








芯东西(ID:aichip001)
编 | 温淑
芯东西5月19日消息,近日,位于瑞士苏黎世的IBM欧洲研发中心研发出一种基于相变存储器(PCM)的非·冯诺依曼架构芯片技术,能像人脑一样在存储中执行计算任务,以超低功耗实现复杂且准确的深度神经网络推理。
IBM研究人员用ResNet分类网络进行实验,在将训练后的权重映射到PCM突触后,在CIFAR-10数据集上和准确率达到93.7%,在ImageNet基准上的top-1准确率达到71.6%。
此外,研究人员通过一种补偿技术,可将原型芯片在1天内的测试准确率保持在92.6%以上,据悉,这是迄今为止任何模拟电阻式存储硬件在CIFAR-10数据集上所产生的最高分类准确率。

未来,这项技术或可用于智能相机、AR眼镜、无人机等设备,使这些设备在更少的能耗下提供更快的计算速度。
这项研究发表在科学期刊《Nature Communications》上,论文名称为《使用计算相变存储器进行精确的深度神经网络推理(Accurate deep neural network inference using computational phase-change memory)》。
论文链接:
https://www.nature.com/articles/s41467-020-16108-9

一、IBM新架构:像人脑一样存储和计算,能耗更低
深层神经网络(DNN)可以用于完成图像识别、语音识别等认知任务,是一项重要的AI技术。但是,现有的硬件限制了深层神经网络的性能和能效。
目前,深层神经网络大多在冯·诺伊曼架构上运行,谷歌的张量处理器(tensor processing unit)、NVIDIA的GPU Tesla T4均属于冯·诺伊曼架构。
冯·诺伊曼架构将存储器和处理器分开,处理过程中数据在存储单元和处理单元之间不断传输转移。拥有大型数据中心的公司往往需要通过增加服务器数量来满足更高的处理要求,按照这种方法,随着运算量不断增多,深度学习任务的能耗也不断攀升,很多公司意识到,这种通过搭建更多发电装置来解决能耗问题的做法既不经济也不可持续。
有些公司试图用云计算来解决这个问题。云计算可以实现更快的处理过程,有助于提升深度神经网络性能。但是,云计算面临着数据隐私、响应延迟、服务成本等问题,另外,在互联网连接质量较差的地区,云计算的性能会被削弱。
IBM研究中心提出一种基于相变存储器(PCM,phase-change memory)的非冯·诺伊曼架构。

▲位于瑞士苏黎世的IBM欧洲研发中心的研究人员
就像人的大脑一样,这种架构没有把存储和计算过程分开,因此能耗更低。运行一个ResNet-32分类网络时,PCM核心芯片的能量效率约为11.9 TOPS/W。相变存储器利用特殊材料在晶态、非晶态之间相互转换时表现出的导电性差异来存储数据,具有存取速度快、可靠性高的优势。
二、添加随机噪声,提高非理想条件下的模型准确率
基于上述设想,研究人员用两个神经网络模型作为研究对象,通过添加随机噪声来提高分类网络模型的准确率。
首先,研究人员选用ResNet卷积神经网络(CNN)进行训练。选用两个数据集,用数据集CIFAR-10训练ResNet-32卷积神经网络,用数据集ImageNet训练ResNet-34卷积神经网络。
ResNet-32网络由3个不同的ResNet块组成,每个ResNet块有10个3*3内核。ResNet-32网络包含361722个突触权重,用于分类32*32像素的RGB图像。
ResNet-34网络与ResNet-32网络最大的区别是ResNet块的数量和大小不同、输入和输出通道更多。

▲a:ResNet-32网络,b:ResNet-34网络
然后研究人员对模型添加噪声,并观察噪声对神经网络分类准确率的影响。
用模拟存内计算硬件进行推理时,深度神经网络受网络权重的不准确编程、硬件权重的时间波动等噪声影响,可能会产生误差。因此,可以用添加噪声的方法来模拟非理想的运行状态,以此提高分类模型对模拟混合信号硬件弹性。
研究人员用一个误差项𝛿𝐺𝑙𝑖𝑗代表噪声,𝛿𝐺𝑙𝑖𝑗会使每个突触权重在推理过程的前向迭代(forward pass)中发生扭曲。
研究人员在每次推理过程的前向迭代中增加与𝛿𝐺𝑙𝑖𝑗造成的误差相对应的噪声。他们发现,仅给向前传播算法(forward propagation)中的权重增加噪声就足以达到接近基线的准确率,在反向传播算法(backward propagation)中增加权重并不会改善结果。
为简单起见,假设𝛿𝐺𝑙𝑖𝑗是高斯分布的,这通常是模拟记忆电阻硬件的情况。
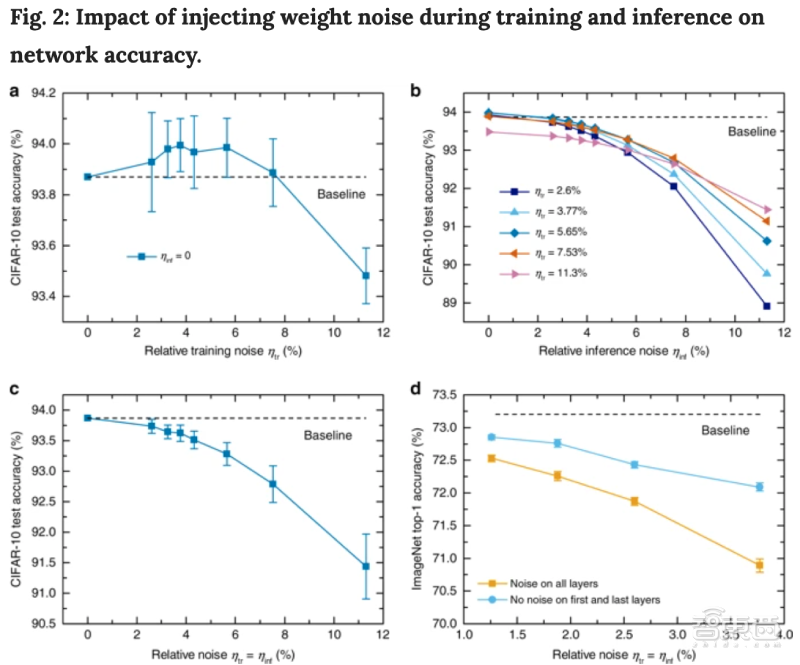
▲在训练和推理过程中添加噪声对网络精度的影响。a.不引入权重扰动,噪声输入量不同时,ResNet-32分类网络在CIFAR-10上准确度;b.推理过程中,用不同噪声输入量进行训练的神经网络对权重扰动的容忍度;c.d.对于给定的权重扰动值,噪声输入量与其相同时,模型分类准确率最高。
在不添加权重噪声时,在CIFAR-10数据集上,ResNet-32卷积神经网络分类准确率在噪声输入量Ntr为8%时接近基线准确率,基线准确率为93.87%。
与ResNet-32分类相比,在ImageNet top-1标准下,ResNet-34卷积神经网络对添加噪声的反应更为灵敏。在所有层都添加噪声后,准确率从基线下降超过0.5%,相对噪声下降超过1.2%。
根据之前的研究,许多网络压缩技术允许第一层和最后一层有更高的准确率。为了简化过程,研究人员去除了第一个卷积层和最后一个全连接层中的噪声。训练后,ResNet-34卷积神经网络的分类准确率可提升1%以上。
三、将权重转移至PCM突触,进行高精度编程
为了验证上述训练方法,研究人员在一个原型多级PCM芯片上进行了实验,该芯片采用90nm CMOS工艺,包含100万个PCM器件。
研究人员设计出一个优化的迭代编程算法,能以高精度编程PCM设备中的电导值。下图a显示了11个代表性编程水平的电导值实验累积分布。下图b提取这些标准差,并用目标电导的多项式函数(图a中的曲线)对其进行拟合,测量编程后25s的准确度数值。
在所有水平上,权重转移到PCM突触上的标准差均小于1.2μS,低于此前研究中纳米级PCM阵列中相似范围的一半。
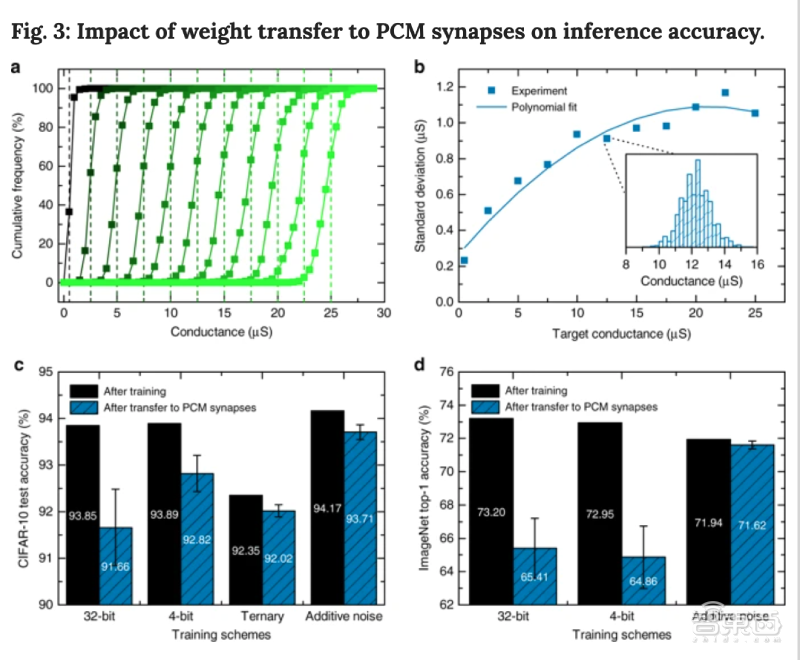
▲权重转移到PCM突触对推理准确率的影响
图c显示了基于CIFAR-10数据集训练ResNet-32分类网络的准确率数值。将权重转移至PCM突触,加噪后ResNet-32分类网络能达到的最高准确率为93.71%。可以看出,权重转移至PCM突触后,经过无限制的标准FP32训练后模型准确率下降最多。与FP32相比,用4-bit数字权重进行训练准确率下降较少,但仍然下降了1%以上。
图d显示了用ImageNet数据集训练ResNet-34分类网络的准确率数值。将权重转移至PCM突触,加噪后ResNet-34分类网络能达到的最高准确率为71.62%。权重转移至PCM突触后,用4-bit数字权重进行训练后模型准确率下降最多,约下降了8%。用无限制的标准FP32训练后模型准确率约下降7.7%。
四、迄今用模拟电阻式存储训练CIFAR-10的最高分类准确率
CIFAR-10训练的网络随时间变化的最终准确率如下图d所示,编程后25秒测得的测试精度为93.75%,与上一张图的结果非常相似。
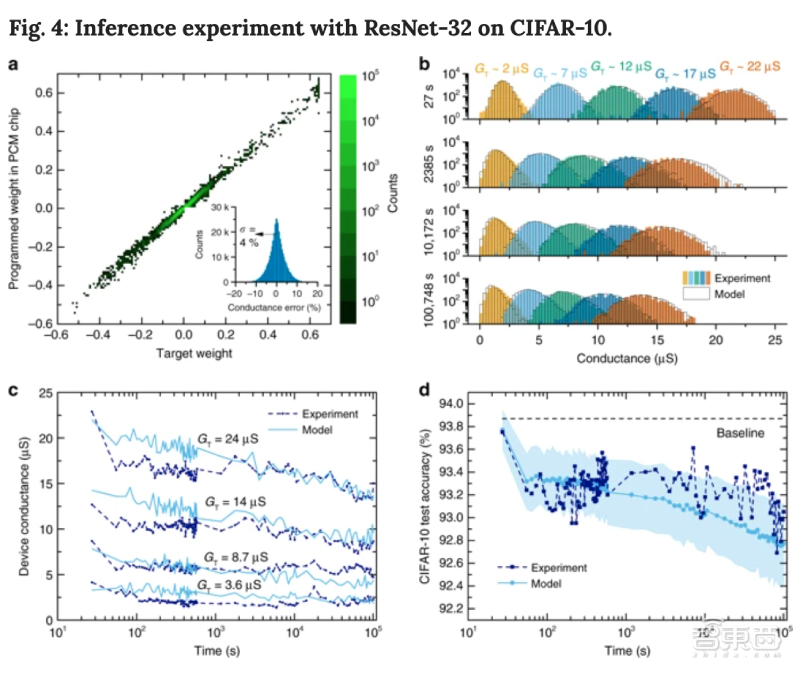
▲在CIFAR-10数据集上进行软硬件推理实验
但如果不对电导漂移(conductance drift)进行补偿,准确率将在约1000秒内迅速下降至10%。这是因为PCM权重的大小随着时间推移而逐渐减小,并会阻止激活在整个网络中的传播。
对此,研究人员选择应用全局漂移补偿(GDC,global drift compensation)程序来补偿漂移的影响。在用测试集进行推理之前,研究人员对每一层进行了简单的GDC处理。
补偿结果如上图d,GDC方法可以使PCM芯片上的测试准确率在1天内保持在92.6%以上,并有效防止全局权重随时间衰减。据悉,这是迄今任何模拟电阻式存储硬件在CIFAR-10数据集上所产生的最高准确率。
五、降低1/f噪声影响,延长高准确率保持时间
虽然GDC可以补偿阵列中的全局电导漂移,但它不能减轻1/f噪声和器件间漂移变化分别对准确率波动和准确率随时间推移单调递减的影响。
为了进一步提高准确率保持时间,研究人员采用了自适应批量归一化统计更新技术(AdaBS),用批量归一化参数在推理过程中校正激活分布。
研究人员分别在ResNet-32分类网络和ResNet-34分类网络上应用了AdaBS技术。
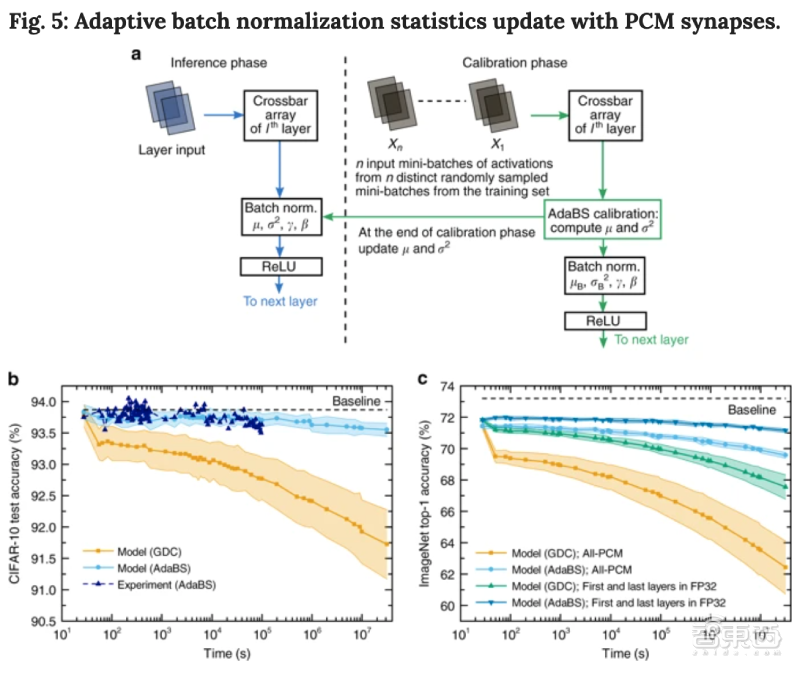
▲用PCM突触更新自适应批量归一化统计数据
数据显示,AdaBS使ResNet-32网络在一天内保持93.5%以上的测试准确率,比GDC提高了0.9%。当用PCM模型推算结果时,模型一年准确率可比GDC方式提高1.8%。
通过仅用ImageNet训练集的0.1%(1300张图像)进行校准,采用和CIFAR-10上相同的AdaBS方法,一年内的准确率相较GDC提到了7%。当第一层和最后一层在数字FP32中实现时,初始准确率提高到71.9%,该技术与AdaBS方法结合使用,可将一年内的准确率保持在71%以上。
不过用这种方式进行推理也存在缺点,由于第一层和最后一层的参数数量且输入大小很少,其执行效率有限,即需在校准阶段付出额外的计算代价。
例如,根据论文,第一层和最后一层包含的网络权重不到3%,在ResNet-34分类网络推理期间负责约3.12%的乘法和累积操作。
结语:不只是分类模型,还能用于LSTM和GAN
相比于传统的神经网络运作方式,IBM研究中心提出的基于相变存储器的架构提升了深度神经网络计算的能效和准确率。
根据论文,IBM研究人员实现了迄今为止模拟电阻式存储硬件在CIFAR-10数据集上训练ResNet分类网络所达到的最高分类准确率。
除了基于模拟相变存储组件训练ResNet分类模型外,IBM研究人员通过使用混合精度架构,在多层感知器、长短期记忆网络(LSTM)、生成对抗网络(GAN)等几类小规模模型上也能实现”软件等效“的准确率。
当今是一个日益向基于AI的技术过渡的时代,物联网电池供电设备、自动驾驶汽车等技术都将高度依赖于快速、低功耗、可靠的DNN推理引擎。IBM研发的基于PCM的架构或有助于这些技术的实现。
在一份声明中,IBM表示:“我们开发的战略旨在提高AI硬件的准确率,使DNN能在高能效下进行训练和推理,这项战略显示了巨大的潜力。”
文章来源:IBM、Nature Communications、VentureBeat
