








机器学习已经成为了当今的热门话题,但是从机器学习这个概念诞生到机器学习技术的普遍应用经过了漫长的过程。在机器学习发展的历史长河中,众多优秀的学者为推动机器学习的发展做出了巨大的贡献。
从 1642 年 Pascal 发明的手摇式计算机,到 1949 年 Donald Hebb 提出的赫布理论——解释学习过程中大脑神经元所发生的变化,都蕴含着机器学习思想的萌芽。事实上, 1950 年图灵在关于图灵测试的文章中就已提及机器学习的概念。到了 1952 年, IBM 的亚瑟·塞缪尔(Arthur Samuel, 被誉为“机器学习之父”)设计了一款可以学习的西洋跳棋程序。 塞缪尔和这个程序进行多场对弈后发现,随着时间的推移, 程序的棋艺变得越来越好。 塞缪尔用这个程序推翻了以往“机器无法超越人类,不能像人一样写代码和学习”这一传统认识。并在 1956 年正式提出了“机器学习”这一概念。
本期的智能内参,我们推荐清华人工智能研究院的研究报告《人工智能之机器学习》,从机器学习的发展史、技术特点、人才概况、行业应用和未来趋势五大维度剖析机器学习技术。如果想收藏本文的报告(人工智能之机器学习),可以在智东西(公众号:zhidxcom)回复关键词“nc427”获取。
本期内参来源:清华人工智能研究院
原标题:
《人工智能之机器学习 》
作者:未注明
一、什么是机器学习?
对机器学习的认识可以从多个方面进行,有着“全球机器学习教父”之称的 Tom Mitchell 则将机器学习定义为:对于某类任务 T 和性能度量 P,如果计算机程序在 T 上以 P衡量的性能随着经验 E 而自我完善,就称这个计算机程序从经验 E 学习。
普遍认为,机器学习(Machine Learning,常简称为 ML)的处理系统和算法是主要通过找出数据里隐藏的模式进而做出预测的识别模式,它是人工智能(Artificial Intelligence,常简称为 AI)的一个重要子领域。
从机器学习发展的过程上来说,其发展的时间轴如下所示:
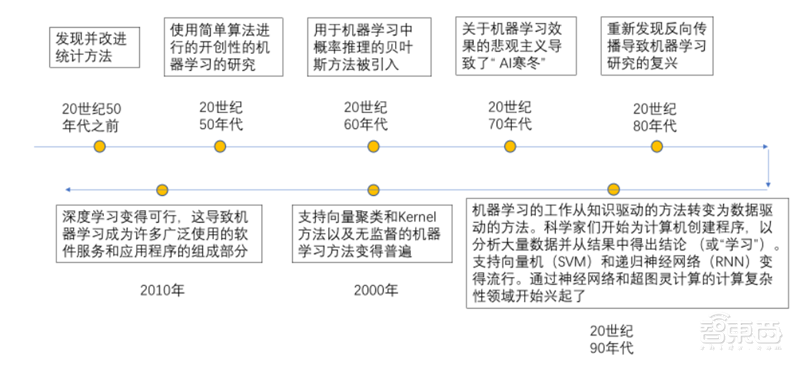
▲机器学习发展历程
机器学习算法可以按照不同的标准来进行分类。比如按函数 f (x, θ)的不同, 机器学习算法可以分为线性模型和非线性模型;按照学习准则的不同,机器学习算法也可以分为统计方法和非统计方法。但一般来说,我们会按照训练样本提供的信息以及反馈方式的不同,将机器学习算法分为监督学习、无监督学习和强化学习。
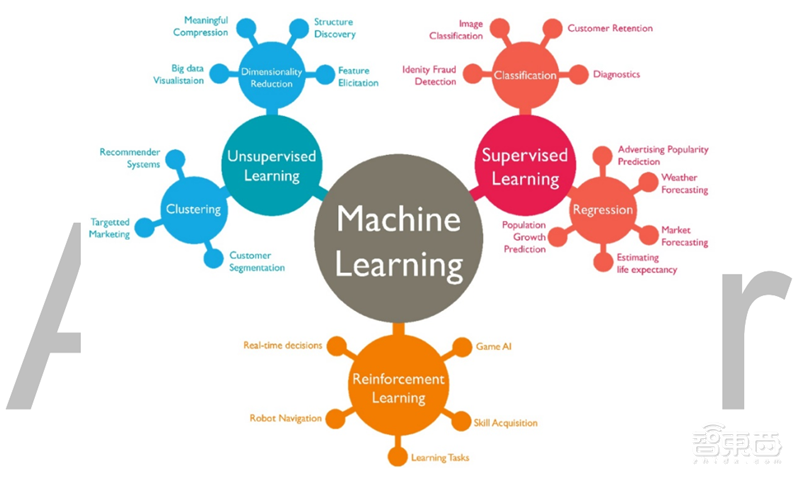
▲机器学习分类
1980 年机器学习作为一支独立的力量登上了历史舞台。在这之后的 10 年里出现了一些重要的方法和理论,典型的代表是:分类与回归树(CART, 1984) 、 反向传播算(1986)、卷积神经网络(1989)。 从 1990 到 2012 年,机器学习逐渐走向成熟和应用,在这 20 多年里机器学习的理论和方法得到了完善和充实,可谓是百花齐放的年代。代表性的重要成果有:支持向量机(SVM, 1995) 、 AdaBoost 算法(1997)、 循环神经网络和 LSTM(1997)、 流形学习(2000)、 随机森林(2001) 。 机器学习代表算法包括:
线性回归 ;
分类与回归树(CART) ;
随机森林(Random Forest) ;
逻辑回归 ;
朴素贝叶斯(Naive Bayesian) ;
k 最近邻(kNN) ;
AdaBoost ;
K-均值算法(K-Means) ;
支持向量机(SVM) ;
人工神经网络 ANN(Artificial Neural Network) ;
1、 生成对抗网络及对抗机器学习
生成对抗网络(Generative Adversarial Networks, GAN) 是用于无监督学习的机器学习模型,由 Ian Goodfellow 等人在 2014 年提出, 由神经网络构成判别器和生成器构成,通过一种互相竞争的机制组成的一种学习框架, GAN 在深度学习领域掀起了一场革命。 传统的生成模型最早要追溯到 80 年代的 RBM,以及后来逐渐使用深度神经网络进行包装的AutoEncoder, 然后就是现在称得上最火的生成模型 GAN。
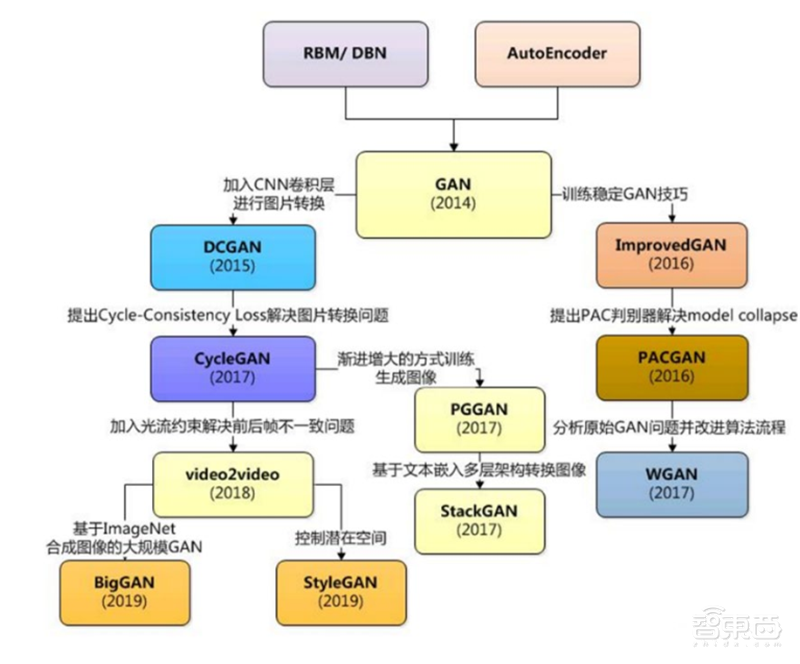
▲GAN 发展脉络
对抗机器学习是一个机器学习与计算机安全的交叉领域。对抗机器学习旨在给恶意环境下的机器学习技术提供安全保障。由于机器学习技术一般研究的是同一个或较为稳定的数据分布,当部署到现实中的时候,由于恶意用户的存在,这种假设并不一定成立。比如研究人员发现,一些精心设计的对抗样本(adversarial example) 可以使机器学习模型失败输出正确的结果。针对模型的攻击问题,我们主要分为两大类,就是从训练阶段和推理(inference)阶段来进行讨论。
训练阶段的攻击 。 训练阶段的恶意攻击(Training in Adversarial Settings) ,主要的目的就是针对模型的参数进行微小的扰动,从让而模型的性能和预期产生偏差。这样的行为主要是通过数据投毒来完成的。
推理阶段的攻击(Inference in Adversarial Settings) 。当训练完成一个模型之后,这个模型就可以看做一个 BOX,那么这个盒子中,对于我们如果是透明的话,我们就把它当成是“白盒”模型,如果这个盒子中,我们什么都看不了,我们就把它当成“黑盒”模型。(我们在这个部分不讨论灰盒模型)那么针对白盒和黑盒的进攻手段自然是不同的,但是最终的目的都是希望能对模型的最终结果产生破坏,与预期脱离。其影响力以及攻击的构造粒度也是有所不同的。
2、自动机器学习
自动机器学习(AutoML)旨在通过让一些通用步骤(如数据预处理、模型选择和调整超参数) 自动化,来简化机器学习中生成模型的过程。 AutoML 是指尽量不通过人来设定超参数,而是使用某种学习机制,来调节这些超参数。这些学习机制包括传统的贝叶斯优化,多臂老虎机(multi-armed bandit),进化算法,还有比较新的强化学习。自动机器学习不光包括大家熟知的算法选择,超参数优化,和神经网络架构搜索,还覆盖机器学习工作流的每一步。自动机器学习的用处就在于此,它帮助研究人员和从业者,自动构建机器学习管道,将多个步骤及其对应的多个选项集成为工作流,以期快速找到针对给定问题的高性能机器学习模型。 AutoML 的基本过程如下图所示:虚框是配置空间,包括特征、超参数和架构;左边训练数据进入,上面的优化器和它相连,定义的测度发现最佳配置,最后出来的是模型;测试数据在模型中运行,实现预测的目的。
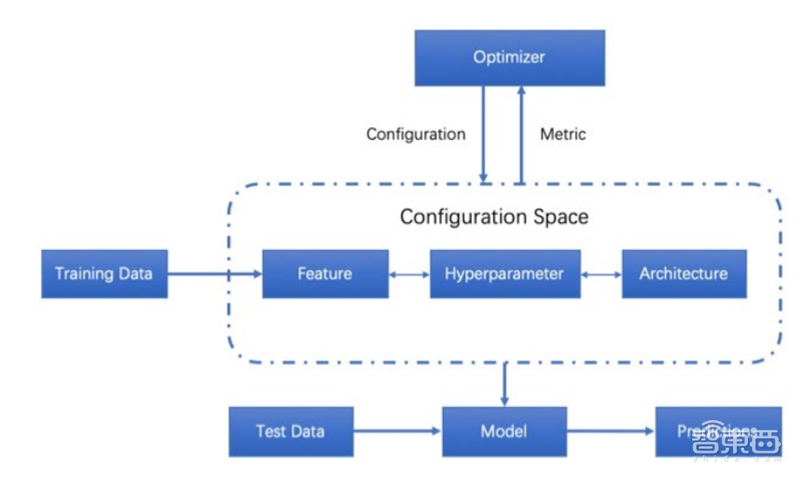
▲AutoML 基本过程
近日,在 ACM CHI 计算系统中人的因素会议上,麻省理工学院,香港科技大学和浙江大学的研究人员共同研发出一种工具,将 AutoML 方法的分析和控制权给到用户手中。该工具名为 ATMSeer,它将 AutoML 系统、数据集和有关用户任务的一些信息作为输入,然后在用户友好型的界面内实现可视化搜索过程,界面中还能提供更多关于模型性能的信息。
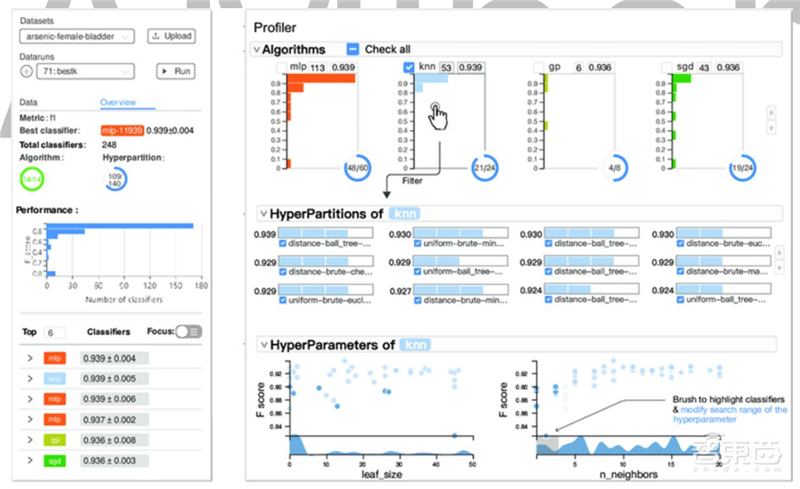
▲ATMSeer 自动机器学习定制化工具的用户友好型交互界面
上图是 ATMSeer 生成的一个用户友好界面,显示有关所选模型性能的深入信息,以及可调整的算法和参数的选项。 对没有 AutoML 经验的机器学习专家的案例研究表明,让用户掌握控制权确实有助于提高 AutoML 应用的性能和效率。对生物学、金融等不同科学领域的 13 位研究生的研究也表明,确定用户对 AutoML 的搜索的自定义关键有三点:搜索的算法数量、系统运行时间以及查找表现最好的模型。研究人员表示,这些信息可用来为用户量身定制系统。
3、可解释性机器学习
可解释性是指人类能够理解决策原因的程度。机器学习模型的可解释性越高,人们就越容易理解为什么做出某些决定或预测。模型可解释性指对模型内部机制的理解以及对模型结果的理解。其重要性体现在:建模阶段,辅助开发人员理解模型,进行模型的对比选择,必要时优化调整模型;在投入运行阶段,向业务方解释模型的内部机制,对模型结果进行解释。比如基金推荐模型,需要解释:为何为这个用户推荐某支基金。
机器学习流程步骤:收集数据、清洗数据、训练模型、基于验证或测试错误或其他评价指标选择最好的模型。第一步,选择比较小的错误率和比较高的准确率的高精度的模型。第二步,面临准确率和模型复杂度之间的权衡,但一个模型越复杂就越难以解释。一个简单的线性回归非常好解释,因为它只考虑了自变量与因变量之间的线性相关关系,但是也正因为如此,它无法处理更复杂的关系,模型在测试集上的预测精度也更有可能比较低。而深度神经网络处于另一个极端,因为它们能够在多个层次进行抽象推断,所以他们可以处理因变量与自变量之间非常复杂的关系,并且达到非常高的精度。但是这种复杂性也使模型成为黑箱,我们无法获知所有产生模型预测结果的这些特征之间的关系,所以我们只能用准确率、错误率这样的评价标准来代替,来评估模型的可信性。事实上,每个分类问题的机器学习流程中都应该包括模型理解和模型解释。
4、 在线学习
传统的机器学习算法是批量模式的,假设所有的训练数据预先给定,通过最小化定义在所有训练数据上的经验误差得到分类器。这种学习方法在小规模规模上取得了巨大成功,但当数据规模大时,其计算复杂度高、响应慢,无法用于实时性要求高的应用。与批量学习不同,在线学习假设训练数据持续到来,通常利用一个训练样本更新当前的模型,大大降低了学习算法的空间复杂度和时间复杂度,实时性强。在大数据时代,大数据高速增长的特点为机器学习带来了严峻的挑战,在线学习可以有效地解决该问题,引起了学术界和工业界的广泛关注。早期在线学习应用于线性分类器产生了著名的感知器算法,当数据线性可分时,感知器算法收敛并能够找到最优的分类面。经过几十年的发展,在线学习已经形成了一套完备的理论,既可以学习线性函数,也可以学习非线性函数,既能够用于数据可分的情况,也能够处理数据不可分的情况。下面我们给出一个在线学习形式化的定义及其学习目标。
根据学习器在学习过程中观测信息的不同,在线学习还可以再进一步分为: 完全信息下的在线学习和赌博机在线学习。前者假设学习器可以观测到完整的损失函数,而后者假设学习器只能观测到损失函数在当前决策上的数值,即, 以在线分类为例,如果学习器可以观测到训练样本,该问题就属于完全信息下的在线学习,因为基于训练样本就可以定义完整的分类误差函数;如果学习器只能观测到分类误差而看不到训练样本,该问题就属于赌博机在线学习。由于观测信息的不同,针对这两种设定的学习算法也存在较大差异,其应用场景也不同。
5、 BERT
BERT 的全称是 Bidirectional Encoder Representation from Transformers,即双向 Transformer 的 Encoder。 可以说是近年来自残差网络最优突破性的一项技术了。 BERT 主要特点以下几点:
1) 使用了 Transformer 作为算法的主要框架, Trabsformer 能更彻底的捕捉语句中的双向关系;
2) 使用了 Mask Language Model(MLM) [14]和 Next Sentence Prediction(NSP) 的多任务训练目标;
3) 使用更强大的机器训练更大规模的数据,使 BERT 的结果达到了全新的高度,并且Google 开源了 BERT 模型,用户可以直接使用 BERT 作为 Word2Vec 的转换矩阵并高效的将其应用到自己的任务中。
BERT 的本质上是通过在海量的语料的基础上运行自监督学习方法为单词学习一个好的特征表示,所谓自监督学习是指在没有人工标注的数据上运行的监督学习。在以后特定的NLP 任务中,我们可以直接使用 BERT 的特征表示作为该任务的词嵌入特征。所以 BERT提供的是一个供其它任务迁移学习的模型,该模型可以根据任务微调或者固定之后作为特征提取器。BERT 的源码和模型已经在 Github 上开源,简体中文和多语言模型也已开源。
BERT 的网络架构使用的是“Attention is all you need”中提出的多层 Transformer 结构,其最大的特点是抛弃了传统的 RNN 和 CNN,通过 Attention 机制将任意位置的两个单词的距离转换成 1,有效的解决了 NLP 中棘手的长期依赖问题。 Transformer 的网络架构如下图所示, Transformer 是一个 encoder-decoder 的结构,由若干个编码器和解码器堆叠形成。 下图的左侧部分为编码器,由 Multi-Head Attention 和一个全连接组成,用于将输入语料转化成特征向量。右侧部分是解码器,其输入为编码器的输出以及已经预测的结果,由 Masked Multi-Head Attention, Multi-Head Attention 以及一个全连接组成,用于输出最后结果的条件概率。
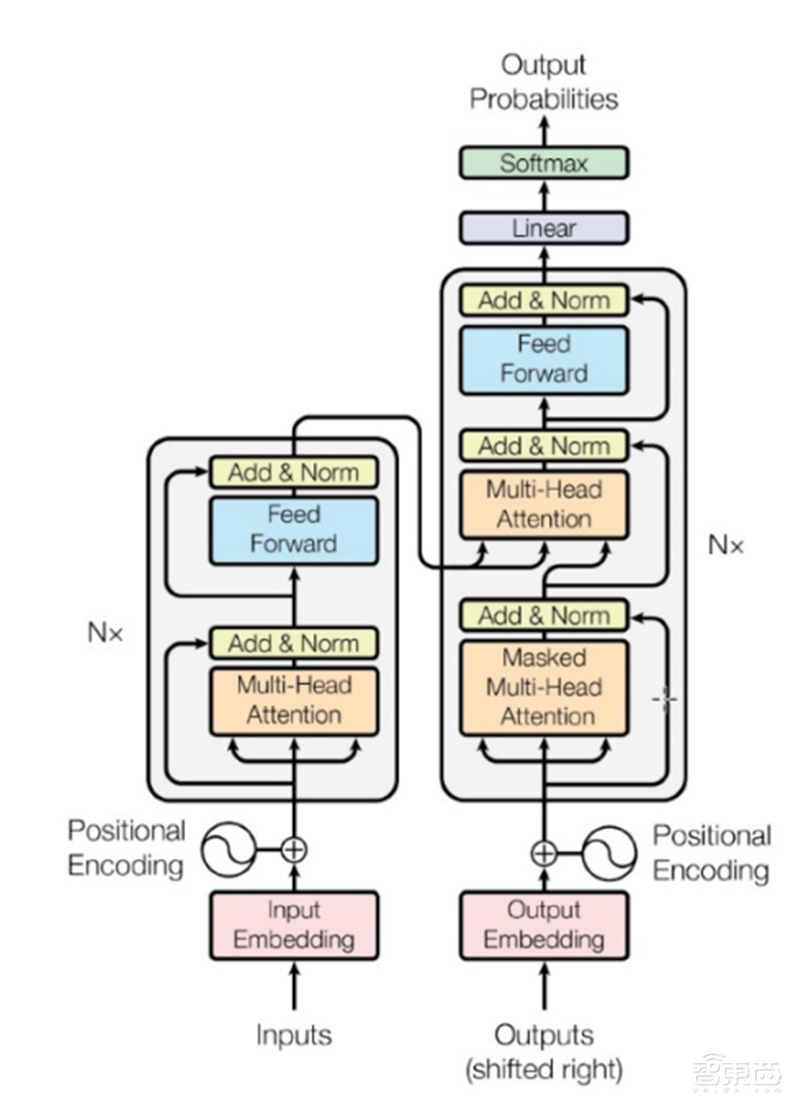
▲Transformer 的网络架构
6、卷积与图卷积
两个函数的卷积,本质上就是先将一个函数翻转,然后进行滑动叠加。在连续情况下,叠加指的是对两个函数的乘积求积分,在离散情况下就是加权求和,为简单起见就统一称为叠加。 教科书上一般定义函数 f, g 的卷积 f * g(n)如下:
连续形式:
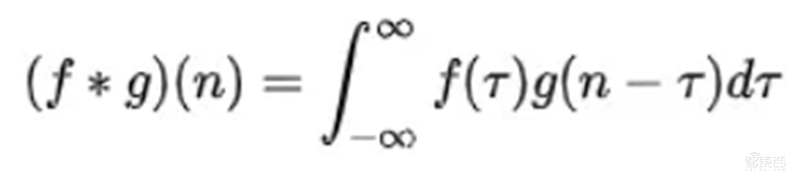
离散形式:
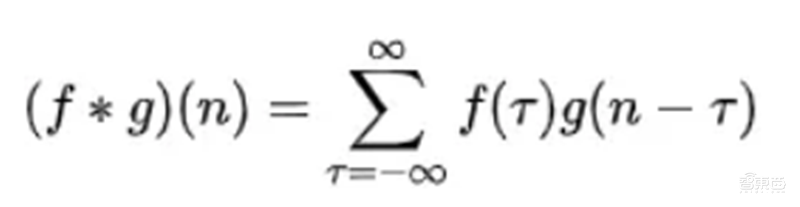
从计算的方式上对公式进行的解释为: 先对 g 函数进行翻转,相当于在数轴上把 g函数从右边褶到左边去,也就是卷积的“卷”的由来。然后再把 g 函数平移到 n,在这个位置对两个函数的对应点相乘,然后相加,这个过程是卷积的“积”的过程。 整体看来是这么个过程:
翻转→滑动→叠加→滑动→叠加→滑动→叠加
多次滑动得到的一系列叠加值,构成了卷积函数。卷积的“卷”,指的的函数的翻转,从 g(t)变成 g(-t)的这个过程;同时,“卷”还有滑动的意味在里面。如果把卷积翻译为“褶积”,那么这个“褶”字就只有翻转的含义了。卷积的“积”,指的是积分/加权求和。对卷积的意义的理解如下:
1) 从“积”的过程可以看到,我们得到的叠加值,是个全局的概念。以信号分析为例,卷积的结果是不仅跟当前时刻输入信号的响应值有关,也跟过去所有时刻输入信号的响应都有关系,考虑了对过去的所有输入的效果的累积。在图像处理的中,卷积处理的结果,其实就是把每个像素周边的,甚至是整个图像的像素都考虑进来,对当前像素进行某种加权处理。所以说,“积”是全局概念,或者说是一种“混合”,把两个函数在时间或者空间上进行混合。
2) 进行“卷”(翻转)的目的其实是施加一种约束,它指定了在“积”的时候以什么为参照。在信号分析的场景,它指定了在哪个特定时间点的前后进行“积”,在空间分析的场景,它指定了在哪个位置的周边进行累积处理。
要理解图卷积网络的核心操作图卷积,可以类比卷积在 CNN 的地位。如下图所示,数字图像是一个二维的离散信号,对数字图像做卷积操作其实就是利用卷积核(卷积模板)在图像上滑动,将图像点上的像素灰度值与对应的卷积核上的数值相乘,然后将所有相乘后的值相加作为卷积核中间像素对应的图像上像素的灰度值,并最终滑动完所有图像的过程。
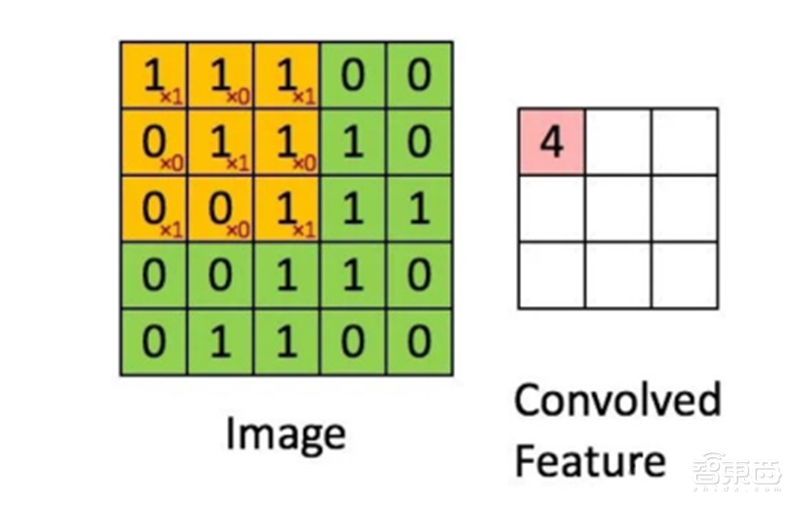
▲图卷积示意图
现实中更多重要的数据集都是用图的形式存储的,例如社交网络信息、 知识图谱、 蛋白质网络、 万维网等等。这些图网络的形式并不像图像,是排列整齐的矩阵形式,而是非结构化的信息,那有没有类似图像领域的卷积一样,有一个通用的范式来进行图特征的抽取呢?这就是图卷积在图卷积网络中的意义。对于大多数图模型,有一种类似通式的存在,这些模型统称图卷积网络。因此可以说,图卷积是处理非结构化数据的大利器,随着这方面研究的逐步深入,人类对知识领域的处理必将不再局限于结构化数据,会有更多的目光转向这一存在范围更加广泛,涵盖意义更为丰富的知识领域。
二、 深度学习
深度学习是近 10 年机器学习领域发展最快的一个分支, 由于其重要性,三位教授(Geoffrey Hinton、 Yann Lecun、 Yoshua Bengio)因此同获图灵奖。深度学习模型的发展可以追溯到 1958 年的感知机( Perceptron)。 1943 年神经网络就已经出现雏形(源自NeuroScience), 1958 年研究认知的心理学家 Frank 发明了感知机,当时掀起一股热潮。后来 Marvin Minsky(人工智能大师)和 Seymour Papert 发现感知机的缺陷:不能处理异或回路等非线性问题,以及当时存在计算能力不足以处理大型神经网络的问题。于是整个神经网络的研究进入停滞期。
最近 30 年来取得快速发展。总体来说,主要有 4 条发展脉络:
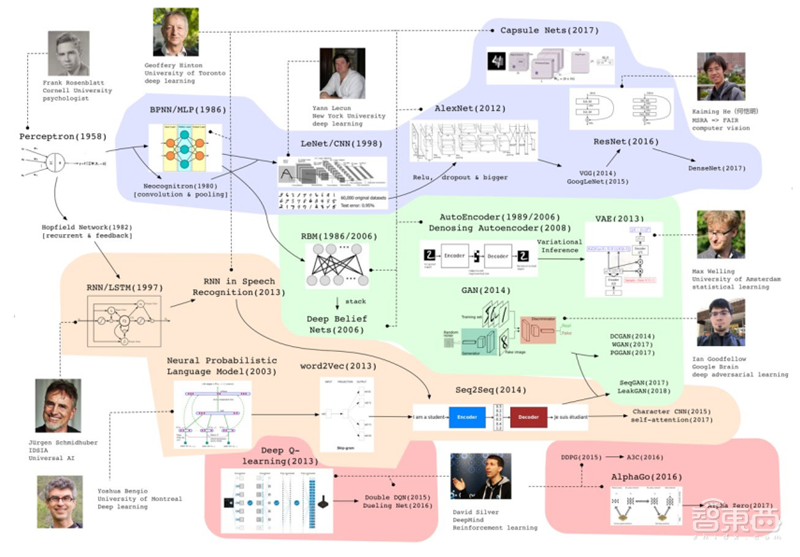
▲深度学习模型最近若干年的重要进展
1、 深度学习近期重要进展
在过去几年中,深度学习改变了整个人工智能的发展。深度学习技术已经开始在医疗保健,金融,人力资源,零售,地震检测和自动驾驶汽车等领域的应用程序中出现。至于现有的成果表现也一直在稳步提高。本小节将介绍深度学习近期的一些重要进展。
2018年三大进展:
BERT 模型 。 BERT 的全称是 Bidirectional Encoder Representation from Transformers,是基于深度双向Transformer 的预训练模型,能用所有层的上下文语境训练深度双向表征。自 Google 在 2018年公布 BERT 在 11 项 nlp 任务中的卓越表现后, BERT 就成为 NLP 领域大火的模型。
视频到视频合成(Video-to-Video Synthesis) 。 我们通常习惯由图形引擎创建的模拟器和视频游戏进行环境交互。虽然令人印象深刻,但经典方法的成本很高,因为必须精心指定场景几何、材料、照明和其他参数。一个很好的问题是:是否可以使用例如深度学习技术自动构建这些环境。 NVIDIA 的研究人员解决了这个问题。他们的目标是在源视频和输出视频之间提供映射功能,精确描绘输入内容。作者将其建模为分布匹配问题,其目标是使自动创建视频的条件分布尽可能接近实际视频的条件分布。为实现这一目标,他们建立了一个基于生成对抗网络(GAN)的模型。在 GAN 框架内的关键思想是,生成器试图产生真实的合成数据,使得鉴别器无法区分真实数据和合成数据。他们定义了一个时空学习目标,旨在实现暂时连贯的视频。
图网络(Graph Network) 。 DeepMind 联合谷歌大脑、MIT 等机构 27 位作者发表重磅论文“Relational inductive biases, deep learning, and graph networks”,提出“图网络”(Graph network),将端到端学习与归纳推理相结合,有望解决深度学习无法进行关系推理的问题。 作者认为组合泛化是人工智能实现与人类相似能力的首要任务,而结构化表示和计算是实现这一目标的关键,实现这个目标的关键是结构化的表示数据和计算。该论文讨论了图网络如何支持关系推理和组合泛化,为更复杂的、可解释的和灵活的推理模式奠定基础。
2019年三大进展:
XLNet 模型 。 XLNet 是 CMU 与谷歌大脑提出的全新 NLP 模型,在 20 个任务上超过了 BERT 的表现,并在 18 个任务上取得了当前最佳效果,包括机器问答、自然语言推断、情感分析和文档排序。
MoCo 。何恺明在其工作“Momentum Contrast for Unsupervised Visual Representation Learning”中提出了动量对比度(MoCo)用于无监督的视觉表示学习。 从作为字典查找的对比学习的角度来看,作者构建了一个带有队列和移动平均编码器的动态字典。这样就可以实时构建大型且一致的词典,从而促进对比性的无监督学习。 MoCo 在 ImageNet 分类的通用线性协议下提供了竞争性的结果。更重要的是, MoCo 学习到的表示将转移到下游任务。 MoCo 可以胜过在 PASCAL VOC, COCO 和其他数据集上进行监督的预训练对等任务中的检测/细分任务,有时会大大超过它。这表明在许多视觉任务中,无监督和有监督的表征学习之间的鸿沟已被大大消除。
DL System 2 。 Yoshua Bengio在NeuIPS 2019上的报告“FROM SYSTEM 1 DEEP LEARNING TO SYSTEM2 DEEP LEARNING”讨论了深度学习发展的方向,引起了广泛关注, 清华大学的唐杰教授对其进行了深度解读。
三、人才
1、 学者情况概览
学者地图用于描述特定领域学者的分布情况,对于进行学者调查、分析各地区竞争力现况尤为重要,下图为机器学习领域全球学者分布情况:
▲机器学习领域全球学者分布
地图根据学者当前就职机构地理位置进行绘制,其中颜色越深表示学者越集中。 从该地图可以看出,美国的人才数量遥遥领先且主要分布在其东西海岸;欧洲中西部也有较多的人才分布;亚洲的人才主要分布于我国东部及日韩地区;其他诸如非洲、南美洲等地区的学者非常稀少;机器学习领域的人才分布与各地区的科技、经济实力情况大体一致。此外,在性别比例方面,机器学习领域中男性学者占比 89.8%,女性学者占比 10.2%,男性学者占比远高于女性学者。
h-index 分布 。 机器学习学者的 h-index 分布如下图所示,大部分学者的 h-index 都在 30 以上,其中 hindex 小于 30 的人数最多,有 591 人, 占比 29.1%。
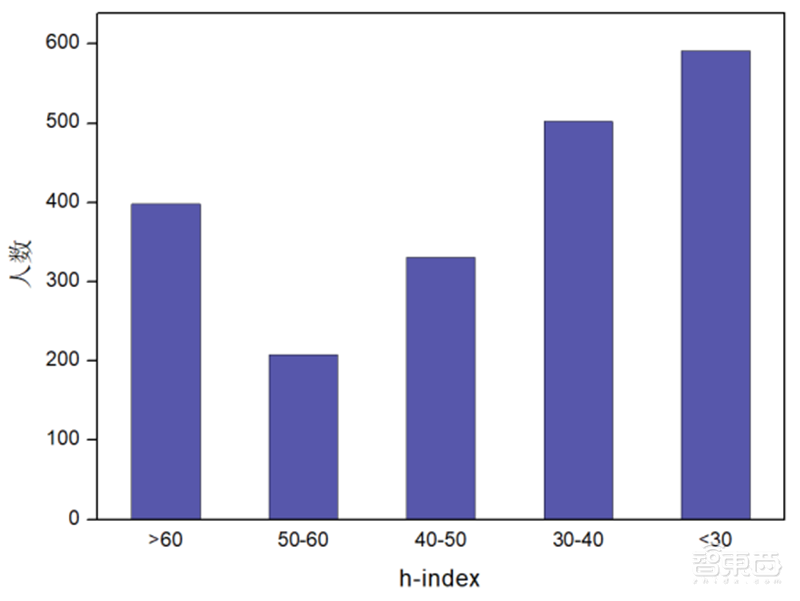
▲机器学习领域学者 h-index 分布
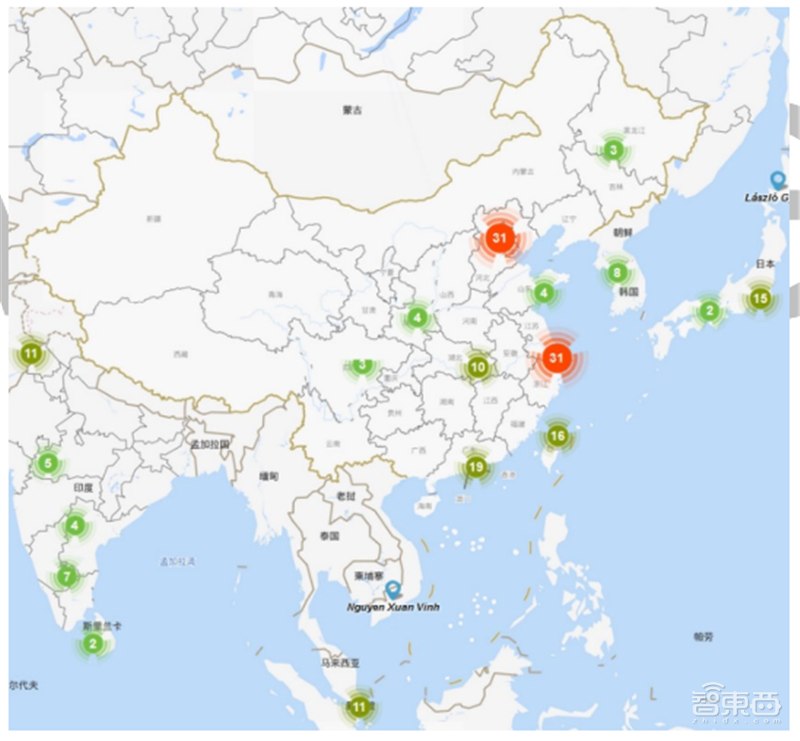
▲机器学习领域中国学者分布
我国专家学者在机器学习领域的分布如上图所示。通过上图我们可以发现,京津地区在本领域的人才数量最多,其次是长三角和珠三角地区,相比之下,内陆地区的人才较为匮乏,这种分布与区位因素和经济水平情况不无关系。同时,通过观察中国周边国家的学者数量情况,特别是与日韩、东南亚等亚洲国家相比,中国在机器学习领域学者数量较多。
中国与其他国家在机器学习的合作情况可以根据 AMiner 数据平台分析得到,通过统计论文中作者的单位信息,将作者映射到各个国家中,进而统计中国与各国之间合作论文的数量,并按照合作论文发表数量从高到低进行了排序,如下表所示。
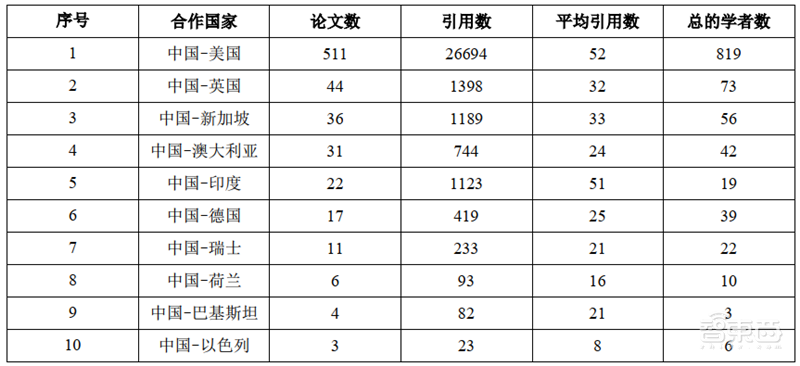
▲机器学习领域中国与各国合作论文情况
从上表数据可以看出,中美合作的论文数、引用数、平均引用数、学者数遥遥领先,表明中美间在机器学习领域合作之密切;从地域角度看,中国与欧洲的合作非常广泛,前 10名合作关系里中欧合作共占 4 席;中国与印度合作的论文数虽然不是最多,但是平均引用数依然位列第二,说明在合作质量上中印合作也达到了较高的水平。
四、 行业应用
1、 金融行业应用
欺诈检测 。 使用机器学习进行欺诈检测时,先收集历史数据并将数据分割成三个不同的部分,然后用训练集对机器学习模型进行训练,以预测欺诈概率。最后建立模型,预测数据集中的欺诈或异常情况。与传统检测相比,这种欺诈检测方法所用的时间更少。由于目前机器学习的应用量还很小,仍然处于成长期,所以它会在几年内进一步发展,从而检测出复杂的欺诈行为。
股票市场预测 。 当今,股票市场俨然已成为大家关注的热点, 但是,如果不了解股票运作方式和当前趋势,要想击败市场则非常困难。随着机器学习的使用,股票预测变得相当简单。这些机器学习算法会利用公司的历史数据,如资产负债表、损益表等,对它们进行分析,并找出关系到公司未来发展的有意义的迹象。
财资部(Treasury) /客户关系管理(CRM) /现货交易(Spot Transactions) 。 客户关系管理(CRM)在小额银行业务中占有十分突出的地位,但在银行内部的财资空间却没什么作用。因为财资部有自己的产品群,如外汇、期权、掉期交易(Swaps)、远期交易(Forwards)以及更为重要的现货交易(Spots)。线上交易需要结合这些产品的复杂程度、客户风险、市场与经济行为以及信用记录信息,这对银行来说几乎是一个遥远的梦想。
聊天机器人/私人财务助理 。 聊天机器人可以担当财务顾问,成为个人财务指南, 可以跟踪开支,提供从财产投资到新车消费方面的建议。财务机器人还可以把复杂的金融术语转换成通俗易懂的语言,更易于沟通。一家名为 Kasisto 的公司的聊天机器人就能处理各种客户请求,如客户通知、转账、支票存款、查询、常见问题解答与搜索、内容分发渠道、客户支持、优惠提醒等。
2、自动驾驶
将汽车内外传感器的数据进行融合,借此评估驾驶员情况、进行驾驶场景分类,都要用到机器学习。 自动驾驶汽车的设计制造面临着诸多挑战,如今,各大公司已经广泛采用机器学习寻找相应的解决方案。汽车中的 ECU(电子控制单元)已经整合了传感器数据处理,如何充分利用机器学习完成新的任务,变得至关重要。潜在的应用包括将汽车内外传感器的数据进行融合,借此评估驾驶员情况、进行驾驶场景分类。这些传感器包括像激光雷达,雷达,摄像头或者是物联网。
车载信息娱乐系统所运行的应用,能从传感器数据融合系统中获取数据。举个例子,如果系统察觉驾驶员发生状况,有能力把车开到医院。基于机器学习的应用,还包括对驾驶员的语言和手势识别以及语言翻译。相关的算法被分类为非监督和监督算法。它们两者的区别在于学习的方式。
在自动驾驶汽车上,机器学习算法的一个主要任务是持续渲染周围的环境,以及预测可能发生的变化。这些任务可以分为四个子任务: 目标检测、 目标识别或分类、 目标定位、 运动预测。
机器学习算法可以简单地分为 4 类:决策矩阵算法、聚类算法、模式识别算法和回归算法。可以利用一类机器学习算法来完成两个以上的子任务。例如,回归算法能够用于物体定位和目标识别或者是运动预测。
▲自动驾驶目标识别、运动预测
3、 健康和医疗
为了更好地了解人工智能和机器学习正如何改变医疗保健行业, 我们通过一些具体案例,并且这些案例可以有力证明这些前沿技术的实用价值。
判断发展中国家的结核病情况。识别图像中的模式(Pattern)是现有人工智能系统中最强有力的一点,研究人员现在正在训练人工智能检查胸部 x 光片, 识别结核病。这项技术可以为缺乏放射学家的结核病流行地区带来有效的筛查和评估手段。
一种治疗退伍军人创伤后应激障碍(PTSD) 的人工智能 。退伍军人创伤后成长计划与 IBM Watson 合作使用人工智能和分析技术,以确保更多患有创伤后应激障碍的退伍军人能够完成心理治疗。使用这些技术,他们的完成率从不到 10%上升到 73%。根据退伍军人事务部的统计, 80%的患有创伤后应激障碍的退伍军人在确诊后一年内完成治疗计划,然后康复。在 300 万阿富汗和伊拉克战争老兵中,大约五分之一患有创伤后应激障碍。
检测脑出血 。以色列医疗技术公司 MedyMatch 和 IBM Watson Health 正在使用人工智能,通过检测颅内出血,帮助医院急诊室的医生更有效地治疗中风和头部外伤患者。 AI 系统使用临床洞察力(clinical insight)、深度学习、患者数据和机器视觉来自动标记潜在的脑出血,以供医生检查。
优化管理工作流程并消除等待时间。行政和助理工作是 AI 起作用的主要领域。埃森哲表示,语音到文本转录等省时的工作流功能有可能替代为医疗专业人员订购测试和处方以及在图表中写笔记等任务–任何涉及非患者护理的任务。这相当于节省了 17%的医生工作时间和 51%的注册护士工作时间。
检测阿尔茨海默病 。现在,人工智能机器人只需要不到一分钟的时间,就可以根据语音模式和声音来诊断阿尔茨海默氏病,准确率达到 82%,而且这种准确率还在不断提高。人工智能系统可以处理单词之间的停顿长度、处理代词优于专有名词的任何偏好、处理过于简单的描述以及语音频率和幅度的变化。所有这些因素对于人类听众来说都很难高精度地记录和检测,但人工智能系统却能够进行客观和可量化的分析。
癌症诊断 。用于检测和诊断癌症的传统方法包括计算机断层扫描(CT) 、磁共振成像(MRI) 、超声和 X 射线。不幸的是,许多癌症无法通过这些技术得到足够准确的诊断,从而可靠地挽救生命。微阵列基因图谱的分析是一种替代方法,但这项技术需要计算很多小时,除非这项技术可以使用 AI 替换。现在已经被证明,斯坦福大学的人工智能诊断算法与由 21 名经委员会认证的皮肤科医生的团队一样有效地从图像中检测潜在的皮肤癌。 Startup Enlitic 正在使用深度学习来检测 CT 图像中的肺癌结节,其算法比作为一个团队工作的专家胸科医生的准确率高 50%。
机器人辅助手术 。 在价值潜力方面,机器人辅助手术是人工智能辅助方向的佼佼者。 AI-enabled 机器人技术可以通过集成实时操作矩阵、来自实际手术医生的数据以及来自手术前病历的信息来提高和指导手术器械的精度。事实上,埃森哲报告说,人工智能机器人技术带来的进步缩短了 21%的停留时间。
4、 零售业
IDC 副总裁 Ivano Ortis 最近分享了他的观点“人工智能将把分析带到一个新的水平,并将成为零售创新的基础,这已经得到了全球半数零售商的认可。人工智能可以实现规模化、自动化和前所未有的精度,当适用于超细微客户细分和上下文交互的时候,可推动客户体验”。
鉴于人工智能和机器学习的能力,很容易看到人工智能和机器学习是如何成为零售商强大的工具。现在,计算机可以读取、倾听和了解数据,从数据中进行学习,立即且准确地推荐下一个最佳动作,而不需要明确的编程。这对那些希望能够准确预测需求、预期客户行为、优化和个性化客户体验的零售商来说是一个福音。
零售商正在通过机器学习结合物联网技术来预测需求,优化商店业务并减轻员工负担。
基于店内摄像头检测提供个性化的广告,承担店员部分的半手动的、通过在平板电脑或者触屏终端设备查看客户的消费记录。
零售商可以监控排队结账的等候时间,以了解个别店面的流量和商店销售效率,然后进行分类和调整店面布局来实现购物篮、满意度和销售的最大化。
系统现在可以通过把计划调整为按需活动,来识别和预测客户行为,改善员工生产效率。
摄像头系统可以在店内员工之前检测易腐产品的新鲜状态。
实体店正在实现很多操作任务的自动化,例如设置货架定价,确定产品分类和混合,优化促销等。
店内应用可以显示客户在特定通道停留了多长时间,根据个人消费记录和偏好数据,提供有针对性的优惠和建议(通过他/她的移动设备) 。
机器学习可以帮助减轻推动利用可用数据所需的分析任务。当部署了一个全公司范围的、实施的分析平台时,这将成为所有公司职能优化决策所依赖的事实来源。
5、 制造业
与自动驾驶汽车一样,随着物联网的发展,制造业企业可以从安置在生产线各环节的传感器收集大量的生产数据。
然而,这些数据并没有被充分利用。随着从复杂系统收集到众多参数的数据,数据分析变成了一项艰巨的任务。机器学习在制造业中的最大应用将是异常检测。
据统计,到 2030 年,全球的淡水需求预计将超过供应近 40%。为协助各企业实现净零水循环使用的目标,美国水处理公司 Ecolab(艺康集团)正通过包括 Azure 和 Dynamics CRM Online 在内的微软云平台帮助全球企业实现可持续运营。
与全球各地数以千计传感器相连的云平台能收集实时用水数据,并通过机器学习和商业智能分析全球各地的生产用水运营解决方案,不仅提高效率,还能降低水、能源消耗及运营成本。
尽管在这个领域之前已经进行过一些分析尝试,未来将会有更多机器学习通过监督学习和建模来预测风险和失败。
此外, 机器学习也将推动工业自动化的实现,通过观察生产线和数据流来学习,并能够精确优化生产过程,降低生产成本,加快生产周期,从而节省人工分析数据的时间成本和资金成本。
五、 趋势
技术趋势分析描述了技术的出现、变迁和消亡的全过程,可以帮助研究人员理解领域的研究历史和现状,快速识别研究的前沿热点问题。 图中每条色带表示一个话题,其宽度表示该术语在当年的热度,与当年该话题的论文数量呈正相关, 每一年份中按照其热度由高到低进行排序。 通过技术趋势分析可以发现当前该领域的热点研究话题 Top10 是: Neural Network、 Machine Learning、 Deep Neural Networks、 Deep Learning、Support Vector Machine、 Reinforcement Learning、 Feature Selection、 Deci Tree、 Data Mining、Artificial Neural Network。
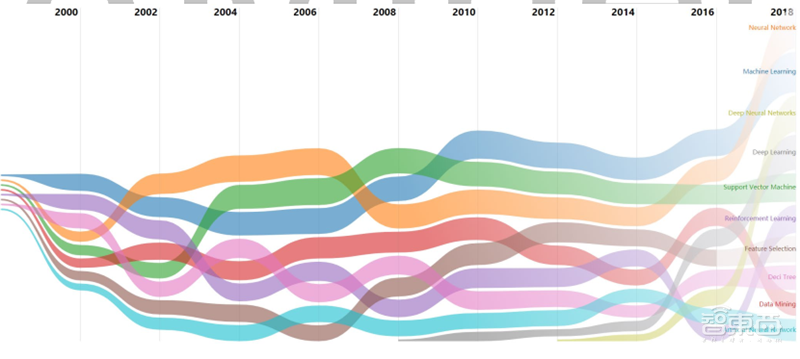
▲机器学习技术趋势
根据技术趋势分析我们可以发现, 该领域当前最热门的话题是 Neural Network,从全局热度来看, Neural Network 一直保持着较高的话题热度, 2002-2006 年期间保持着最高的热度并于 2018 年重登榜首。
智东西认为, 机器学习的处理系统和算法是主要通过找出数据里隐藏的模式进而做出预测的识别模式,是人工智能的一个重要子领域。 虽然机器学习只是人工智能的一个子集,但近些年机器学习技术的火爆,机器学习依然成为人工智能的代名词。 在过去几年中,包括深度学习在内的机器学习改变了整个人工智能的发展,在金融、自动驾驶、医疗、零售和制造业等行业已经开始产生了重要影响,按照现在的趋势,几年后以机器学习为代表的人工智能技术就将给人类社会带来一场广泛而深刻的变革。
