







智东西(公众号:zhidxcom)
文 | 心缘
近两年,越来越多企业在思考如何应用人工智能(AI)挖掘更多数据价值。然而训练AI需要大量数据,这些数据却越来越难获得。
即便是信息化起步早、数据丰富的金融业,同样饱受高质量数据缺失的困扰。
金融业看似数据多,实则许多数据未经专业标注,有效数据非常少,大量数据的控制权分散在不同机构、部门,“数据孤岛”问题严重,加之数据隐私保护立法日趋严苛,数据交换与共享受到重重限制。
高度智能化和高度隐私安全如何兼得?难道只有拥有海量数据的机构,才能享受AI带来的效率和成本优化?
产学界探讨的解局之法,逐渐聚焦于一个新兴技术——联邦学习(Federated Learning)。
联邦学习能让多方在数据不离本地的前提下,协作建立一个共享模型,它比任何一方单独训练出的AI模型都更精准,同时不会侵犯隐私。
这一技术在国内的先行者是金融界的“科技代表”微众银行,它率先将联邦学习用在解决跨部门、跨企业数据融合问题,并借助从腾讯云调用的NVIDIA GPU资源,用联邦学习技术解决了70%以上无历史信用信息的小微企业贷款难问题,支撑的企业贷款发放量已超过10亿。
作为国内首家民营银行、互联网银行,微众银行一直积极通过人工智能、大数据、区块链等科技创新,推动普惠金融落地。由国际知名AI科学家杨强教授领导的微众银行AI团队,对于传统机器学习及联邦学习在金融领域的研究和落地应用均有着深厚积累。
如今,数据孤岛、隐私保护已是传统行业应用AI所面临的共性问题。
微众摸索出的方法,对于传统金融机构以及其他走向智能化的企业来说,同样有借鉴意义。
一、消弭数据鸿沟,微众的另辟蹊径之道
为更充分了解联邦学习的技术难点、应用价值和落地经验,近日,我们与微众银行人工智能部高级算法研究员黄启军进行了深入交流。
首要问题即是,联邦学习方法怎么兼顾数据聚合、数据保护和性能提升?
黄启军告诉我们,联邦学习与传统机器学习最大的区别,就是交换的数据是密态的。
传统机器学习通常将数据移动到云端数据中心来训练模型,但遇到隐私合规问题时,这类方法就行不通了。
联邦学习不移动各方数据,通过信息与模型参数的加密交换,结合多方数据优势构建一个虚拟的共有模型,这个虚拟模型等同或接近直接把各方数据聚合在一起所训练出的模型。
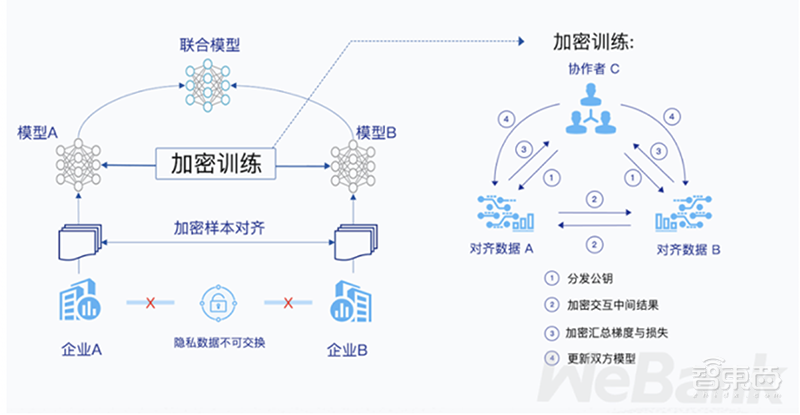 ▲联邦学习系统构架
▲联邦学习系统构架
微众银行提出了三种进行联邦学习的模式:横向联邦学习、纵向联邦学习、联邦迁移学习。
横向联邦学习的各参与方共同用户少,但共同用户特征多。例如谷歌在每个手机上单独建模,然后把模型参数加密后传到云端,对通用模型进行更新,再传送给各个手机。
纵向联邦学习正好相反,各参与方的共同用户特征少,但共同用户多。比如银行A有用户的信用评级,电商B有同一批用户的购买记录,两者交换加密后的模型参数,就能合成一个更完备的模型。
联邦迁移学习适用于各参与方既没有共同用户,也缺少共同特征。不过这个方法还处于研究阶段,实际工业应用有待进一步开发。
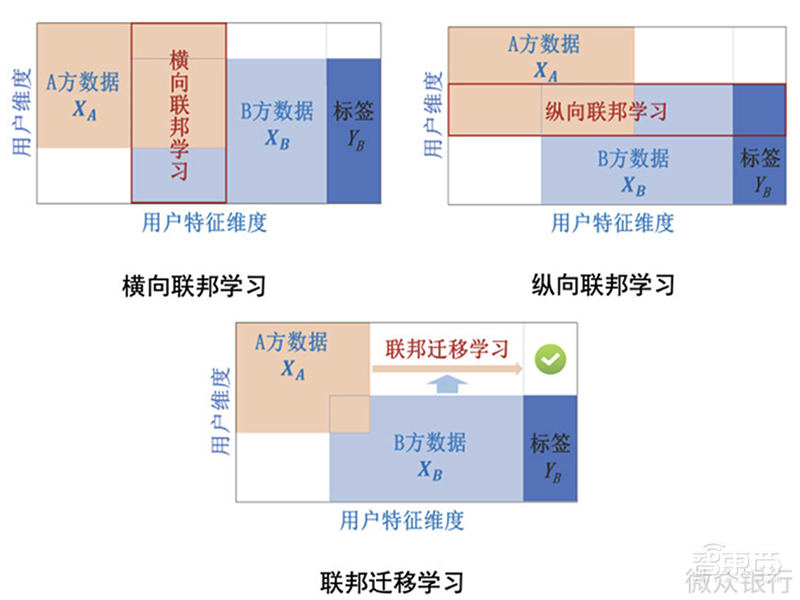 ▲联邦学习的分类
▲联邦学习的分类
从理论来看,联邦学习能实现多方共赢。但光谈理论还不够,怎么让它在实际应用场景中发挥更多作用呢?
从2018年到2019年初,微众银行AI团队逐步搭建起理论研究、工具软件、技术标准、行业应用的多层级联邦学习生态框架,并吸引腾讯、华为、京东、平安等生态合作伙伴加入。
2019年1月,微众推出全球首个工业级联邦学习开源框架FATE(Federated AI Technology Enabler),开始将联邦学习应用于金融业务。
这个框架提供一系列“开箱即用”的联邦学习算法,以及完善的建模辅助和模型评估工具,还有一套友好的跨域交互信息管理方案,解决了联邦学习信息安全审计难的问题。
也就是说,想应用联邦学习的企业,无需在底层技术方面投入过多精力,就能享受到在保护数据隐私的前提下,通过多方数据联合带来的业务水平提升。
信贷风控、反洗钱、客户权益定价……自FATE推出后,它在金融领域的落地愈发深入。
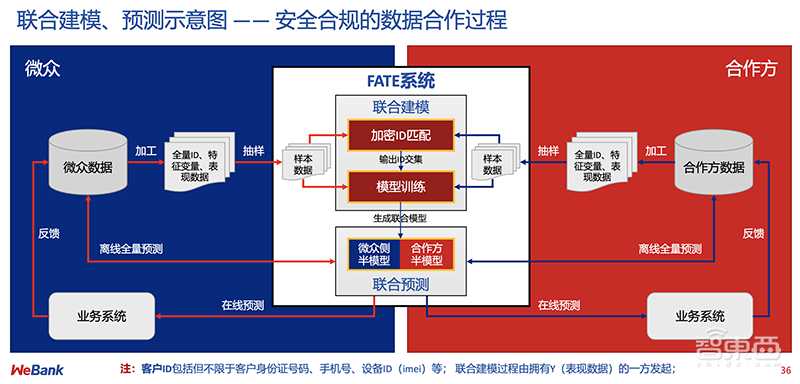 ▲基于FATE的联合建模
▲基于FATE的联合建模
2019年6月25日,微众银行成为Linux基金会黄金会员中唯一的金融机构,并将FATE项目贡献给Linux基金会。如今,FATE开源社群已成为业界规模最大的联邦学习开发者社区,吸纳了128家机构企业机构和145所高校应用和共建。
据黄启军介绍,此前GitHub上的联邦学习框架大多属于横向联邦学习方向,而在纵向联邦学习方面达到可用级别的框架,唯有FATE。
由于联邦学习基础平台和架构不同于其他平台,微众特意做了一个分布式计算和存储的框架,还支持跨站点的传输。
当前FATE已在单机上成功实现与TensorFlow、PyTorch等深度学习框架的对接,将来还计划尝试分布式系统。
二、加密带来数据暴增,微众联邦学习如何抗住重压?
无论是过硬的算法与安全技术实力,还是丰富的工程经验,微众银行都是国内联邦学习领域的翘楚。
但推进联邦学习落地的道路并非一帆风顺。联邦学习交换加密状态下,数据体积暴增,致使它需要更高的计算和通信能力。
计算方面,传统机器学习有32-bit芯片指令支持,而联邦学习的Paillier/RSA算法依赖2048-bit甚至更长的大整数模幂、模乘等复杂运算。
传输方面,传统机器学习的参数聚合使用内网传输,而联邦学习给数据加密后体积变大30倍以上,还要经多轮传输。

如果计算和通信能力不足,算法性能就会损失,那么,微众是怎么考量加速计算的基础架构,来支撑暴涨的计算和通信需求呢?
我们先来看看联邦学习算法的几个特点:
(1)计算高度并行:数据密态计算,不同数据计算互不影响;
(2)重复轻量级运算:计算公式不复杂,但重复执行次数巨大;
(3)计算密集型任务:数据I/O时间不到计算时间的0.1%;
(4)批量大数据:数据批量产生,并且数据量巨大。
这些特性,均与擅长多线程并行计算的GPU相当契合。
但只关注加速方案的性能还不够,操作灵活性、便利性和稳定性同样需要考量。
通常企业选择基础架构有两种方式,本地部署或私有云服务对数据安全的把控度更高,而云端服务可缩短开发周期、弹性配置计算资源、降低初期启动成本。
微众联邦学习目前采用的方案,是通过腾讯云平台基于NVIDIA Tesla V100 GPU,结合GPU高速互联技术NVLink,来加速联邦学习计算任务。
“联邦学习对算力要求高,只要硬件方案价格合理,能满足对加速任务的需求,我们都愿意尝试。”黄启军说。
在他看来,NVIDIA V100已经是非常成熟的方案,使用效果相当不错。经测试,相比使用单个英特尔至强6100系列CPU,使用1台8卡GPU服务器可以替换20台以上CPU服务器。
不仅如此,黄启军表示,NVIDIA的软件对微众联邦学习同样有很大帮助。
NVIDIA软件平台提供了丰富的机器学习和深度学习开源库。在研究联邦学习期间,黄启军他们曾重点参考过NVIDIA实验室中主要做大数运算的CGBN库。
此外,NVIDIA还提供有完整的GPU编程开发环境和各种满足需求的开发工具,并在系统设计和优化方面给予了很多指导与参考。黄启军认为,这对降低开发成本颇有帮助。
例如写完算法后,如果发现GPU加速效果不如预期,可以使用SDK中自带的Profile工具去做详细分析,它不仅会直接告诉你问题所在,比如把寄存器用的太过了,而且会引导你一步一步去解决问题,比如怎么优化寄存器的应用、怎么平衡并行和寄存器占用的关系。
黄启军回忆道,问题解决后,“效果立即就有2-3倍的提升。”
在NVIDIA GPU平台的基础上,微众联邦学习还提出了三种优化方法,进一步挖掘GPU的加速潜力。
第一步,基于分治思想做元素级并行,通过递归将大整数乘法分解成可并行的小整数乘法;
第二步,结合平方乘算法和蒙哥马利算法,降低运算复杂度,并完全避免了取模运算;
第三步,用中间剩余定理减小中间计算结果。
优化后评测结果显示,相对于传统方法,星云Clustar基于GPU所做的优化方案,将同态加密效率提升了5.8倍,将同态解密效率提升了5.93倍,将密态乘法效率提升了31.4倍,将密态加法的效率提升了419倍。
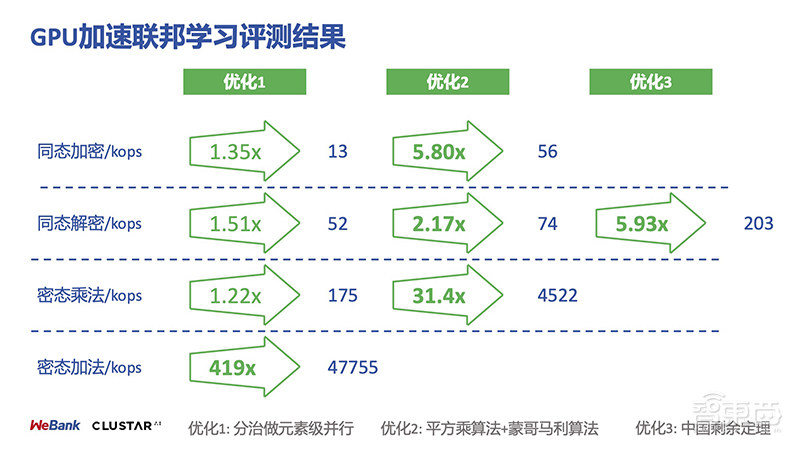 ▲GPU加速联邦学习优化方案效果
▲GPU加速联邦学习优化方案效果
黄启军表示,微众银行AI团队还希望进一步探索更高的算力支撑。
三、从金融防控到精准医疗,联邦学习应用日趋丰富
继在学术界掀起研究热潮后,联邦学习技术也逐渐渗透到更多行业应用中,解决金融、零售、医疗等典型AI应用场景中的有效数据少和数据合规难题,推动跨领域的数据共享与融合。
1、金融风控:破解小微企业贷款难题
在金融领域,联邦学习能帮助显著改善风险量化能力、降低整体金融产品价格。
比如小微企业贷款,银行一般只有征信报告和部分国家政策允许获得的税务数据,但70%以上的小微企业是白户,没有任何征信记录和税务记录。发票对评估企业信用风险很有帮助,但当前70%-80%的发票数据均由税控发票机登记,数据比较敏感,不方便直接披露给银行。
 ▲小微企业信贷风险管理难题
▲小微企业信贷风险管理难题
基于保证原始数据不交换的前提,微众银行将贷款客户信用数据与发票登记信息进行联合建模,优化风控模型,解决了70%以上无历史信用信息的小微企业贷款难问题。目前通过这种联合建模所支撑的企业贷款发放量已超过10亿。
微众银行还牵手腾讯云神盾沙箱,帮助对数据依赖强的机构在保护数据隐私的前提下进一步挖掘数据价值,推进AI落地应用。
2、精准引流:提升信息和资源匹配的效率
智慧零售中的个性化产品推荐、定向广告投放等服务,对吸引客流、培养用户习惯至关重要。但在实际应用中,这些业务涉及的数据特征通常分散在不同部门或企业。
比如银行有购买能力的特征,社交平台拥有用户个人偏好特征,电商平台则拥有产品特点的特征。如果将这些数据结合,就能构建更精准的营销模型、推荐模型,但隐私问题又是迈不过的门槛,联邦学习则成为可行之径。
在保护三方数据互不交流的基础上,联邦学习构建比单独建模更精准的AI模型。微众银行曾通过联邦学习将采购备货准确率提升21.4%。
3、智慧医疗:突破数据标注缺失瓶颈
医疗领域的数据具有高度隐私、数据分散的特点,单一组织往往缺乏足够样本。
数据标注也严重缺失。有人曾估计,把医疗数据放在第三方公司标注,需要动用1万人用长达10年的时间,才能集齐有效的数据。
联邦学习可以在保证不进行数据交换的前提下,聚集多家医院、多个部门的病患数据资源构建一个共享模型,其效果要远远超过各医院只用自己的数据集训练出的AI模型,各医院共同获益。
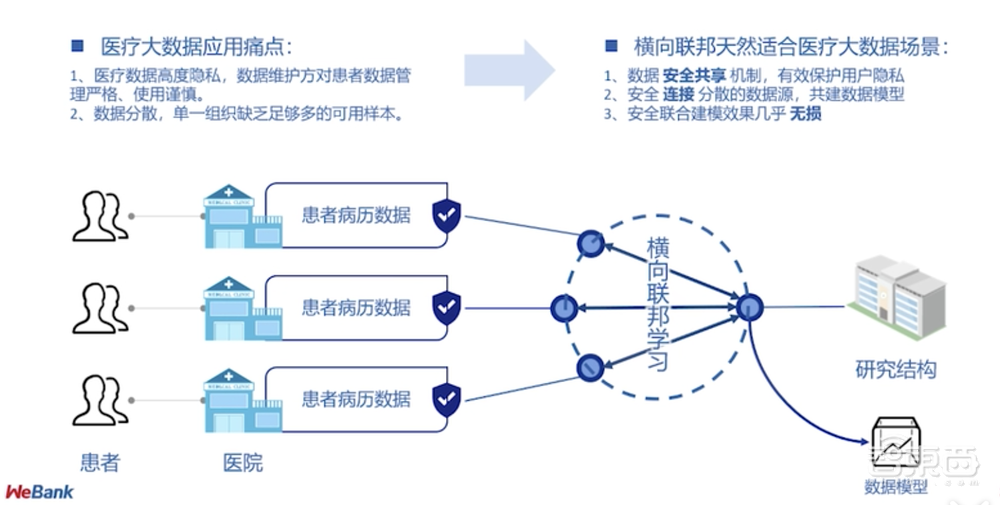 ▲联邦学习解决医疗大数据痛点
▲联邦学习解决医疗大数据痛点
结语:联邦学习,普惠AI行之有效的新路径
在人工智能落地更多行业的同时,隐私安全问题也如影随形,兼顾数据隐私保护和优化AI模型的联邦学习方法,正蕴藏巨大的发展潜力。
在NVIDIA V100 GPU的加速下,微众联邦学习已陆续解锁智慧出行、工业质检等更多AI应用场景,从技术角度合规地打通数据孤岛。
如今联邦学习刚踏入批量落地的新阶段,更多企业和学术机构正加入联邦学习生态,随着安全合规、防御攻击、算法效率、联盟机制的进一步完善,联邦学习将推动AI更健康的落地与赋能。
