








芯东西(公众号:aichip001)
编 | 心缘
芯东西7月30日消息,在最新MLPerf基准测试中,NVIDIA和谷歌接连公布打破AI性能记录的消息,使AI战场上再度弥漫起浓烈的火药味。
这厢NVIDIA宣布其A100 Tensor Core GPU在加速器的全部8项MLPerf基准测试中展现了最快的市售商用产品性能,那厢谷歌称其机器学习训练超级计算机在8项MLPerf基准测试连创6个性能记录。
谷歌第四代TPU芯片性能也首次披露,得益于硬件创新及软件优化,TPU v4的性能较TPU v3平均提升2.7倍,此外基于TPU v3的谷歌最强ML训练超算峰值性能超430 PFLOPs。

MLPerf是一个由亚马逊、百度、Facebook、谷歌、哈佛大学、英特尔、微软和斯坦福大学等70多家公司和来自领先大学的研究人员组成的联盟。
MLPerf基准测试是衡量机器学习性能的行业标准,展示了AI行业在处理器、加速器及软件框架方面的进步。NVIDIA和谷歌分别是通用和专用AI芯片的代表玩家。
在此次基准测试中,NVIDIA是唯一一家在所有测试中均采用市售商用产品的公司,采用了其今年最新发布的旗舰AI产品A100 Tensor Core GPU,以及多个DGX A100系统互联的庞大集群DGX SuperPOD系统。
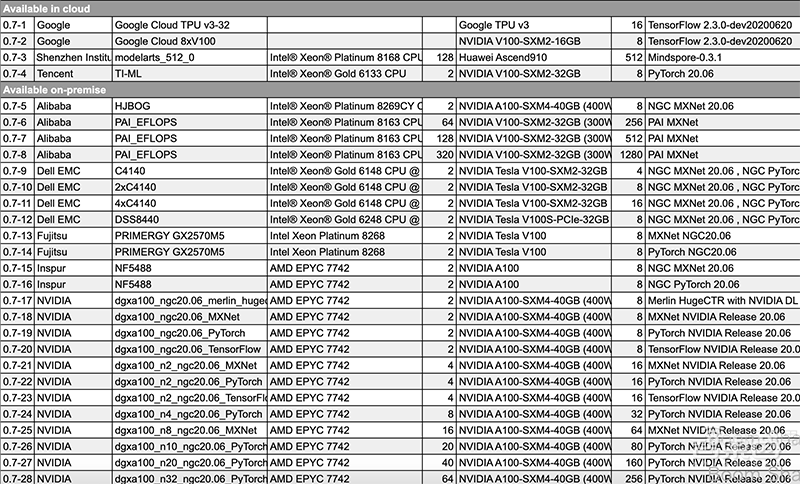 ▲最新MLPerf基准测试提交的可商用类别部分截图
▲最新MLPerf基准测试提交的可商用类别部分截图
其他大多数提交的或为预览类别(preview category),产品预计几个月后才会面市;或为研究类别的产品,较长一段时间不会面市。
例如谷歌提交的AI系统即多用于研究、开发或内部使用,或通过谷歌云对外提供,如谷歌第二代和第三代TPU超级计算机现已通过谷歌云对外开放。
谷歌在此次测试中使用的是其第三代、第四代张量处理单元(TPU)以及谷歌最快的机器学习(ML)训练超级计算机。
在最新MLPerf基准测试中,我们也看到了基于华为昇腾910芯片的两项提交测试结果。
 ▲最新MLPerf基准测试提交的研究/开发/内部使用类别部分截图
▲最新MLPerf基准测试提交的研究/开发/内部使用类别部分截图
MLPerf训练基准测试结果链接:
https://www.mlperf.org/training-results-0-7
一、MLPerf基准测试的八种模型
当前MLPerf训练基准测试包含图像分类、图像分割、目标检测、翻译等8种机器学习模型,通过测试训练其中某一模型达到预定性能目标所需的时间(单位为分钟),来体现其性能。
 ▲MLPerf训练基准测试包含的8种机器学习模型
▲MLPerf训练基准测试包含的8种机器学习模型
最新版本的MLPerf包括两个新的测试BERT、DLRM和一个大幅修订的测试MiniGo。
前沿对话式AI模型BERT是现有最复杂的神经网络模型之一,常被用作翻译、搜索、文本理解、问答等任务。
推荐系统是日益普及的一项AI任务,深度学习推荐模型DLRM常被用于在线购物推荐、搜索、社会媒体内容排序等任务。
强化学习模型MiniGo使用了全尺寸19×19围棋版本,是本轮最复杂的测试,内容涵盖从游戏到训练的多项操作。
最新一轮MLPerf训练基准测试中,提交结果的有9家公司,共提交了138个不同系统的结果,包括商业可用系统,即将发布的预览系统以及正在研究、开发或内部使用的RDI系统。
二、NVIDIA在市售商用加速器中,刷新全部8项测试AI性能纪录
根据发布的MLPerf基准测试结果,NVIDIA首款基于Ampere(安培)架构的加速器A100 Tensor Core GPU在市售商用加速器的全部8项测试中,具备最快的AI训练性能。
在实现总体最快的大规模解决方案方面,利用HDR InfiniBand实现多个DGX A100系统互联的庞大集群DGX SuperPOD系统,在性能上开创了8项全新里程碑。
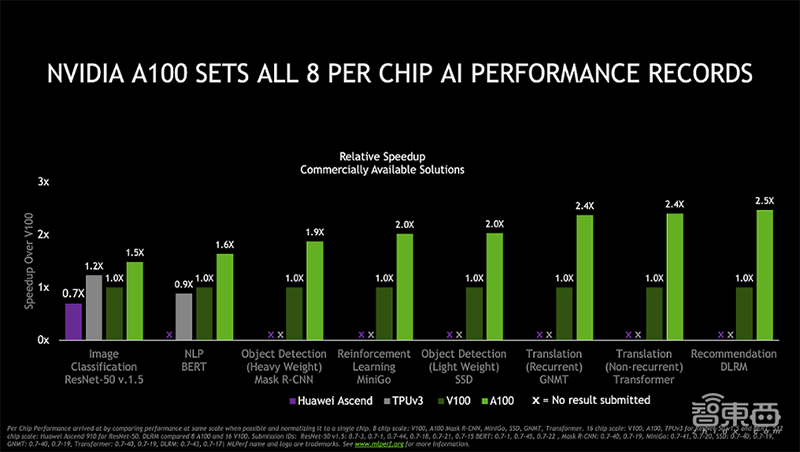 ▲NVIDIA A100集群破MLPerf全部8项AI性能记录
▲NVIDIA A100集群破MLPerf全部8项AI性能记录
从图中可见,相较基于NVIDIA V100 GPU的系统,基于A100的系统在全部8项AI性能测试中均有1.5-2.5倍的性能提升。
对比华为昇腾910处理器在图像分类测试、谷歌TPU v3在自然语言处理(NLP)测试的成绩,NVIDIA A100的处理速度依然相对更高。
这已是NVIDIA连续三次在MLPerf中连续第三次展现强劲性能。2018年12月,NVIDIA首次在MLPerf训练基准测试中创下了6项纪录,次年7月NVIDIA再次创下8项纪录。
通过持续发展全新GPU、软件升级和不断扩展的系统设计,NVIDIA AI平台性能得到进一步提升。
测试结果显示,相较于首轮MLPerf训练测试中使用的基于V100 GPU的系统,如今DGX A100系统能够以相同的吞吐率,实现高达4倍的性能提升。
同时,得益于最新的软件优化,基于NVIDIA V100的DGX-1系统亦可实现高达2倍的性能提升。
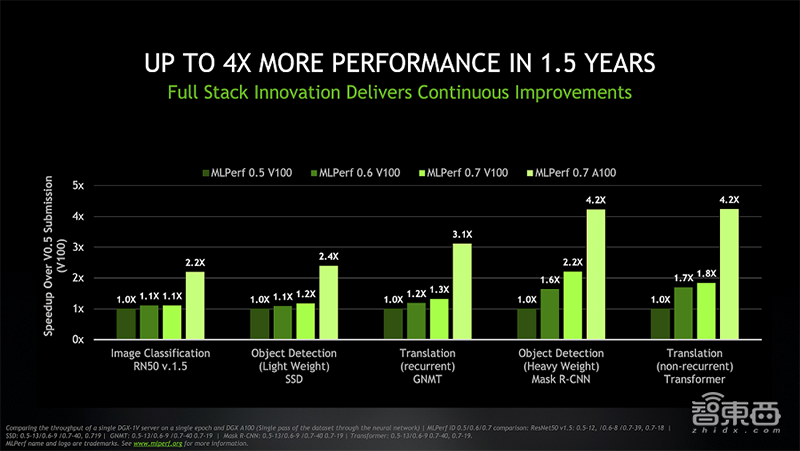 ▲过去一年半,NVIDIA系统性能提升高达4倍
▲过去一年半,NVIDIA系统性能提升高达4倍
许多战略性AI应用已受益于NVIDIA带来的强大性能,例如阿里巴巴在11月“双十一”期间创造380亿美元的销售记录,其推荐系统即使用了NVIDIA GPU,使每秒查询量达到了CPU的100倍以上。
在提交结果的9家公司中,除NVIDIA之外,有6家公司均提交了基于NVIDIA GPU的测试结果,其中包括阿里云、谷歌云和腾讯云三家云服务提供商,以及戴尔、富士通和浪潮三家服务器制造商。
 ▲采用NVIDIA平台参与基准测试的NVIDIA合作伙伴
▲采用NVIDIA平台参与基准测试的NVIDIA合作伙伴
包括这些MLPerf合作伙伴在内的近二十家云服务提供商和OEM组成的生态系统,已采用或计划采用NVIDIA A100 GPU来打造在线实例、服务器和PCIe卡。
大多数NVIDIA及其合作伙伴在最新MLPerf基准测试中使用的软件,现已可通过NGC获取。
三、第四代TPU平均性能提升2.7倍, 谷歌最强ML训练超算峰值性能超430 PFLOPs
谷歌的第四代TPU ASIC提供了超出TPU v3两倍的矩阵乘法TFLOPS、内存带宽和互连技术进步。
基于TPU v4的硬件创新以及软件优化,基于相同规模64个芯片,谷歌TPU v4的性能相比在MLPerf Training v0.6训练测试中的TPU v3性能平均提高了2.7倍。
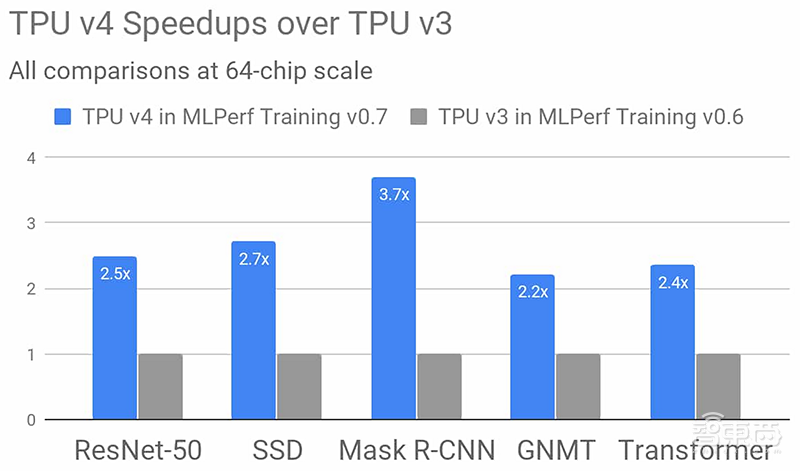 ▲谷歌TPU v4在6种模型测试中的性能相比TPU v3平均提高了2.7倍
▲谷歌TPU v4在6种模型测试中的性能相比TPU v3平均提高了2.7倍
谷歌很快将发布更多关于TPU v4的信息。
在MLPerf Training v0.7基准测试的所有可用类别中,谷歌提交的最快速度均超过了非谷歌提交的最快速度。
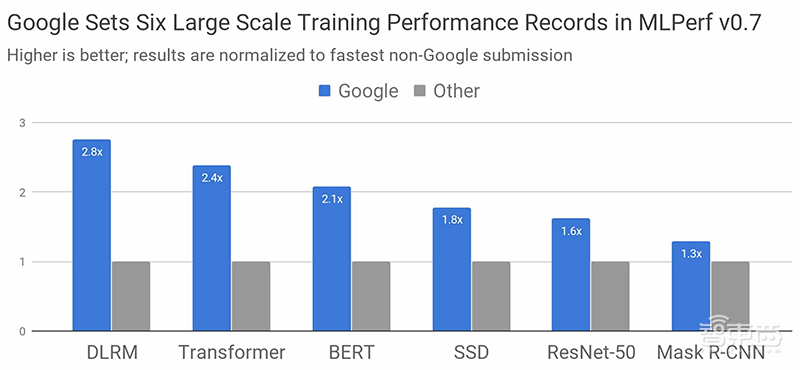
▲MLPerf Training v0.7基准测试的所有可用类别性能表现,无论系统规模大小从8个芯片到4096个芯片,比较都按照总体训练时间进行归一化,数值越高越好
在本次MLPerf训练中,谷歌使用的超级计算机,规模比在之前创下三项记录的云TPU v3 Pod大四倍。
该系统包括4096个TPU v3芯片和数百台CPU主机,所有连接通过超高速、超大规模的自定义互连,能提供超过430 PFLOPs峰值性能。
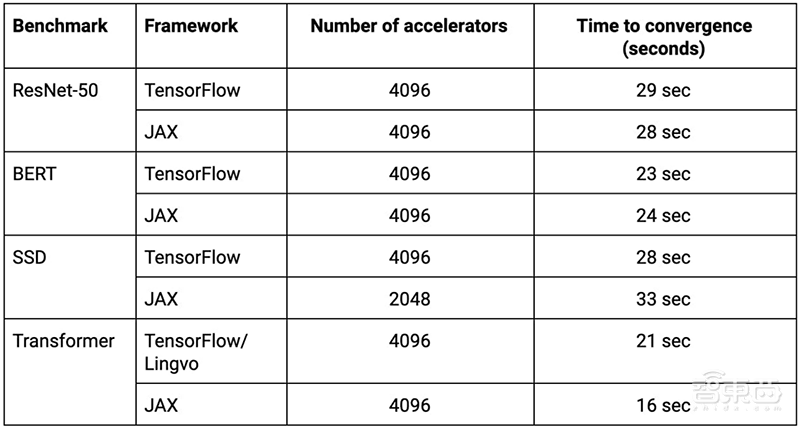 ▲在谷歌新ML超级计算机上,所有MLPerf提交均在33秒或更快的时间内完成
▲在谷歌新ML超级计算机上,所有MLPerf提交均在33秒或更快的时间内完成
在谷歌新ML超级计算机上,无论是使用2048或4096个TPU芯片,所有这些MLPerf测试都在33秒或更快的时间内完成。
谷歌使用TensorFlow、JAX和Lingvo中的ML模型结合XLA实现了这些成绩。
TensorFlow是谷歌端到端的开源机器学习框架,XLA是支持所有谷歌MLPerf测试的底层编译器技术,Lingvo是使用TensorFlow构建的序列模型高级框架,JAX是一种基于可组合函数转换的新型研究框架。
这些性能成绩体现了谷歌在推进机器学习研究方面的进展。
在2015年,谷歌让一款手机用当时有最先进的硬件加速器需要花费三个多星期进行类似的训练。
仅仅五年时间,谷歌就可以将同一模型的训练速度提高近5个数量级,这一进展令人相当印象深刻。
谷歌表示,用户现可通过谷歌云使用谷歌的第二代和第三代TPU超级计算机。
结语:AI加速器竞赛良性升级
机器学习模型的快速训练对于研究和工程团队来说至关重要,而不断演进的通用及专用AI加速芯片正带来新的突破。
随着NVIDIA A100和谷歌TPU v4的问世,AI芯片领域战况将更为激烈,而这些良性的竞争也将进一步带动AI相关研究及应用落地的快速发展。
