







智东西(公众号:zhidxcom)
作者 | 徐珊
编辑 | 云鹏
智东西3月11日消息,近日微软和俄亥俄州立大学的研究人员发布论文,提出了一种受到生物启发的可以增强大语言模型使用工具能力的方法,即模拟试错(STE)法,并将其开源。
该方法协调了试错、想象和记忆三个关键机制。具体而言,STE通过大模型的“想象力”来模拟使用工具的一些合理场景,从而尝试适配不同的大模型,随后从新的反馈中,获得反馈不断优化。
ToolBench实验结果显示,STE在上下文学习和微调设置下显著提高了大语言模型的工具学习能力,让Mistral-Instruct-7B实现了46.7%的性能提升,使其成绩超过了GPT-4。
▲论文封面
论文PDF:https://arxiv.org/pdf/2403.04746.pdf
一、无法兼顾准确性和灵活性,大语言模型调用工具遭遇两大难题
寻找合适的工具一直以来都是训练大语言模型中关键一环。目前有关大语言模型的工具研究,主要集中在两个方面:为大语言模型增加一些新的工具,以及能够让大语言模型访问多个工具。
这些研究方向一般采用两种常见的设置:1)上下文学习(ICL),通过给预训练模型展示一些API规范以及输入-输出工具使用的示例,从而训练大语言模型在对应场景下的能力。2)大语言模型对工具使用示例进行微调。一般来说,微调可以更有效且更高效地引导大语言模型的行为。
但这两种设置在研究人员看来都有不足之处。上下文学习的方法确实能够保证大语言模型使用工具的灵活性,但是其精度却难以达到生产力水平。而微调的方法能够为大语言模型提供更高的准确性,但无法优化大语言模型本身使用工具能力。此外,如果想要优化大语言模型本身使用工具能力,还需要更高的精度,以面对法律、金融等特殊场景的需求。
同时,研究人员发现,哪怕是已经为了工具进行微调的GPT-4和开源大语言模型,在实际使用工具的过程中,也只有30%至60%的正确率。
在此背景下,研究团队探索如何让大语言模型能够提升使用已训练过工具的能力。他们从生物系统中获取灵感,设立了一个新的模拟试错法(STE),从而改善大语言模型使用工具学习的能力。
二、模拟大语言模型使用工具的过程,设记忆机制反思结果
研究团队对STE的研究分为了两个阶段:探索阶段和开发阶段。
在探索阶段中,研究团队做了一系列测试性实验:合理设想了一个用户查询相关API信息的提问;尝试实现与API交互进行查询;反馈实验结果。在训练的过程中,研究人员通过设计记忆机制来提高记忆的质量。其中,STE的短期记忆以及长期记忆将分别用于提高大语言模型使用工具学习能力的深度和广度。
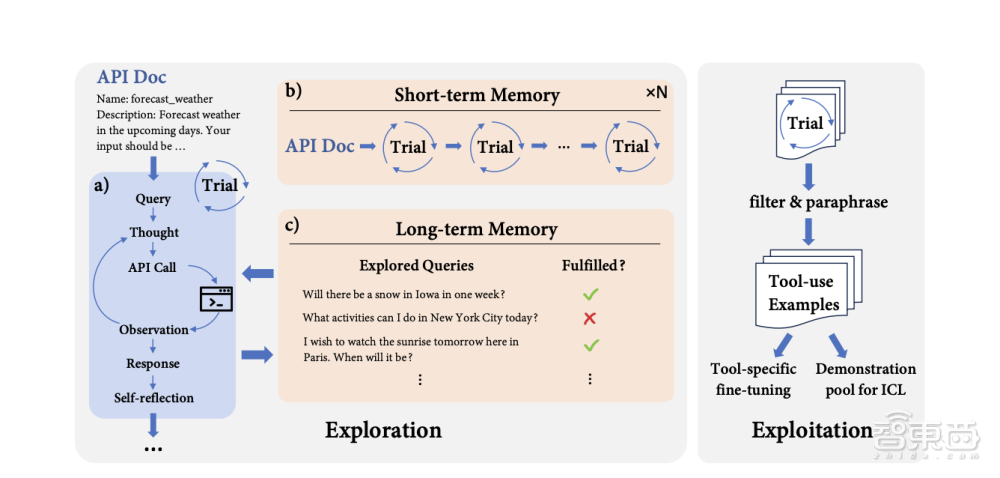
▲STE训练示意图
如示意图所示,当大语言模型想要提升调用天气预报软件的API能力时,大语言模型会先想一些和设想一些有关天气的问题,然后和工具交互以完成用户查询,最后对结果进行自我反思试验。大语言模型将会利用这些短期实验记忆,不断优化相关信息的精确性,并探索API的应用范围,并且逐步形成长期记忆。最后,短期和长期的记忆都将帮助大语言模型提升使用工具的能力。
三、大语言模型使用工具能力大幅提升,Mistral-Instruct-7B性能超越GPT-4
在经过一系列实验、验证之后,研究团队总结道:STE方法对ICL和微调两种设置都有效。
研究团队先测试了在没有采用STE方法前,不同参数规模的Llama、GPT、Mistral大语言模型使用API的能力。这时,80亿的GPT-4效果最好,其API适配达到78.1%,正确率能达到60.8%。
随后,研究团队又测试了通过STE方法后,不同参数规模的大语言模型使用API的能力。在该阶段,几乎不同参数规模的大语言模型均较之前有所提升。通过微调,Mistral-Instruct-7B实现了46.7%的性能提升,其API的匹配能力,以及正确使用工具的能力均超过了GPT-4。
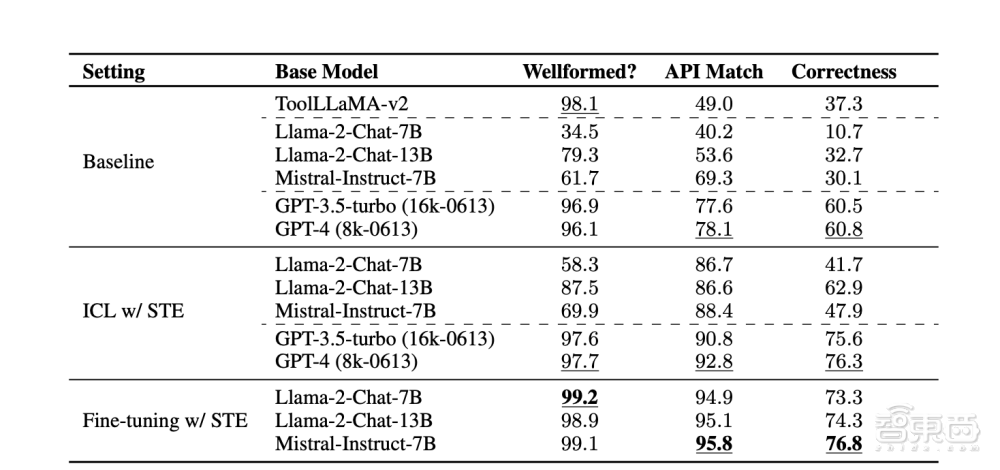
▲在STE训练方法下,大模型使用工具能力的成果表现
目前,研究团队已经从ToolBench显示成果中验证了该方法的有效性。并且,通过调整训练重点,大语言模型在使用工具的过程中,可以有所侧重的优化使用方法。
结语:促进应用生态,降低大模型适配成本
随着AI爆发时代的到来,越来越多的大语言模型将面临如何更好地接入不同应用的问题。我们看到微软正在通过一种测试方法,帮助工具更好的和不同的大模型适配。
同时,我们也能够看见现阶段对大语言模型的研究更加细分化,各界正在共同推动大语言模型的应用落地,为人们提供高效、精确的生产力工具。
