








智东西(公众号:zhidxcom)
编 | 董温淑
智东西6月18日消息,近日,中国科学院北京分院的研究团队研发出一个AI人像生成模型。该模型可以依据简笔画生成逼真的人脸肖像。
利用这一模型,没有绘画经验的人也可以很容易地得到逼真图像。除了用于娱乐,在未来,这个模型或能帮助执法人员进行嫌疑人画像。
这项研究发表在学术网站arXiv上,论文标题为《深度人脸画像:从草图深度生成人脸图像(DeepFaceDrawing: Deep Generation of Face Images from Sketches)》。今年七月份,这项技术将在计算机图形学顶会SIGGRAPH会议上展出。
论文链接:https://arxiv.org/pdf/2006.01047.pdf
研究项目官网:
http://geometrylearning.com/DeepFaceDrawing/

一、给人脸“分区”,逐块推理出逼真图像
现有的“从图像生成图像”的技术已经可以实现快速输出结果。但是,现有解决方案对输入图像的要求较高,只有以专业素描画像等逼真度较高的图像作为输入时,才能生成逼真的人脸肖像。
在这种模型中,输出结果的质量直接受到输入图像的影响,即输出结果受到输入图像的“硬约束”。
为了解决这一问题,中国科学院北京分院的研究团队设计出一种“从局部到全局(local-to-global)”的“软约束(soft constraint)”方法。总的来说,这一方法基于一个深度学习框架,分为两步进行。
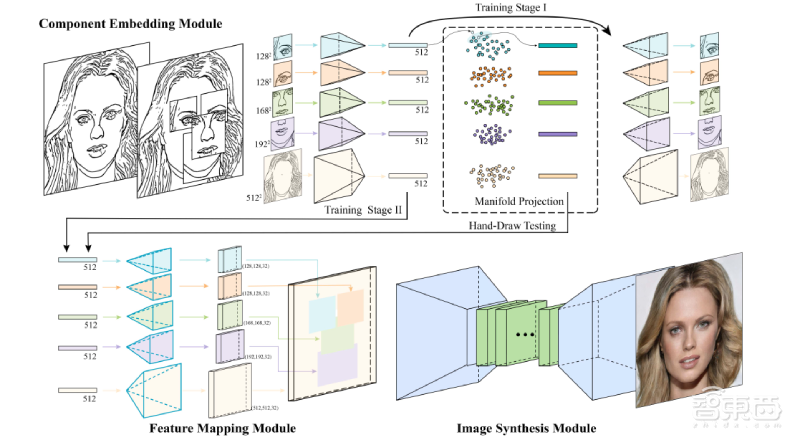
首先,研究人员把简笔画输入模型。模型依据简笔画,推理出人脸上各个器官的“布局”情况。这一步中,模型采用隐式建模(implicitly model)方法建立人脸图像的形状空间模型,并学习人脸关键部位的特征嵌入。
模型将人脸分成左眼、右眼、鼻子、嘴唇、脸型这5个关键“组件”。
然后,模型依据脸部的“布局”情况,从简笔画“倒推”出逼真的人脸图像。这一步中,模型依据人脸组件样本的特征向量,从输入简笔画的相应部分,推理出潜在的人脸组件流形(Manifold)。
对于每一个关键部位,模型隐式定义了一个潜在流形。研究人员假设底层组件的流形是局部线性的。模型运行经典的局部性嵌入算法,将简笔画人脸特征的组件投影到其组件流形上。
为了改善信息流,研究人员应用另一个深层神经网络,使其在上述两步之间输出中间结果。这个深层神经网络通过多通道特征映射,学习从嵌入组件特征到逼真图像的映射结果。
二、60位参与者打分1302次,证实模型输出结果更逼真
模型搭建好后,研究人员使模型在一台搭载了一个英特尔i7-7700 CPU和一个NVIDIA GTX 1080Ti GPU、拥有16GB内存的电脑上运行,用17000张简笔画和照片进行训练。训练结束后,研究人员对模型进行了评估。
研究人员首先用线条不同的简笔画作为输入。结果显示,不同的线条会导致输出图像拥有不同的细节,但输出图像其他部分大体上没有变化。
比如,在下图中,简笔画鼻子部位的线条变化导致输出图像整个脸部的光线出现了变化。

然后,研究人员选用现有的全局检索(global retrieval)模型和组件级检索(component-level retrieval)模型与本项研究中的“从局部到全局”模型进行了对比。结果显示,“从局部到全局”模型返回的样本最接近输入组件草图。
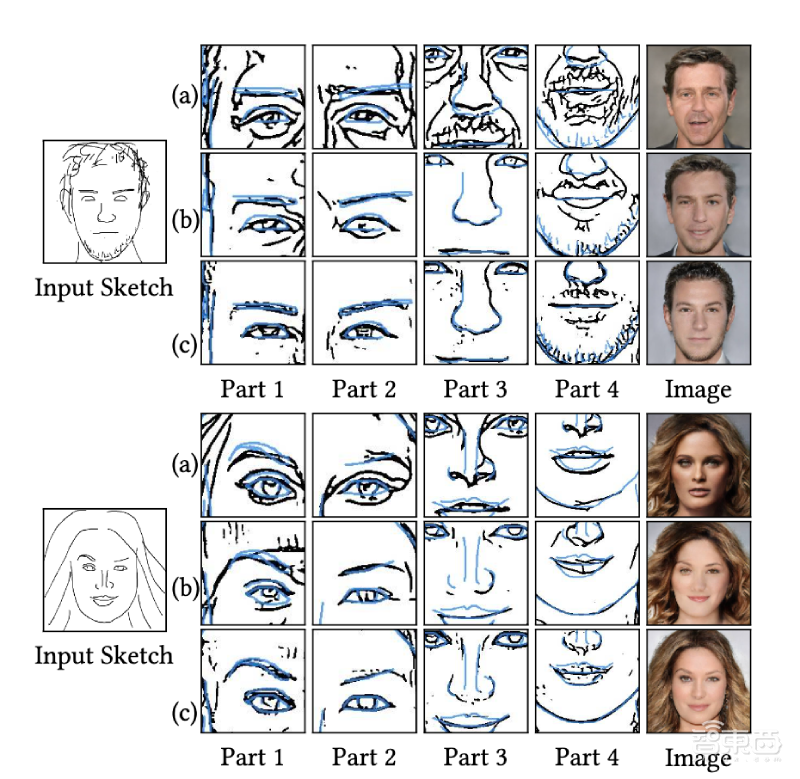
▲a-全局检索模型输出结果,b–局部检索模型输出结果,c-“从局部到全局”模型输出结果
为了使评估结果更加精确,研究人员进行了一项用户调查。研究人员选用22张抽象层次不同、粗糙度不同的简笔画作为输入,分别用全局检索模型、组件级检索模型、“从局部到全局”模型输出结果。
共有60名参与者(39男21女,年龄介乎18至32岁)参加了用户调查。研究人员向每个参与者展示4张照片,其中1张为简笔草图、3张为模型输出的合成图像。

▲向每个参与者展示4张图像(左–全局检索模型输出结果,中–局部检索模型输出结果,右-“从局部到全局”模型输出结果)
研究人员共得到1320个主观评价。对这些评价结果的统计结果显示,参与者普遍认为“从局部到全局”模型的输出结果更加准确、图像质量也更高。
输出结果准确性方面,“从局部到全局”模型平均得分为4.85,局部检索模型平均得分为4.23,全局检索模型平均得分为5.37。
输出结果图像质量方面,“从局部到全局”模型平均得分为5.50,局部检索模型平均得分为4.68,全局检索模型平均得分为3.65。
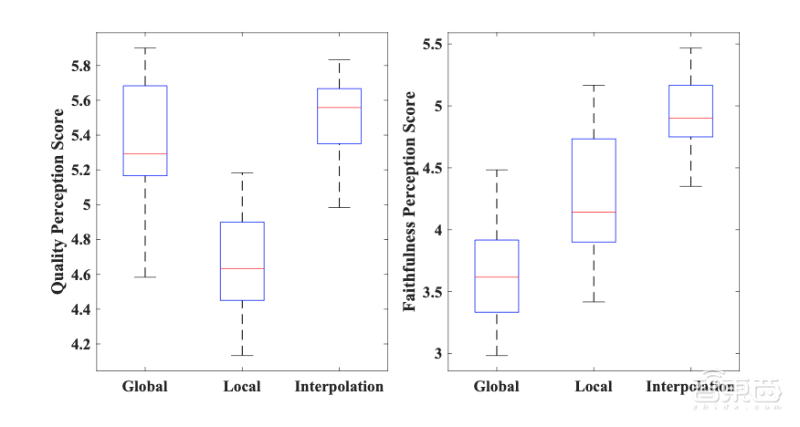
▲左-输出结果图像质量分数,右-输出结果准确性分数
三、局限性:易出现不兼容问题,缺乏少数族裔样本
评估结果显示,“从局部到全局”模型能根据一张人脸简笔画,输出仿真度较高的人脸图像。但是,论文指出,这一模型还有一些局限性。
将人脸简笔画“分区”的方法优势在于灵活度较高,但也可能带来各个组件不兼容的问题。这个问题对于眼睛来说尤其明显。模型“分区”考虑左右眼的策略可能导致输出图像的眼睛不对称。

▲模型输出结果出现了眼睛不同色的问题
根据论文,引入对称损失(symmetry loss)或明确规定输出结果中的眼睛必须来自同一样本可解决这一问题。

▲明确规定输出结果中的眼睛必须来自同一样本
另外,在用于训练的17000张简笔画和照片中,大部分是白种人、南美人的脸,缺乏少数族裔样本。因此,模型对少数族裔样本的画像结果可能会出现失真等问题。
结语:人脸合成技术的价值超出预期
本项研究中,中国科学院北京分院的研究团队采用“从局部到全局”的方法,设计出一个AI人像生成模型。该模型可以依据一张人脸简笔画,输出逼真的人脸画像。
根据论文,在未来,研究人员计划引入侧脸简笔画、在简笔画中增加随机噪声等,通过增加训练数据的规模,使模型输出图像结果更准确。
另外,“从局部到全局”模型的官网信息指出,研究人员将很快推出该模型的代码。这意味着在不久的将来,我们将能看到这个模型的实际应用。
近些年来,基于生成对抗网络(GAN)的Deepfake技术多次被曝出滥用丑闻,引起了很大争议。学界和业界一度谈Deepfake而“色变”,致力于找出能规避其风险的解决方案。比如,
同样用到生成对抗网络,这次中科院团队研发的模型可以利用简笔画生成逼真人像,这既显示出了现在人脸合成技术的厉害之处,也启示我们人脸合成技术的价值比想象的更加丰富和超出预期。
参考信源:Engadget、arXiv
