








3月20日,智东西与NVIDIA共同策划的「NVIDIA公开课」在深度学习社群开讲,主讲嘉宾为NVIDIA(英伟达)大中华区高性能计算及Applied Deep Learning部门技术总监赖俊杰博士,主题为《AI浪潮来袭,如何搭建适合自己的深度学习平台?》。这是NVIDIA在国内首次就深度学习主题组织公开课,吸引到超过1200人报名,基于专业性审核,共有近1000名以研发工程师为核心的行业用户参与到听课与互动当中。此前,智东西先后与大疆创新、亚马逊中国策划过「大疆公开课」和「亚马逊公开课」。

本文为「NVIDIA公开课」主讲嘉宾赖俊杰博士的讲课实录,分为主讲+Q&A二部分。全文共计8216字,读完需要20分钟左右,你可以掌握到:
-Deep Learning发展到了什么程度;
-如何选择合适的硬件平台;
-Deep Learning开发过程中的软件工具。
主讲实录
大家晚上好,很荣幸能有这样一个机会跟大家交流,今天我想顺着这么一个思路。
首先,Deep Learning(简称DL)发展到今天,站在我的视角上看,发展到了什么程度。当然这也是越来越多的公司需要在DL加大投入,大家会考虑搭建DL平台的原因。
第二,从硬件的角度,在做模型训练及线上服务的时候,如何选择合适的硬件平台。
最后,介绍在Deep Learning开发过程中的各种软件工具。选择合适自己任务的软件工具能大大降低开发的难度,加快产品的研发不熟,提高硬件的利用效率。
因为时间的关系,我不会讲太多技术的细节以及产品的SPEC。就像我一般做一些技术报告跟培训的时候,我经常说,希望大家听过之后,就像在听一个故事,留有一些印象。也即我大概讲了几个内容,以后遇到实际工程问题的时候,知道可以有哪些软硬件的工具平台可供选择,就足够了。细节,比如软件的API,硬件的参数,到了用的时候可以查,40分钟的时间大家听完也记不住这些。
先简单介绍一下我们团队:
第一,我们负责跟中国区核心客户的工程师合作,完成用户in-house代码的GPU移植及性能优化工作。
第二,我们会参与到各种加速计算库,包括跟Deep Learning相关加速库的开发,比如cuBLAS,CUDNN,TENSORRT等。这其中也包括由中国开发团队主导的,用来做视频智能分析的DeepStream SDK。
第三,随着Deep Learning的重要性越来越高,我们也开始尝试做一些算法模型相关的工作。比如常见的计算机视觉问题,像人,车,物的监测识别等等。
我下午在办公室截了一个短视频,就是我们基于DeepStream的一个简单工作。大家可以看一下,有一个直观的认识。后面我会稍微详细一点介绍。
那我们接下来从DL现在的应用开始。


经常有人会问Deep Learning是不是泡沫,包括这次活动收集上来的问题里面也有类似的疑问。在我看来,Deep Learning作为一种技术手段,在今天的很多领域中,或者超过了原有传统手段的效果(比如最明显的ImageNet图像分类),或者解决了用很多传统机器学习方法非常难以解决的问题。DL的使用在很多情况下都转化为了使用者的最终收益。这个也很容易理解,识别率高,效果好的产品自然而然会吸引到更多的用户。
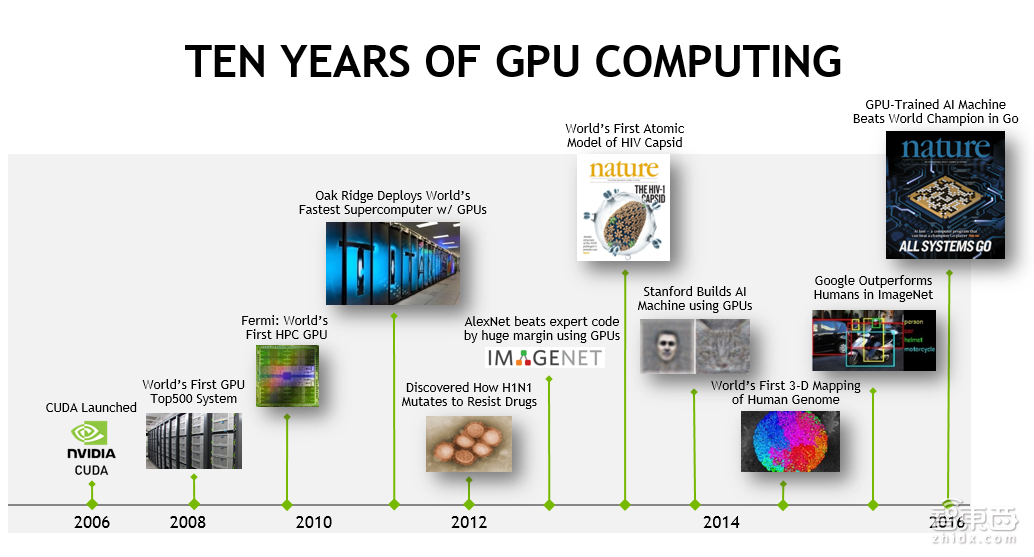
Deep Learning当然不是万能解药。但是基于以上的原因,对于工业界的用户来说,必然是有足够大的热情进行持续不断投入的。上面两页截图反映了现在深度神经网络等技术应用得比较好的一些领域。
常见的,比如计算机视觉应用中的检测,识别。语音识别。翻译。医疗影像分析处理等等。大家都比较了解。我这里也就不多赘述了。
下面举几个有意思一点的应用。


Delft理工做的无人驾驶公交车。

Paypal做的fraud detection

最后NASA用一般的图片分类的方法对地形地貌进行统计。
Deep Learning一个显而易见的好处在于大大降低了算法研发的门槛。很多传统上需要专业算法团队,积累几年甚至更久才能做的工作,现在很多公司都可以相对而言快速地涉足。
从我们的观察上看,相对而言,互联网以及安防公司在这一波的技术浪潮中走的相对靠前。我们国内比较成熟的使用Deep Learning的,其实还是主要集中在计算机视觉以及语音等领域,比如常见的以图搜图,目标检测,人脸识别,语音识别,辅助驾驶等等。在这些领域,快速迭代的网络结构以及方法,推动着算法效果日新月异地演进着,也催生出一大批创业公司。
下面我们看一下从整个生态的角度,如何去选择合适自己的平台和工具。


接触过NVIDIA加速计算产品的用户,应该都对CUDA这个词不陌生,CUDA从最初发布到今天已经有10年的历史了。CUDA是Compute Unified Device Architecture的缩写,从这个词组本身设计上,可以看出,CUDA的最初开发人员是希望CUDA成为不同平台上的统一计算接口。
NVIDIA的芯片产品主要包括:面向游戏业务的GeForce、面向专业图形图像领域的Quadro、面向企业级计算的Tesla、面向嵌入式计算的Tegra,以及面向虚拟化应用的Grid。
今天CUDA在高性能计算,加速计算领域占据着非常重要的地位,也实现了在NVIDIA各个产品线上统一接口的目标。换句话说,在NIVIDA的GeForce,Quadro,Tesla,Tegra等产品上都可以运行CUDA程序。
GPU当然并不是适合所有的任务,并且在很多情况下,需要跟CPU做很好的配合,由CPU来负责程序中的串行部分。GPU从设计之初是为了加速大量类似操作(比如几百万甚至更多像素的渲染),所以architecture做tradeoff的时候考虑的是获得多个任务总体的高throughput,而不是单个任务的低延迟高相应。GPU拿来做其它任务也必然是类似的,会比较适合大量类似的并发处理,或者说应用的并行度要足够高。
从传统上看,一直到2013年、2014年左后,NVIDIA 的GPU,特别是企业产品Tesla,主要还是应用在传统的高性能计算领域,用户主要是用GPU来加速一些理论物理、分子动力学等等科学计算类的任务。工业界的应用的话,主要集中在石油行业。其他的一些应用,也包括一些金融类应用,比如期权定价等等。那么,2012年Hinton在ImageNet比赛中取得突破性的进展的时候,采用的就是NVIDIA 的GeForce游戏显卡。那么到现在,也就是2017年,机器学习特别是深度学习,已然成为NVIDIA企业级产品应用最大的领域。
从这里我们可以看到,NVIDIA 的GPU产品在最近几年,在深度学习领域取得的成功,是有一定的偶然因素的,也存在一定的必然。说偶然,是因为技术的突破,数据的积累还有计算能力的演进,大概到了这样的一个时间点。必然呢,是因为NVIDIA其实对于Deep Learning的促进,跟在其他领域,特别是科学计算领域对那些应用的促进,并没有本质的区别,都是来源于NVIDIA 在高性能计算领域,对于整个生态环境的持续投入。正是因为有了比较好的软硬件的工具,还有比较完善的生态系统,研究人员才可以很容易的基于GPU去开发所需要的应用。回到Deep Learning,像2012年Hinton他们做的工作,最终引导了这一次比较深刻的技术变革。
我们现在再回到上面已经发过的一页PPT,里面有我们的几个平台或者说方案吧。有大家都用过的游戏显卡,像1080 TitanX这种GeForce、针对深度学习特别开发的Server服务器DGX-1。另外,我们跟很多合作伙伴会推出基于Tesla的服务器,以及我们跟用户或者合作伙伴,像Amazon、阿里云等等,在云端给用户提供有GPU的HPC节点。
这次交流其实很重要的一点,大家在做DL,特别是刚开始做DL训练的时候,选择用什么样的一个方案呢?这里只是我的一些建议:
首先,如果大家在开始或者是初期的时候,如果只有非常少量的服务器,或者说机器。打比方说,我只有四五台 Server,很多人的选择就是先用几块GeForce显卡,稍微先试一试;当需要大规模投入的时候,一般来讲大家都会去选择用企业级产品Tesla。这里面最大的一个原因,在这里就不展开讲,主要是由于硬件设计之初,企业级产品是要保证24小时稳定工作的,不太像消费级产品对容错率要求不是那么高。可以想像一下,假设一块显卡的出错概率,是一个月出错一次,那么你想一下,如果你有一百块,甚至更多的显卡的时候,会是什么样的一个场景。
如果需要大量计算资源的时候,也有两种选择:
1、比如说买一些GPU的Server;
2、选择NVIDIA跟合作伙伴做的Tesla的GPU Server,或者选择DGX-1。
两者之间主要区别是什么呢?DGX-1主要是对扩展性要求比较高的场合。换句话说,当你需要在相对短时间内,对一个比较大的模型进行训练的时候,用DGX-1。
如果你不太有比较大规模训练任务,比如用2块GPU做几个小时就可以完成的,一般用2卡或4卡的机器,都可以满足大家的需求。
那么,到底是自己选择买Server,还是用云服务,也就是HPC GPU节点。主要区别在于你到底想不想在IT这块,也就是硬件的infrastructure上做投入。如果用云服务,硬件维护还有整个环境的管理,都是由云服务商提供的,确实可以省去比较多的麻烦。当然,如果决定自己去维护这个环境的话,可以试图搭建硬件平台。


上面两页是Tesla P100的SPEC。它的具体SPEC,比如峰值是多少等等,我就不详细介绍了。主要说两点,一个是P100用了HBM2高速的memory,它的GPU memory带宽会非常高,第二,GPU之间可以用NV Link进行互联。NV Link单个通路,单向可以做到每秒二十几GB,能够大大地加速GPU之间的数据传输。
NVIDIA推出的DGX-1,是由2个CPU,再加8个P100的GPU所构成的,GPU之间由NV Link进行互联。在做神经网络模型训练的时候,实际上有两个主要步骤:
一是做梯度的计算;
二是做梯度的Reduction;Reduction的时候是需要大量的数据传输。用DGX-1的话,中间利用NV Link,能够显著的缩短Reduction时候内存拷贝所带来的对于scalability的影响。
对于training来讲,选择稍微复杂一点。总结一下,还是要看大家的需求:
如果是少量training需求,特别是一开始尝试的时候,完全可以买一二块消费级显卡先试一试;当变成非常严肃的投资时,当你需要买几十块乃至几百块GPU,还是建议用企业级产品,要么采购GPU服务器,要么用云服务商提供的GPU节点。inference的话,相对简单一些。

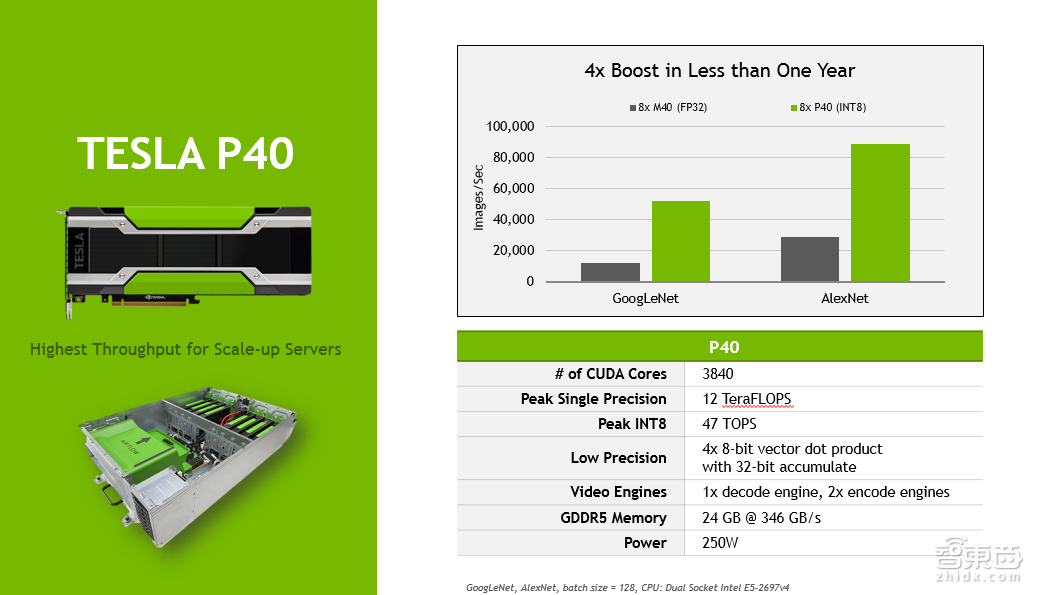
上面是P4和P40两款GPU的SPEC。这里也不详细介绍了。最关键的提一点,就是其中的int8的支持。
int8指的是用8比特的整型去做神经网络的前向inference。实际测试发现,int8的使用,可以通过数据转化的调整等等操作,把精度的损失降到非常非常的小,打比方说,在做图像分类的时候,精度损失在百分之零点几。对于精算性能的提高,还是很显著的。理论上来说,是四比一的关系。实际上,相对于MP 32的浮点数计算能力,大概是三点几倍。
值得提的一点,Tesla P4实际上是由NVIDIA中国的解决方案工程师针对中国用户的需求,向美国总部提出并设计的产品。你会发现它的功耗比较低,只有50瓦或者70瓦这两种SPEC的SQ,不需要额外供电,能够插在很多没有针对GPU做额外电源设计的服务器里面。
上面主要介绍的是硬件的平台的选择。接下来,主要从整个软件生态上做一个概括性的介绍,大概能了解清楚NVIDIA提供哪些软件库供方便大家使用,很多情况下不需要做重复开发。
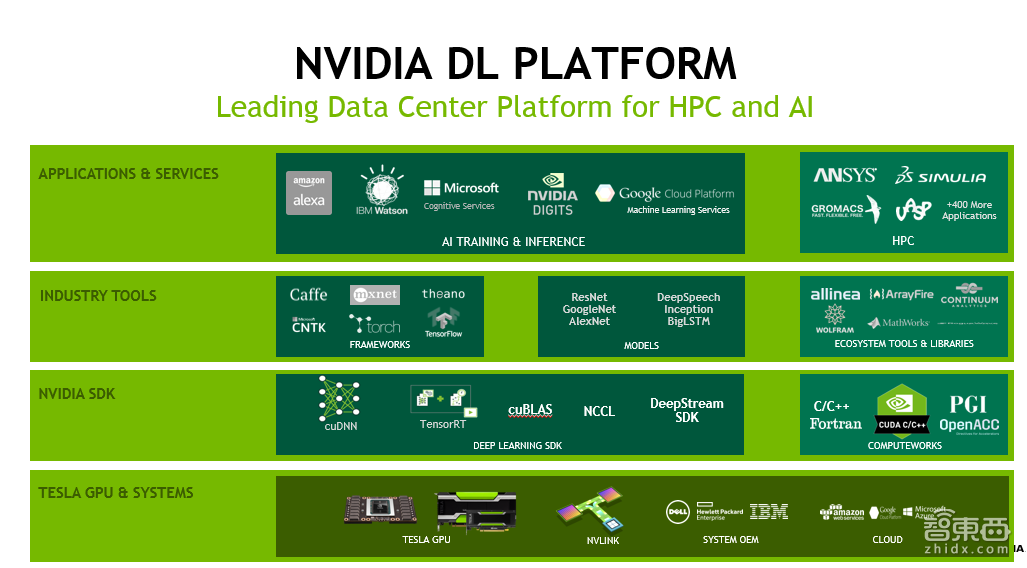
大家看下上面这一页PPT。前面我主要讲的是最下面的Tesla GPU &Systerm,也即最底层的硬件。在这之上,有CUDA Runtime,有基于CUDA的各种各样的算法库,最基本如BlAS做基础的矩阵,相当于运算的库。接下来的话,我会大概的介绍一下主要是三个,一个是CUDNN,一个是TENSORRI,一个是中国团队做的DeepStream。
刚才我又截了几页PPT。其实,每一个软件或库,展开讲可能几个小时都讲不完,所以我这里大概介绍下。
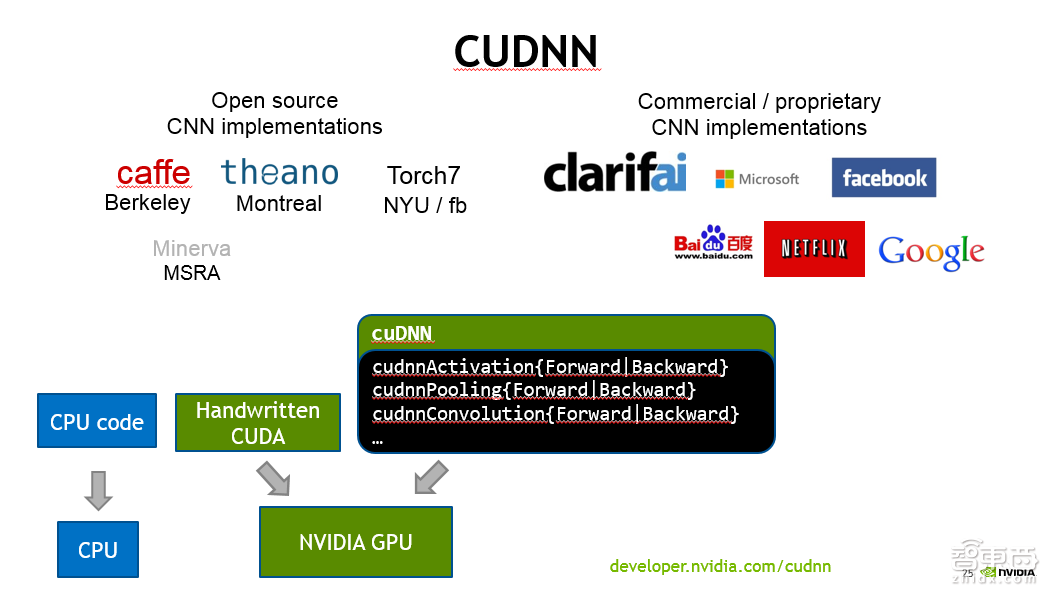
首先讲CUDNN。 CUDNN设计的最主要目标,性能是第一位,其次是灵活性。它主要针对Deep Learning的training工具设计的。换句话说,CUDNN实现了我们在神经网络里面遇到的一些常见layer,或者说是操作。打比方说,一般的卷积convolution、pooling等等defining操作。这些都是按照Deep Learning的开发人员能更方便理解和使用的接口,暴露给大家。
大家在用CUDNN的库的时候,实际上大多数情况下,你都不大需要了解是怎么在GPU上做CUDA代码的开发的,因为这些细节都隐藏在CUDNN后面了。
现在主流的一些可训练工具,像Caffe、Torch7、Theano、MxNet,都提供CUDNN的backend。
作为这些Deep Learning训练工具的研发人员,就可以很方便地用CUDNN 提供的layer的前向与后向的操作,来快速搭建training的库。
当然,我们完全可以基于CUDNN写一个网络的前向计算。我之前也做过类似工作。但是,在大多数情况下,不管是做Deep Learning的训练还是inference,都比较少用CUDNN,或者说CUDNN对大家来讲是透明的。比方说,在编译Caffe的时候,就把CUDNN在Caffe的makefile去给它enabel,然后把CUDNN的库下载下来,编译下Caffe,然后link一下就可以work。实际上是在用CUDNN,但是你没有在代码里面主动调用。
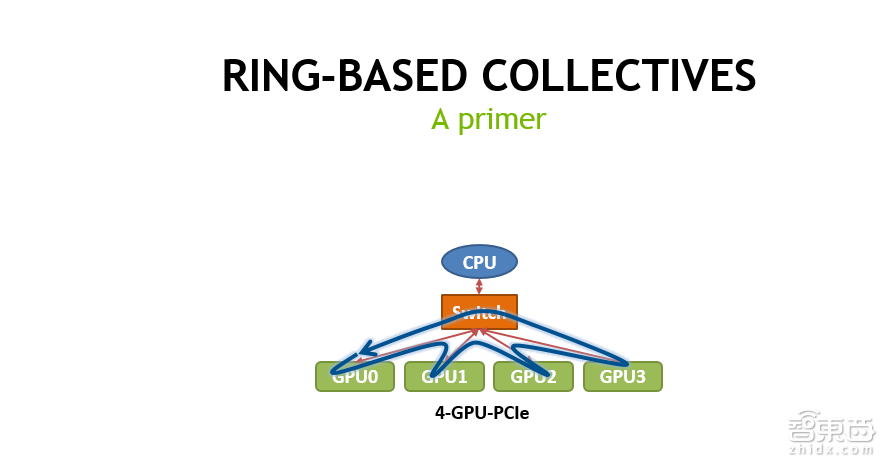
第二页PPT是NVIDIA的NCCL库的作用示意。NCCL主要是为了加速在多GPU环境,同时用多块GPU做training的时候,它做出一个同步,或者说Reduction时候,加速collective的过程。
它的最核心思想是什么呢?在做数据传输的时候,把大块数据切成小块,同时利用系统里面的多条链路,比如现在是PCI-E链路,同时利用PCI-E的上行和下行,尽量去避免不同的数据同时用某一个上行或者下行通道,可能会造成数据的contention,大大降低传输效率。
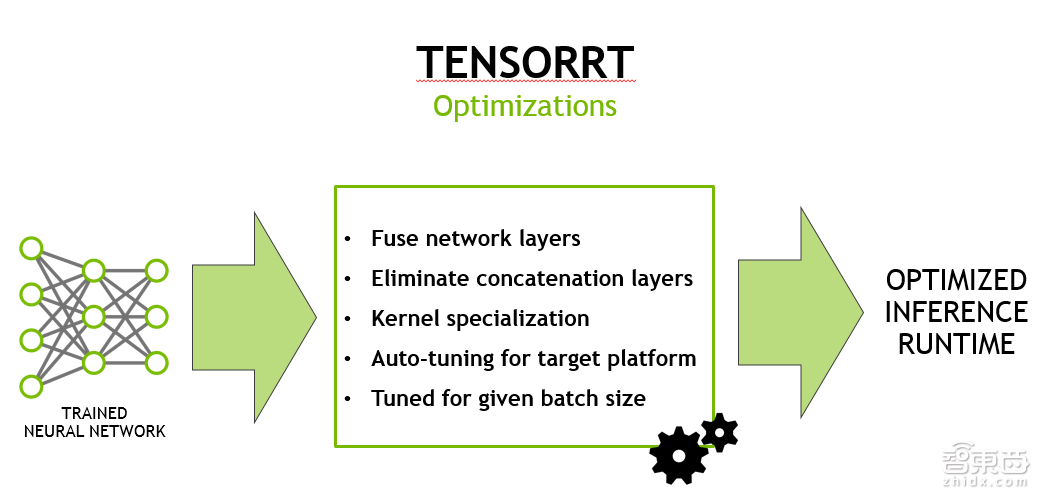
第三页PPT是TENSORRT。TENSORRT的目标很简单,当你训练好了网络,需要部署的时候,能够尽量地加速线上的inference的throughput。TENSORRT跟CUDNN最大的区别在于,CUDNN里面的API都是ProModule,或者说ProLayer,也就是说,在优化卷积的时候,我只知道卷积的参数,然后再做优化;而输入给TENSORRT的信息,是包含整个网络的信息,如layer结构是什么样子,连接关系是怎样的。
所以说,TENSORRT可以做很多CUDNN做不了的优化,这里面列举了一些常用的:
举一个例子,卷积属于比较大的操作。在卷积之后,经常会连接一些小的操作,比如pooling。如果用CUDNN,实际上把计算过程会变成两个API的调用:一个做卷积,一个pooling。这样的话,卷积和pooling之间,首先卷积的结果,要把它存到memory里面去,然后再去做pooling操作,你需要把数据从memory读回来,然后再把最终结果存回去。
Network LayerFusion的一个思想,指的是我既然知道前面是卷积,后面是pooling或者其他操作的话,在有可能的情况下,在前面的这个layer做完之后,我不是把结果立马写回memory里面去,而有一些后面的小操作可以直接做的情况下,我可以先做了之后,再寄存器或者memory。把数据存在那个位置,然后把最终结果算完之后,再一次存回内存里面去,可以显著地提高性能。
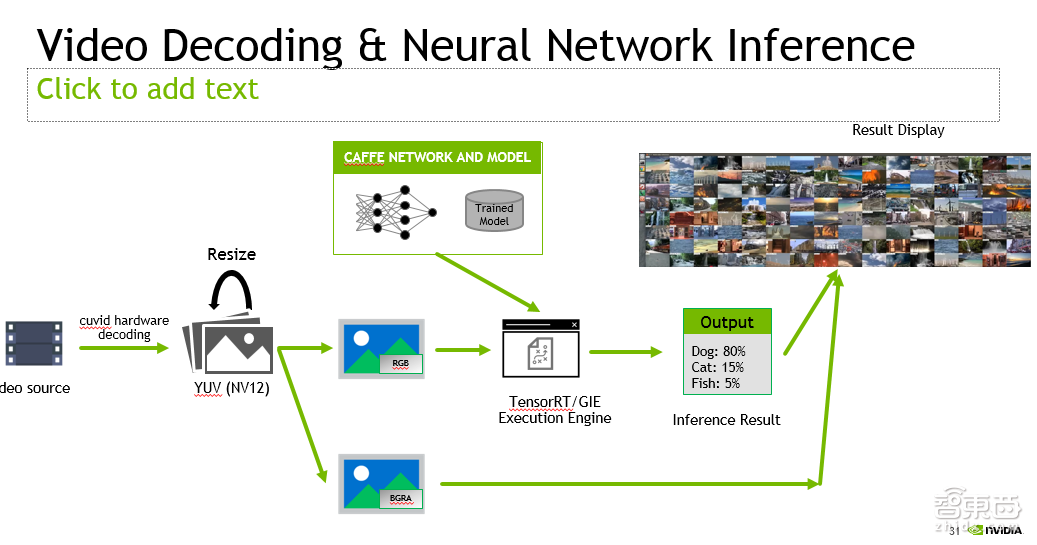
这是前面提到的我们做的DeepStream的SDK。想法也很简单,NVIDIA的GPU上,除了有一般的计算单元,可以用来做神经网络的前向计算,还有做视频编解码的ASIC。
这也可以说是我们从消费产品里继承的一些东西,在Deep Learning的应用里,有很大一类应用是来做视频的智能分析。我们实际上可以用GPU上专有的视频解码硬件,去对视频首先做解码操作,再将解码出来的视频帧,扔给后面的神经网络去做前向的计算。大概的流程就如这页PPT里所展示的样子。
那么,有了这样一个SDK,或者说编程框架之后,我们在做视频类的智能分析的时候,就非常方便。比如说上面是我们做的几个应用,第一个是基于NVIDIA DetectNet做的车、人检测;第二是人脸的检测和关键点的定位;第三个是大量视频的scene classification,就是场景的分类。
这里面主要有两点值得注意的地方:第一,它的一个目标是做大量视频的同时的实时处理,这些短的截图都是在一块NVIDIA的GPU上做到的。
那么application at scale实际上是NVIDIA很大的一个价值所在,用GPU的话,可以用相对少的硬件去完成很多任务的处理。
另外一个值得注意的地方,也是我们开始做这个工作的一个初衷,就是有了这样的一个框架之后,你可以想象成,当你训练好一个Model,你把这个Model放进SDK里面,我就可以拿到一个最终的产品了,然后非常方便地做产品的部署。

最后,稍微总结一下,我们前面提到了互联网行业和安防行业在这一波浪潮中属于脚步相对较快的;与之相对,传统行业对深度学习技术的接受与应用相对较慢一些,这是从我们的角度看到的一个现象。很多公司其实都询问过我们,他们的应用是否适合深度学习的方法去做。
从这个角度来看,深度学习、深度神经网络,以及其他一些比较新的机器学习的方法,其实有非常非常大的想象空间,因为有非常多潜在应用可能都可以采用这些方法去做很大的革新。我相信随着技术的不断进步,我们会在越来越多的其他领域发掘出深度学习的一些妙用。
最后,坦白讲,今天我们讲的人工智能,可能跟大众心目中的强人工智能的距离还是比较远的。不过我觉得深度学习是我们朝着真正的所谓智能迈出的非常坚实的一步,把这一步夯实,其实我们已经可以做非常多有价值的工作了。这其实也是NVIDIA,特别是我们团队努力的目标,那就是使得越来越多的应用能更好、更方便地使用深度学习的技术,并且最关键的是要达到工业级应用的水平,换句话说就是有足够高的性价比,能为大家去创造价值。
最后在这里我真诚地向大家发出邀请。如果大家对NVIDIA加速计算及Applied DL部门感兴趣,有志加入NIVIDA的话,全职或是实习均可,可以加给我发邮件julienl@nvidia.com,并附上您的简历。谢谢!
Q&A实录
提问一:创业公司搭建深度学习平台初期,应注意的重点。(来自@Alice-恩知-智慧医疗)
赖博士:主要是看需求,如果只是少量的计算需求,或者刚开始使用GPU平台的话,完全可以先买几块GeForce消费级显卡试水。如果需要大量部署的时候,主要有两种选择。如果不想投入太多硬件维护的人力,可以采用像阿里云,Amazon Cloud等等云服务商提供的GPU节点。当然用户也可以自己购买GPU服务器,这里面包括NVIDIA自己的DGX-1(主要适合对于扩展性要求高,模型大,训练量大的场合),或者是一般的NVIDIA合作伙伴提供的GPU服务器。
提问二:赖老师,您好!非常高兴能听您的分享,我们公司现在在做机器学习这块,工作站及个人笔记本都用的英伟达GPU,想问您一个问题,就是我们在做机器学习时,如何能最大化GPU使用效率?另外一个问题,不知道赖老师对于深度学习在工业方面的应用能不能给出一些建议?或者从您的了解,目前在工业自动化领域,深度学习是否已经开始或得到了一些比较好的运用?非常非常感谢您!(来自@肖素枝-兰宝传感-机器学习)
赖博士:第一个问题,最大化GPU使用效率。在做training的时候,如果用户是用一般的开源框架去做,其实这些东西已经wrap到工具内部了,一般不太涉及到计算性能优化的问题。如果用户是自己开发的训练的软件,这里面问题就很复杂,一两句就描述不清楚了。最核心的其实就是如何能够提高软件的Scalability。如果是做inference,部署的时候的性能优化还是需要做一些工作的。建议有需要的时候可以跟NVIDIA联系,我们的团队可以给一些具体一些的建议。
第二个,深度学习在工业自动化领域的应用。我大致了解,在这个领域,很多都是把CV里面的一些检测分类的方法用到具体的问题里面。NVIDIA跟FANUC已经开展了比较深入的合作。
提问三:现有的深度学习神经网络模型很容易被未来更好的模型所取代。如何在GPU平台做到很好的可重构性,同时保证高效能?(来自@程亚冰-机器学习)
赖博士:GPU平台的一个很大的好处就在于,其有一定的通用性,编程相对容易。所以在新的模型,或者layer出现之后,在GPU上可以很快地获得比较高效的实现。所以新的网络在GPU上往往会获得快速的应用。这也是为什么大家选择GPU做DL的很重要的因素之一。
提问四:深度学习的商业化广泛应用时间点?(来自@王学刚-Senmass-智能包装)
赖博士:其实我们完全可以说,现在深度学习已经获得了广泛的商业应用。打个比方说,我们常见的语音图像类应用,大部分都已经切换到了深度神经网络的backend。你会发现这几年手机里面的各种语音助手似乎都达到了基本可用的地步。这些都是深度神经网络大规模商用带来的好处。
现在的问题是如何进一步扩展DL应用的应用领域。想象空间如前面所讲,是非常非常大的。
提问五:可以简单介绍下 Applied DL部门主要的工作内容,和已有的成果吗?(来自@贾庸-中科院·MLDL算法精研社)
赖博士:前面其实介绍过一些。我们核心做的还是加速计算。让用户用更少的硬件完成更多的任务。除了做一些具体的代码的移植优化的工作,主要也会做一些library(像DeepStream)之类。另外现阶段基于DeepStream做过一些人脸,人车检测等等应用的参考。主要考虑是了解用户那边的workload,方便用户做二次开发。
提问六:赖博士,DL能够应用到EDA工具软件里面吗?例如,PCB自动布线,未来能够利用DL完全替代人工是否可能?(来自@刘颖峰-舒尔电子-高级工程师)
赖博士:坦白讲,我对这个真不了解。不过我可以讲的是NVIDIA确实有研发人员在探讨如何将DL用在芯片设计流程中。
提问七:非常精彩的报告!想问个问题。与GPU用于一般的HPC相比,GPU用于Deep Learning有啥不同?
赖博士:其实没有什么本质的不同。我们完全可以把Deep Learning的workload,不管是training还是inference看成是HPC的应用。这也是为什么现在做DL的infrastructure一般都采用的HPC模式。像通信接口采用MPI。这里面追求的核心是performance,而不是扩展性,容错性,等等。
提问八:GPU Server的计算能力和memory之间有瓶颈吗?有的话是在内存(DRAM, HBM)带宽,还是内存和存储(SSD, 3D point)之间的带宽?(来自@王楠-中科创达-战略投资经理)
赖博士:计算能力跟内存(DRAM)到底谁是瓶颈取决于应用大致是compute bound还是memory bound的?
一般来讲,至少我看到的例子,不太会反复地对存储进行大量数据的读写,如果真有这样的应用的话,那很有可能存储的带宽会变成瓶颈。GPU的计算能力跟memory带宽量级都较存储带宽高很多。更多的情况是,预先把数据都load 到memory(CPU或者GPU),或者存储里的数据地访问,相对于后续的处理是相对少量的。
提问九:谢谢赖博士精彩的报告。我们对瞳孔识别的定位帧率和精确度有比较高的要求,我们自己普通PC上做到了120HZ左右。但想更快。不知道有没有可能利用DL进一步提升。NVIDIA有训练相关的模型或者库,支持相关的开发吗?(来自@范杭-弥德科技-裸眼3D游戏)
赖博士:这个太专了。我首先不清楚DL用在你们的应用里面是否能达到足够的,你们需要的精度。其次,一般来讲,DL相对于传统的方法的计算量需求都大。所以一般不太会有为了提高计算速度而采用DL的。一般都是为了提高精度(当然是可能的前提下),牺牲一些计算量,来用DL。
