq及一些网友分享的技术演示视频及截图,在LPU上跑大语言模型Mixtral 8x7B-32k,生成速度快到接近甚至超过500tokens/s,远快于公开可用的OpenAI ChatGPT 4。
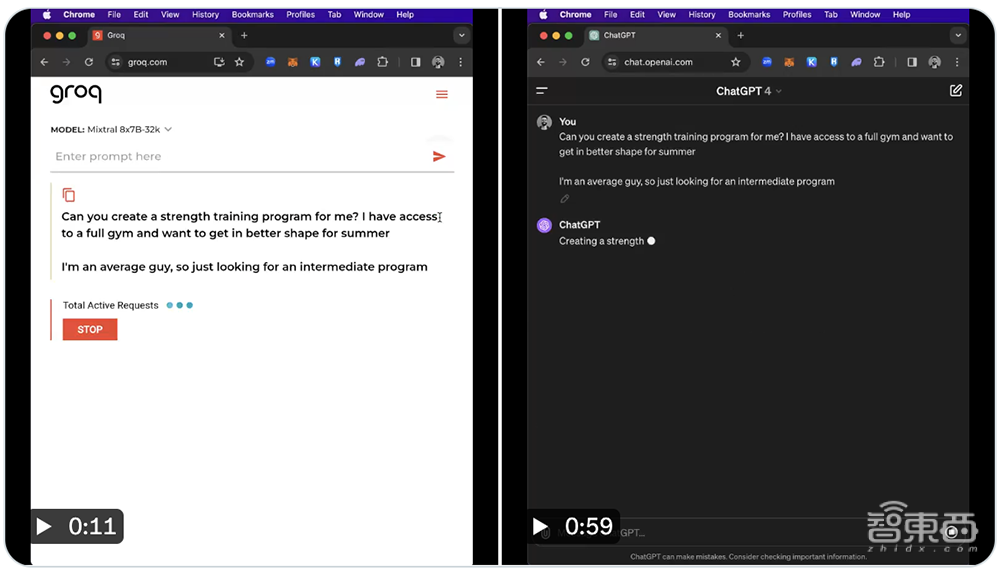 ▲输入相同指令,ChatGPT 4生成回答的时间大约1分钟,而在Groq上运行的Mixtral 8x7B-32k只用时11秒。
▲输入相同指令,ChatGPT 4生成回答的时间大约1分钟,而在Groq上运行的Mixtral 8x7B-32k只用时11秒。
“这是一场革命,不是进化。”Groq对自己的进展信心爆棚。
2016年底,谷歌TPU核心团队的十个人中,有八人悄悄组队离职,在加州山景城合伙创办了新公司Groq。接着这家公司就进入神隐状态,直到2019年10月才通过一篇题为《世界,认识Groq》的博客,正式向世界宣告自己的存在。
随后“官网喊话”就成了Groq的特色,尤其是近期,Groq接连发文“喊话”马斯克、萨姆·阿尔特曼、扎克伯格等AI大佬。特别是在《嘿 萨姆…》文章中,公然“嫌弃”OpenAI的机器人太慢了,并给自家LPU打广告,声称运行大语言模型和其他生成式AI模型的速度是其他AI推理解决方案速度的10倍。

现在,Groq继续保持着高调,除了官号积极出面互动外,前员工和现员工还在论坛上“撕”起来了。前员工质疑实际成本问题,现员工则抨击这位前员工离开并创办了一家Groq的竞争对手+没做出“世界最低延迟的大语言模型引擎”+没保证“匹配最便宜的token价格”。
面向LPU客户的大语言模型API访问已开放,提供免费10天、100万tokens试用,可从OpenAI API切换。
Groq致力于实现最便宜的每token价格,承诺其价格“超过同等上市型号的已发布供应商的任何已公布的每百万tokens价格”。
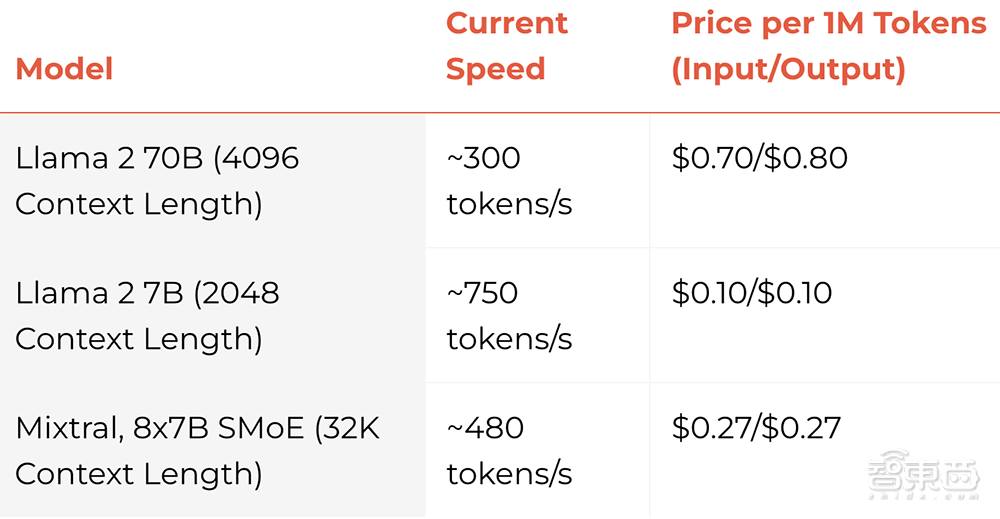
据悉,Groq下一代芯片将于2025年推出,采用三星4nm制程工艺,能效预计相较前一代提高15~20倍,尺寸将变得更大。
执行相同任务的芯片数量也将大幅减少。当前Groq需要在9个机架中用576颗芯片才能完成Llama 2 70B推理,而到2025年完成这一任务可能只需在2个机架使用大约100个芯片。
一、1秒内写出数百个单词,输出tokens吞吐量最高比竞品快18倍
按照Groq的说法,其AI推理芯片能将运行大语言模型的速度提高10倍、能效提高10倍。
要体验LPU上的大语言模型,需先创建一个Groq账户。
输入提示词“美国最好的披萨是什么?”跑在LPU上的Mixtral模型飞速给出回答,比以前慢慢生成一行一行字的体验好很多。
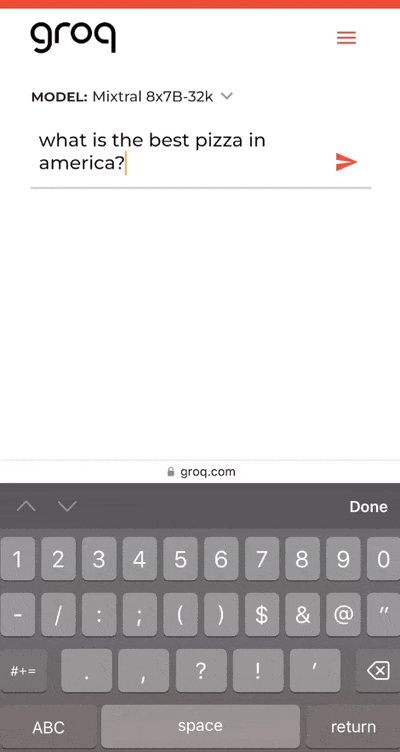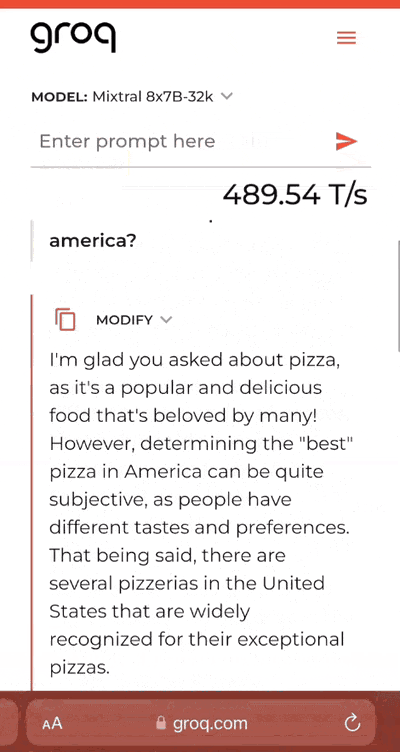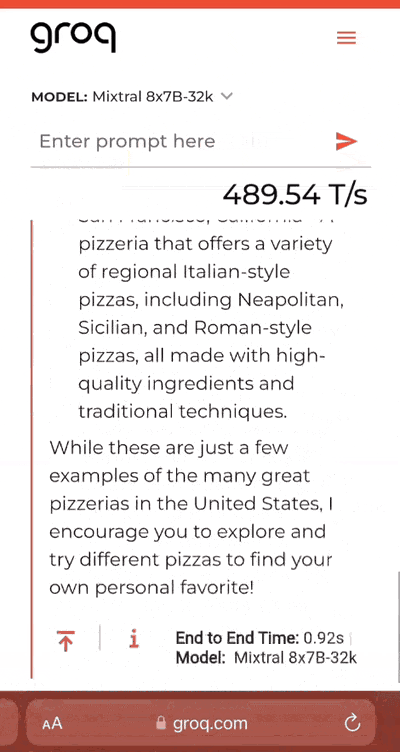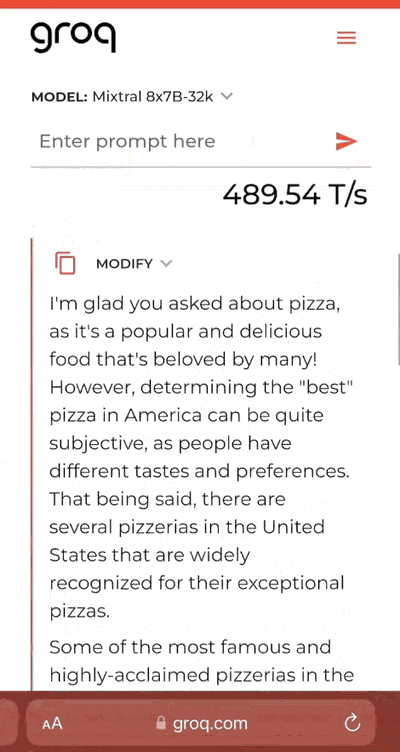
它还支持对生成的答案进行修改。
在公开的大语言模型基准测试上,LPU取得了压倒性战绩,运行Meta AI大语言模型Llama 2 70B时,输出tokens吞吐量比所有其他基于云的推理供应商最高要快18倍。
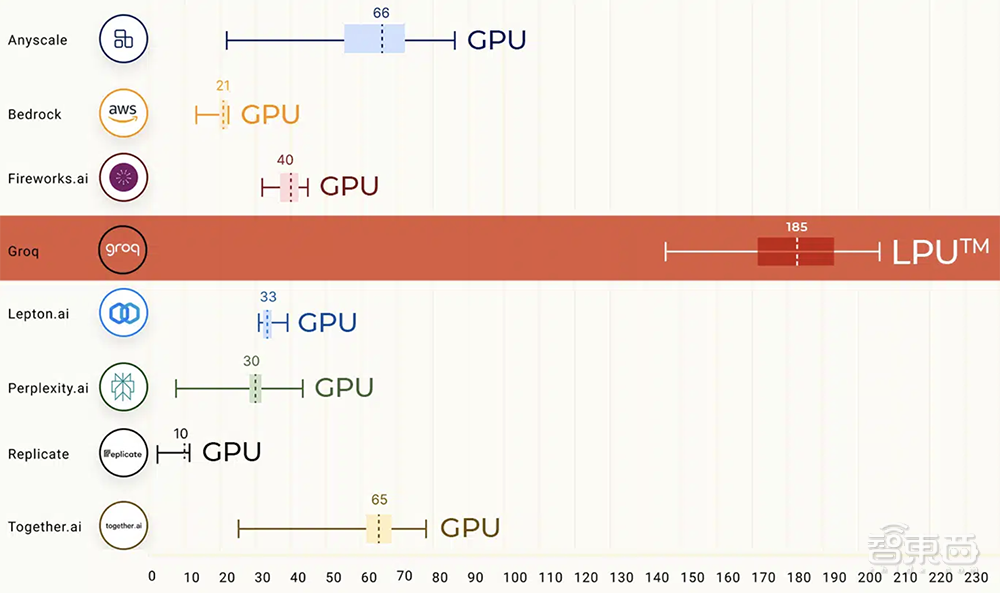
对于Time to First Token,其缩短到0.22秒。由于LPU的确定性设计,响应时间是一致的,从而使其API提供最小的可变性范围。这意味着更多的可重复性和更少的围绕潜在延迟问题或缓慢响应的设计工作。

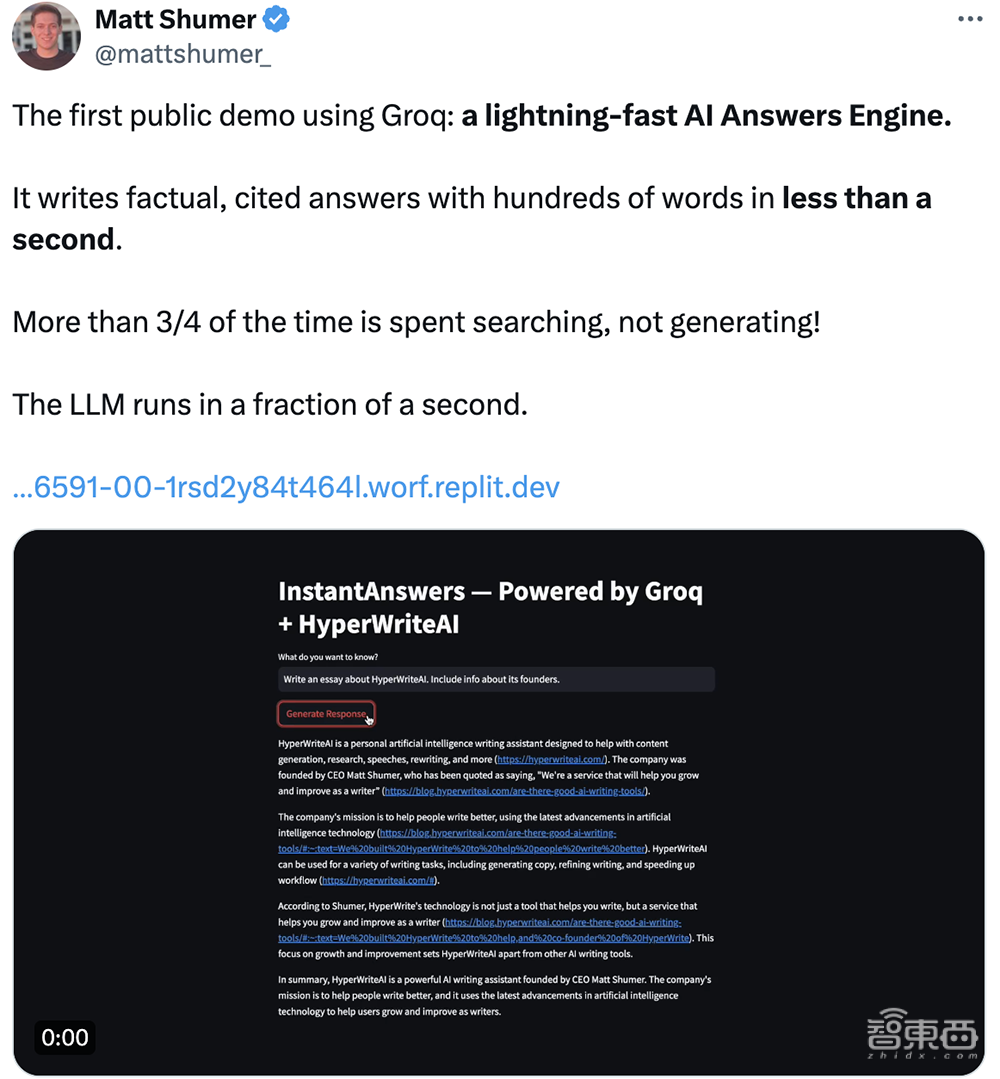
AI写作助手创企HyperWriteAI的CEO Matt Shumer评价LPU“快如闪电”,“不到1秒写出数百个单词”,“超过3/4的时间花在搜索上,而非生成”,“大语言模型的运行时间只有几分之一秒”。
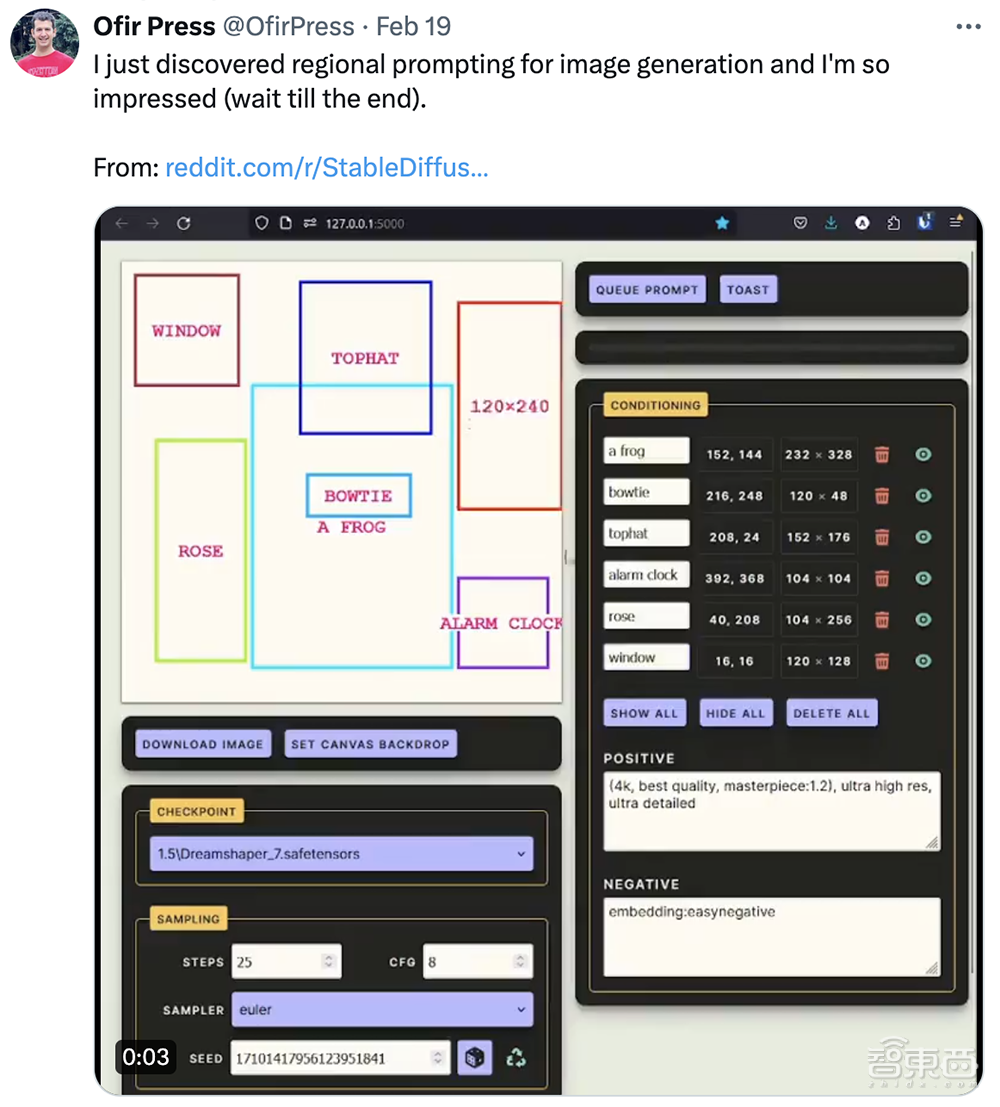
有网友分享了图像生成的区域提示,并评价“非常印象深刻”。
二、贾扬清分析采购和运营成本:比H100服务器贵多了
Groq芯片采用14nm制程工艺,搭载230MB片上共享SRAM,内存带宽达80TB/s,FP16算力为188TFLOPS,int8算力为750TOPS。
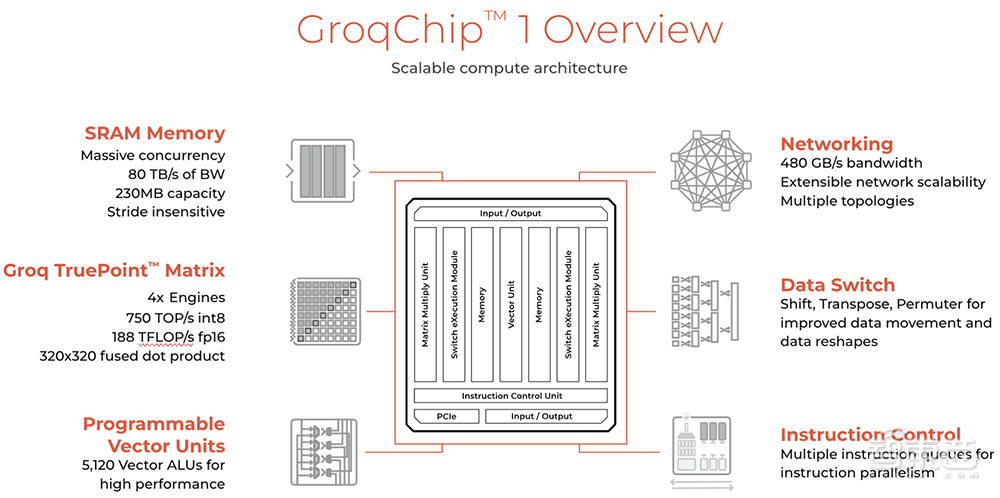
Groq在社交平台上解答了一些常见问题:1、LPU为每token提供很好的价格,因为效率高而且拥有从芯片到系统的堆栈,没有中间商;2、不卖卡/芯片,除非第三方供应商将其出售给研究/科学应用团体,销售内部系统;3、其设计适用于大型系统,而非单卡用户,Groq的优势来自大规模的设计创新。
与很多大模型芯片不同的是,Groq的芯片没有HBM、没有CoWoS,因此不受HBM供应短缺的限制。
在对Meta Llama 2模型做推理基准测试时,Groq将576个芯片互连。按照此前Groq分享的计算方法,英伟达GPU需要大约10~30J来生成token,而Groq每token大约需要1~3J,也就是说推理速度是原来的10倍,成本是原来的1/10,或者说性价比提高了100倍。
Groq拿一台英伟达服务器和8机架Groq设备做对比,并声称非常确定配备576个LPU的Groq系统成本不到英伟达DGX H100的1/10,而后者的运行价格已超过40万美元。等于说Groq系统能实现10倍的速度下,总成本只有1/10,即消耗的空间越多,就越省钱。
自称是“Groq超级粉丝”的原阿里副总裁、创办AI infra创企Lepton AI的贾扬清则从另一个角度来考虑性价比,据他分析,与同等算力的英伟达H100服务器成本比较,Groq LPU服务器实际要耗费更高的硬件采购成本和运营成本:

1. 每张Groq卡的内存为230MB。对于Llama 70B模型,假设采用int8量化,完全不计推理的内存消耗,则最少需要305张卡。实际上需要的更多,有报道是572张卡,因此我们按照572张卡来计算。
2. 每张Groq卡的价格为2万美元,因此购买572张卡的成本为1144万美元。当然,因为销售策略和规模效益,每张卡的价格可能打折,姑且按照目录价来计算。
3. 572张卡,每张卡的功耗平均是185W,不考虑外设,总功耗为105.8kW。(注意,实际会更高)
4. 现在数据中心平均每千瓦每月的价格在200美元左右,也就是说,每年的电费是105.8 x 200 x 12 = 25.4万美元。(注意,实际会更高)
5. 基本上,采用4张H100卡可实现Groq的一半性能,也就是说,一台8卡H100与上面的性能相当。8卡H100的标称最大功率为10kW(实际大概在8-9kW),因此每年电费为2.4万美元或更低一些。
6. 今天8卡H100的采购成本约为30万美元。
7. 因此,如果运行三年,Groq的硬件采购成本是1144万美元,运营成本是76.2万美元或更高。8卡H100的硬件购买成本是30万美元,运营成本为7.2万美元或更低一些。
如果按这个算法,运行3年,Groq的采购成本将是H100的38倍,运营成本将是H100的10倍。
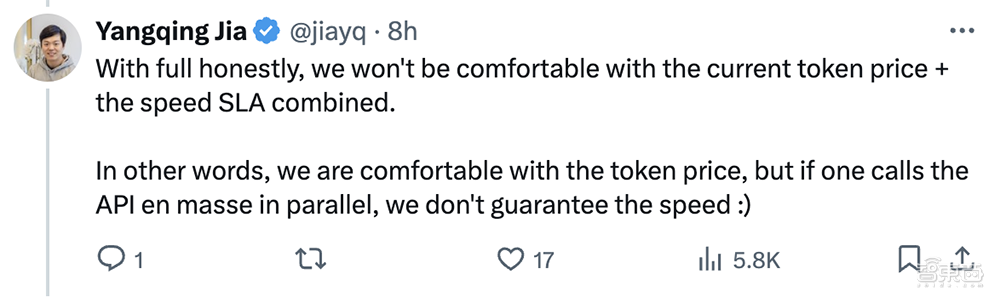
贾扬清还在评论区谈道:“老实说,我们对当前的token价格+速度SLA组合感到不适。换句话说,我们对token价格感到满意,但如果并行调用API,我们无法保证速度。”
三、存算一体+编译器优先,支撑更快的大语言模型计算
Groq联合创始人兼CEO Jonathan Ross曾宣称,相比用英伟达GPU,LPU集群将为大语言推理提供更高吞吐量、更低延迟、更低成本。
“12个月内,我们可以部署10万个LPU;24个月内,我们可以部署100万个LPU。”Ross说。
 ▲Groq领导层
▲Groq领导层
根据官网信息,LPU代表语言处理单元,是Groq打造的一种新型端到端处理单元,旨在克服大语言模型的计算密度和内存带宽瓶颈,计算能力超过GPU和CPU,能够减少计算每个单词所需时间,更快生成文本序列。消除外部内存瓶颈使得LPU推理引擎能够在大语言模型上提供比GPU好几个数量级的性能。

LPU采用了单核心时序指令集计算机架构,无需像传使用高带宽存储(HBM)的GPU那样频繁从内存中加载数据,能有效利用每个时钟周期,降低成本。
 ▲传统GPU内存结构
▲传统GPU内存结构
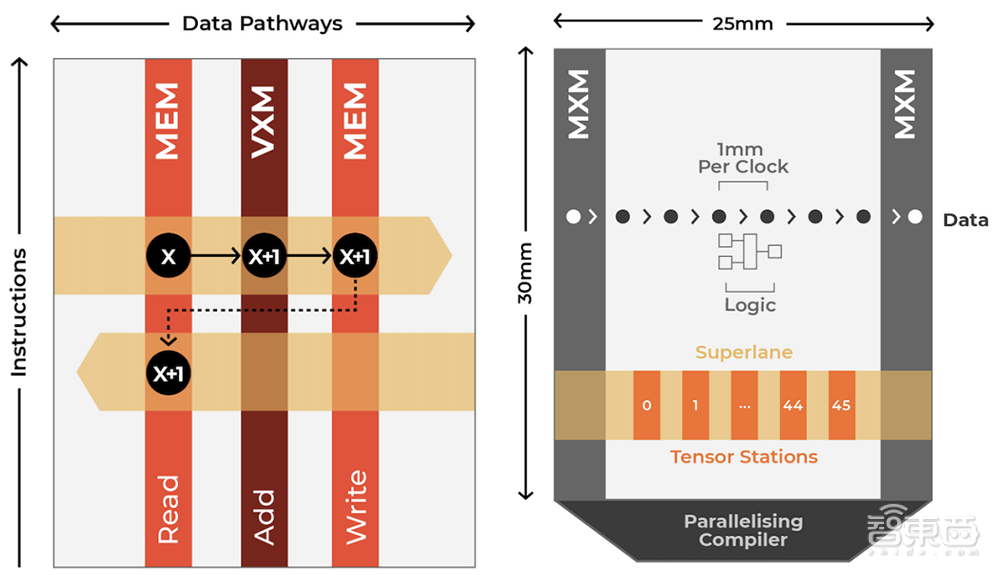 ▲Groq芯片内存结构
▲Groq芯片内存结构
Groq芯片的指令是垂直走向,而数据流向东西流动,利用位置和功能单元相交以执行操作。通过将计算和内存访问解耦,Groq的芯片在处理数据时能进行大量读写,即一步之内有效进行计算与通信,提供低延迟、高性能和可预测的准确性。
其特点包括出色的时序性能、单核架构、大规模部署可维护的同步网络、能自动编译超过500亿参数的大语言模型、即时内存访问、较低精度水平下保持高准确度。
 ▲单个LPU架构
▲单个LPU架构
“编译器优先”是Groq的秘密武器,使其硬件媲美专用集成电路(ASIC)。但与功能固定的ASIC不同的是,Groq采用软件定义硬件的思路,利用了一个可以适应和优化不同模型的自定义编译器,使其编译器和体系结构共同构成了一个精简的、稳健的机器学习推理引擎,支持自定义优化,以平衡性能与灵活性。
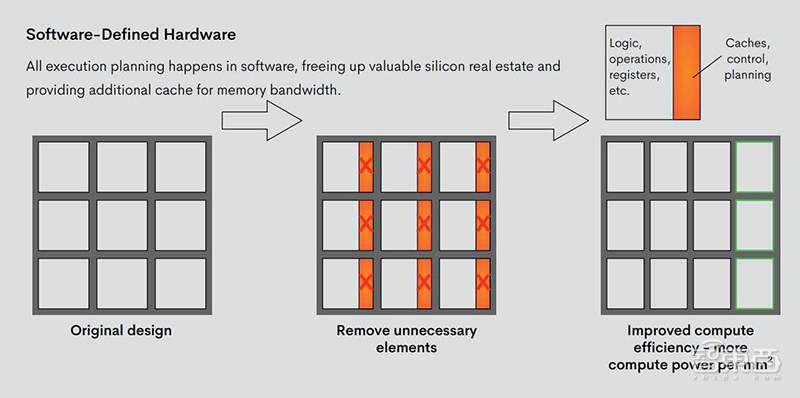 ▲Groq的简化软件定义硬件方法释放了额外的芯片空间和处理能力
▲Groq的简化软件定义硬件方法释放了额外的芯片空间和处理能力
受软件优先思想的启发,Groq将执行控制和数据流控制的决策步骤从硬件转移到了编译器,以调度跨网络的数据移动。所有执行计划都在软件栈中进行,不再需要硬件调度器来弄清楚如何将东西搬到芯片上。这释放了宝贵的芯片空间,并提供了额外的内存带宽和晶体管来提高性能。
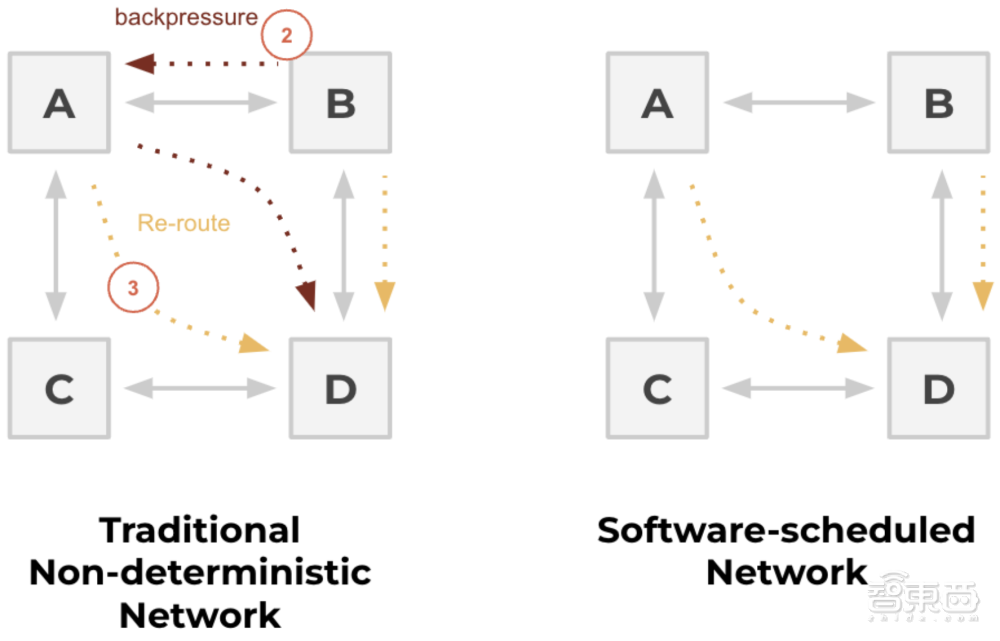 ▲传统的非确定性网络与软件调度网络的比较
▲传统的非确定性网络与软件调度网络的比较
Groq的简化架构去除了芯片上对AI没有任何处理优势的多余电路,实现了更高效的芯片设计,每平方毫米的性能更高。其芯片将大量的算术逻辑单元与大量的片上内存结合,并拥有充足带宽。
由于控制流程已进入软件栈,硬件是一致且可预测的,开发人员可以精确获知内存使用情况、模型效率和延迟。这种确定性设计使用户可在将多芯片扩展连接时,精确把控运行一次计算需要多长时间,更加专注于算法并更快地部署解决方案,从而简化了生产流程。
扩展性方面,当Groq芯片扩展到8卡、16卡、64卡,所支持的性能和延迟如下:
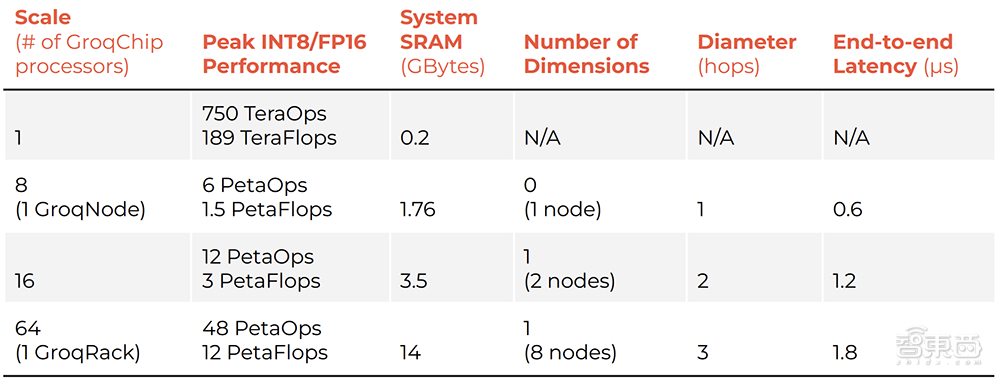
Groq工程师认为,必须谨慎使用HBM的原因是它不仅涉及延迟,还有“非确定性”问题。LPU架构的一大好处是可以构建能快速互连的数百个芯片的系统,并知道整个系统的精确时间在百万分之几以内。而一旦开始集成非确定性组件,就很难确保对延迟的承诺了。
结语:AI芯片上演新故事
Groq气势汹汹地向“世界最快大模型推理芯片”的目标发起总攻,给高性能AI推理市场带来了新的期待。
在系统级芯片采购和运营成本方面,Groq可能还难以做到与H100匹敌,但从出色的单batch处理和压低token价格来看,其LPU推理引擎已经展现出相当的吸引力。
随着生成式AI应用进入落地潮,AI芯片赛道也是时候多上演一些新故事了。
