








出品 | 智东西公开课
讲师 | 童志军 阅面科技合伙人&CTO
提醒 | 点击上方蓝字关注我们,并回复关键词 嵌入式04,即可获取课件。
导读:
4月17日,阅面科技合伙人&CTO童志军在智东西公开课进行了嵌入式AI合辑第四讲的直播讲解,主题为《面向嵌入式设备的轻量级神经网络模型设计》。
在本次讲解中,童志军老师从神经网络模型在嵌入式设备运行的挑战、神经网络模型从“特征驱动”、“数据驱动”、“精度优先”到“速度优先”等不同阶段的发展历程,并通过实际案例解读如何在嵌入式设备上实现神经网络模型的高效部署和运行。
本文为此次课程主讲环节的图文整理:
正文:
大家好,我是阅面科技合伙人&CTO童志军,很高兴能在智东西公开课和大家一起分享今天的课题。我今天分享的主题为《面向嵌入式设备的轻量级神经网络模型设计》,主要分为以下4个部分:
1、神经网络模型在嵌入式设备运行的挑战
2、从“特征驱动”到“数据驱动”的大型神经网络模型设计
3、从“精度优先”到“速度优先”的轻量级神经网络模型设计
4、在嵌入式设备实现神经网络模型的高效部署与运行
神经网络模型在嵌入式设备运行的挑战
目前,在所看见的嵌入式设备上,很大一部分会有AI的算法的身影。在我们身边也有很多应用,比如刷脸解锁手机、刷脸支付、家用的摄像头,或马路上随处可见的公共安防摄像头等。
嵌入式设备在我们身边无孔不入,这些设备分为两种,一种是只做视频的抓取没有计算,只是把视频传到后台服务器,然后做分析;另一种是设备上会带有AI计算能力,一些算法会在前端设备上去计算,然后把计算得到的结构化数据再传到后端服务器去做进一步分析。
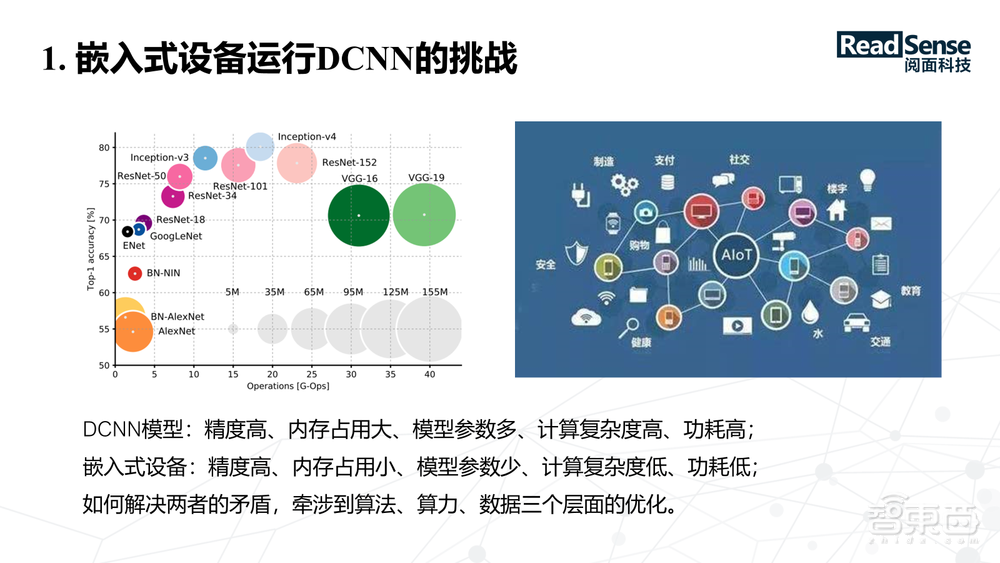
上图左边列举了一些主流的神经网络模型,包括计算量及参数量,相应在Imagenet公开数据集上Top-1的精度。上图横坐标代表的是计算的浮点计算量,然后纵坐标是精度。可以看到神经网络模型的精度与模型的计算量成正比,随着模型计算量越来越大,精度也越来越高。
但也可以看到,网络模型的精度与模型的参数量是没有完全呈正比。比如VGG网络,它的参数量很大,但是精度不是特别高。在嵌式设备上运行神经网络,首先要求模型的精度要非常高,只有模型的精度达到一定的准确率才能满足人们实际使用的需求。由于嵌入式设备的功耗、存储及计算资源都非常有限,如何在有限的计算资源下把高精度的模型运行为实时动态的效果是非常重要的,这里会涉及到算法、算力及数据几个层面的优化,今天主要与大家探讨在算法层面,更确切的是在网络设计的层面如何解决?
从“特征驱动”到“数据驱动”的大型神经网络模型设计
首先回顾下大型的神经网络模型的发展脉络,其实卷积神经网络很早就出现, LeNet-5很早在美国邮政的数字识别上已经得到很好的应用。但后来并没有得到更多的推广,沉默了10年,10年内主流的一些视觉分析的方法还是手工特征。
对于手工特征,大家比较熟悉的是SIFT特征,它是在x方向跟y方向去提取梯度图,然后把每一个像素的梯度图按照一定的角度区间各自去做梯度方向的投影,最终得到128位的描述子。如果把这个问题换一个角度来思考,可以发现 SIFT特征的生成过程,可以等效是一个卷积层和一个pooling层。
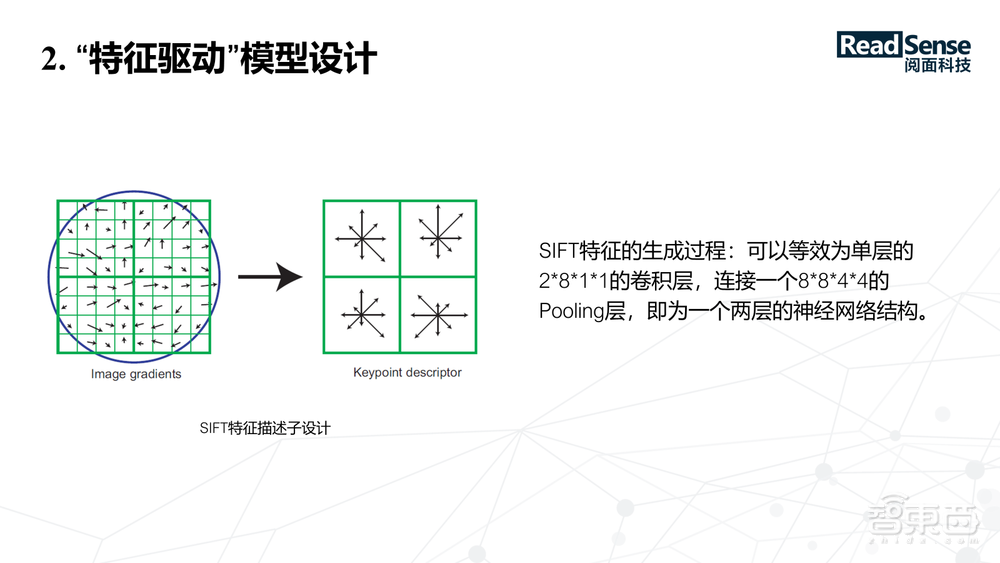
上图可以看到它的8个方向的梯度,代表的是输出Channel为8,kernel大小为1*1的卷积,输入是x方向跟y方向的梯度流。对于 x方向跟y方向的图,等效成一个2*8*1*1的卷积操作,后面再接了一个8*8*4*4的Pooling层,最终得到一个两层的神经网络结构。
随着特征描述的发展,逐渐从底层的特征设计发展到中层特征设计。中层特征设计比较典型的是Fisher Vector,它在图像搜索的方面应用的非常广泛。Fisher Vector特征首先对图像做特征提取,然后基于GMM模型对特征做进一步的编码,编码得到的特征,再通过空间卷积得到在不同的尺度空间上的特征描述。用现在的神经网络结构的方式去看,可以等效为一个SIFT特征提取过程,加一个编码层和一个Pooling层,即为一个四层的神经网络结构。4层的网神经网络结构比两层的神经网络精度会更高,特征也更抽象,表达能力更强。
到2010年时,李飞飞教授带领的一帮学者整理了一个非常大型的数据集-Imagenet,这个数据集有1000类,大概120万张图片,这个数据集的出现是神经网络得到飞速发展的基石,掀起了整个AI界的军备竞赛。
时间到了2012年,ImageNet比赛冠军提出来一个新的网络AlexNet。它由5个卷积层,3个全连接层。另外由于当时GPU显存的限制,把网络的卷积分成分组的形式,使得网络能够在 GPU有限的情况下运行起来,里面还有drop out的技巧等。AlexNet开创了神经网络结构的一个新河,在此之后,工业界的人开始相信深度学习是有效的,可以产生一些有价值的东西,而不仅是学术界的一个玩具。
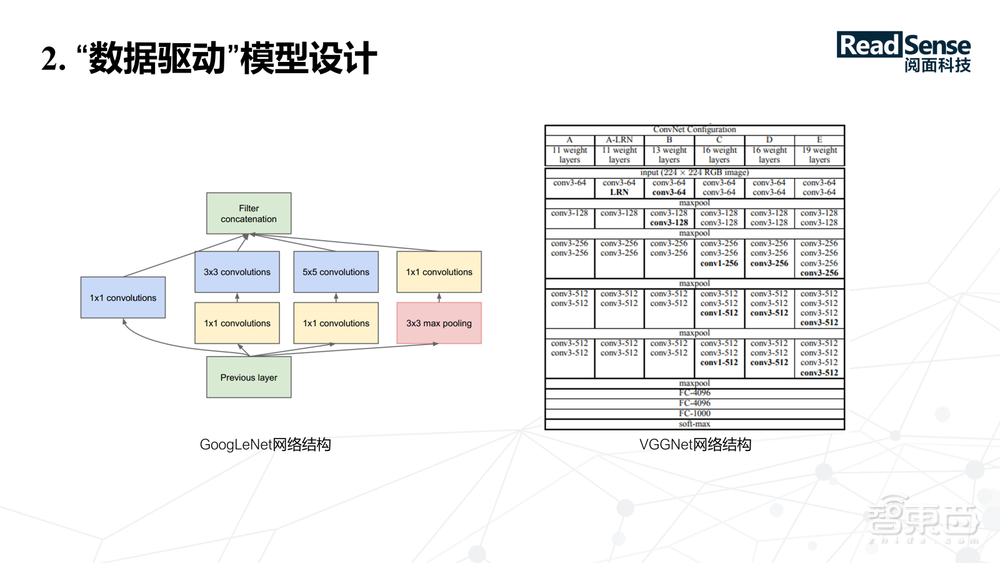
2014年,出现了VGG和GoogleNet两种不同的网络结构,两个网络其实都是在不同层面对网络去建模。在早期,AlexNet出现之后,在调网络的时候发现一种很奇怪的现象,当把层数往上堆时,很容易出现梯度弥散的效应。如何把网络做深,在当时一直没有得到很好的解决。
VGG跟GoogleNet做的网络都接近20层左右,这是一个突破,这里也是使用了一些技巧,比如 GoogleNet是在层中间插入 loss的监督, 然后在block的设计上引入了一些技巧,通过这种多尺度的卷积核,提取图像上的多尺度的信息。其实尺度是一个非常重要的因素。另外逐层的 finetuning,在VGG用的比较多,还引入了连续两个3×3的卷积核去模拟5×5的感受野,它使得网络可以做得更深,精度做得更高。
2015年,微软亚洲研究员何凯明设计的残差网络,把神经网络从20层提升到几百层。可以看到网络层数越来越深,而且网络的宽度也越来越宽,当然最终的精度也是非常高。
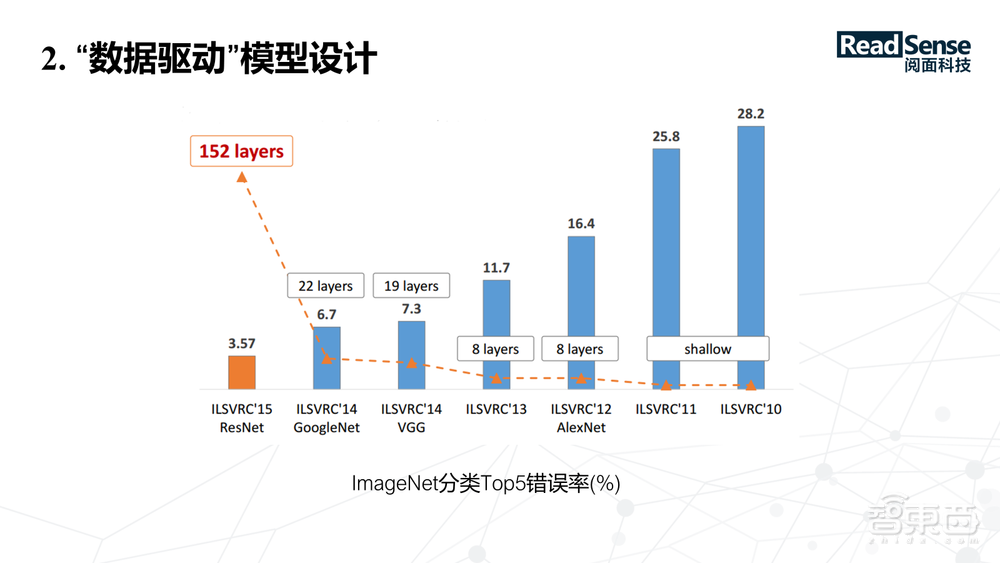
上图为ImageNet分类Top5错误率图,可以看到网络的精度随着层数逐渐增加越来越高,网络结构也在不断创新。
从“精度优先”到“速度优先”的轻量级神经网络模型设计
自2015-2016年之后出现网络模型有往端上发展的趋势,如何把神经网络模型在终端上跑得更快,是演变的一个趋势,也就是模型的设计从精度优先到后来的速度优先。
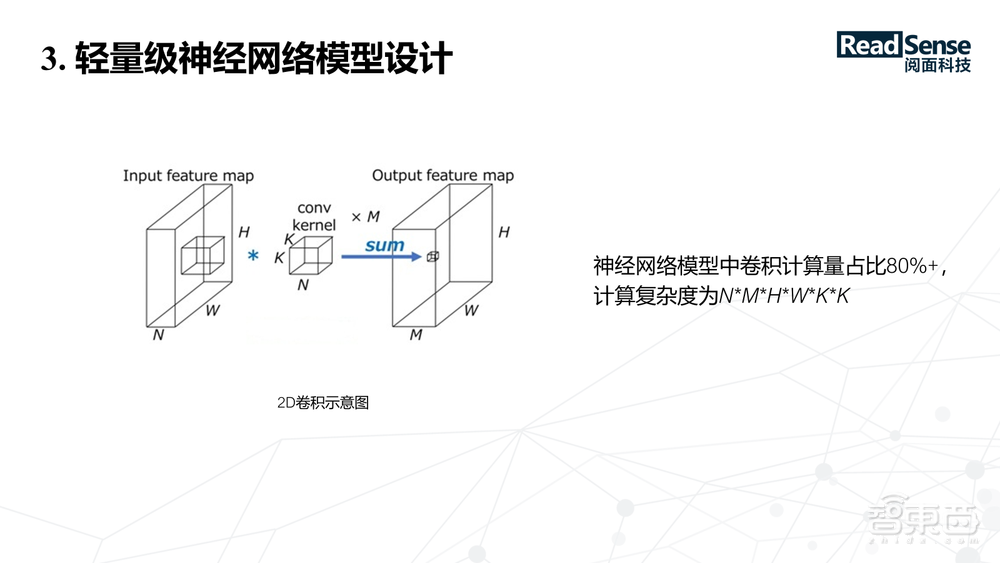
我们可以简单分析下神经网络模型的计算量,可以看到一般的神经网络模型,大部分都是由卷积层组成,卷积层在里面的计算量占到了80%以上,卷积的计算示意图如上图所示,计算复杂度为N*M*H*W*K*K。
轻量级的神经网络模型所做的工作,就是围绕着计算复杂度,把里面的一些参数尽量的减小,使得计算量能够降低。计算量在嵌入式设备上体现最明显的是它的速度。如何在优化计算复杂度的同时保证模型的高精度,就是下面一些主流的神经网络模型设计所做的工作。
最开始比较有代表性的一个网络是SqueezeNet网络,它有两个特点,先用1×1的卷积核做通道压缩,然后把1×1与3×3的卷积核并排,使得卷积核可以更小。也就是通过减小通道数以及卷积核大小降低模型的计算量,使得模型可以推理的更快。
第二个是MobileNet网络和ShuffleNet网络,MobileNet网络用到一个比较重要的点是Depthwise卷积,也是把原来稠密的卷积N*M的计算量,直接优化为N的计算量。ShuffleNet网络借鉴了 MobileNet网络一些点,比如Depthwise卷积,当应用Depthwise卷积后,发现整个神经网络计算量更多是在1×1的卷积上,这时就可以把1×1卷积去做一个通道Shuffle分组,分组之后做通道卷积,使得它能够在3×3上再进一步的融合,可以看到大家更多的是把卷积由原来的稠密卷积变成通道的卷积。
最近的神经网络是模型搜索NAS,这方面有很多的轻量级的网络结构,但是没有把它应用到嵌入设备上,为什么?因为 NAS搜索出来的网络规律性比较差,对嵌入式设备不是很友好。实际应用更多的还是停留在MobileNet网络这种比较直线型的网络上去优化。
后来有一个EfficientNet网络结构,它的想法比较综合,把网络计算量的几个因素同时去做一个联合搜索优化,比如网络的层数,或者图像的feature map的长宽,以及计算复杂度中提到的N、M、K,去做一个统一的建模,通过增强学习去搜索最优解。另外,网络结构也做一些重复的堆叠,相对非常有规律,对整个嵌入式设备还是非常友好的。
在嵌入式设备实现神经网络模型的高效部署与运行
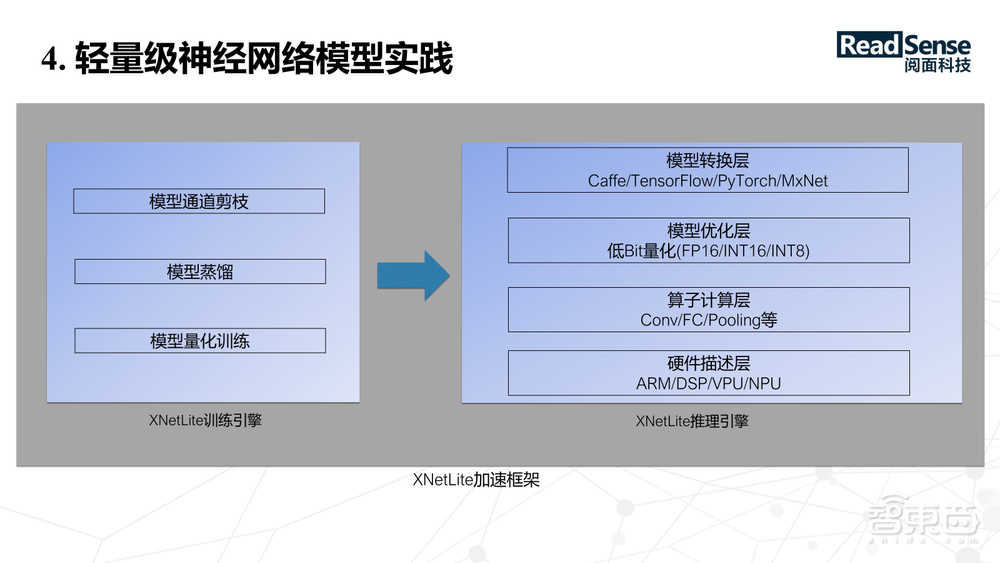
首先看下整体的加速框架,这里面大概包含了阅面所做的一些工作,左边是训练端,主要做了模型的通道剪枝、模型蒸馏和量化训练的工作,右边是在嵌入式设备上做模型的转换,以及卷积运算算子的优化,使得我们的模型可以在一些硬件层面快速的跑起来。
第一个是通道剪枝,剪枝包括稀疏化等,但对嵌入式设备不是很友好,因为稀疏化剪枝得到的模型没有规律,让内存的取值变得随机,使得设备速度跑不起来。后来通道剪枝可以得到规则模型,使得剪完之后的模型能够复用以前的计算引擎,这方面更多的是基于一些规则,比如选取响应最大卷积核或选一些方差比较大的卷积核,对卷积核建模,通道压缩率也可以通过强化学习的方法去反复搜索,最终得到最优的结果。
通道剪枝主要针对MobileNetV2和 EfficientNet这类网络,可以看到当模型从原来的200-300M的计算规模,到后来100M以下,其精度下降在一个可以接受的范围内,这样的模型可以在检测或者是识别任务上得到很好的使用。
第二是模型蒸馏,最早主要是体现在loss设计上,比如 Student模型去学习Teacher模型的样本分布,最终来提高Student模型的精度。以Margin为例,Margin在细粒度分类上用的比较多。通过Student模型去学习Teacher模型的Margin分布,使得Student模型的精度得到非常大的提升。
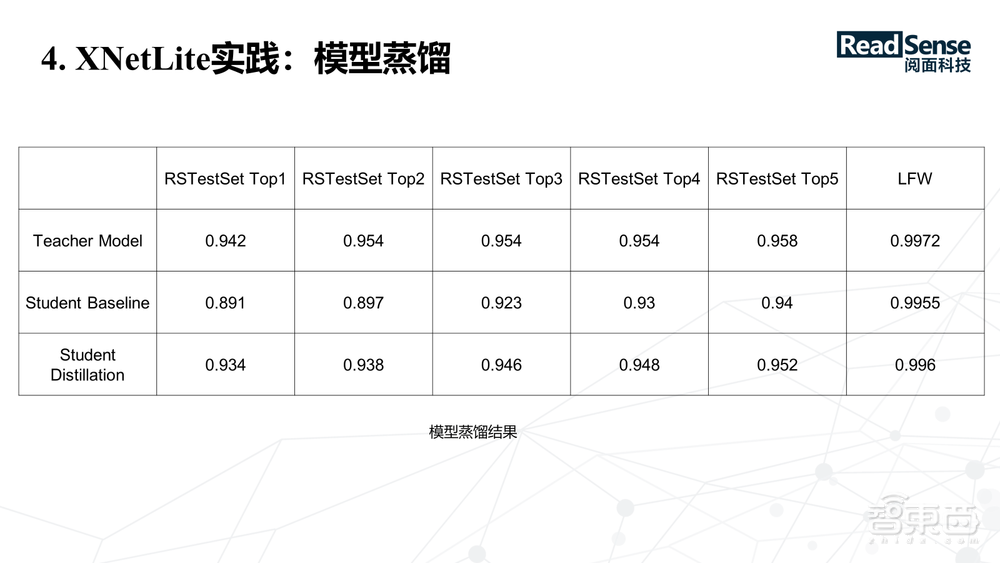
上图为训练人脸识别网络,第一行是 Teacher模型的精度,第二行是Student模型的一个baseline ,第三行是用模型蒸馏的方法产生的Student模型的记录,可以看到训练出的 Student模型的精度,是介于Teacher模型跟Student模型之间,而且比较接近Teacher模型的精度,相对于baseline有非常大的提升。
第三块是量化训练,为什么要做量化训练?模型量化会带来很多好处,最常见的比如可以把模型的存储量,从原来的FP32减到INT16或INT8,直接减掉一半或1/4。另一点是做量化之后,使得模型做并行加速,比如同样一个指令周期,原来可以操作1个浮点数,现在可以同时操作2个INT16或4个INT8,使得数据的吞吐量提升,这也是一种提速。
它的流程如下:首先会收集前向的数据集,然后对网络做统计,统计分为两部分,一个是模型的 weight做最大最小或者 kr散度分布上的统计,另一个是对模型的输入输出做统计,从而可以选取到最优的一个标准去对模型做量化。如果只做INT16的量化,模型的精度是可以完全保持住的。但当做更低精度,比如INT8或INT4,模型精度会有一些损失,这时还需要做一些finetune,使得模型精度可以回到跟原来浮点模型的精度。
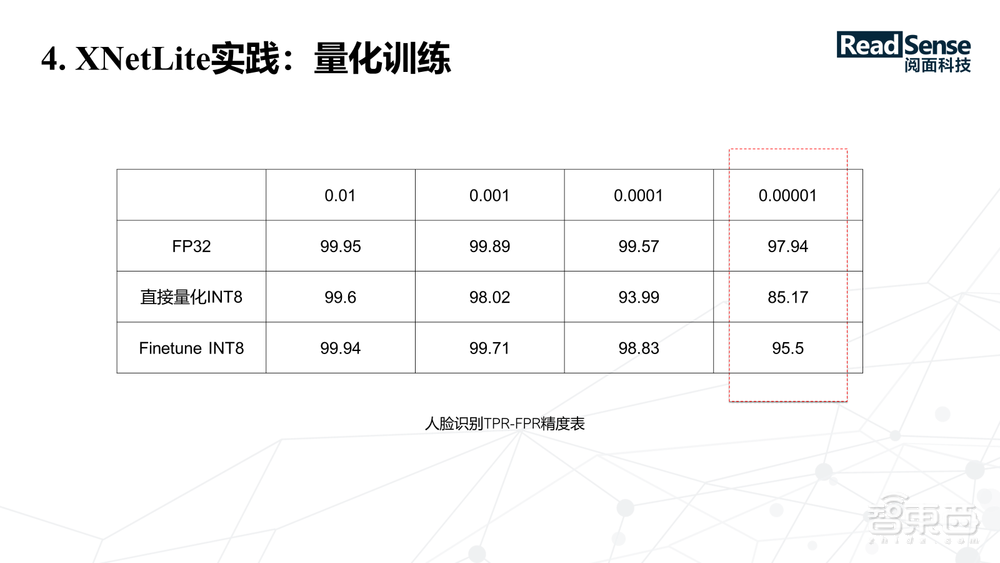
上图是在人脸识别模型上所做的工作,比如FP32在1/10万是达到97.94%的识别率,直接量化INT8,精度为 85.17,通过finetune使得最终的模型可能只降低了1~2个点。量化是一个非常有效的降低模型计算量,同时适合嵌入式设备,不管是功耗或存储的占用都非常友好。
第四点是当得到一个最优的模型结构之后,最终部署到嵌入式设备上,就涉及到推理引擎。推荐引擎主要的计算在卷积运算, 我们采用的是直接基于原始的卷积方式做优化。这涉及到行主序的内存重排、矩阵分块、内存对齐、内存复用、缓存预读取、SIMD并行加速、循环展开、多线程等。
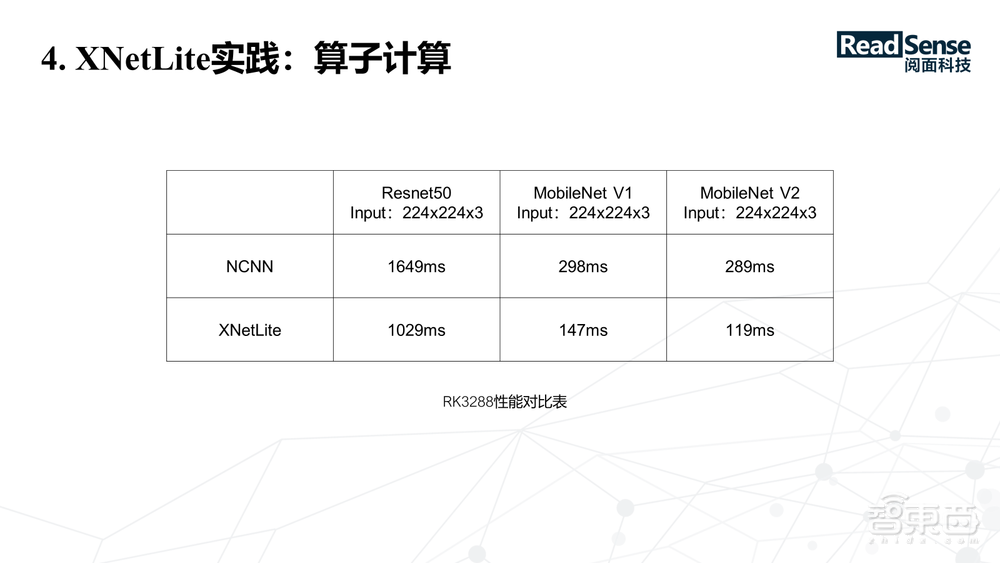
我们在RK3288上做的优化,对比的是腾讯开源的NCNN推理引擎。可以看到在同样的输入下,我们的速度提升大概有40%~50%之间,这个引擎还在持续的优化,算子的计算优化也是非常重要的一环。
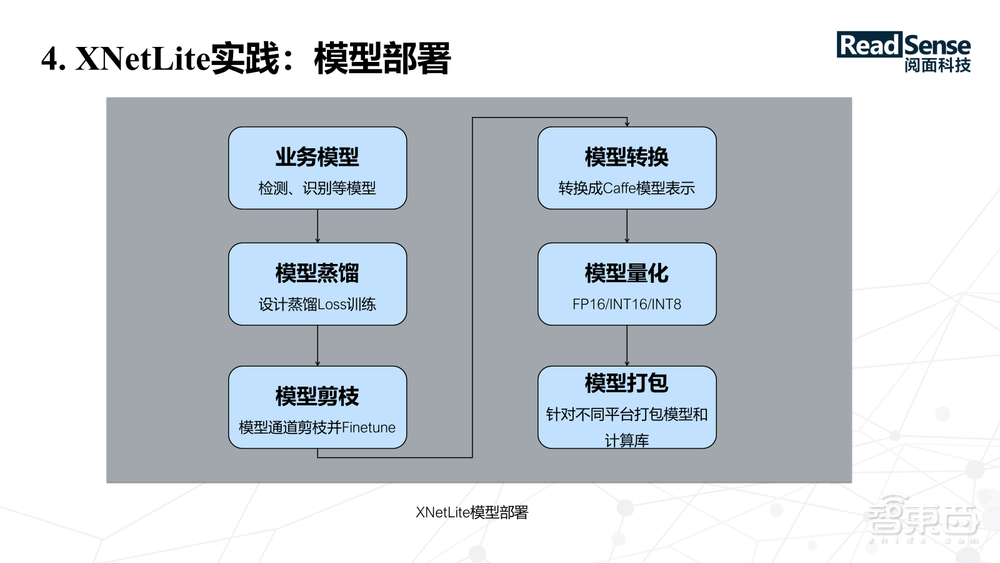
最后总结下,在嵌入式模型部署所做的工作,首先会得到检测或识别的业务模型,根据具体客户的需求训练浮点模型,之后做模型蒸馏的loss训练,把计算量做进一步的精简。精简完之后,对一些稀疏的通道,做进一步的剪枝,并且把模型finetune,得到一个最紧凑的深度学习模型。之后根据前面的一些积累,我们更多是基于Caffe的框架,在这个基础之上对模型做进一步的量化,量化可能会根据具体硬件不同会有所不同。最终得到一个最优化的量化模型之后,把算子计算库打包一起,最终形成一个运行程序,部署到实际的设备上。上面就是完整的模型部署的流程。
以上就是我今天的分享内容,谢谢大家。
