










智东西(公众号:zhidxcom)
整理|智小西
今年5月,在加州圣何塞举办的 2017 GPU技术大会(GTC 2017)上,英伟达 CEO 黄仁勋发布了使用最新一代架构Volta的NVIDIA Tesla V100,被业界称为“宇宙最快”GPU加速器。
12月21日晚8点,智东西策划的英伟达公开课第二期开课,主讲导师NVIDIA中国高级解决方案架构师吴磊就主题《如何为深度学习和HPC提供更高算力—Telsa V100 深度讲解》,对Volta架构的最新特性、GV100的V架构、专为深度学习设计的Tensor Core以及Volta如何加入深度学习英语进行了深度讲解。同时,NVIDIA中国首席解决方案架构师罗华平与吴磊一起参与了本期公开课的Q&A环节的交流。
课程提纲如下:
-Volta架构最新特性;
-Volta架构深度解析;
-Volta加速HPC应用;
-Volta加速Deep Learning应用;
-Volta家族产品;
如果你需要本期英伟达公开课的标准课件和完整音频,可以通过这个地址下载:https://pan.baidu.com/s/1hslIP3Q(密码: i6mu);如果你需要试用NVIDIA Tesla V100,可以通过这个地址免费申请:https://www.marketingneat.com/registration-form/v100cmpreg?s=zhidxgkk
我们摘选了讲师吴磊在讲课中的部分重要内容,供你快速了解和掌握:
-不同于基于上一代Pascal架构的产品多样化(有P100,P40和P4),这一代基于Volta架构的Tesla产品只推出了Tesla V100这一款——我们称为universial(通用)的GPU,可以同时实现HPC、AI 训练(Training)和推理(Inference)的加速、以及虚拟化功能。相比上一代,Volta产品在各个应用领域的加速性能都有所提升,尤其是在AI Training和AI Inference上的应用,得益于新增加的张量计算单元,平均的加速比可以达到3倍。
-Tensor Core是Volta架构最重磅特性,是专门针对Deep Learning应用而设计的专用ASIC单元,实际上是一种矩阵乘累加的计算单元。(矩阵乘累加计算在Deep Learning网络层算法中,比如卷积层、全连接层等是最重要、最耗时的一部分。)Tensor Core可以在一个时钟周期内实现两个4×4矩阵乘法以及与另一个4×4矩阵加法。整个计算的个数,就是在一个时钟周期内可以实现64次乘和64次加。
-利用Tensor Core实现矩阵乘法的加速的两种方式:1、在CUDA编程里实现Tensor Core的调用。新的CUDA 9.0里增加了WMMA,可以调用其中的API实现输入矩阵的Load,两个矩阵做乘加,还有结构矩阵的Store;2、可以利用现成库函数,最新版本的cuDNN 7.0、CUDA9.0中的cuBLAs,TensorRT 3.0都支持Tensor Core的调用。这个方式相对比较简单。
-目前Tensor Core可以支持的深度学习框架有Caffe、Caffe2、MXNet、PyTorch、Theano、TensorFlow等,但不支持CNTK、Chainer、Torch;
-在底层实现上,NVIDIA提供了大量SDK去支持上层应用或者框架,来最简化、最高效地帮助用户实现GPU加速Deep Learning的训练或推理的过程。这些SDK包括在Training(训练)端的SDK,如标准线性代数库cuBLAS、深度学习算法库cuDNN(最新版本7.0)、多GPU的集合通信库NCCL(最新版本2.0)、基于WEB UI交互式的深度学习训练系统DIGITS(最新版本6.0),以及Inference(推理)端SDK,如推理加速引擎Tensor RT(最新版本3.0)、智能视频分析工具DeepStream。
-全球3组现在或者今后会大规模部署Tesla V100 GPU的数据中心:1、美国橡树岭国家实验室的Summit超级计算机,将在明年完成超过3400台Tesla V100 GPU服务器的搭建;2、日本国家先进工业科学和技术研究所(AIST)将在其数据中心部署4352颗Tesla V100 GPU;3、NVIDIA超级计算器SARURNV。SARURNV将在原有的基础上进行升级改造。去年,SARURNV由124台DGX-1服务器搭建而成,每台DGX-1的服务器搭载了8颗Tesla P100 GPU,这台超级计算机曾经在世界Top500绿能计算机中排名第一。在升级之后,SARURNV将会由660台DGX-1V服务器组成,每台DGX-1V服务器会由8颗Tesla V100 GPU组成。
– Tesla V100有NVLink和PCIe两个版本,但计算核心都是GV100,都有5120个CUDA Cores以及640个Tensor Cores,不同点在于主频和功耗。NVLink版本主频更高,双精度浮点计算能力可以达到7.8个TFLOPS,单精度浮点计算能力可以达到15.7个TFLOPS,而混合精度计算能力可以达到125个TFLOPS。PCIe版本对应指标分别是7个TFLOPS、14个TFLOPS和112个TFLOPS。两个版本在计算性能上并无差异,主要取决于用户实际需求。如果需要在GPU之间频繁进行数据交换,那么PCIe的传输带宽可能会成为瓶颈;如果使用NVLink版本就能达到比较好的效果,否则PCIe版本的Tesla V100是更通用的选择;
-全世界越来越多的超算中心开始使用GPU计算集群代替原有的CPU计算集群,主要是因为GPU的核心价值是可以为客户大幅度的节省资金。相比CPU计算集群,GPU计算集群会把绝大部分的成本花费在购买计算力上,而CPU的集群有很多的成本花费在建设基础设施、网络、机柜等花销上。
主讲实录
吴磊:大家好。我是NVIDIA高级解决方案架构师吴磊。今天我将为大家带来NVIDIA最新推出的Tesla V100 GPU的深度讲解。今天的课程将首先介绍Volta的最新特性,然后会深度解析Volta架构,接着我会带大家了解一下Volta 加速HPC和Deep Learning的应用,最后为大家介绍Volta产品家族中的一些产品。
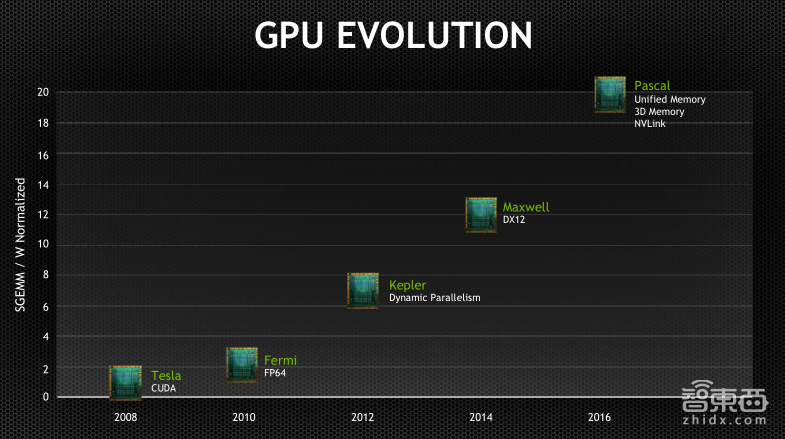
熟悉GPU发展历程的朋友可能知道,从2006年NVIDIA发明CUDA到现在,我们推出了一系列支持加速计算的产品,每代产品都以著名物理学家的名字来命名,从Tesla到Fermi、Kepler、Maxwell、Pascal,再到今年最新推出的Volta。相比于上一代,每一代新产品在计算能力上都会有显着提升。今年5月在美国举办的一年一度的GPU技术大会上,NVIDIA宣布了新一代GPU——Volta的诞生。不同于基于上一代Pascal架构的产品的多样化(有P100,P40和P4),这一代基于Volta架构的Tesla产品只推出了一款Tesla V100——我们称为universial(通用)的GPU,可以同时实现HPC、AI 训练(Training)和推理(Inference)的加速,以及虚拟化的功能。

从上面的四幅图片可以看出,相比于上一代,Volta的产品在各个应用领域的加速性能都有所提升,尤其是在AI Training和AI Inference上的应用,得益于新增加的张量计算单元,平均的加速比可以达到3倍。
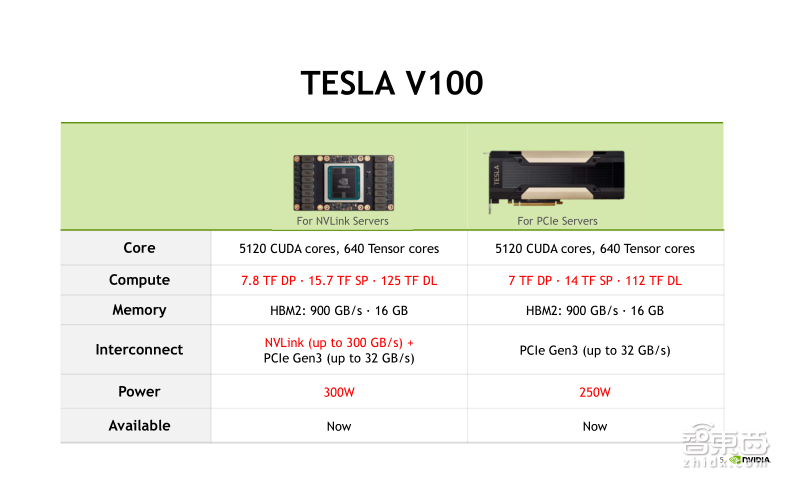
Tesla V100目前有两款产品供大家选择,左侧的为NVLink版本,右侧为PCIe版本。但是实际上这两款产品的计算核心是相同的,都叫做GV100,他们都有5120个CUDA Cores以及640个Tensor Cores。我们在后面会对Tensor Core进行详细讲解。二者的不同点在于主频和功耗。主频更高的Tesla V100 NVLink版本,双精度浮点计算能力可以达到7.8个TFLOPS(每秒万亿次浮点运算),单精度的浮点计算能力可以达到15.7个TFLOPS,而混合精度计算能力可以达到125个TFLOPS。PCIe版本对应的指标分别是7个TFLOPS,14个TFLOPS和112个TFLOPS。

从这幅图上可以看到,Tesla V100 GPU具有五大特性:
1、Tesla V100采用了最新的12nm工艺设计。这使得在原有芯片面积上能部署更多的晶体管单元,进而显著增加GPU芯片内部计算单元的个数,进一步提升芯片的节能性。
2、改进了Tesla V100的IO性能。我们知道,异构计算中GPU的计算能力提升是很快的,尤其在近几年的时间里,而瓶颈往往会出现在存储IO或者总线IO上。在这里,我们采用了最新的NVLink2.0技术,有效地提升了CPU与GPU或者GPU与GPU之间传输带宽,并采用了最新的HBM2技术,进一步提升了显存的带宽和利用率。
3、采用了新的MPS多进程技术。MPS技术可以允许多个CPU的进程,同时发射CUDA任务到GPU中去执行,这可以显著提升GPU的利用率和吞吐能力。Tesla V100采用了新的基于硬件加速的MPS技术,进一步优化任务加载的延迟,同时容纳更多的客户数量。
4、我们采用了全新的SIMT编程模型,每个线程可以拥有独立的存取计数和堆栈,使得线程间同步通信可以更加灵活,也可以去适应更复杂的算法逻辑。
5、我们针对深度学习中的Training(训练)和Inference(推理)大量的矩阵运算,专门设计了Tensor Core单元,这一点是整个设计中最重磅的一点。
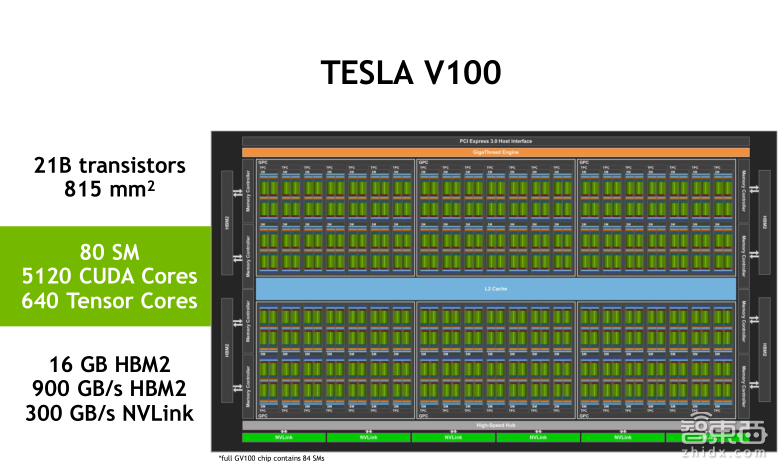
上面是Tesla V100的框图。Tesla V100的芯片面积有815平方毫米,一共有210亿颗晶体管,搭载了84个SM(流多处理器)单元,其中有效单元是80个。每个SM单元中有64个单精度的处理单元CUDA Core以及8个混合精度的矩阵运算单元Tensor Core,总共有5120个CUDA Core和640个Tensor Core。还有16GB的HBM 2的显存,带宽可以高达900GB/s,并且支持300GB/s双向带宽的NVLink2.0的主线协议。
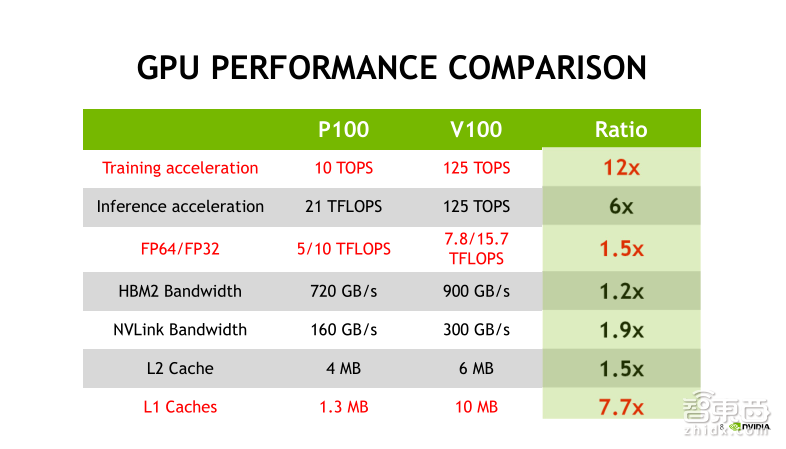
接下来我们看一下Tesla V100与Tesla P100的性能比较。首先看第一行,Tesla P100有10个TFLOPS的单精度浮点计算能力和21个TFLOPS半精度浮点计算能力,而基于Tensor Core ,Tesla V100有125 个TFLOPS的混合精度计算能力。对比之下,V100分别提升了12倍和6倍;再看第三行,相比于Tesla P100,Tesla V100在双精度和单精度浮点计算性能上都有了50%的性能提升;最后一行是L1 Caches,Tesla V100在容量上有了显著的提升,对于全局存储访问比较密集,并且数据局部性比较好的程序,能够显著提升程序的执行速度。
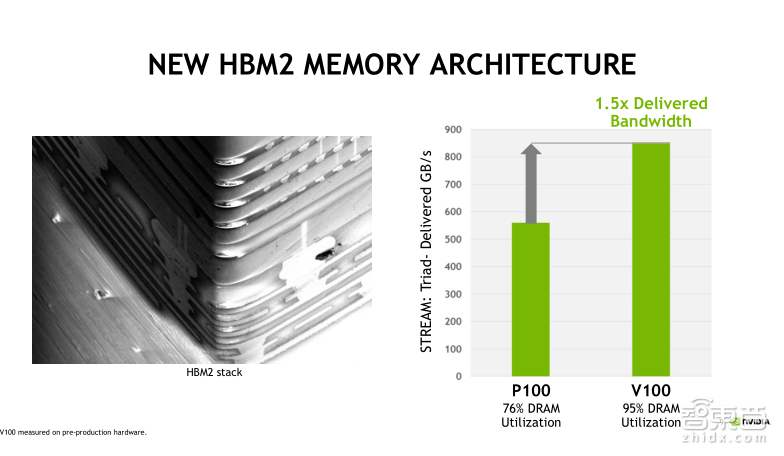
实际上,HBM2技术在上一代的 GP100就已经开始使用了。它是一种堆栈式的存储技术,共有4096位的主线位宽,这使得存储器可以在较低的主频下实现较高的带宽。而Tesla V100采用的是更新的HBM2技术,在位宽不变的情况下,主要是提升了Memory Clock的时钟以及DRAM的利用率。这使得Tesla V100的HBM2的实际显存带宽比Tesla P100提升50%左右,最高可以达到900GB/s。
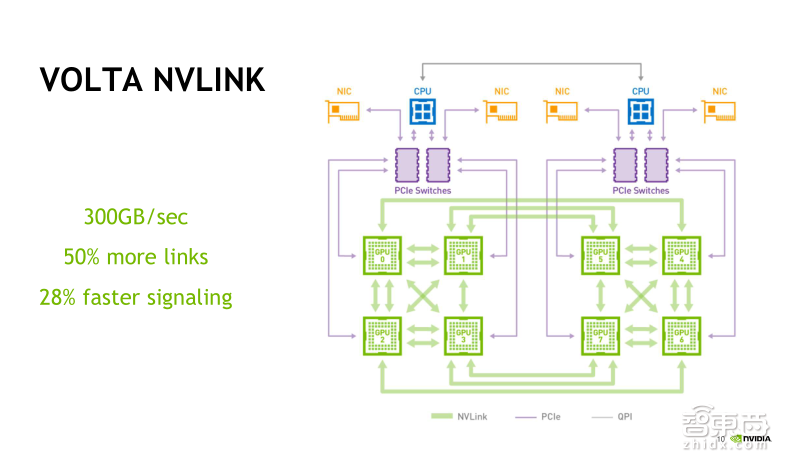
Tesla V100的NVLink版本支持NVLink2.0高速互联总线协议。Tesla P100是支持当时的NVLink1.0协议,每颗GPU可以连接4根总线,每根总线的单向传输带宽可以达到20GB/s,四根总线可以实现单向80GB/s、双向160GB/s的IO带宽。而在Tesla V100中,我们支持最新的NVLink2.0协议,每颗GPU最多可以实现六根总线互联,每根总线的单向传输带宽可以达到25GB/s,六根总线可以实现单向150GB/s、双向300GB/s的IO带宽,相比NVLink1.0,带宽几乎提升了1倍。

下面我们一起来了解下Tesla V100在可编程性方面新增的一些特性。

首先讲一下Unified Memory(统一内存寻址)。在编写CUDA程序的时候,我们需要在CPU端和GPU端分别定义不同的内存空间,用于存储输入或输出的数据。简单来说,Unified Memory的概念就是定义一个内存指针,既可以从CPU端去访问,也可以从GPU端去访问。Unified Memory经历了一个比较长的发展历史,2010年CUDA4率先推出了统一虚拟地址——UV的概念,当时我们叫做零复制内存,GPU代码可以通过PCIE总线访问固定的CPU内存,无需进行Memory Copy。
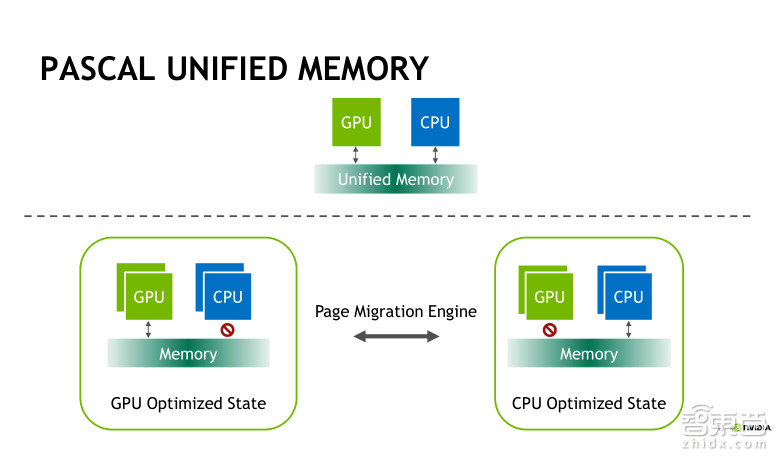
在CUDA6中推出了统一内存池的概念。内存池可以在CPU与GPU之间进行共享,而CPU和GPU均可以利用单一的指针来访问管理内存。但是,当时受限于Kepler和Maxwell架构,CPU涉及的所有管理内存必须是在Kernel函数启动之前先要与GPU同步,CPU和GPU是无法同时访问管理内存分配空间的,而且统一的地址空间也要受限于GPU物理内存的大小。
在Pascal架构之后,我们增加了大型地址空间的支持,可以支持49位的虚拟地址空间以及页错误,这是我们在Pascal架构下新增的两大特性。其中,页错误指的是GPU上代码所访问的页没有常驻GPU内存,这页就会出错,支持页错误可以让该页按需页迁移GPU内存或者映射到GPU地址空间,以便通过PCIE或者NVLink互联来进行访问,实现按需进行页迁移的操作。
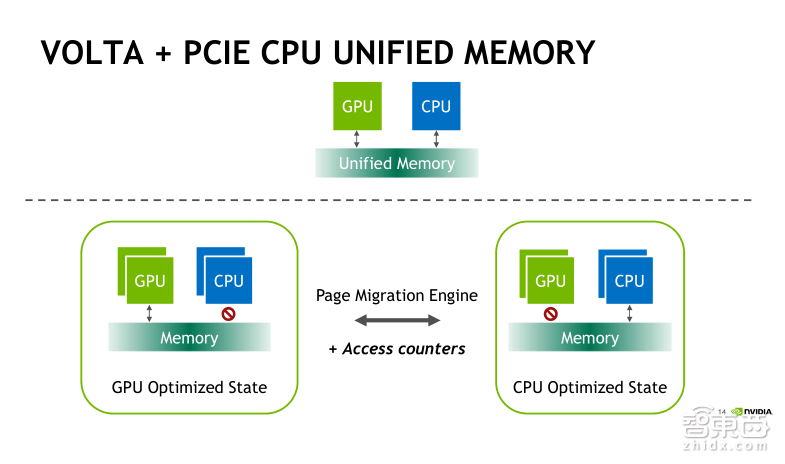
新一代Volta架构是在Pascal的基础上新增加了Access Counters(存取计数器)功能,它可以使得页迁移控制更加精细、合理。
Pascal架构下的页迁移就如前一张图片所示。它会根据GPU或者CPU上被访问地址所在页的位置,比如logo的访问或者remote的访问,按需发起页迁移操作,这时候CPU或者GPU访问统一内存不是直接访问方式,而是通过页迁移来实现的。
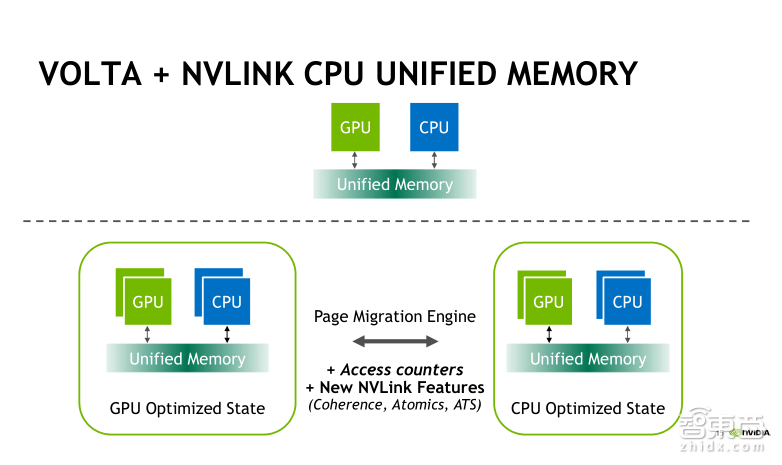
在Volta架构下面,我们新增了Access Counters的存取计数器这一特性。我们会对内存访问的频繁程度进行计数,只会对访问频繁的内存进行迁移,从而进一步提升内存访问的效率。另外,基于NVLink连接的统一内存管理,它支持对CPU与GPU的内存进行直接访问和cache(高速缓冲存储器),但是目前支持这项功能的CPU实际上指的就是IBM的Power。同时,它支持CPU与GPU之间的原子操作,以及地址转换服务(ATS)功能,可以实现GPU访问CPU的分页表,为GPU提供了对CPU内存的完整访问权限。
接下来我们来了解一下多进程服务——MPS。从Kepler的GP10架构开始,我们就引入了MPS(基于软件的多进程服务),这种技术在当时实际上是称为HyperQ ,允许多个 流(stream)或者CPU的进程同时向GPU发射Kernel函数,结合为一个单一应用程序的上下文在GPU上运行,从而实现更好的GPU利用率。在单个进程的任务处理,对GPU利用率不高的情况下是非常有用的。实际上,在Pascal架构出现之后的MPS可以认为是HyperQ的一种实现方式。
现在在Volta架构下面,我们又将MPS服务进行了基于硬件的优化。MPS有哪些好处呢?首先可以增加GPU的利用率;其次可以减少多个CUDA进程在GPU上的上下文空间。该空间主要是用于存储和调度资源;最后可以减少GPU的上下文的切换。但MPS实际上也是有一些使用限制的,比方它现在仅支持Linux操作系统,还要求GPU的运算能力必须大于3.5。
下面用一个例子来比较使用MPS和不使用MPS有什么不同。
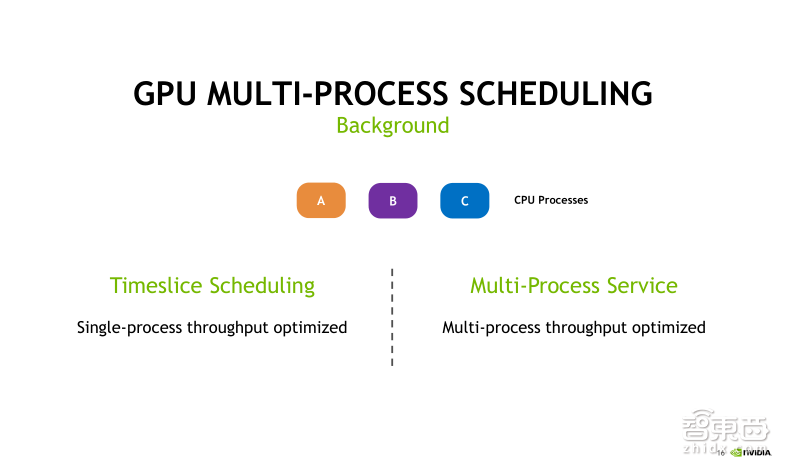
假设在CPU端有A、B、C三个进程,每个进程都要发射CUDA Kernel的任务到GPU上去,并且假设它们每一个独立的任务对GPU利用率都不高。
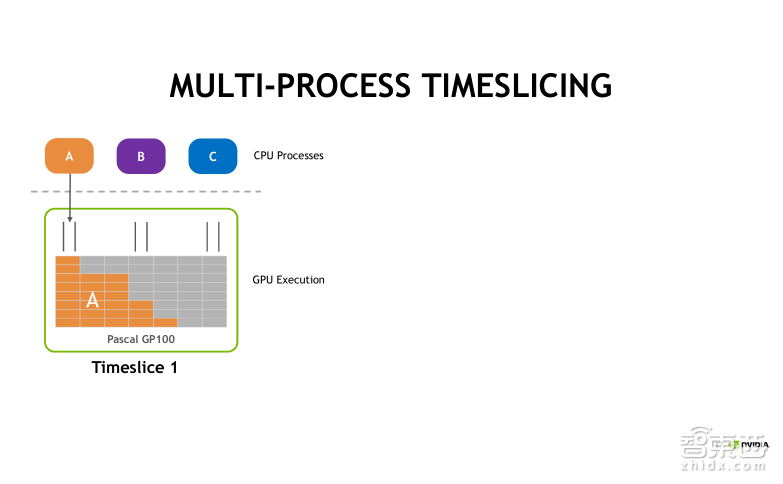
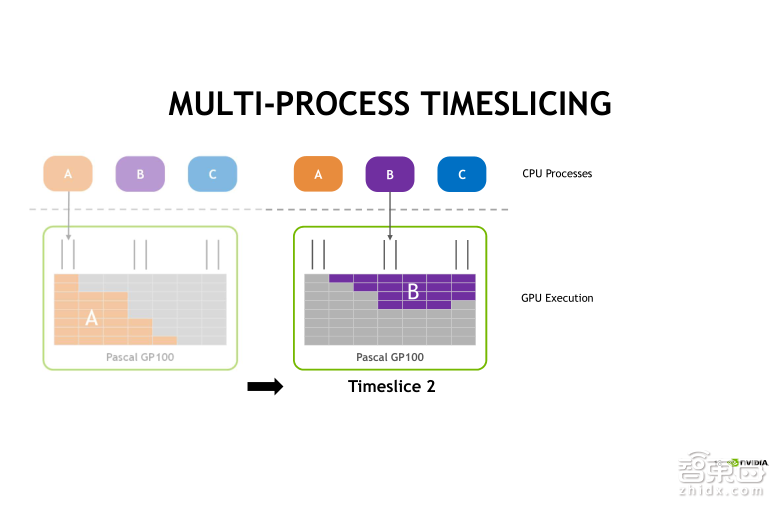
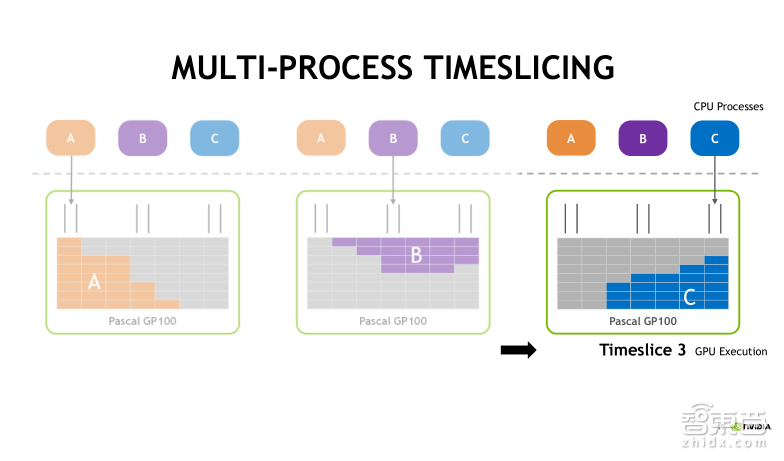
在不使用MPS服务的情况下,A、B、C三个进程实际上也可以同时把CUDA任务发射到GPU上去,但是默认采用时间片轮转调度的方式。首先第一个时间片,A任务被执行,接着第二个时间片,执行B任务,第三个时间片, C任务将被执行。时间片是依次进行轮转调度的,分别执行A、B、C中的任务。
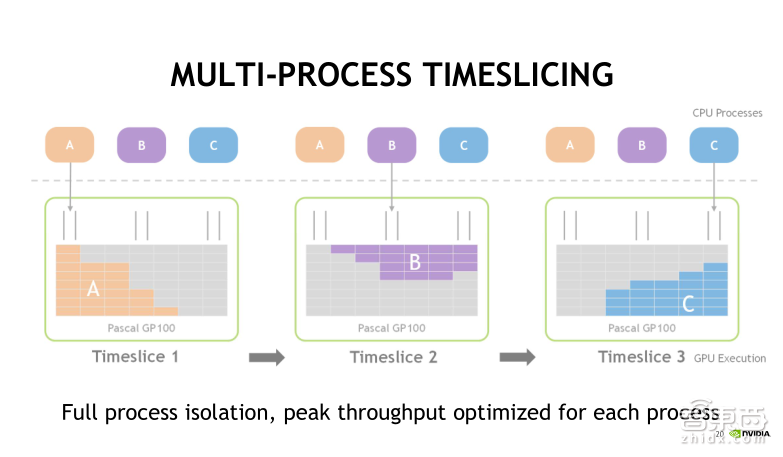
此时我们可以直观地看到, 在GPU中,每一个时刻只有一个任务在执行。这种情况下,CPU中的process(进程)发射的CUDA任务对GPU的利用率是很低的!
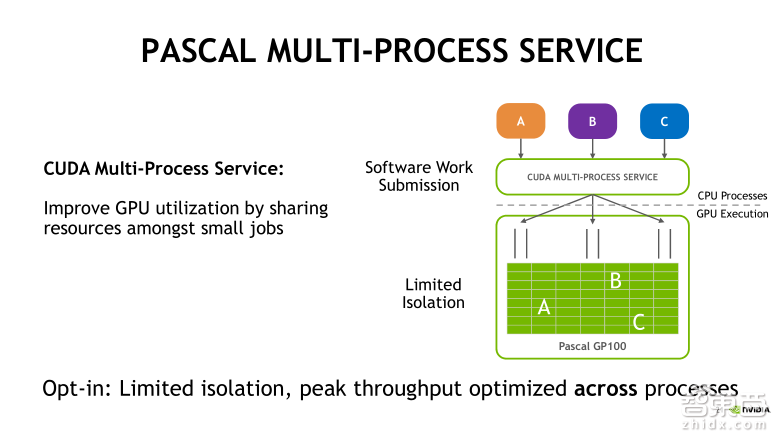
接下来看一下基于Pascal架构的MPS服务对任务的处理情况。从右侧的框图可以看到A、B、C三个进程分别提交各自的任务到MPS的服务端,并在服务端整合为一个统一的上下文,并将三个任务同时发射到GPU中执行,这就有效地提升了GPU的利用率。在Pascal架构下,MPS是最多可以支持16个进程或者说16个用户同时去提交任务的。
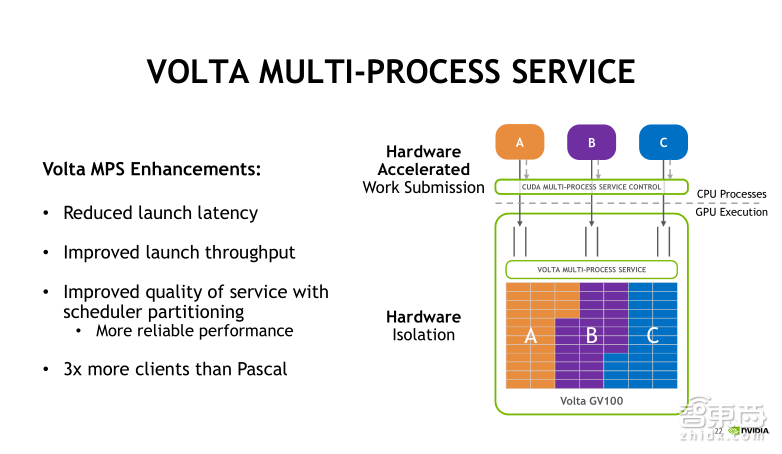
Volta架构对MPS的实现做了进一步的改进,主要是基于硬件加速的方式来实现。此时不同的进程是可以直接穿过MPS服务器,提交任务到GPU的硬件,并且每个进程客户端有隔离的地址空间,这样可以进一步减少Launch(发射进程)时带来的延迟,也可以通过限制执行资源配置来提升服务质量。这里所说提升服务质量是指怎么样平衡多个process(进程)发射任务对计算和存储资源的占用情况。比如我们现在可以去设定每一个process上下文,最多可以使用多少个资源。Volta下的MPS服务最多可以允许同时48个Client(客户端)。
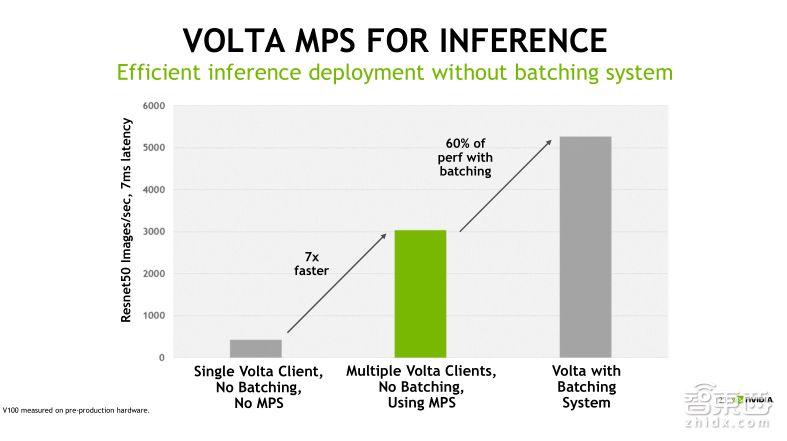
我们用一个benchmark(基准)来进行比较,进而了解MPS技术到底能带来哪些好处。我们知道,对于单个任务占用GPU资源比较少的情形,MPS服务是非常有用的,比如在深度学习中做Inference(推理)应用。相比Training(训练),Inference对于计算和存储资源的要求比较小,这个时候会出现我们之前看到的情况,单一的Kernel任务是没法有效利用GPU的。从上面的benchmark可以看到图中最左侧灰色的柱状图,在不使用MPS的情况下,Inference的吞吐性能很小;而中间绿色的柱状图,使用MPS允许多个Client同时发射计算任务到GPU,此时GPU吞吐性能直接提升了七倍;最后一个柱状图表示,如果我们使用MPS,并结合Batching操作,吞吐性能还能继续再提升60%左右。由此可见,对于像Deep Learning的Inference这样的应用,MPS技术是可以有效地帮助我们优化GPU利用率以及程序的吞吐性能。

在上一节里面,我们主要是讲解了Tesla V100的最新特性,包含计算性能和IO性能的提升,还有可编程性中针对Unified Memory和MPS技术的改进。在第二节,我会带着大家一起来深度解析Tesla V100计算核心,我们称之为GV100的V架构的特性。

首先我们看到在GV100中每个流多处理器SM的单精度浮点计算单元个数是64个,双精度浮点计算单元格数是32个,这和上一代Pascal的GP100架构是完全相同的。但是,GV100中增加了INT32以及Tensor Core两种计算单元。这在之前的GPU架构中是没有的。在Volta之前,整型运算主要是由单精度浮点计算单元以及SFU单元来完成的。另外Tensor Core单元是专门为混合精度矩阵乘法而设计的。在后面我们还会详细讲Tensor Core。另外,值得注意的是,L1 cache和 Shared Memory再次被整合到了一起,二者各自的最大分配是96KB。
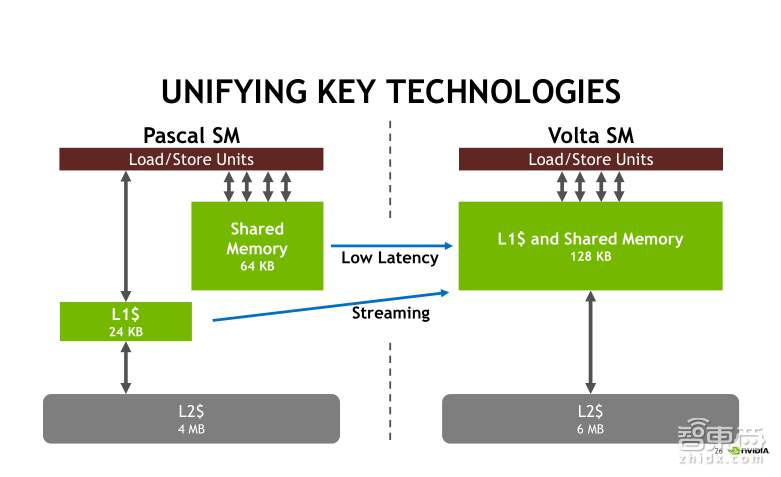
通过两张框图比较一下Pascal架构与Volta架构的L1 cache和Shared Memory有什么不同。首先,在Pascal架构下,L1 Cache值固定是24kb,Shared Memory固定是64kb,而且二者是独立的。并且Shared Memory的带宽比较高,延迟比较小。而在Volta里,我们将二者整合在了一起,可以达到128kb,可以分别配制成32、48或者96三种模式,并且L1 cache和Shared Memory有着相同的带宽和延迟的,这实际上等于极大地提升了L1 cache的大小以及性能。
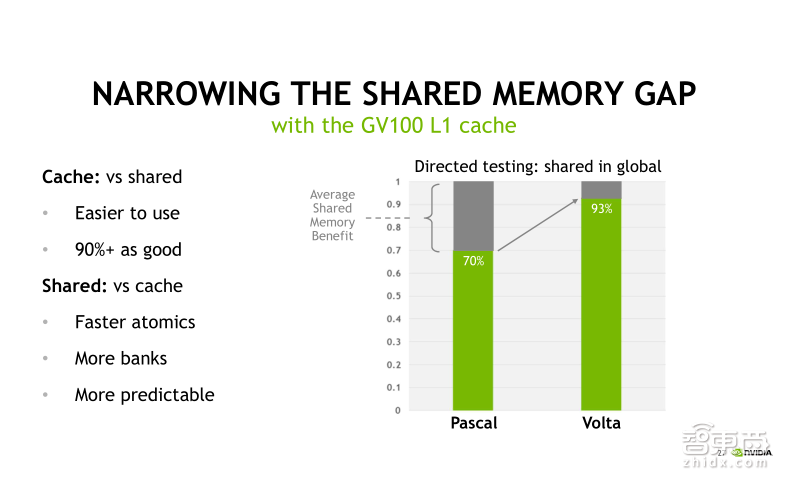
通过这页的benchmark来看一下这样做到底有什么好处。我们知道在CUDA程序里Shared Memory是可以被程序员手动控制的,并且可以利用它对全局内存访问进行优化。而相比之下,L1 cache是不能被直接控制的,也就是说它对程序员来讲是透明的,但是有效地利用合并访问机制仍然可以利用L1 cache,从而极大提升内存访问性能。我们从右侧的柱状图可以看出,在Volta架构下,L1 cache提升全体内存访问的性能已经接近Shared Memory的90%,极大提升了可编程性,使得我们在一些场合可以不用手动地使用Shared Memory进行程序优化也能达到比较好的性能!

接下来我们了解一下在Volta架构下新增加的一个特性——独立线程调度机制。
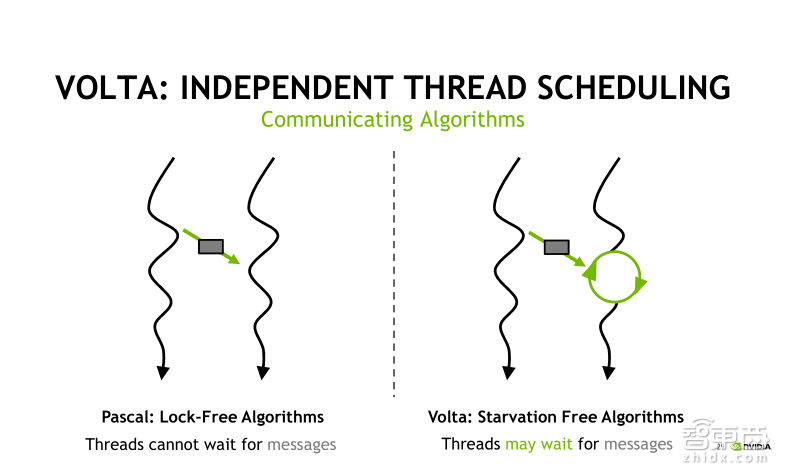
独立线程调度机制可以这样理解,主要是为线程与线程之间的通信和同步提供更加灵活的方式。

GPU中的线程执行实际上是以WARP为基本单元执行的,每个warp包含32个线程,这32个线程拥有共同的程序计数器,叫做Program Counter,还有Stack(堆栈)。无论程序是否出现分支,32个线程在同一个时刻都要执行相同的指令。
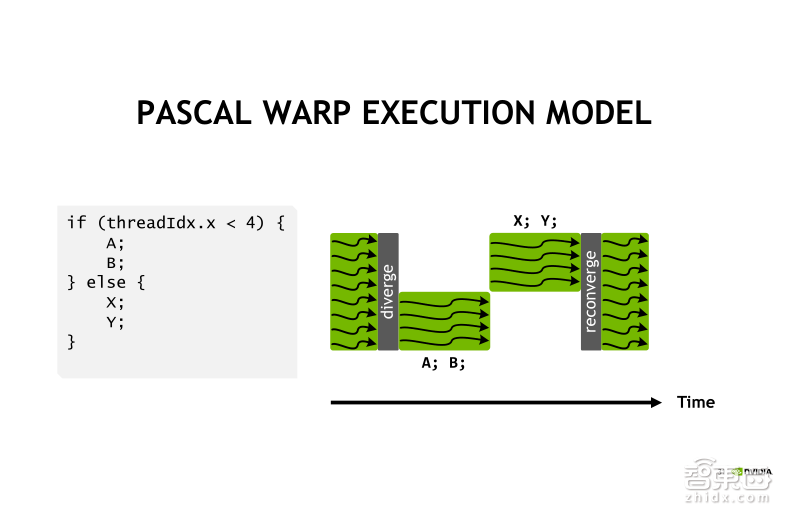
比如上图这样的一段代码,用现成ID号来定义程序的分支。我想让0到3号执行A、B指令,其他线程去执行X、Y指令。执行过程就像右图中所示,首先0到3号线程会去执行A、B指令,但同时其他线程会处于空跑的状态。接下来其他线程去执行X、Y指令,而0到3号线程处于空跑状态。所以说整个指令执行完毕的时间,实际上是A、B、X、Y四个指令的执行时间之和。这就是我们通常讲的,在WARP内出现分支时的执行时间轴。
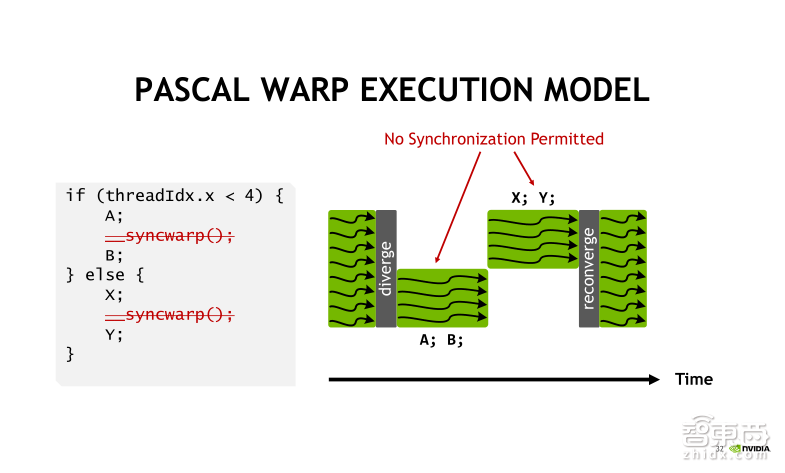
如果我需要在A指令与X指令执行之后,进行一个线程之间的同步通信,例如线程从0到3执行指令B时需要利用指令X的执行结果,而这种算法在Pascal架构下是没有办法实现的。
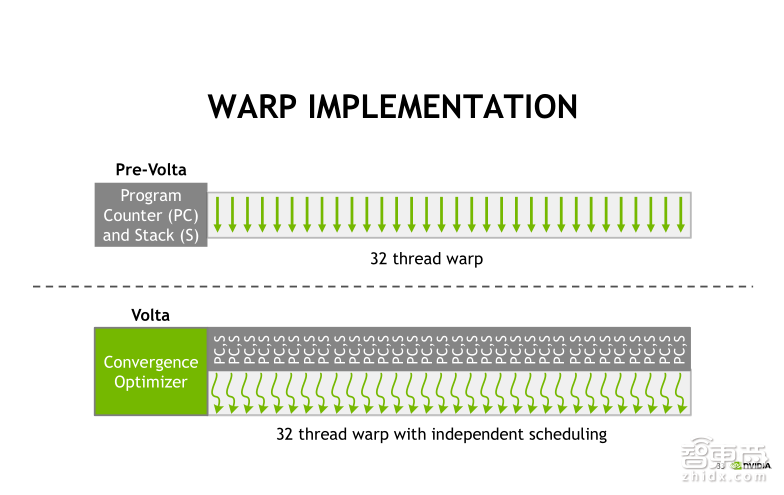
在Volta架构下,我们改变了这种线程调度机制。每一个线程可以有自己独立的程序计数器PC以及堆栈,这使得每个线程可以独立进行线程的调度。
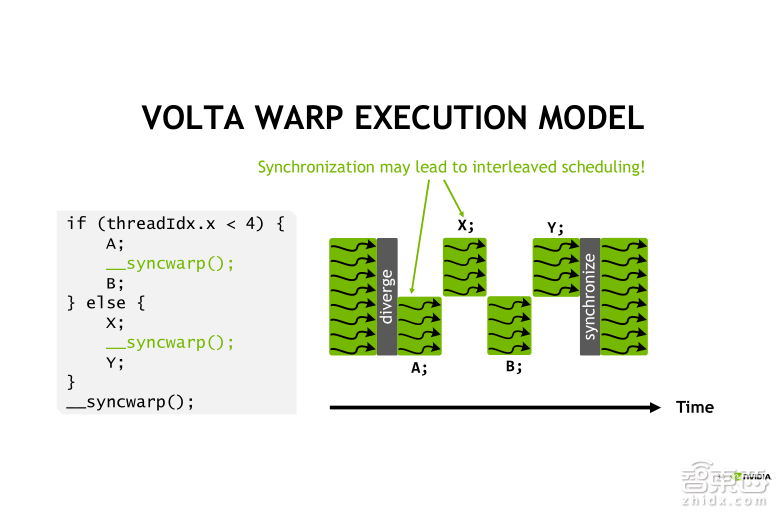
在我们所举的例子里,执行指令B之前需要新同步通信得到A和X的结果。我们可以在A指令和X指令执行之后,进行一个WARP内的同步。我们在CUDA9里面新增加的一个函数——syncwarp,这样就改变了指令的执行顺序。可以看右边的图,此时变成了什么呢?首先线程0到3去执行指令A,然后其他的线程去执行指令X,接下来0到3再去执行指令B,最后是其他线程再去执行指令Y。需要注意的是,此时在这个分支的外部,我们还需要再进行显式的syncwarp的线程同步的声明。

接下来的小节里,我会向大家重点介绍Tensor Core,也是Volta架构里面最重磅的特性。

Tensor Core实际上是一种矩阵乘累加的计算单元。矩阵乘累加计算在Deep Learning网络层算法中,比如卷积层、全连接层等是最重要、最耗时的一部分。Tensor Core是专门针对Deep Learning的应用而设计的专用ASIC单元,可以在一个时钟周期内实现两个4×4矩阵的乘法以及与另一个4×4矩阵的加法。整个计算的个数就是我们在一个时钟周期内可以实现64次乘和64次加。
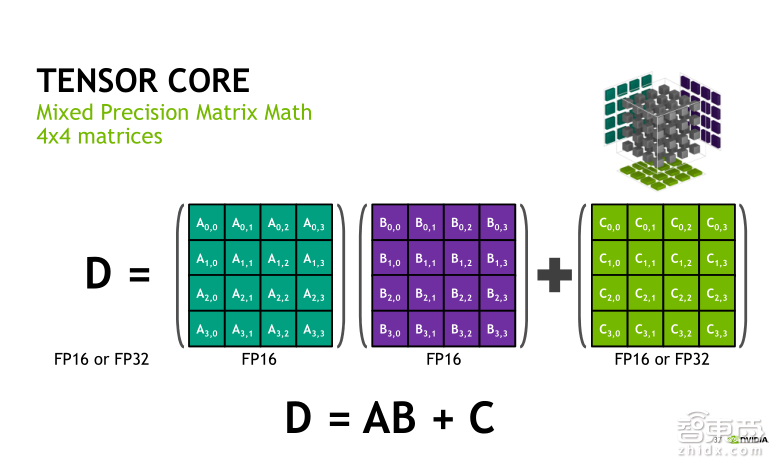
Tensor Core的矩阵乘累加运算是一种混合精度运算。我们前面提到的一个V100可以实现125 TLOPS的混合精度运算,指的就是Tensor Core的混合精度。比如我们现在要计算D=A*B+C这样的矩阵乘累加运算,实际上这里面要求A、B两个矩阵必须是半精度,即FP16的类型。而加法矩阵C还有结合矩阵D既可以是FP16类型,也可以是FP32类型。在Tensor Core中,这是需要大家注意的一个特性。
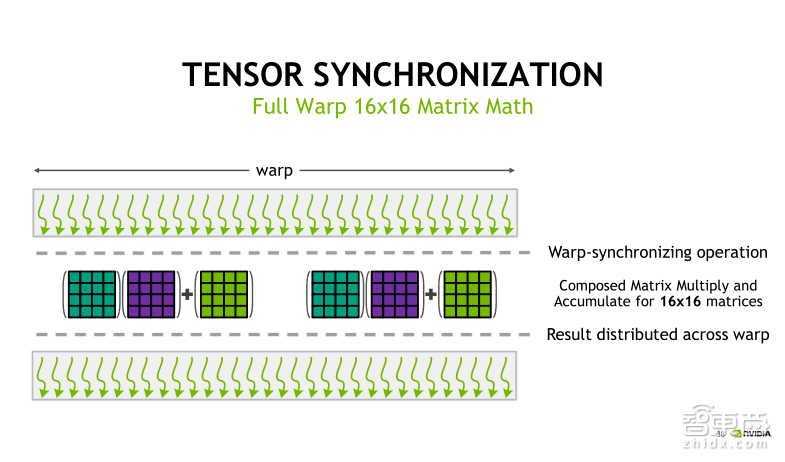
在具体实验过程中,Tensor Core以WARP为单元执行。一个WARP中执行的是一个16×16×16的矩阵乘累加运算。这里就用到了刚才我们提到syncwarp线程之间进行数据交换和同步的机制。
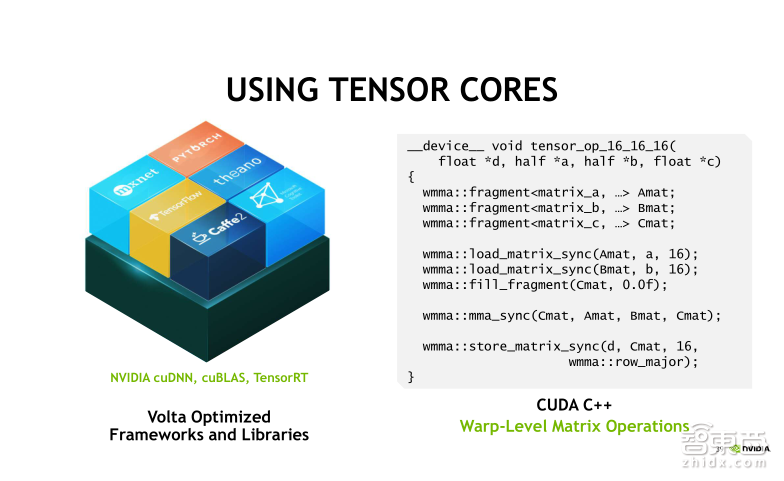
关于如何利用Tensor Core实现矩阵乘法的加速,我们提供两种方式。第一种方式如右侧图中展示的代码,在CUDA编程里实现Tensor Core的调用。我们在新的CUDA 9.0里增加了一个秘密空间——WMMA,可以调用其中的API去实现输入矩阵的Load(加载),两个矩阵做乘加,还有结构矩阵的Store(存储)。而第二种方式相对比较简单,可以利用现成的库函数,最新版本的cuDNN7.0、CUDA9.0中的cuBLAs,TensorRT3.0都支持Tensor Core的调用。
Tensor Core的功能正在被集成到越来越多的深度学习框架里去,目前Tensor Core可以支持的深度学习框架有Caffe、Caffe2、MXNet、PyTorch、Theano、TensorFlow等,但CNTK、Chainer、Torch目前还不支持Tensor Core的调用,这点需要大家特别注意一下。
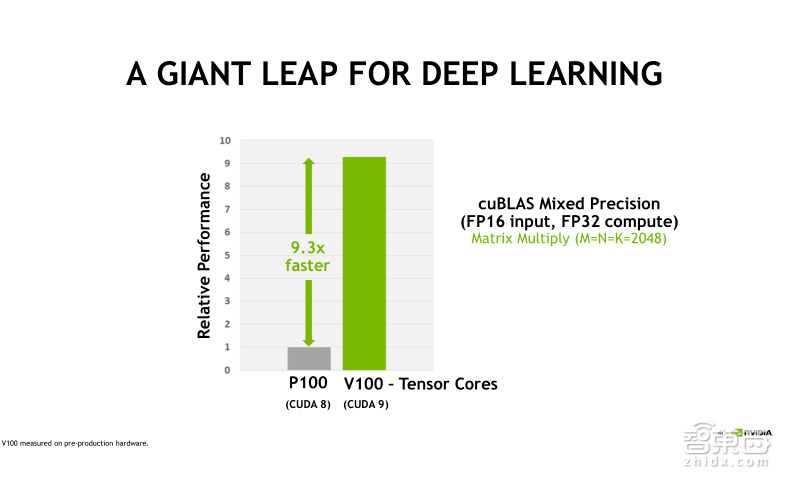
第二幅图是一个benchmark的测试结果,左侧的灰色的柱状表示的是Tesla P100+CUDA8调用cuBLAS库,进行混合精度的矩阵乘法得到的性能,而右侧绿色的柱状表示Tesla V100+CUDA9调用cuBLAS库,实现混合精度矩阵乘法的性能。可以看到,Tesla V100相比于Tesla P100提升了9.3倍。

我们进入第三节的内容。在第二节里面我们剖析了Tesla V100的V架构特性,解释了新的SIMT模型,独立线程调度的概念,并重点说明了Tensor Core的工作原理以及调用的方式。在第三节里面,我们会带着大家了解Tesla V100在HPC中的一些应用。

实际上排名前15的HPC商用软件都可以支持GPU的加速,比如我们比较熟悉的ANSYS、Gaussian、VASP、AMBER。它们在物理、化学、生物、流体电磁等领域的设计、仿真、验证方面都起到至关重要的作用,可以极大提升工程师的工作效率,促进产品创新。很多产品在GPU上的加速效果,相比于CPU可以达到几倍甚至十几倍的加速比。在未来,Tesla V100 GPU将会为这些HPC软件提供更好的加速效果。
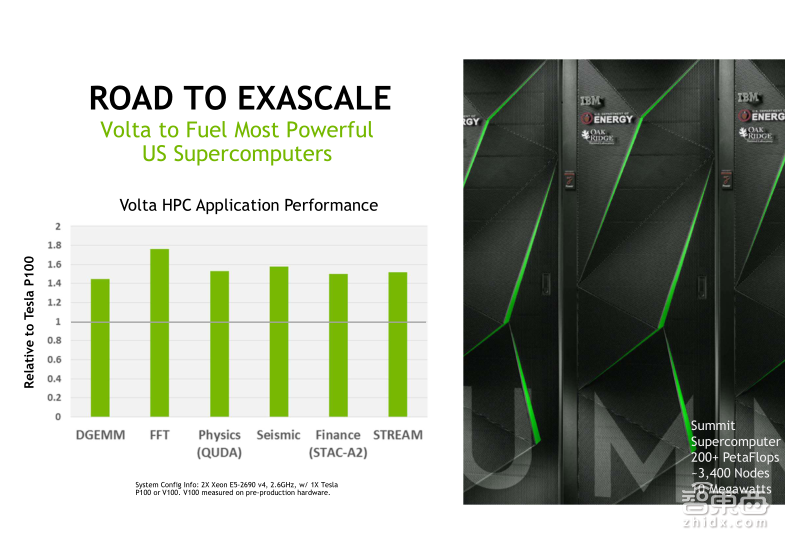
让我们来看一下Tesla V100 GPU在一些HPC算法中的benchmark测试,比如矩阵乘,快速傅里叶变换,QUDA等等。从图中可以看到,相比Tesla P100的GPU,Tesla V100的平均加速比是在1.5倍左右。由于这些算法都是使用双精度浮点计算,所以这个结果与Tesla V100的双精度浮点计算能力方面比Tesla P100有50%的性能提升是直接相关的。
来关注几组现在或者在不远的将来会大规模部署Tesla V100的GPU的数据中心。

第一个是美国的橡树岭国家实验室,它将在明年完成超过3400台Tesla V100 GPU服务器的搭建,这台超级计算机称为Summit。相比于上一代超级计算机Titan(Titan,中文名泰坦,是在2012年建造的,今年的全球排名是第四名),Summit的浮点计算性能大概提升了10倍,也为各种HPC的应用提供5到10倍的性能提升。

第二个是日本的国家先进工业科学和技术研究所(AIST)将在其数据中心部署4352颗Tesla V100 GPU,实现37PetaFLOPS的双精度浮点计算性能,以及大约0.55ExaFLOPS的混合精度计算性能。该超算中心将会为一些世界级的AI研发提供创新平台,以使得AI的研发成果能够更快地部署到商业和社会应用中。

第三个是NVIDIA超级计算器——SARURNV。SARURNV将在原有的基础上进行升级改造。去年,SARURNV由124台DGX-1服务器搭建而成,每台DGX-1的服务器搭载了8颗Tesla P100 GPU,这台超级计算机曾经在世界Top500绿能计算机中排名第一。在升级之后,SARURNV将会由660台DGX-1V服务器组成,每台DGX-1V服务器会由8颗Tesla V100 GPU组成。
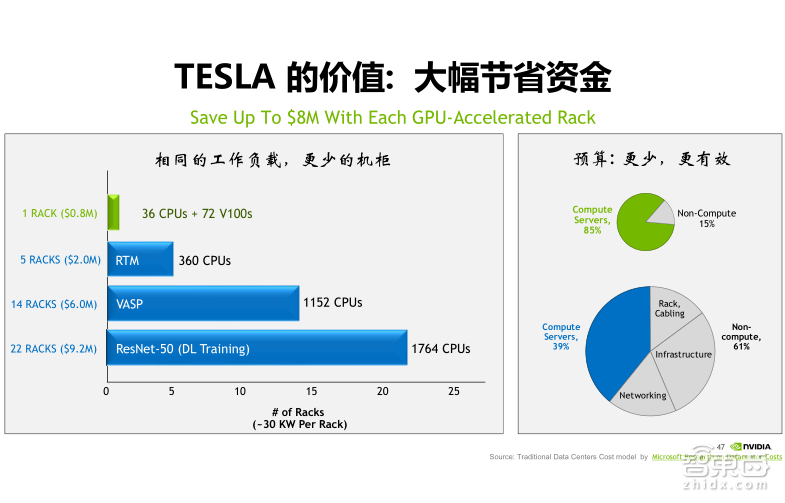
全世界越来越多的超算中心开始使用GPU计算集群代替原有的CPU计算集群,主要是因为GPU的核心价值是可以为客户大幅度的节省资金。从右边的两个饼图可以看到,相比CPU计算集群,GPU计算集群会把绝大部分的成本花费在购买计算力上,而CPU的集群有很多的成本花费在建设基础设施、网络、机柜等花销上。从左侧的benchmark的对比看到,假设有18台GPU服务器,每台是由2颗CPU和4颗V100的GPU,同等计算力的情况下,对于不同的算法,需要多少CPU的计算集群。
RTM算法需要360颗CPU放入五个机柜,VASP的算法需要1152颗CPU放入14个机柜。而对于ResNet-50深度学习训练模型来说,需要有1764颗CPU去实现同等计算力。相比而言,从成本、功耗方面,GPU集群拥有巨大的优势!

在第四部分,我们再来看一下Tesla V100 GPU在加速深度学习应用方面会有哪些提升。在这一节里面我也会简单的跟大家介绍一下几个Tesla V100 GPU在深度学习开发生态中比较重要的软件SDK。

提到Deep Learning(深度学习),大家一定会想到GPU。我认为GPU在Deep Learning方面如此受欢迎主要有两方面原因,第一是GPU在硬件性能上拥有强大的浮点计算能力。无论是对于训练端,还是推理端来讲,GPU相比CPU都有巨大的性能优势。并且,NVIDIA每年推出新的GPU产品在计算性能上也在不断地提升。由于GPU产品多样化的特征,无论是针对云端的数据中心,还是自动驾驶汽车或者嵌入式智能机器人,我们都有对应的GPU产品可以被用户所选择。因此从训练端到推理端的解决方案方面,GPU有着天然优势!
对于一个训练好的神经网络模型,我们当然希望在做推理时,可以最小化导入模型、修改模型、执行模型。如果在训练端使用GPU处理器,并在推理端使用同样架构的GPU处理器,并且实现比较高的吞吐和低延迟,当然是最好不过的选择!
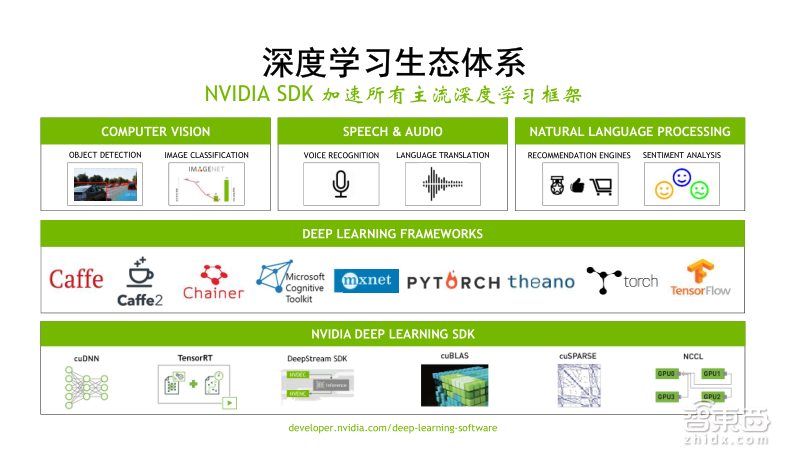
GPU在Deep Learning方面受欢迎的第二个原因,它拥有一套非常强大且完整的生态体系。无论是对计算机视觉、语音识别和翻译,或者是自然语言处理方面的应用,我们都可以使用GPU进行加速。目前所有主流的深度学习框架,像Caffe、TensorFlow、MXNet、CNTK等都支持GPU的加速。对使用这些框架的用户来讲,这种加速是透明的,通常我们只需要在执行脚本里面加入类似于GPU enable的命令就可以了。
那么,在底层实现上,NVIDIA提供了大量SDK去支持上层应用或者框架,来最简化、最高效地帮助用户实现GPU加速Deep Learning的训练或推理的过程。这些SDK包含了像标准线性代数库cuBLAS、深度学习算法库cuDNN、多GPU的集合通信库NCCL以及推理加速引擎Tensor RT等。我会一一地向大家介绍。
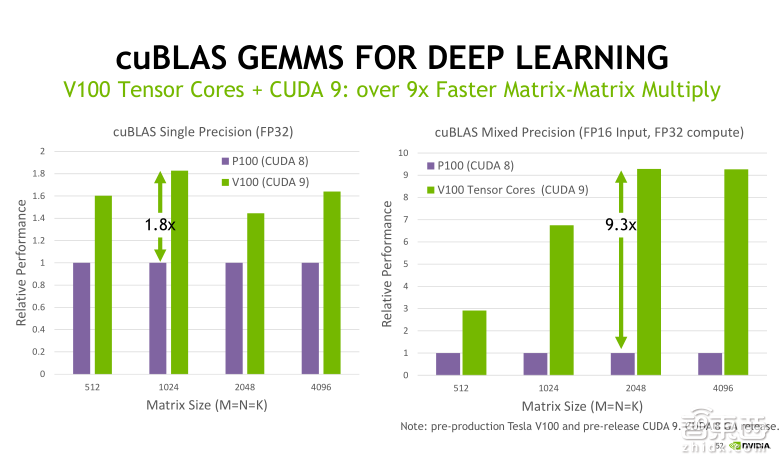
先来看一下在Training(训练)端的SDK。第一个是cuBLAS库,cuBLAS是标准线性代数库在GPU上实现的一种封装。大家可以看到这幅图的两个benchmark测试结果,我们分别比较了Tesla P100和Tesla V100在单精度浮点计算矩阵乘法和混合精度浮点计算矩阵乘法方面的性能。
左侧的单精度浮点计算矩阵乘法,可以看到不同矩阵大小得到加速比实际上是不一样的,最大加速比可以达到1.8倍左右,而平均的加速比是在1.5倍。这跟Tesla V100比Tesla P100在单精度的浮点计算性能上提升50%的结果是相吻合的。
右侧的混合精度浮点计算,由于Tesla V100可以使用Tensor Core进行加速,所以最大的加速比达到了9.3倍。因此Tensor Core在矩阵乘法方面的性能优势可见一般。
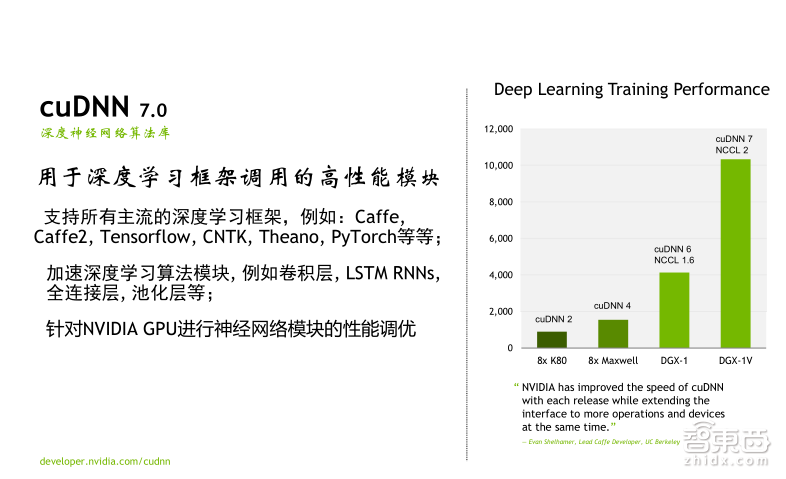
在Training方面第二个比较重要的库是cuDNN。cuDNN是深度学习基础模块加速库,可以支持所有主流的深度学习框架,比如Caffe、Tensorflow、CNTK、Theano、PyTorch等,这些基础模块指的是深度学习框架中常用的一些layer(神经网络层)操作,比如卷积、LSTM、全连接、Pooling(池化层)等。那么cuDNN的优势有什么呢?首先它将layer专门针对GPU进行了性能调优;第二是cuDNN以调用库函数的方式进行神经网络设计,能够大大节省开发者的时间,让大家可以将时间和精力集中在神经网络的设计和实现,而不是去进行GPU代码的开发和性能调优。
在这个benchmark中大家都可以看到,分别使用了八颗不同架构的GPU服务器对GoogLeNet网络进行训练的性能对比,大家可以只看最后两个绿色的柱状图,分别代表的是八颗P100的DGX-1服务器以及八颗Tesla V100的DGX-1V服务器。大家可以看到二者的性能差异大概是在2.5倍左右,也就是我们在Tesla V100上进行Deep Learning 训练时的性能提升水平。

接下来介绍的SDK是NCCL。NCCL表示的是NVIDIA集合通信库的一个简称。它是多GPU之间常用的一些集合通信算法,比方说all-reduce、all-gather以及broadcast等等,它能够自动检测GPU之间的拓扑连接关系,再结合通信采用最佳的路径实现数据IO。在最新的NCCL 2.0版本里面,增加了对多服务器节点的支持,在NCCL 1.0版本里面我们只是支持单节点内的多GPU,但目前NCCL 2.0可以支持多节点的,并且可以同时支持PCle和NVLink连接方式。大家从右侧的benchmark可以看到,从单节点一颗GPU到单节点八颗GPU,再到两个节点16颗GPU,以及四个节点32颗GPU,使用NCCL实现的Deep Learning 训练的吞吐性能几乎是线性增长的,其实这是非常难达到的一个性能。而目前NCCL 2.0最多可以支持八个服务器节点的并行。

接下来要给大家介绍一个工具,叫做DIGITS。DIGITS是一个基于WEB UI交互式的深度学习训练系统。对于深度学习的初学者或数据科学家来说,这个工具能够为他们提供极大的便利性,主要有四个方面的功能。
1、进行数据的预处理。比如说我可以把一些原始的jpeg格式的图片转成lmdb或者leveldb这样的数据库导入到DIGITS。
2、我可以利用DIGITS去配置我的网络模型,比如我去选某个Deep Learning的框架,某一个标准的模型,比如AlexNet、GoogLeNet等,或者自定义一个网络模型,然后去设置模型训练参数,以及要使用哪些GPU。
3、可以实时动态地监控整个训练过程。当导入数据和配置网络模型完成后,就可以点击按钮开始训练,在训练过程中可以实时动态地去监控loss和accuracy这样的参数曲线以及GPU、 CPU的利用率,包括显存和内存的使用情况都可以一目了然。
4、训练完成之后,我们还可以使用保存的训练好的model的参数进行一些测试,包括网络层可视化这样的工作。目前DIGITS支持的深度学习框架包括了Caffe、PyTorch和TensorFlow,支持的算法主要是包含了图像分类、图像分割、目标检测。
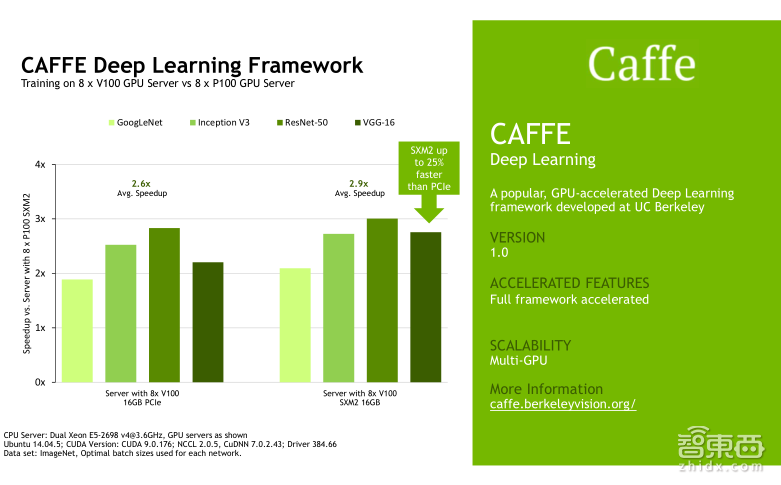
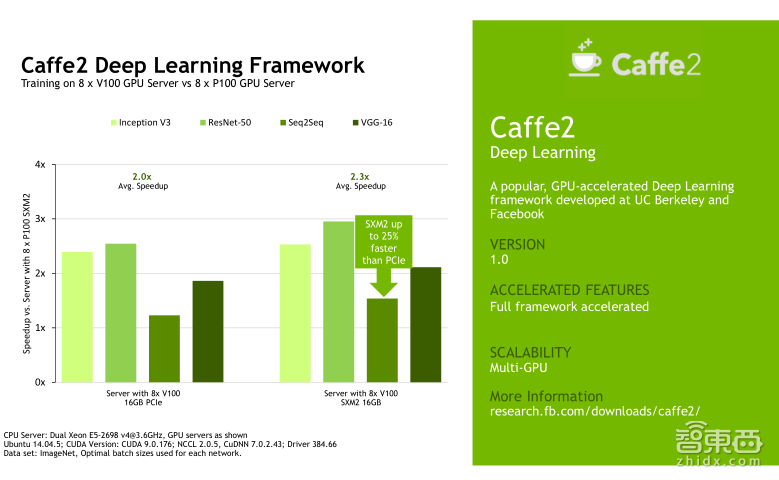
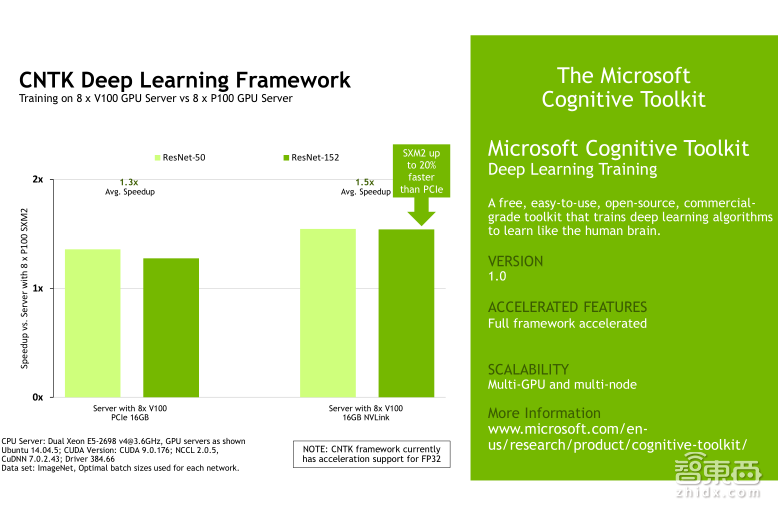

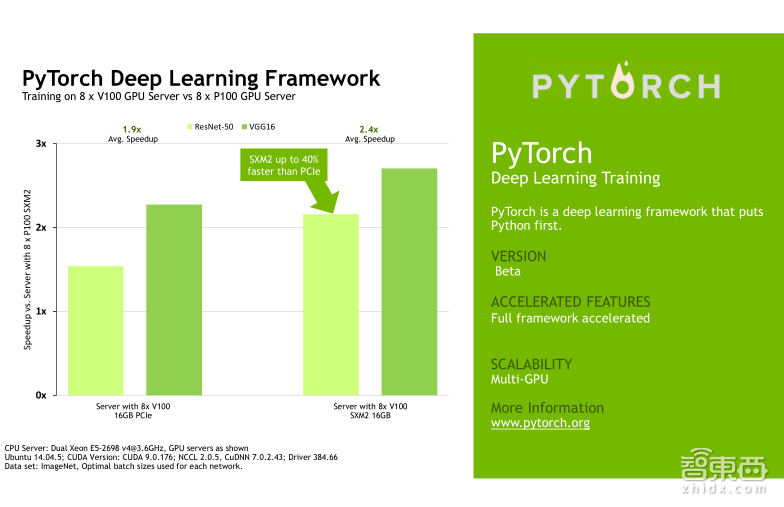
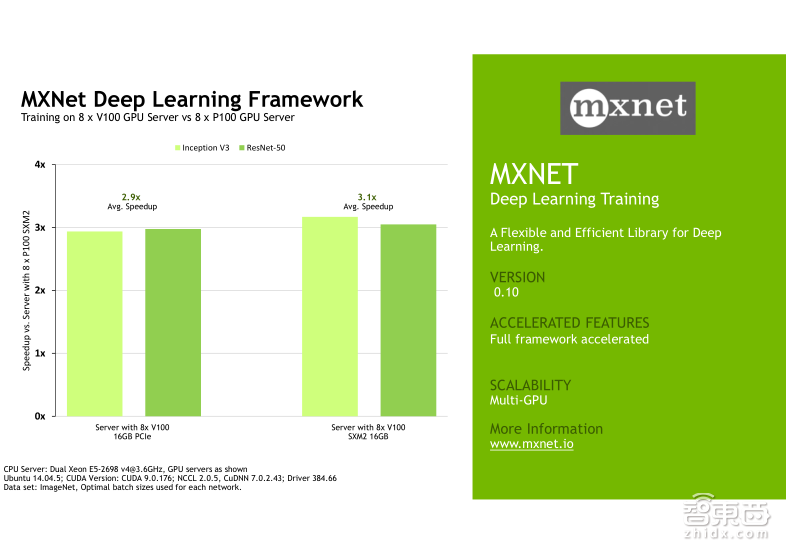
下面我会给大家展示几组Tesla V100在不同的Deep Learning的framework上,针对不同的网络模型的一些benchmark测试结果,他们对比的都是八颗Tesla V100以及八颗P100的性能加速。左边展示的是Tesla V100的PCIe卡的性能加速,右边展示的是Tesla V100的NVLink卡的性能加速。大家可以挑选自己使用的framework测试结果来看,我就不一一介绍了。针对不同的framework,实际上Tesla V100的加速效果确实会略有不同,需要向大家说明的是,这些framework测试中包括Caffe、Caffe2、TensorFlow、MXNet以及PyTorch,他们都支持Tensor Core,但是目前CNTK还不支持Tensor Core。
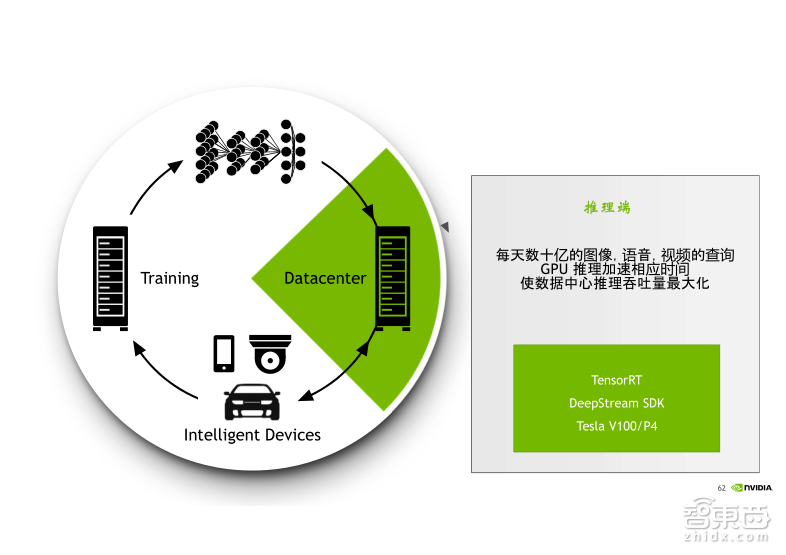
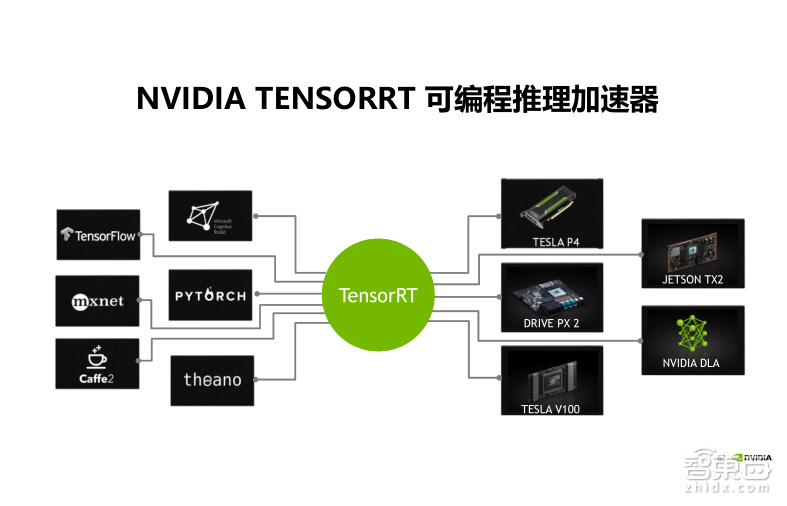
接下来我们来看一下在Inference(推理)端的SDK的工具。首先是TensorRT,TensorRT是可编程的处理加速器,主要是用来部署神经网络到Inference端之前,对于网络进行优化加速,来提高程序的吞吐量以及降低延迟。TensorRT理论上可以支持所有主流的深度学习框架,目前最新的版本是3.0版,可以支持Caffe 模型的直接导入,还有就是TensorFlow模型转换为UFF格式后的导入。对于其他的framework,需要用户手动的去调用一些API进行模型和参数的导入,而且在TensorRT 3.0里面还加入了对Python接口的支持,原来我们是只支持C++的,目前加入了Python,这样使得导入网络模型可以变得更加容易一些。
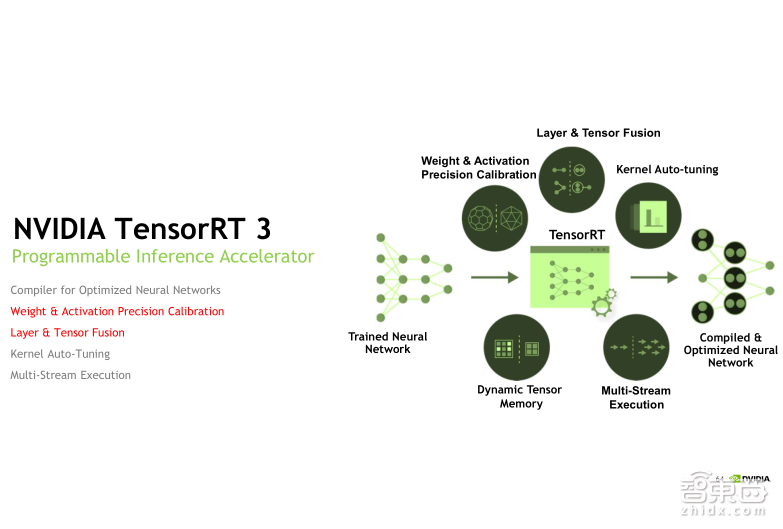
TensorRT 能够帮助我们做哪些网络模型优化呢?大家可以看到右边这个图里面有五大优化方面,这里面着重介绍两个,第一个叫做权重系数和激活值的精度校准,我们知道在Training端,一般计算精度是FP32单精度的。但是在做Inference部署的时候,在整个网络精度变化不大的情况下,我们更关心延迟和吞吐。实际上这也是降低计算精度的一个很常用的方法。比如我们可以将FP32的精度降为FP16或者INT8,由于量化范围缩小,我们只需要在量化过程中做一些动态的校准,TensorRT 就可以自动帮助我们完成校准过程,并且精度损失缩到最小化。
第二个叫做网络层的合并,在网络模型里,通常一个layer(网络层)就需要发射一次Kernel,而在layer比较小的情况下,这种发射的效率是比较低的,因为每次Kernel发射是需要耗时的,并且对GPU的利用率也不会很高。这时TensorRT 就可以自动地去检测一些可以合并的来源,把它们合并成一个比较大的Kernel发射,减少Kernel发射并且提升GPU的利用率。关于其他的一些优化方法,大家可以再参考TensorRT 用户手册进行详细的了解。
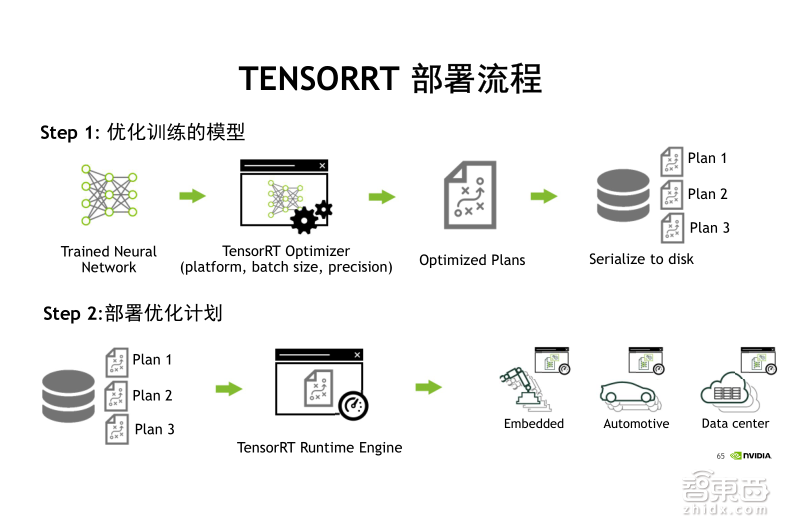
TensorRT的部署流程可以分成两部分。首先是向TensorRT 导入训练好的网络模型、参数,输入一组测试集数据,这个数据集不用太大。在TensorRT 启动之后,会根据我们刚才所说的几大优化方式依次对网络模型进行优化,对于规模不大的网络,这个过程可能需要耗费几分钟的时间。在执行完成之后,它会输出一个优化策略,如上图所示的Plan。这时我们可以选择将这个优化策略以序列化的方式导出到磁盘文件进行存储,这样,这个策略文件就可以被复制以及移植到不同的设备端来使用。接下来我们就可以拿着这个优化策略文件连通TensorRT 的引擎,一起部署到线上服务端。
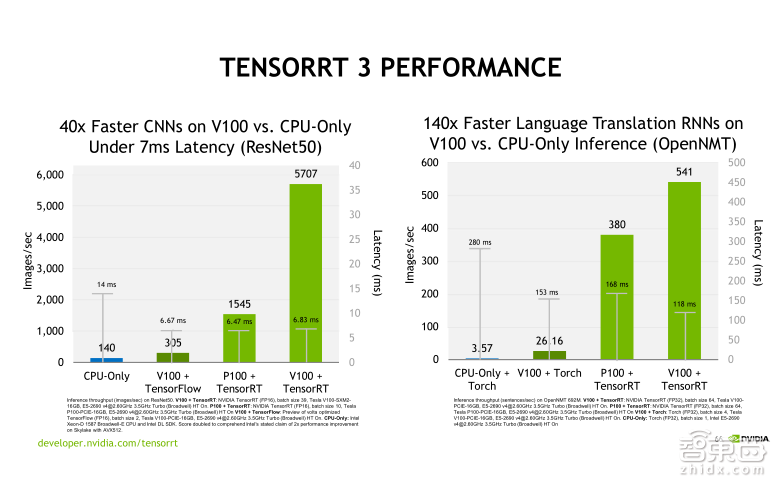
我们在上面这幅图里给出了两组TensorRT 3.0 Performance的benchmark,左侧的benchmark是对一个CNN网络ResNet-50的测试结果,大家可以先看第二和第四个柱状图,这里面是比较了使用V100 加TensorFlow,也就是不用TensorRT做优化 ,然后直接做Inference,此时的吞吐量是305,在使用TensorRT 加速以后,吞吐量提升到5707,大概是20倍的性能提升。另外,大家再看第三和第四个柱状图,可以看到同样使用FP16的计算精度,Tesla V100比Tesla P100提升了大概3倍多的性能,这主要得益于Tensor Core的加速。
右边的benchmark是对一个RNN网络OpenNMT的测试结果。大家可以先来看二和四这两个柱状图,使用Tesla V100+Torch直接做Inference,这时候吞吐量是26.16,我们用TensorRT 加速以后,吞吐量直接提升到了541,加速比可以达到20倍以上。我们再来看第三和第四,比较一下Tesla P100和Tesla V100的加速,可以看出Tesla V100大概比Tesla P100加速比在1.5倍左右,这主要是因为我们在该网络模型里使用FP32进行Inference,无法使用Tensor Core进行加速,实际上TensorRT 目前对RNN网络只能支持FP32的精度,还不能支持到FP16。
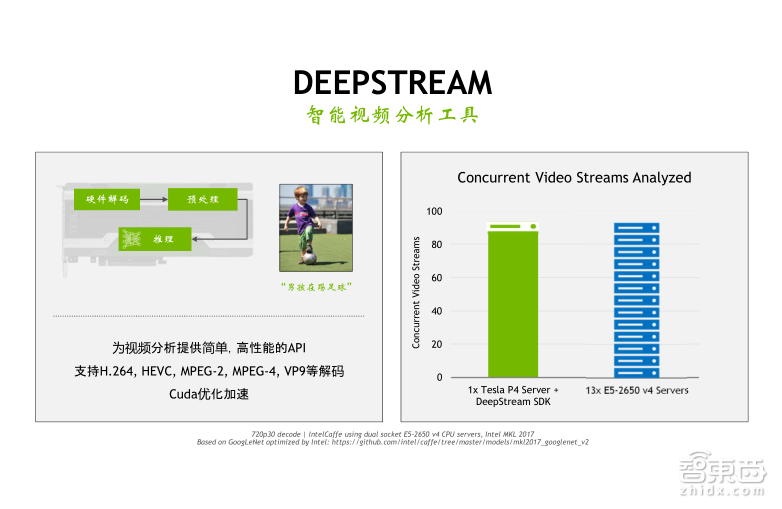
在Inference端的最后一个SDK的软件我们叫做DeepStream,DeepStream主要是针对于智能视频分析的一个工具,智能视频分析我们称之为IV。实际上IV的工作流程主要是包含三个部分,首先是做视频解码,然后进行图片的预处理,比如Reset(重置)或颜色空间的转换等,最后是基于神经网络的推理操作。GPU有独立的编解码单元,并且可以支持多种编解码格式。我们在调用DeepStream SDK的时候是可以将视频的解码以及Inference(推理)的功能集中在一起,直接利用GPU上的NVdata单元做解码,利用Cuda core做Inference,方便开发者使用,同时提升处理的效率。
从右边的benchmark中,大家可以看到在测试环境为720P的视频解码里面采用GoogLeNet做神经网络的分类预测,这个时候我们可以用DeepStream SDK搭载一张P4的GPU服务器,而它的视频流的处理能力大概相当于13台E5 CPU双路服务器,因此整个的性能提升还是非常可观的。


前面四个部分主要是给大家介绍了关于Volta架构的解析以及在HPC和Deep Learning中的一些应用。最后一部分给大家介绍Volta产品家族。首先针对Deep Learning的应用,如果只做Training或者既需要做Training,又需要做Inference这样的场景,Tesla V100肯定是最好的选择,因为我们搭载了最新的Tensor Core,可以支持Training和Inference的加速。对于NVLink的应用,比如Transcoding + Inference,实际上我们的Tesla P4这款GPU是最合适的,它的功耗很低,有50瓦和75瓦两款产品,同时也能够提供最佳的计算性能和功耗比。
对于中间的两款Tesla V100的GPU ,NVLink版本以及PCIe版本,其实没有非常严格的界限,要根据客户的实际应用进行选择。一般来说如果算法里需要在GPU之间频繁进行数据交换,那么PCIe的传输带宽可能会成为瓶颈,如果这个时候使用NVLink版本的GPU就能达到比较好的效果,否则PCIe版本的V100是更通用的选择,毕竟二者在计算性能上的差异并不大,而且支持PCIe版本的GPU 服务器是比较多的!
另外NVIDIA在去年推出了深度学习一体机——DGX系列产品。目前DGX有两款产品可供选择,分别叫做DGX Station和DGX-1 Server,它们为需要快速部署深度学习研发环境的客户提供了一种最佳的选择。下面我们分别来看一下这两款产品的技术细节。

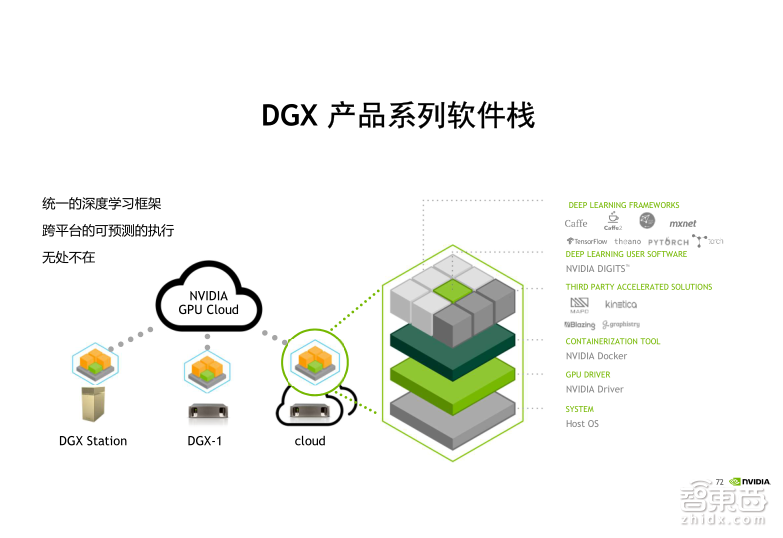

DGX-1的第一代产品是NVIDIA在去年推出的。上一代产品里面搭载了八颗Tesla P100的GPU。在今年美国GTC大会上,我们陆续推出了DGX的升级版,也叫做DGX-1V的服务器,它搭载了八颗Tesla V100GPU,它的混合精度计算能力可以达到1PFLOPS,这是由每一个V100由125个TFLOPS乘以八颗Tesla V100计算得到的。而它的NVLink带宽最高可以达到300GB每秒。这相比上一代产品有显著提高,刚才我们在这部分也给大家做了详细的介绍。另外,在其他特性上,比如搭载了两颗Xeon CPU,8TB RAID 0磁盘阵列,4路IB,2路万兆网接口,这些技术跟上一代的产品都是一样的。
今年我们又推出了DGX家族的一个新成员,叫做DGX Station,也就是DGX工作站,搭载了四颗Tesla V100的GPU,GPU之间采用的是NVLink互联,它的混合计算精度可以达到500TFLOPS,DGX Station最大的亮点是采用了静音水冷设计,它的噪音水平小于35db,非常适合研发人员将它放在办公室桌面端进行使用,不需要放在机房里面。
DGX产品家族的亮点不止于刚才我们提到它具有非常强大的硬件配置性能,同时它还向客户提供了非常丰富的软件栈产品。这些软件栈主要指一些基于Docker 镜像的封装,比如针对深度学习主流的学习框架Caffe、TensorFlow、MXNet等,我们都会向客户提供一些Docker 的镜像,而且这些镜像是NVIDIA的工程师专门针对DGX硬件做了优化,可以实现比普通的GPU服务器环境更快的性能,同时购买DGX的用户,它的镜像可以在NVIDIA的官方网站上进行更新,可以免费下载使用。
今天整个公开课的内容就是这些,也欢迎大家来使用我们目前宇宙最快的加速器V100。谢谢大家。
Q&A实录
问题一
胡远武-城市生活(北京)资讯有限公司-架构师
1、OpenGL和OpenCL能否集成,如果能集成,他的主要优势是什么?
2、GPU取代CPU的前景如何?
3、提升GPU利用率的关键点是哪些?
罗华平(英伟达中国首席解决方案架构师):1、关于第一个问题,在很多年之前Open CL可以去调用Open GL的API,就是说Open CL可以直接使用Open GL的库函数来对OpenGL图形信息进行处理计算,这个技术在Cuda里也早已实现。那么它到底有哪些优势呢?我觉得现在用Open CL的人并不太多,虽然说Open CL是一个跨平台的软件,但是Open CL目前面临的最大问题就是它虽然是跨平台的,但是针对不同的平台,可能需要进行不同的性能优化,所以OpenCL目前并没有得到一个很好的推广!另外一个方面就是Open CL是由一个联盟组织来规范能够加入哪些新的功能,因此OpenCL的发展就会受制于各个厂家对性能的一些要求等,因而发展比较慢。现在在异构计算里Cuda已经是使用最普遍的一个并行编程平台,也可以说Cuda已经是业界的一个事实标准。使用Cuda,特别是在NVIDIA GPU上,可以获得一个最高的性能。虽然Open CL可以跨平台,但是目前确实没有Cuda使用的那么快,因此它有什么优势,我现在确实也说不上来。在并行计算领域,我们还是推荐Cuda或者加OpenGL,来处理计算和图形的任务。
2、可以说GPU的出现不是取代CPU的,GPU是对CPU的一个补充。GPU离开CPU是不能单独工作的,所以GPU需要一个x86的CPU或者是IBM的Power CPU来做运行操作系统,运行整个程序只是把需要并行计算的部分我放到GPU上来加速进行,所以GPU不会取代CPU,同时GPU离开CPU也是不能工作的。
吴磊:3、实际上对于GPU利用率的提升,我们可以分两方面来讲:第一个方面,我们刚才在介绍MPS的时候也介绍到了,如果我们现在发射的Kernel的计算量不大,那么这时候我们可以采用多Kernel并行发射的方式,比如利用MPS技术,使得多个Kernel同时发射到GPU中去,提升GPU的利用率;另一方面,如果单一的Kernel计算量就很大,可以把GPU的资源几乎占满,对于这种情况下我们就需要去考虑基于GPU以及基于Cuda的一些优化方法。比如我们知道常用的一些优化方法有:基于存储的优化、基于指令的优化以及基于延迟的优化。具体的要去利用一些工具,比如Visual Profiler 以及其它的工具进行性能的剖析,然后在我们知道性能受限的因素之后,再进行一个具体的优化。
问题二
管伟-千丁互联-自然语言处理工程师
做深度学习的最低配置方面,最小能出效果的数据量是多少?
罗华平:这个问题说实话不是特别好的回答,现在做深度学习主要是让训练速度快,训练时间越短越好。从我们训练的GPU平台上来讲,现在已经从标准的四卡服务器发展到八卡服务器,且八卡服务器目前也受到了大家普遍的接受,可以说在明年将成为训练平台的一个主要配置。至于多少数据量才能出效果,要根据用户的神经网络模型来决定的,说实话,我们现在也不好确切回答,可以看到,做图像和做语言处理需要的数据量也是不一样的,还是需要根据具体的神经网络的模型来看待,这是我的一点点看法!
问题三
董瑞宾-北京瑞远机器人-视觉工程师
NVIDIA有没有较低功耗的嵌入式平台,可以快速部署本地化处理深度学习的成熟的解决方案?
罗华平:NVIDIA专门有一条产品线叫Tegra,这是NVIDIA嵌入式的一个解决方案。目前我们NVIDIA的嵌入式平台有Jetson TX1和TX2两个产品,这两个产品的功耗非常低,大概是10W左右的功耗,但是计算力非常强,它实际上是一个SoC,是ARM + GPU这样一个架构,能够自己独立运行操作系统,独立做很多计算。目前如果你在大的GPU上训练好的神经网络,可以直接部署在我们的TX1和TX2去做线上的推理,像无人机、机器人甚至一些自动驾驶的方案都在采用我们TX1和TX2的解决方案。
问题四
王武峰-七彩虹科技-技术经理
目前DL各种框架(framework)比较繁多,NV是否会认为这种情况会持续下去?
吴磊:我们都知道现在做Deep Learning有非常多的framework和非常多的方法。不同的framework实际上是针对一些不同的应用场景,比如caffe,它主要是针对CNN网络做图像方面的一些应用。对于“这种情况是否会持续下去”的问题,我觉得从NVIDIA角度来说,没有办法去回答这个问题。但是我们知道现在GPU是支持所有主流的framework的加速,而且还在进一步扩大这个名单,同时NVIDIA的工程师会和这些framework的工程师一起去优化这些规模,去实现更好的加速效果。
问题五
snow-AMD-高级软件工程师
对于DL 的各种frameworks caffe/tensorflow/mxNet/torch, cuda 版本,cudnn, cublas,是否只有采用一个版本就能做到所有framework 都适用,可以达到兼容性。
罗华平:确实是这样,NVIDIA的目的是通过同一个版本的cuDNN、cuBLAS和Cuda来支持所有的framework框架,这是NVIDIA的目标。可能每个框架的适配时间会略微有点差别。比如说我们现在最新的cuDNN版本是7.1,再过上一段时间,所有的框架都会引入7.1,这是我们的目标,当然时间上确实还会有点差异,比如TensorFlow会快一点,Caffe会慢一点等这些情况也会出现。但是总体来讲,我们一个版本的这些库都会支持所有的框架。
问题六
刘博-北京思普科股份有限公司-AI工程师
深度学习平台的模型部署一般具体如何实施,还有就是都需要注意哪些?
罗华平:这个问题可以这么来看,NVIDIA刚才也介绍了,可以提供一个端到端的解决方案,从训练到线上的推理,特别是在训练平台上,我们有自己的一体机。DGX系列有DGX-1的服务器以及DGX Station工作站系列,这个系列最大好处就是已经预装了操作系统,预装了针对GPU优化好的各种框架,Caffe、TensorFlow等等。这样用户部署起来就会非常简单,只需要简单的开启设施就可以选择你使用的深度学习框架,比如Caffe、TensorFlow等等,通过DOC的方式,只需把这个框架拉下来,就可以进行深度学习。
在训练的时候选择什么样的网络模型,要根据自己的实际情况来看,可以选择Google Net、AlexNet等网络模型上进行一些修改来适应你的深度学习目标。同时需要准备相应的数据才能够去进行训练。
除此之外,我们还提供一个叫做DIGITS,基于web UI的图形训练平台,它也可以在DGX服务器上运行。它可以通过图形界面的方式来选择你的神经网络模型,选择你的数据,你可以采用几个GPU来做训练,非常方便,训练的过程也可以通过图形化的方式显示出来。对于在训练这一端,如果用户对于这些框架的部署不是特别熟悉,建议你采用DGX一体机来做深度学习的训练。对于训练好的模型,可以用我们的TensorRT来进行优化以及部署到不同的GPU平台上去,我们可以支持嵌入式的平台DIGITS、TSPACTS2,也可以支持低功耗的GPU P4或者是其他的大功耗GPU等等。
