








智东西(公众号:zhidxcom)
编 | 王颖
智东西5月7日消息,ICLR在其官网公布了ICLR大会2019的两篇最佳论文,这两篇论文在ICLR大会共收到的大约1600份论文中脱颖而出,它们分别是,加拿大蒙特利尔算法学习研究院MILA发表的NLP深度学习模型论文和麻省理工学院计算机科学与AI实验室CSAIL发表的神经网络压缩技术论文。
CSAIL的研究论文“彩票假设:寻找稀疏、可训练的神经网络”清楚的向我们展示了深度神经网络如何以更小的规模、更快的速度创建模型。
这篇论文的研究成果计划在5月6日~9日新奥尔良举行的国际学习代表大会ICLR上展示。
研究论文表明,深度神经网络能够将训练网络的参数个数减少90%以上,降低存储要求,提高推理的计算性能。虽然网络规模大幅减小,但它们能够被训练做出同样精确的预测,在某些情况下甚至比原始网络更快。
那么到底什么是深度神经网络?这种网络构建的模型又能起到什么作用呢?接下来,请通过下文了解深度神经网络。
一、什么是深度神经网络?
深度神经网络,以生物神经元为模型的数学函数层,是一种多功能的AI体系结构,能够执行从自然语言处理到计算机视觉的各种任务。
深度神经网络通常非常大,需要相应的大型语料库,即使是最昂贵的专用硬件,对它们进行训练也可能需要数天时间。
如果初始网络不需要那么大,为什么不能在一开始就创建一个大小合适的网络呢?针对这个疑问,论文合著者Jonathan Frankle博士表示,通过神经网络,可以随机初始化这个大型网络结构,并在进行大量数据进行训练之后开始工作。
Jonathan Frankle说:“这种大型结构就像买了一堆彩票,即使只有很少的几张彩票能让你变得富有,但我们仍然需要一种技术,在没有看到中奖号码的情况下找到获奖者。”
二、深度神经网络如缩小规模?
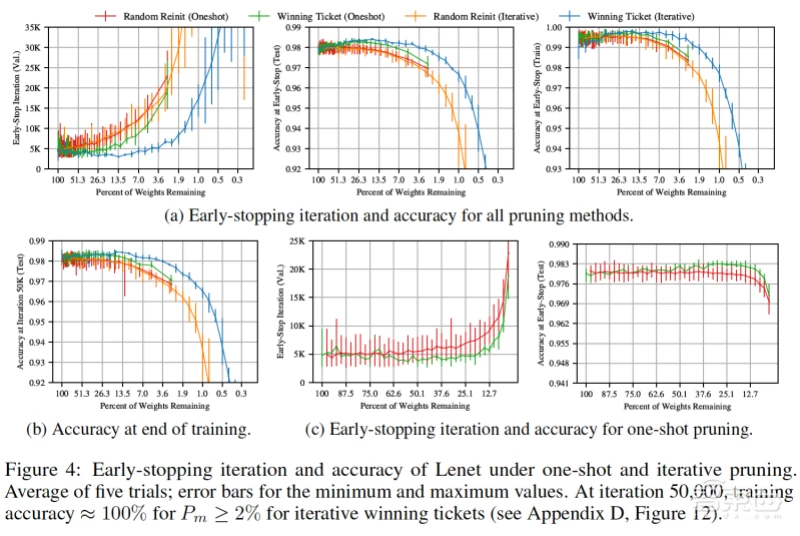
研究人员缩小神经网络规模的方法包括消除这些功能(或神经元)之间不必要的连接,以使其适应功能较低的设备,这一过程通常称为剪枝。(他们特别选择了具有最低“权重”的连接,这表明它们是最不重要的。)
接下来,他们在不对连接进行剪枝的情况下训练网络并重置权重,在修剪其他连接后,他们确定了有多少连接可以被删除而不影响模型的预测能力。
虽然剪枝后的系数架构会使训练过程变得更难,但这也带来一个好处,通过训练难度的增加提高性能。
Michael Carbin和Jonathan Frankle在论文中表示,标准的剪枝技术可以自然地揭示子网络的初始化使它们能够有效地训练。
在一系列条件限制下,通过不同的网络重复这一修剪过程数万次之后,他们报告称,他们发现的AI模型的规模不到完全连接的父网络的10%至20%。
三、没有最好只有更好的深度神经网络
论文合著者兼助理教授Michael Carbin表示,重新设置一个表现良好的网络通常会带来更好的结果,这表明无论我们第一次做什么,都不是最佳选择,这些模型还有改进的空间,可以学习如何改进自己。
Michael Carbin和Jonathan Frankle指出,他们在较小的数据集上进行以视觉为中心的分类任务,把探索为什么某些子网络特别擅长学习和快速识别这些子网络的方法留给了未来的工作。
他们认为,深层神经网络的研究结果可能对迁移学习产生影响,迁移学习是一种为一项任务训练的网络适应另一项任务的技术。
结语:深度神经网络已与现代应用深度融合
深度神经网络能够提取更多的数据特征,获取更好的学习效果。目前,深度神经网络已经成为许多AI应用的基础,这项技术已经应用于语音识别、图像识别、自然语言处理等领域。
借助AI模型解决复杂问题是现在研究领域的重点工作内容,深度神经网络能够大幅缩小这些模型的规模,将为AI技术带来更方便、更快速的精准运算。
论文链接:https://arxiv.org/abs/1803.03635
原文来自:VentureBeat
