








智东西(公众号:zhidxcom)
文 | Lina 晓寒
9月26日的北京,天气阴凉,略有雾霾。
智东西9月26日北京现场消息,今天,英伟达2017 GTC China(GPU技术大会中国分会)的最重磅环节——CEO黄仁勋(粉丝爱称“老黄”)主题演讲——开始了!智东西作为特邀媒体,从大会现场第一排发来报道(文末附全场PPT下载)
GTC大会已经不仅仅是通常意义理解的“显卡技术大会”了,而是一场展示英伟达AI、VR、深度学习等众多新技术的重要窗口,在早上8点多就引来上千人到场。

本次演讲的几大亮点如下:推出新版TensorRT 3深度学习应用平台;推出世界第一款机器人芯片XAVIER;宣布阿里、百度、腾讯“三朵云”数据中心都开始使用Tesla V100新款GPU;与海康威视合作打造AI城市;宣布与京东在仓储机器人与送货无人机方面的合作等。
5月时,英伟达曾在美国主会场举办2017 GTC,并推出了新款GPU Tesla V100以及DGX-1超级电脑、HGX-1云服务器、ISSAC机器人训练平台等众多新品,智东西作为特邀媒体,受邀来到硅谷对其进行过详细的深度报道(多人VR交互、30亿刀的显卡、神秘ISAAC黑科技……干货满满的GTC 2017一文看尽)
和5月的GTC相比,本次GTC China上推出的新品与宣布的合作案例大多集中在深度学习推理应用(Inference)领域。可以看得来,凭借着超高计算性能的GPU在深度学习训练(Training)领域赚得盆满钵满的英伟达,现在也想要朝应用端发力了。
一、开场:跟5月的GTC差不多


(老黄今天还是一身万年不变的经典黑色皮衣开场)
9点十几分,主题演讲稍稍延迟开场。名为“i am ai”的开场视频以“我是科学家”、“我是治愈者(healer)”、“我是保护者”、“我是老师”等第一人称作为旁白,介绍了以英伟达GPU驱动的人工智能如何在数据、医疗健康、翻译、机器人、自动驾驶、教学等等领域进行应用。
这个开场视频复用了与5月GTC的开场视频架构,但是加入了本土化的科大讯飞、图森驾驶等镜头。
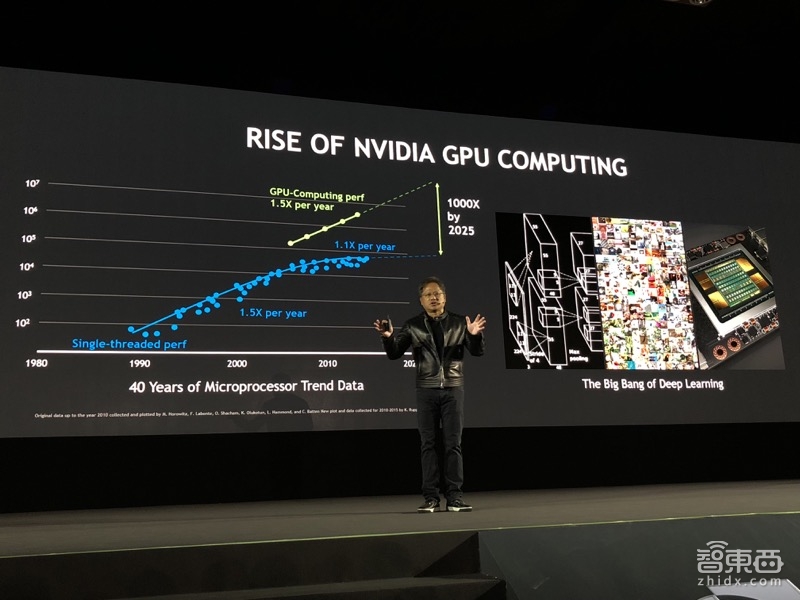
与5月的GTC一样,老黄在开场时讲起了最近的几年里摩尔定律开始失灵,人们需要花越来越多的成本来换取计算能力的些微增加。而且,与摩尔定律逐渐失灵形成对比的是GPU的崛起。
随着人工智能与深度学习在近年来的兴起,以GPU驱动的计算已经随处可见,英伟达的AI平台也支持目前所有深度学习框架、所有云与数据中心,并设立了Inception深度学习创企计划,目前已经有1900家企业参与。
而且,CUDA开发人员的数量也在5年里增长了14倍,超过60万人,CUDA SDK的下载量也达到180万。世界各地的AI初创公司不断涌现,今年为止已经获得了66亿美元的融资,而且今年发表的深度学习论文也已经超过了3千篇。

现在有不少AI应用都是此前人类难以想象的,比如利用深度学习自编码器完成只有部分被渲染的逼真图像、自动生成语音+3D人脸动画、人体动作动作实时追踪、人体动作模拟等等。

接着,老黄又讲起了5月曾经发布的VR多人交互平台Holodeck,不过这一部分跟(多人VR交互、30亿刀的显卡、神秘ISAAC黑科技……干货满满的GTC 2017一文看尽)展示的相同,没有增加新内容。
二、将阿里、百度、腾讯“三朵云”纳入囊中
在5月的GTC上,老黄请来了亚马逊AWS和微软Azure云,而这次的GTC China上,又怎么少得了国内云服务合作伙伴呢?
这次老黄宣布,阿里云、百度云、腾讯云,国内三个代表云服务商都开始用上咱们新推出的Tesla V100 GPU啦!
其实在此之前,BAT三朵云的数据中心里面已经在使用英伟达的GPU了,这次老黄只是强调下他们都已经用上Tesla V100啦,同时BAT作为深度学习思想领袖赞助商来露个脸~

(Tesla V100参数图)
Tesla V100是英伟达在今年5月推出的新款GPU,号称“世界上最昂贵的计算能力项目”——投入30亿美元研发。这款GPU采用的是台积电的12nm Finfet工艺,有210亿个晶体管,采用Volta Tensor Cores架构,单个计算单元比原本的速度快了12倍。
此外,老黄还宣布,国内的HGX云计算服务器将会由华为、浪潮、联想作为OEM商进行代理。

HGX-1是英伟达在今年5月GTC上推出的一款专门用于GPU云计算的超级电脑,适用于公有云、深度学习、图形渲染、CUDA计算等。配备了8块Tesla V100 GPU,售价14.9万美元。
三、重磅:新版深度学习应用平台TensorRT 3
深度学习分为训练(Training)和推理应用(Inference)两个部分,数据科学家们在将一个神经网络通过大量数据训练好之后,再将这个训练好的神经网络应用到硬件上,进行人脸识别、语音识别等的AI软件应用。

然而,从CNN到LSTM再到GANs,现在的深度学习神经网络框架正变得越来越复杂、越来越多样、而且在日新月异地变化着,训练环节的复杂性自然也带来了应用环节的复杂性——TensorRT就是为了解决这一问题的。
这次GTC China上,老黄带来了新一代深度学习应用平台TensorRT 3。

TensorRT是一款可编程应用平台(Programmable Inference Platform),什么意思呢?就是你将一个神经网络训练好了之后,可以通过TensorRT可编程平台,简便快捷地将这个训练好了的神经网络部署(Deploy)到Tesla V100、Jetson TX2、Drive PX 2等英伟达的GPU硬件上。
跟上一代相比TensorRT,本次的TensorRT 3有三方面的进化:
1)增加支持的深度学习框架:新一代TensorRT支持TensorFlow、mxnet、Caffe2、PYTORCH、theano、Microsoft Cognitive Toolkit、Chainer、还有百度的PaddlePaddle——几乎覆盖了市面上所有的深度学习开源框架。
2)增加支持的GPU:现在TensorRT可以应用到英伟达的全线GPU中,从几瓦到几百瓦的Tesla V100、Tesla P4、Drive PX2、Jetson TX2,以及NVIDIA DLA框架都可以支持。
3)增加应用:原先TensorRT相对而言更擅长图像处理等方面的深度学习应用,现在无论是云、数据中心、机器、机器人等等,都可以轻易处理。
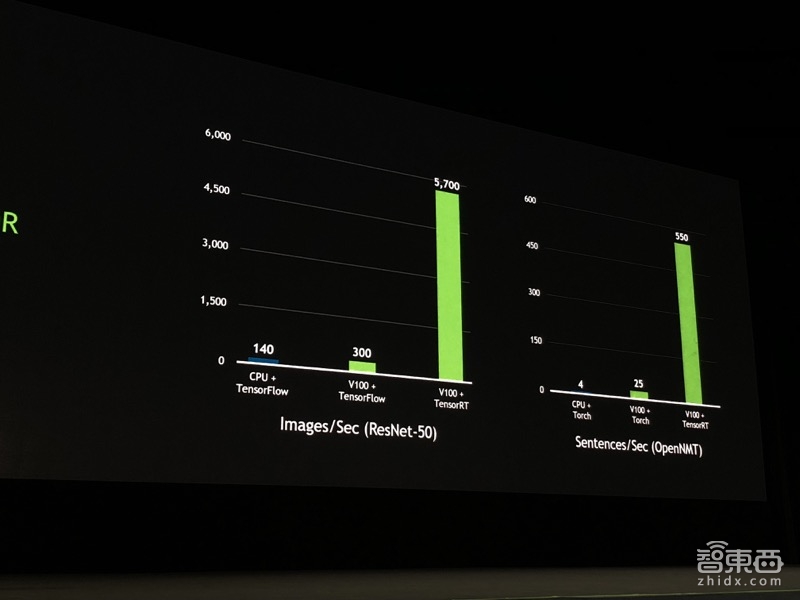
此外,TensorRT还被老黄称之为“世界上最快的TensorFlow应用平台”,在Tesla V100上应用的性能能达到CPU的几十到数百倍,并且处理图像时只有7ms的延迟,处理语音的延时不到200ms(前不久谷歌用于数据中心的TPU也是7ms的延迟)

为了达到这样的高效、快速、低延迟、高能效比的效果,TensorRT采用了层级融合、动态内容、多层级并行计算等技术,而且采用的是8bit计算。
工程师将训练好的深度学习神经网络应用在GPU板卡上时,最快只需要几秒钟就能成功部署,而且需要人工操作的地方非常少。

而且,通过迁移学习,英伟达可以提供事先部分训练好的神经网络(Pre-Trained Network),在一个已经经过大量数据训练过的网络的基础上,用户加入自己少量的需要训练的部分数据,就可以得到很好的效果。
由于Tesla V100相较于CPU加速了40倍,所以只需要一台8GPU服务器就可替代160台双CPU服务器或者4个机架,每台V100服务器可以节省50万美元。


(4个机架的CPU和1个机架的GPU)
在这一页PPT里老黄来来回回切换了4、5次,简直玩得不亦乐乎。而且老黄一而再、再而三地强调了“省钱、省钱、省钱”,“Saving Money”从这一刻开始贯穿了全场演讲……
四、TensorRT的合作伙伴与应用案例
阿里云、百度云、腾讯、京东、科大讯飞也都宣布成为英伟达GPU应用加速平台的合作伙伴,他们正竞相讲AI融合到商业、社交、新闻、凸显等应用中。


(用CPU和GPU来识别花朵)
现场的Demo中,老黄展示了用CPU和V100+TensorRT 3来识别花朵的速度差别,GPU将近快了100倍。

第二个Demo则是通过语音识别,在《权力的游戏》中通过搜索台词,直接定位到剧中角色讲出这句台词的镜头。

接着,老黄宣布,英伟达将和海康威视一起打造AI城市。海康威视的安防项目端到端解决方案中将会从训练到应用都使用英伟达平台。据老黄介绍,这是英伟达和海康威视两年以来长期合作的成果。
到了2020年,城市里将会有十亿摄像头,帮助寻找失踪人口、智能控制交通、协助执法等等,城市将变得更智能、更安全。

此外,英伟达还和华为、大华、阿里巴巴等公司在智能城市、智能交通、虚拟保安等方面进行了合作。
五、L3-L5自动驾驶平台
这次GTC China并没有公布新的产品,黄教主重新介绍了一下英伟达在自动驾驶方面的动作——AV(AutonomousDriving ) Computing Platform自动驾驶计算平台。
从纵向来看,该平台共有四层,如下图。

其中DriveOS为自动驾驶汽车所搭载的软件操作系统,这一部分是各个自动驾驶公司的东西,英伟达提供的主要是计算能力。
这里计算能力的核心就是基于英伟达GPU的计算模块Nvidia Drive PX。
目前Drive PX已经发展到了第二代,被称为Drive PX2,通过组合不同数量的Drive PX2可以支持不同级别的自动驾驶能力。
如1块PX2可以支持L2级的自动驾驶,4块PX2则可以支持L4/L5级别的自动驾驶等。
补充一点,PX2上搭载的是基于Pascal架构的显卡,而英伟达在5月时也推出有升级版的产品Drive PX Xavier。搭载了英伟达那个花费30亿美元研制出来的Volta架构的显卡和8个CPU,被英伟达称之为迄今为止最复杂的片上系统,支持L4/L5级别自动驾驶能力。Drive PX Xavier 2018年第一季度为早期合作伙伴推出,第四季度全面出货。
光有硬件不行,为了让开发者更好的使用PX2与PX Xavier系列产品,英伟达也很贴心的推出了配套的开发者工具——英伟达DriveWorks。
有了硬件,有了开发者工具,自动驾驶技术开发者就可以将自己的软件系统部署在这些计算平台上,并运行各种深度学习的网络。
有了深度学习网络,自动驾驶汽车就能对车载的激光雷达、毫米波雷达、超声波雷达、摄像头等传感器的数据进行处理,从而帮助汽车实现感知、定位、规划三大功能,完成自动驾驶功能。

同样是得益于GPU在深度学习方面的先天优势,老黄表示全球有145家从事自动驾驶技术研发的公司在使用英伟达的自动驾驶平台。
其中包括国内的Momenta、获得英伟达投资的图森未来、在前一段刚刚展出了自动驾驶快递车的京东等公司。
有意思的是,黄教主这次并没有单独提及GTC上提出的,包含有Auto-Pilot、Mapping-to-Driving、Guardian Angel、Co-Pilot等功能的AI Car Platform。
最后老黄也表明英伟达的野心其实并不只在自动驾驶汽车,其未来的野心是为无人机、机器人等所有智能设备提供类似的计算能力。
六、从硬到软,打造机器人大脑
会上,老黄正式宣布推出了世界第一款用于自动机器人的处理(芯片)——Xavier,上文提到的自动驾驶Drive PX Xavier芯片是它的一个架构分支。

Xavier集成了8核CPU、Volta TensorCore & CUDA GPU、传感器、8K HDR VP、以及CVA。可以应用在30TOPS的计算机视觉、深度学习等机器人所需要的技能领域,有着超高计算力与超高能效比。
这款处理将于2018年第一季度提供给早期合作伙伴,2018年第四季度全面推出。

与此同时老黄还宣布,英伟达的Xavier将会用在京东的仓储机器人jROVER+京东送货无人机jDRONE等一系列自主机器人当中。据京东表示,到了2022年,将会部署10亿自主机器人。
现在,这些自主机器人有了硬件大脑,可是软件大脑怎么办呢?
别急,今年5月时,英伟达推出了一个用于训练机器人的增强学习世界模拟器——ISAAC机器人训练模拟世界(ISAAC Robot Simulator)模拟真实世界的逻辑、原理、物理定律等,然后再将机器放进这个世界里不断训练。

你可以在这个世界里对成千上万个机器人进行超越物理时间规律的快速训练,然后找到里面最聪明的一个机器人,将它的“大脑”程序复制出来,重复这个过程,直至选出最聪明的一个神经网络,将它部署到XAVIER上,再将这块芯片放进机器人的“脑袋”中。
七、日益兴旺的AI应用需求
正如前文所言,和5月的GTC相比,本次GTC China上推出的都是集中在深度学习推理应用(Inference)领域的新款计算平台TensorRT 3、又或是各种BAT云服务商、京东机器人等的应用端合作落地案例。
凭借着超高计算性能的GPU,英伟已经在深度学习的两个环节之一:训练(Training)这一领域几乎占据统治级地位,此时也想要朝另一个环节:推理应用(Inference)端发力了。
如今,LinkedIn上每天有着2万亿条信息需要被个性化处理、科大讯飞每天有5亿用户需要使用语音识别技术、谷歌翻译每天要处理1400亿个单词、YouTube上每天有600亿帧视频被上传……在这个数据爆炸的年代,我们对AI应用的需求越来越强大,也越来越迫切。
以上种种问题都可以用AI进行处理,但问题在于现在的数据中心很多都是几年前针对搜索引擎等互联网应用打造的,无论是框架还是工作负载都不适宜进行实时AI应用落地。
英伟达的合作伙伴们——像是拥有十亿用户基础的微信语音转文字功能、拥有1千频道的京东需要智能视频分析、以及日均80亿条信息的阿里巴巴需要的翻译功能——在其数据中心里使用了英伟达GPU后,都在速度、准确率、延迟、能效比方面有了极大的提升。
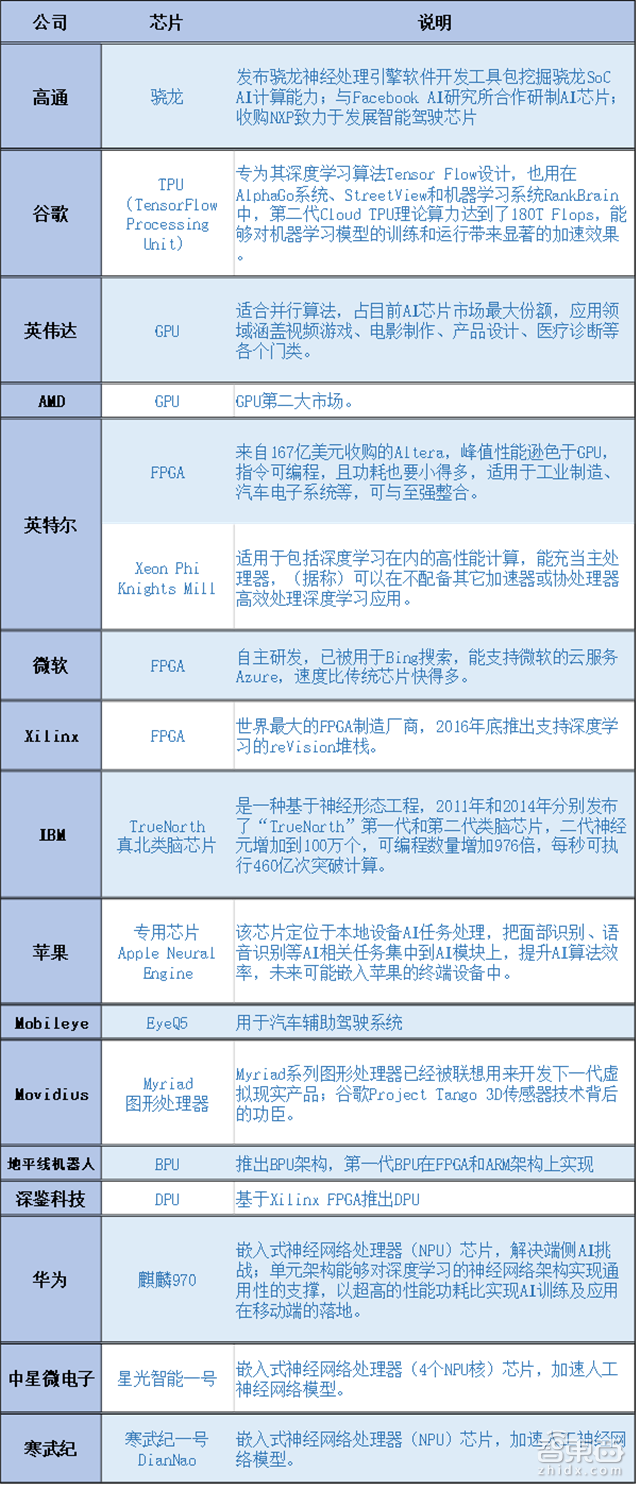
当前人工智能板卡主要分为GPU、ASIC、FPGA。代表分别为NVIDIA Tesla系列GPU、Google的TPU、Xilinx的FPGA。GPU的优势在于性能强大、生态成熟,但从另一个角度来说,跟FPGA、ASIC等板卡比起来也会遇到功耗较大、价格较贵、某方面性能不够极致等弱点。
最近华为推出的麒麟970手机芯片和苹果推出的A11手机芯片等都属于ASIC(专用集成电路,Application Specific Integrated Circuit)根据特定的需求而专门设计并制造出的芯片。
结语:大势所趋的端智能
正常演讲中,老黄已经很少提到训练部分了,大部分都在将深度学习的应用环节。推出新版TensorRT 3深度学习应用平台;推出世界第一款机器人芯片XAVIER;宣布阿里、百度、腾讯“三朵云”数据中心都开始使用Tesla V100新款GPU;与海康威视合作打造AI城市;宣布与京东在仓储机器人与送货无人机方面的合作等……从本次GTC China的种种落地案例中我们可以看到,英伟达正一步步地努力朝AI应用端发力。
而从日益兴旺的AI板卡市场可以看出,端智能(将AI应用落地到硬件终端上)已经成为大势所趋,无论是英伟达的通用GPU,还是谷歌TPU、华为970、苹果A11等一系列定制化板卡,都是让AI在硬件终端开始由软到硬地落地的表现,是人工智能进一步产业化落地的典型代表。
每日一头条
趋势·深度·犀利·干货,最专业的行业解读
深喉爆料、投稿:guoren@zhidx.com

