








智东西(公众号:zhidxcom)
文 | 司北
3月15日,由智东西主办,AWE和极果联合主办的AI芯片创新峰会,在上海成功举办!本次峰会报名参会的观众覆盖了近4500家企业,到会观众极为专业,其中总监以上级别占比超过62%,现场实际到会人数超过1800位。
大会现场,20位人工智能及AI芯片业界翘楚共聚一堂,系统的探讨了AI芯片在架构创新、生态构建、场景落地等方面的技术前景和产业趋势。

▲探境科技创始人兼CEO鲁勇
凭借其创新的存储优先架构(SFA),探境科技去年完成A轮上亿元融资,是中国新崛起的AI芯片新生力量之一。大会现场,探境科技创始人兼CEO鲁勇进行了主题为《基于存储优先架构的AI芯片使能前端智能》的演讲。
由于AI神经网络数据量较大,具有高并发、高耦合等特性,引发了AI芯片高带宽存取、以及数据间的相关耦合性等问题,所以在冯诺伊曼架构之下,目前AI芯片普遍面临了“存储墙”问题——AI计算资源丰富,但存储及数据搬运效率低下。
鲁勇认为,本质上AI计算的核心问题是“如何更高效地将数据输送给计算单位”,而并不是如何增加更多AI计算资源。
因此,去年探境发布了存储优先架构(Storage First Architecture,简称SFA),这是一套不同于冯诺伊曼的AI芯片架构,它这套架构从数据层和计算层中间,通过数据航线,进行节点间的数据搬移。
这套架构的本质是图计算,控制器通过知道在动态运行过程中,哪些数据和哪些算子需要有一定的相关性,从而构建更加合理的网络路径。
SFA架构由此带来的优势包括:数据访问量能降低10到100倍、存储子系统的功耗能下降10倍以上、28nm条件下计算资源利用率高达80%、芯片面积极大缩小。
鲁勇还表示,SFA还可以做到通用型的AI芯片,不仅可以支持任意已知的神经网络,等同于GPU的兼容性,还对神经网络的参数、数据类型没有限制,能够支持多种应用场景,可以真正符合商业应用。
附探境科技创始人兼CEO鲁勇演讲实录
鲁勇:大家好!刚才众多演讲者给大家分享了很多AI在各种应用场景的例子,包括从云端的替代GPU作为提高能效比的工具,从云端到终端的延展,终端包括从小到可穿戴,大到安防、自动驾驶等应用场景。所以我在这里就不重复这些应用场景的情况。
最近有很多AI芯片层出不穷地往这个领域在进展,这里有很多机会,目的是能让AI芯片更加强大、更加易用、更加低功耗。今天上午魏老师提到了AI芯片从0.5到2.0的演进,这当中有大量的创新需要做,基于非常基础层的芯片底层架构,我在这里分享一些探境科技在这方面的创新。
去年探境发布了存储优先架构(Storage First Architecture,简称SFA),这一架构有非常高的领先度,由于很多朋友比较关心和关注,我们今天会先简单回顾一下SFA是什么。
先预告一下,下面的内容可能会比较偏硬核一些,会谈到比较深的技术要点。深度学习给芯片设计带来了很大挑战,深度学习的数据量非常大,包括训练好的权重和运行的动态中间数据。
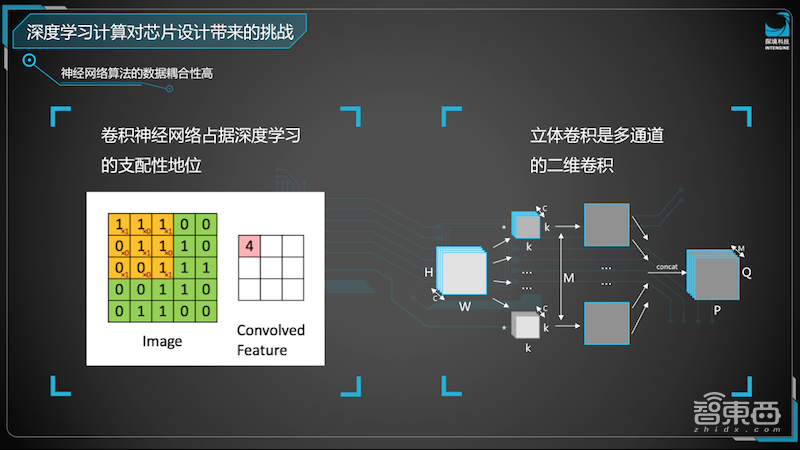
神经网络的运算主要看到的是卷积,左边是单层的卷积,但实际上在神经网络上真正被用到的是右边的立体卷积。立体卷积是多个通道的二维卷积,有非常强的耦合性,其数据的连接关系以及重复的使用给我们带来很大的问题。
通常做卷积运算的第一种方法是直接进行卷积运算,设计一个比较硬核的加速器,这种方式在传统的通信芯片设计里会采用,还有一种方法是采用数学变换的方式,把卷积转化为矩阵,这样可以更加通用地应对不同卷积的尺寸。
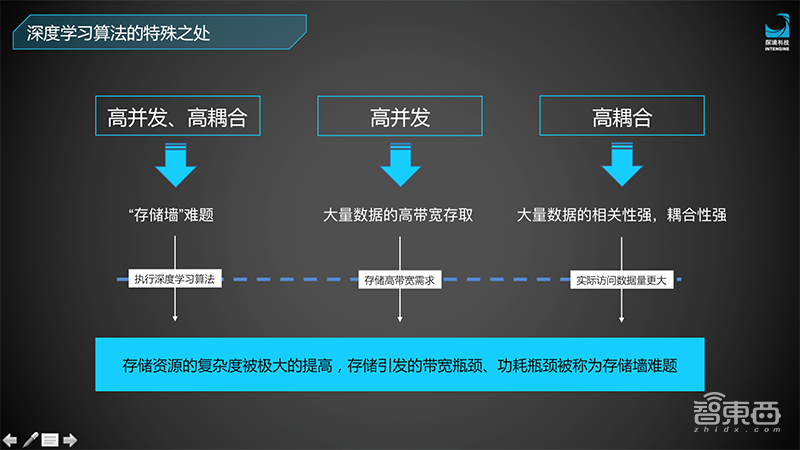
在这几种常见的方法中,我们提到的问题都存在,包括高并发、高耦合,大量的数据引发了高带宽存取、以及数据间的相关耦合性,带来了一个“存储墙”的问题。
在现在的学术界、工业界,“存储墙”都是热点的话题,我们也看到了很多使用试图破解“存储墙”的不同方法。“存储墙”带来的瓶颈是性能跟功耗两方面的。最开始需要通过外存和内存之间交换数据,这一步功耗比较大,第二步是在存储器的数据排序,如何高效地填入到计算单元,这是第二个非常重要的难点。
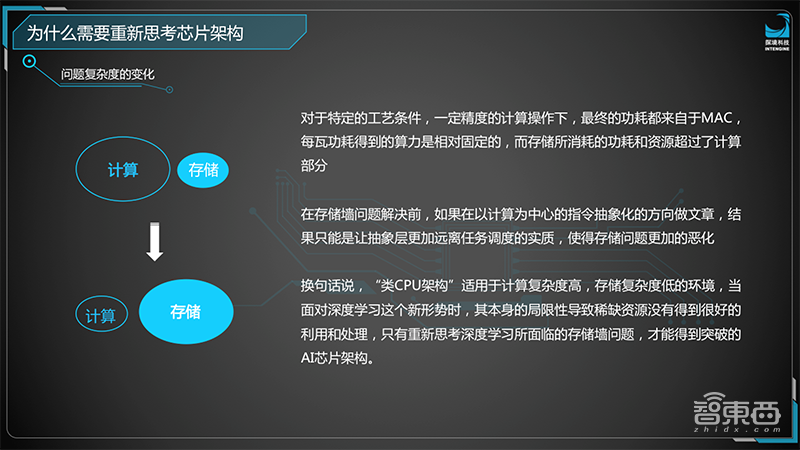
这个问题我们可以简化抽象成用EU是计算单元,Memory是所有的存储。本质上AI计算的核心问题是“如何更高效地将数据输送给计算单位”,而计算并不重要。
我们看到之前很多的解决方案在计算上做了很多文章,包括把计算单位EU升级,从小规模的计算,比如将乘法器升级到更高规格的卷积、三维卷积、矩阵等方式。这种方式并不真正地破解瓶颈,瓶颈是在数据供给方面。

这里有几个具体的困难大家可以探讨一下:
1、数据量大,带宽要求高,数据是不能完全存在片内的,存在片外会有DDR不仅会有功耗问题,我们做SoC的知道,DDR带宽一向是大家争夺的重点,所以系统瓶颈会产生。
2、数据耦合性比较高,很大程度上数据是重复使用的,重复使用的数据会进一步加大功耗。
3、其实更大的困难是第三点,数据的使用复杂度很高,很多朋友在设计AI芯片的时候,数据的排序从不同的网络层之间切换的是非常困难的。
我们总结一下现在常见解决方式:
1、增加计算资源。刚才提到了,这一方法只能增加计算的效率,但是没有办法破解“存储墙”。
2、通过软件的方式编辑数据,让数据的存储方式利于硬件直接调取。但是这种方法对于中间的动态数据流是无法应对的。
3、通过硬件整合更大规模的算子。这一方法有些困难,刚才讲到神经网络有很多不同的配置,这些配置对神经网络很难做到全部兼容。
4、在计算资源内部放入少量的存储资源。但是存储资源仍然有瓶颈,少量的存储资源放不了太多的数据。
5、还有现在比较火的一种方式是把计算资源放到存储器内部,一般叫“存算一体化”,这当中也有很多问题没有被解决,首先它需要非常大的片上存储,只有大量的片上存储才能够把整个神经网络模型都放进去;第二基本上做存算一体的大部分都还是针对全联接层构成的DNN或feature map非常小的卷积层进行设计,对这些比较复杂的卷积神经网络是否能够支持,也是要打问号的。
6、还有一种方法是在算法上设计低精度的网络,降低对存储的需求。这种方式看上去是解决了一定问题,但也有场景受限的情况。
总结一下,如果主要关注在计算方面,即使芯片提高了再大的并行度,它对AI计算的效能提升也是有限的。这种架构我们称之为“类CPU架构,或者“冯诺伊曼架构”。这种架构是由计算驱动存储。因为这种计算资源在神经网络上是比较富余的,用富余的资源驱动稀缺的存储资源,显然没有办法带来很好的收益。
探境科技重新思考了存储和计算的关系,以存储来驱动计算,做了一套完全不同于冯诺伊曼的架构。
这套架构从数据层和计算层中间,通过数据航线,数据作为节点和计算节点,这个过程是一个数据搬移的过程,因为我们可以认为所有的数据都有自己的生命周期,它在生命周期里可能会和其他数据发生相应关系,我们以数据作为优先可以考虑到数据带动算子,而非由算子找数据的关系。
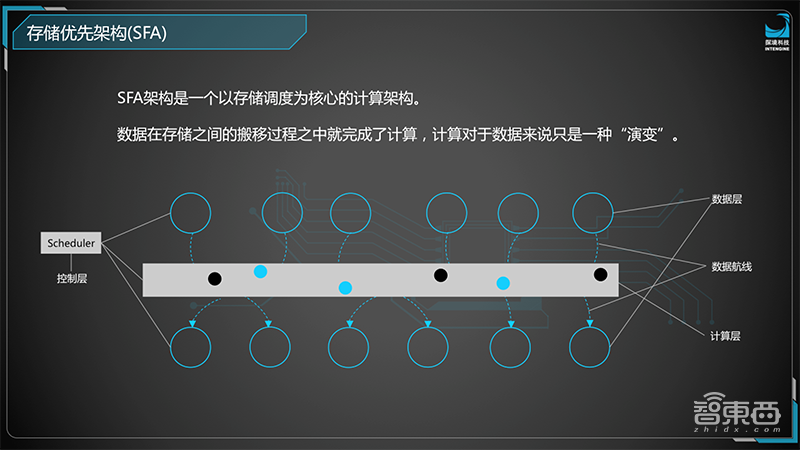
这套关系是由Scheduler控制器来控制的,这样一个CPU可以知道在动态运行过程中哪些数据和哪些算子需要有一定的相关性,从而构建出一张相对比较合理的网络。
所以这里本质上来讲深度学习的计算是图计算,这个方向上我们对此有很高的认知。
举个例子,像曾经大家做通信算法的时候都会做到傅里叶变换,做时域和频域的变化,很多问题在时域里无法解决的时候,你走到频域里就迎刃而解。所以神经网络的本质问题是图计算问题,当你走到图计算的高度的时候,很多问题会迎刃而解。
SFA能带来什么好处呢?首先数据访问量能降低10到100倍,所以存储子系统的功耗能下降10倍以上;在28nm条件下,系统能效比超过4 TOPS/W,计算资源利用率也很高,超过80%,我们可以看到现在公开的很多AI架构芯片资源利用率都只在50%上下浮动。另外SFA面积非常小,在28nm工艺条件下的Post Layout面积是每TOPS 0.5平方毫米。
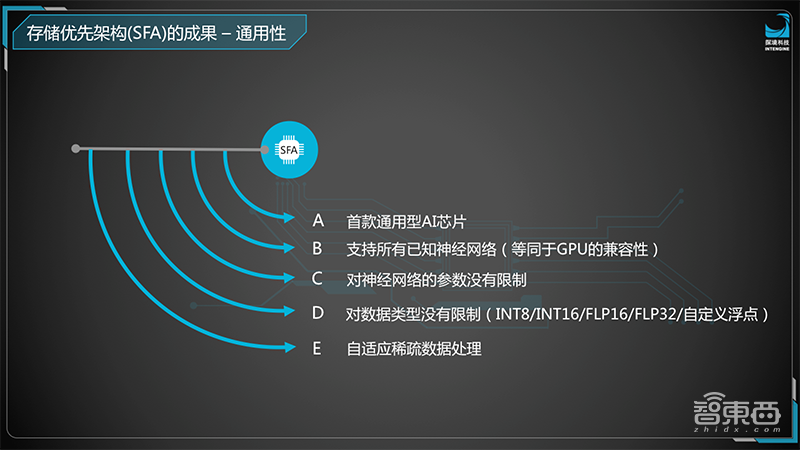
同时,SFA可以做到通用型的AI芯片,可以支持任意已知的神经网络,等同于GPU的兼容性。很多设计芯片的朋友都知道,想要做一款通用型的AI芯片非常非常困难,有的只能支持几个神经网络,有的会在神经网络的参数上有非常大的限制,只能支持一些,有些可能就不支持了。
SFA对所有的神经网络参数、架构没有任何限制,对数据类型也任何限制,包括INT8、INT16、浮点16、浮点32、甚至包括一些自定义的浮点,全都可以支持;并且对于深度学习里所讲到的稀疏化的数据,也是可以自适应去支持,不用事先做任何的预处理。我们知道通用型对芯片设计是非常重要的,因为我们做芯片设计的人通常所面临的场景是非常广泛的,只为一个场景做一个具体的芯片可能成本就太高了。
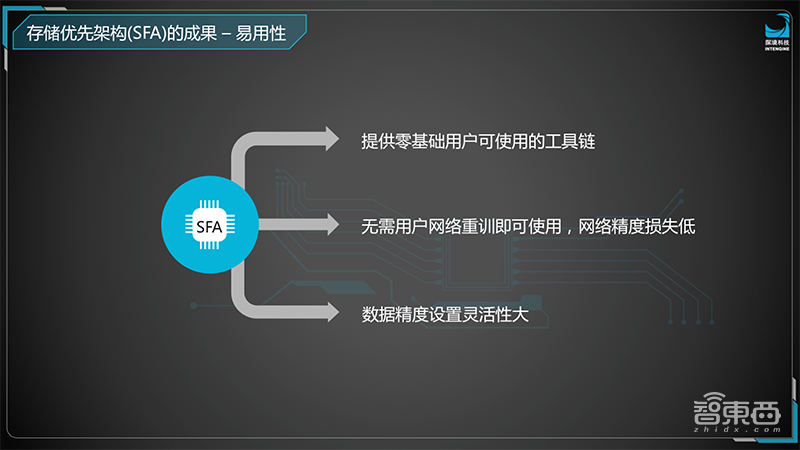
SFA的易用性也非常高,工具链使用很简单,对用户来说网络不需要重新训练,这也是真正用户使用上的头疼问题,需要拿着网络重新训练,但是SFA的网络可以直接拿来使用不用训练,数据的精度设置灵活度非常大,甚至可以做到每层做自己的定义数据精度。
因此,有这样的一些优点,所以可以考虑做出当前没有实现的功能,我们既可以做一些训练,也可以做推理,终端能看到更多的是推理的芯片,SFA也可以做云端的训练和推理,无缝衔接,更重要的事情是在终端可以做到终端推理和终端的一些本地训练。
最近大家对隐私的要求也越来越高,很多用户本地所拍摄的图像是不太愿意上传到云端,但他又希望能够在自己不断地使用过程中通过自己的训练能够让自己的模型变的更加精确、更加适合场景。这样的话需要一些本地训练,或者是需要一些协同性的训练,和其他用户一同训练更好的模型,采用这样的架构功能就可以完成。
我们认为这是真正可以符合商业应用的AI芯片,其他大量的AI芯片会有局限性于固定场景的使用。
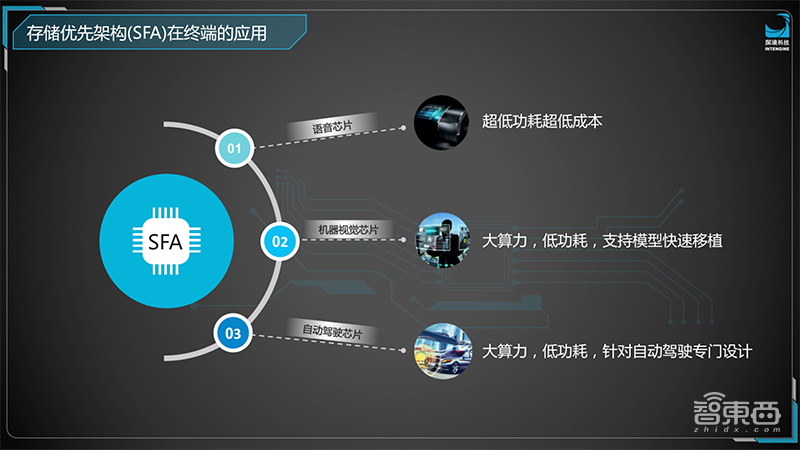
基于SFA对所有终端的应用场景都可以支持,语音芯片、机器视觉芯片、自动驾驶芯片等,这些场景的核心点都在于AI计算,如果AI计算能够超出现有的水平达到更高的能效比、更好的成本控制,在半导体方向上创新永远是推动行业发展的原动力,并且能够带来源源不断的提升。有这样的SFA的架构应该能够给所有终端芯片都有新的收获,包括从成本上、功能上、易用性上,都会有新的创新。
谢谢大家!
