








智东西(公众号:zhidxcom)
文 | Lina
请叫我“杨立昆”,谢谢!
这位自称“杨立昆”的歪果仁真名Yann LeCun,被业界称为“卷积神经网络之父”,同时是深度学习三巨头之一(另外两位分别是Geoffrey Hinton和Yoshua Bengio),现任Facebook人工智能研究院的院长,兼任美国纽约大学教授。
3月23日,这位深度学习的大牛来到了北京,在清华经管学院、清华x-lab、Facebook合作开设的课程中进行了一场主题为《深度学习与AI未来》的2小时英文演讲,智东西也来到了现场。演讲刚开始时,Yann LeCun就在幻灯片上打出了自己新取的中文名——“杨立昆”,引来台下一片了然的笑声,Yann LeCun自己也忍不住笑了。在国内AI圈里,常有人讲Yann LeCun戏称为“杨乐康”,有时则是调侃地直接将LeCun以拼音读成“杨乐村”,不知此事是否传到了这位风趣可爱的技术大牛耳中。

智东西梳理了本次演讲的要点与脉络,并增补了相关背景知识,带你详细了解深度学习的发展现况、成果、困境、以及最前沿的突破性尝试。此外,还有Yann LeCun亲口向智东西回应关于Facebook削减AI预算的报道、以及十年前的2个赌约等科技小八卦。
1、脸书AI研究院与卷积神经网络
Facebook人工智能研究院全称FAIR(Facebook Artificial Intelligence Research),主要研究AI相关的科学与技术,以及其在各个领域中的应用——如计算机视觉、对话系统、虚拟助手、语音识别、自然语言识别等;据闻是一个学术氛围较浓的研究院,研究方向相对自由宽松,也没有近期的产品压力,可以着眼长远做困难和本质的研究问题。
Yann LeCun不仅是FAIR的一把手,同时还是卷积神经网络(CNN, Convolutional Neural Nets)的发明人之一。卷积神经网络是深度学习的重要分支,是第一个真正多层结构学习算法——而深度学习中的“深度”,最简单理解就是“有很多层”。

“深度学习的深度,指的是超过一层的非线性特征转换。(It’s deep if it has more than one stage of non-linear feature transformation)”
目前常见的深度学习模型包括牛津大学视觉几何组VGG网络、谷歌的GoogLeNet、Facebook的深度残差网络ResNet等。
随着近年来深度学习的不断崛起,擅长处理图像(特别是大图像)的卷积神经网络也被视为开发可拓展自动自然语言理解和图像识别工具,甚至是语音识别和视觉搜索系统的基本构件,Facebook的AI实验室也在YannLeCun及一众大牛的带动下飞速前进。
不过,3月初,据The Information报道(就是那个曾经正面怼上Magic Leap的媒体),尽管Facebook一直在进行Messenger聊天机器人相关内容的研发,结果却不尽如人意。在没有人力干预的情况下,Messenger能够正确处理人类请求的概率不到30%。因此,Facebook目前正在削减机器学习和人工智能方面的研发支出。
智东西也就这个问题直接询问了Yann LeCun教授本人,作为Facebook AI研究院的院长他坚定地一口否决。“不,完全没有这回事。”

2、卷积神经网络在Facebook的落地应用
作为Facebook人工智能研究院主任,Yann LeCun的演讲中自然也少不了卷积神经网络及深度学习在Facebook中的落地应用。
最先提到的是DeepFace。DeepFace是FAIR开发的一套人脸识别系统,主要应用卷积神经网络来提取人脸特征完成识别。现在Facebook用户每天上传的图片数量达到了8亿张,拥有大量的数据供机器训练与学习。
此外,Yann LeCun还提到了一项FAIR开发的,用于检测、分割、识别单张图像中每个物体的技术,比如在一盘菜里检测、分割、并识别出西兰花来、又或是在一堆羊群里分割出每只羊,其核心流程为以下三步(去年8月都已开源):

1)使用DeepMask这个新型框架对物体进行检测与分割,生成初始对象掩膜(Mask,相当于一个覆盖区域);
2)使用SharpMask模型优化这些对象掩膜;
3)使用MutiPathNet卷积网络识别每个掩膜所框定的物体。
值得一提的是,MutiPathNet中使用了一种新型的对象实例分割(Instance Segmentation)框架:Mask R-CNN。这是FAIR研究员何凯明(Kaiming He)——同时也是深度残差网络ResNet的作者之一——最近公布的研究成果,它是Faster R-CNN的扩展形式,能够有效地检测图像中的目标,同时还能为每个实例生成一个高质量的分割掩膜(Segmentation Mask)。
3、常识是个好东西,希望大家都有
此外,Yann LeCun还提到了如今AI发展过程中遇到的几大困难:

1)机器需要学习/理解世界的运行规律(包括物理世界、数字世界、人……以获得一定程度的常识)
2)机器需要学习大量背景知识(通过观察和行动)
3)机器需要理解世界的状态(以做出精准的预测和计划)
4)机器需要更新并记住对世界状态的估测(关注重大事件,记住相关事件)
5)机器需要逻辑分析和规划(预测哪些行为能让世界达到目标状态)
目前机器学习中最大挑战之一就是如何让机器拥有常识——即让机器获得填充空白的能力。比如“John背起包来,离开了房间”,由于人类具备常识,因此我们能够知道John在这个过程中需要站起来,打开房门,走出去——他不会是躺着出去的,也不会从关着的门出去,可机器并不知道这一点。又或者我们即使只看到了半张人脸也能认出那人是谁,因为人类常识里左右脸都是通常长得差不多,但机器同样不具备这种能力。
下文提到的无监督/预测学习可以让机器获得常识,现在我们常用的监督学习并做不到这一点。从本质上来说,在无监督学习方面,生物大脑远好于我们的模型。
4、无监督学习才是蛋糕本身
“是的、是的,我知道你们在想什么——那个蛋糕比喻又来了,”切到这张幻灯片时,Yann LeCun笑着说,“这已经是我在人工智能领域的一个梗了。”

在大大小小的无数场演讲中,Yann LeCun不止一次,甚至不止十次地打过这个比方:如果人工智能是一块蛋糕,强化学习(Reinforcement Learning)就是蛋糕上的一粒樱桃,而监督学习(Supervised Learning)是蛋糕外的一层糖霜,但无监督学习/预测学习(Unsupervised/Predictive Learning)才是蛋糕本身。目前我们只知道如何制作糖霜和樱桃,却不知道如何做蛋糕。
我们现在对深度神经网络的训练,用的大部分还是监督学习的方式。你将一张图片展现给系统并告诉它这是一辆车,它就会相应调整它的参数并在下一次说出“车”。然后你再展现给它一张桌子,一个人。在几百个例子、耗费几天到几周的计算时间之后,它就弄明白了。“这其实并不是一个非常复杂的概念。”
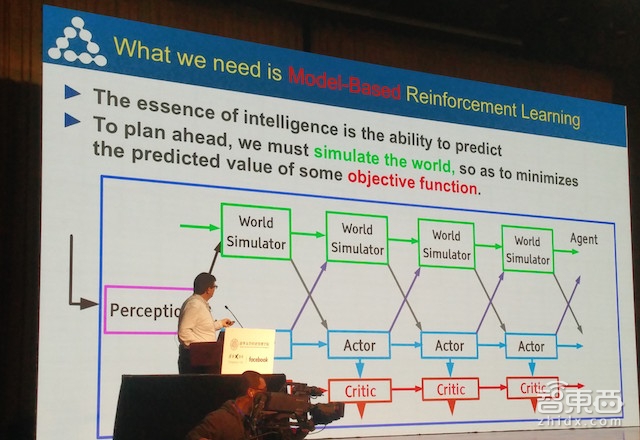
其次,对于一个AI系统来说,预测+规划=逻辑分析(Predicting + Planning = Reasoning)。如果想要让机器能够了解并且预测世界的规律,强化学习(Reinforcement Learning)需要建立一个世界模拟器(World Simulator),模拟真实世界的逻辑、原理、物理定律等。不过真实世界太过复杂,存在大量的表征学习参数,使得机器学习的计算量相当冗余,听起来似乎很诱人,但是在有限的时间内无法学习到成千上亿的参数。
而无监督学习需要机器处理大量没有标记的数据,就像给它一堆狗的照片,却不告诉它这是一条狗。机器需要自己找到区分不同数据子集、集群、或者相似图像的办法,有点像婴儿学习世界的方式。
5、无监督学习的一些突破性的尝试与结果
无监督学习的一大困难之处在于:对不确定性的预测。比如当你将一支笔直立在桌面上时,松开手的那一刻,你并不知道这只笔将会朝哪个方向倒下。如果系统回答这只笔会倒下,却判断错误了倒下的方向,我们需要告诉系统,虽然你不是完全正确,但你的本质上是正确的,我们不会惩罚你。此时需要引入曲面的成本函数,只要系统回答在曲面之下的数据,都是正确的答案。
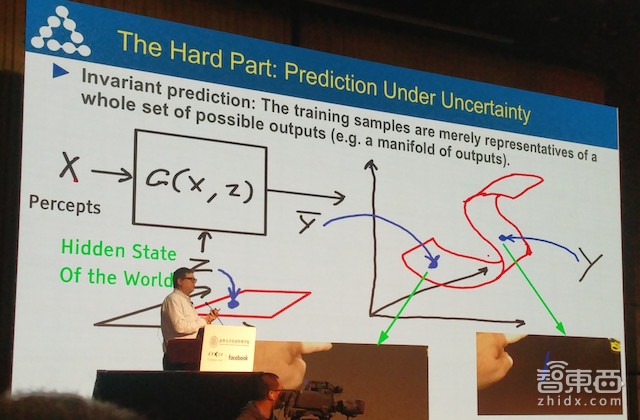
传统神经网络需要一个人类科学家精心设计的成本函数来指导学习,无监督学习为了解决这一问题,利用生成式对抗网络(Generator Adversarial Networks)对机器进行对抗训练(Adversarial Training)成了关键答案。
生成式对抗网络(Generator Adversarial Networks)是一种面向无监督学习的神经网络:它带有一个发生器(Generator),从随机输入中生成某类假数据(比如,假的图片);假数据和来自世界的真数据会一起输入一个判别器(Discriminator)中,等待判别器裁决。

两者的关系就像一个骗子和一个测谎者。判别器这位测谎者要不断优化自己,尽可能地识别出发生器生成的“假图像”,防止自己被骗;而生成器这个骗子为了瞒过判别器,也必须不断进步。在这种动态的对抗中,生成器会得到训练,最后开始生成非常真实的图片,这意味着生成器掌握了图像的特征,自己掌握成本函数——某种意义上,这就是无监督学习。
6、AI的未来
技术讲完了,我们来聊聊行业。
在演讲后的问答环节中,Yann LeCun回答了几个与人工智能行业应用的问题。他认为,未来人工智能将会落地应用、快速改革的行业包括:自动驾驶、语音交流(比如翻译)、工业制造(随着机器人在工业制造中的普及,现在这种“全球工厂”的趋势将会减退,工业制造越来越多地在本地完成,进而导致城市的构架设计也发生变化)、还有医疗健康领域(比如癌症检测)。
此外,对于许多科幻小说里提出的,最终能够“推翻人类”、“统治人类”的“超级智能”,Yann LeCun认为我们真的大可不必太担心。
人类的占领、统治、斗争等大部分行为,都是在一代代进化的过程中,受到“希望获得资源”这一目的所驱动的。而如果我们想要机器做一件事情,则需要给它赋予这个能力,朝这个目的去打造机器。如今我们已经做出了在特定领域比人类更智能的机器,但人工智能并不会真正统治世界,因为我们并不会朝这个目的去做。
7、十年之约与两个小赌
早在20世纪80年代末,Yann LeCun就作为贝尔实验室的研究员,提出了卷积网络技术,并展示如何使用它来大幅度提高手写识别能力。而在演讲的中,他还提到了1995年里,来自贝尔实验室的两个有趣的赌约。

对赌双方分别是:前贝尔实验室负责人Larry Jackel,和支持向量机(Support Vector Machine)的创建者之一Vladimir Vapnik。
第一个赌约:Larry Jackel认为,最迟到2000年,我们就会有一个关于神经网络为什么有效的成熟理论解释。
第二个赌约:Vladimir Vapnik则认为,到了2000年,大家不会再使用神经网络的结构。(毕竟人家是支持向量机的创建者之一,自然更加认可支持向量机)
而对赌结果呢?——两个人都输了。我们至今仍旧没有一个成熟的解释,可以告诉我们为什么神经网络的使用效果这么好;与此同时,我们也仍在使用神经网络架构。
最后在2005年,他们吃了一场昂贵的赌约变现晚饭,由于两人都是各输一局,因此账单对半。
结语:

作为Facebook人工智能实验室主任、卷积神经网络之父、深度学习三巨头之一,Yann LeCun的演讲比文章内体现的内容要学术得多,除了上文的亮点梳理外,Yann LeCun教授的演讲还涉及到深度学习从1957年至今的发展历程、在神经网络结构中引入能量函数的无监督学习、基于能量的生成式对抗网络(EBGAN)、深层卷积生成式对抗网络(DCGAN)、视频内容预测等。在智东西对话页回复“FaceBook”,可以获得YannLeCun本次清华演讲的全部PPT,此处就不一一展开了。
每日一头条
趋势·深度·犀利·干货,最专业的行业解读
深喉爆料、投稿:guoren@zhidx.com

