








智东西(公众号:zhidxcom)
文 | 温淑
老牌金融玩家平安保险集团旗下的平安科技集团,曾在短短一个月时间内搭建了企业办公场景AI翻译产品“平安好译”的模型。
与传统解决方案相比,“平安好译”的数据处理速度较原来提升了 7 倍,翻译1000个英文字符的平均翻译时间从8.3s降低到0.97s。

在“平安好译”实现的效率提升背后,是NVIDIA DGX家族第一代AI超级计算机DGX-1提供的超强AI性能。最近,NVIDIA明星产品DGX家族再添新成员。
今年5月举办的GTC 2020大会上,全球AI计算领导者NVIDIA发布全球最先进AI系统NVIDIA DGX A100。同时,NVIDIA DGX A100即将开放产品测试申请。
AI计算正当风劲扬帆时,千行百业智能化变革在即,有消费互联网基因的IT等产业立在“潮头”,对比之下,医疗、传统工业等智能化能力欠缺的产业转型,无疑面临着更大的挑战。
全球AI计算领跑者英伟达(NVIDIA),正通过DGX家族产品,提供一种帮助企业“降本增效”的AI解决方案。
在NVIDIA DGX A100即将开放产品测试申请之际,今天,智东西与你一起,解读NVIDIA DGX家族为哪些产业带来变化、揭秘NVIDIA DGX A100背后的软硬件“黑科技”。
一、NVIDIA DGX家族产品为AI计算降本增效
病毒基因组测序、感染分析和预测……在生物医药的每个细分领域,如何处理庞杂的医学数据、模拟复杂的感染过程都是一大难题。在药物研发的重要性从未被如此重视的2020年,NVIDIA的DGX SuperPOD正为新冠病毒药物的研发提供助力。
生物医药公司葛兰素史克、阿斯利康将首批使用全球排名第29位的超级计算机Cambridge-1,解决包括新冠病毒在内的医学难题。而超级计算机Cambridge-1,搭载的正是NVIDIA最新推出的NVIDIA DGX SuperPOD解决方案。
NVIDIA DGX SuperPOD是由20~140个NVIDIA DGX A100系统构建的全球首个一站式AI基础设施。
模块化的DGX SuperPOD架构可用短短数周,完成安装并运行传统超级计算机需要数年时间才能部署的系统。

▲Cambridge-1超级计算机
其实,这已不是NVIDIA DGX家族产品首次凭借其亮眼性能为产业带来效率的提升。
比如,本次开放产品测试的DGX A100首批系统,已经交付给美国阿贡国家实验室,用于加速新冠病毒药物研究。其前代AI超级计算机产品DGX-1及DGX-2,也已经落地于许多行业。
针对数字化基础贫弱的传统纺织行业中,织物瑕疵检测的问题,中原工学院(原郑州纺织工学院)基于NVIDIA DGX-1超级计算机训练AI模型。NVIDIA DGX-1集成了8个NVIDIA V100 GPU,而单张V100每秒平均训练的图片的效率,可达双路CPU服务器的30倍以上。
另外,在推动科研院所先进科技成果加速落地的过程中,也有NVIDIA DGX家族的身影。对于科研院所来说,科研人员IT能力的欠缺,是导致先进成果难以落地的一大原因。
针对这一现状,上海交通大学网络信息中心计算部基于NVIDIA DGX-2超级计算机打造AI计算平台,该AI计算平台峰值算力达16 PFLOPS。
截至,上海交大AI计算平台为上海交大人工智能研究院、Bio-X研究院、密西根联合学院等多院系的研究团队优化AI计算及HPC应用,最高将科研效率提升1.8万倍。

▲NVIDIA DGX A100系统
在效率提升的基础上,NVIDIA DGX家族产品在降低成本方面亦有优势。
一个典型的AI数据中心有50个DGX-1系统用于AI训练,600个CPU系统用于AI推理,需用25个机架,功率为630kW,成本逾1100万美元。在这之外,模型训练、推理的时间、资金、人才成本还需另行计算。
相比之下,由5个DGX A100系统组成的机架可达到同样的动作效果,并且功率仅为28kW、成本低至100万美元。
不同于在消费互联网时代积累了大量软硬件基础以及数字化经验的科技企业,生物医药、轻重工业等较为传统的企业、乃至缺乏IT经验的科研院所,在AI技术浪潮中面临的挑战,下至基本的软硬件配置、上至数字化人才的配备。
NVIDIA在2017推出面向深度学习平台构建任务的AI超级计算机DGX-1、在2018年推出面向AI速度和规模挑战的超级计算机DGX-2,正是针对行业智能化转型的困境提出解决方案。
NVIDIA DGX A100已经是NVIDIA DGX家族的第三代AI超级计算机产品,亦是本次NVIDIA产品测试申请计划的“主角”。
二、DGX A100:面向所有AI工作负载,算力媲美数据中心
距离DGX-1推出三年时间,在今年5月14日举办的GTC 2020大会上,NVIDIA推出面向所有AI工作负载的全球AI基础架构通用系统DGX A100,为客户提供5 petaFLOPS AI性能的超强算力,并拥有“开箱”即用的快速部署能力。
1、媲美数据中心的超强算力
NVIDIA DGX A100系统将训练、推理、数据分析统一于一个平台,是世界上第一台单节点AI算力达到5 petaFLOPS的服务器。
5个NVIDIA DGX A100系统组成的机架,算力可媲美一个由50个DGX-1系统、600个CPU系统组成的AI数据中心。
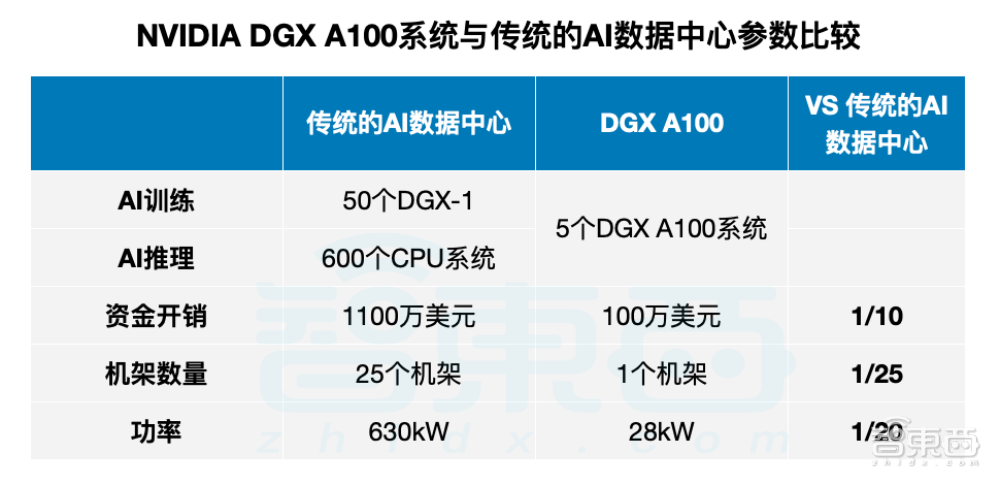
▲NVIDIA DGX A100系统与传统的AI数据中心参数比较
2、“开箱即用”的快速部署能力
NVIDIA DGX系统不仅能满足企业的数据处理和智能化部署需求,而且降低智能化“门槛”,致力于提供“开箱即用”的便捷体验。
以美国阿贡国家实验室(Argonne Nationl Laboratory)基于NVIDIA DGX SuperPOD构建的Selene系统为例。Selene是全球运算速度排名第七的计算机,可用于研究遏制新冠病毒的方法,还推动着AI在汽车、医疗保健和自然语言处理领域的发展。
令人意外的是,基于NVIDIA与客户共享的开放式架构,组装Selene这样一个大型AI系统仅由一个小团队花费不到一个月的时间完成。
相比之下,要基于其他解决方案构建这样一个大型AI系统,在最理想的情况下也需要数十名工程师花费几个月的时间。
三、强大的企业级AI解决方案:从硬到软的全面技术支撑,即将开启测试申请
在NVIDIA DGX A100以及NVIDIA DGX SuperPOD解决方案提供的强大AI解决方案背后,是NVIDIA在NVIDIA DGX A100产品中提供的强大软、硬件支持。
1、集成8个NVIDIA A100 GPU
每个NVIDIA DGX A100系统集成了8个NVIDIA A100 GPU,打造面向训练、推理、数据分析的通用AI解决方案。
NVIDIA A100 GPU基于NVIDIA第8代GPU架构安培架构和7nm制程工艺,包含超过540亿个晶体管,AI训练峰值算力达到312 TFLOPS,AI推理峰值算力为1248 TFLOPS。
与上一代Volta架构GPU相比,NVIDIA A100 GPU的AI训练峰值算力、AI推理峰值算力提升了20倍。

▲NVIDIA A100 GPU
2、提供320 GB超大内存
每个NVIDIA A100系统使用600 GB/s NVSwitch链路连接8个A100 GPU,配备320 GB超大内存,带宽为每秒12.4 TB。
3、由NVIDIA DGX软件栈提供支持
除了8块NVIDIA A100 GPU提供的硬件支持,NVIDIA DGX A100系统还由NVIDIA DGX软件栈提供支持。
NGC(NVIDIA GPU Cloud)是适应于深度学习、机器学习、高性能计算的GPU优化型软件中心,可以加速AI模型从部署到开发的工作流程。
据了解,用户可以在本地、云端、边缘运行NGC目录中的软件,也可以使用混合和多云部署。NGC目录软件可部署在裸机服务器、Kubernetes或虚拟化环境中,从而更大限度地利用 GPU,同时尽可能提高应用程序的可移植性和可扩展性。
4、通过Mellanox实现卓越的数据中心可扩展性
今年4月27日,NVIDIA完成对以色列服务器硬件公司Mellanox的收购。通过融合Mellanox的高性能网络技术,NVIDIA将拥有从AI计算到网络的端到端技术,以及从处理器到软件的全堆栈产品。
这意味着相比前两代产品,NVIDIA DGX A100系统将进一步提升网络性能及可扩展性。
目前,NVIDIA DGX A100即将开放产品测试申请。
意向用户可通过注册链接进行注册,并申请产品测试机会。意向用户可通过NVIDIA认证合作伙伴远程或现场测试DGX A100;亦可咨询如何在短时间内打造由DGX A100组成的AI 超级数据中心。
收到测试申请后,NVIDIA工作人员将在一周内与申请用户取得联系。
申请页面:https://jinshuju.net/f/u69TOj
结语:量身定制的企业智能化转型解决方案
产业智能化浪潮汹涌而来,千行百业身处其中。对于自身AI计算基础较弱的企业来说,走好这条智能化转型之路显得尤为重要。
一边是重塑每个业务环节带来的效率提升,另一边是难以负担的高昂成本、AI技术人才的欠缺等各种问题。如何弥合这两者间的鸿沟,成为面临这场产业变革的“必答题”。
从这个角度来看,NVIDIA的DGX家族产品,正为这道“必答题”贡献了一套解决方案。
NVIDIA DGX A100提供强悍的算力、开箱即用的部署方式、强大团队的技术支持。在即将到来的产品测试中,这款AI计算“大杀器”或将能与迫切期望实现智能化的企业碰撞出更多火花。
