








工欲善其事,必先利其器。AI研究与开发离不开算力支持,尤其是在进行模型训练的时候,一台强力的GPU工作站必不可少。其中处理器、内存/硬盘、显卡、以及散热表现都是选择GPU工作站时需要考虑的因素。
然而由于实际应用环境的差异,开发者对GPU工作站的性能需求都有所不同。目前市面上也有一些面向机器学习开发的GPU工作站,但对于个人开发者,或者在中小企业、传统企业的开发人员而言,如何选择一台可满足性能需求的GPU工作站,并不容易。
作为一名“野生”AI开发者,有幸在最近一周深度体验了一台HP Z8 G4工作站,从开发环境的安装、测试,以及深度学习算法模型,如CIFAR-10和ResNet50分类模型,以及YOLOv3的检测模型的训练,都进行完整的开发训练。下面是我对这一周的开发工作和使用体验的总结整理,供大家参考,希望能有所帮助。
一、关键参数和散热表现
在为大家介绍关键参数和散热表现之前,我拍了几张产品实图,为大家直观的介绍一下HP Z8 G4工作站的外观设计和内部结构。

先说一下外观部分,机身外体采用的是铝制结构,并且以黑色磨砂呈现(比较符合开发者的颜色审美),给人一种很精致的感觉。然后是机体部分,整体采用模块化的设计(符合程序设计的模块化理念),内部布局让人感到整洁无暇。最后是主机后端的电源部分,可以进行免工具进行拆卸,极大的方便了后续的性能扩展。
1、关键参数

-
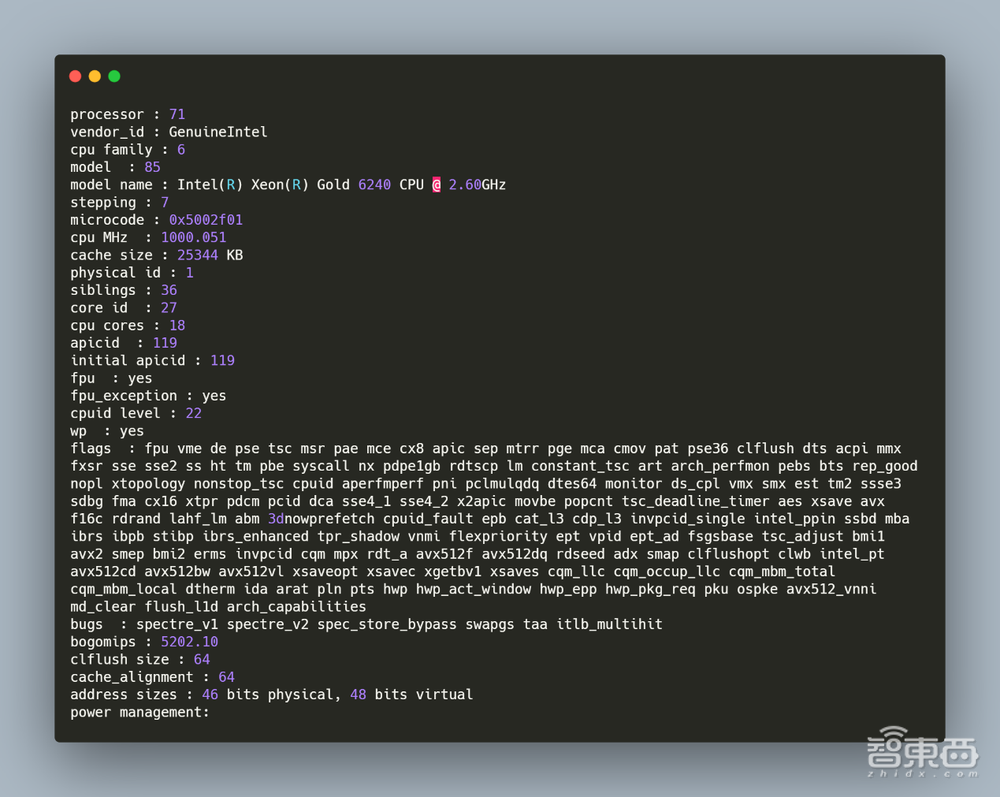
– CPU
图片中的①部分是两颗英特尔® Xeon(R) Gold 6240处理器,可提供72核心144线程,2.6GHz的主频,以及35.75MB的三级缓存。在Linux下可以通过命令cat /proc/cpuinfo查看处理器信息。如下图所示。
-
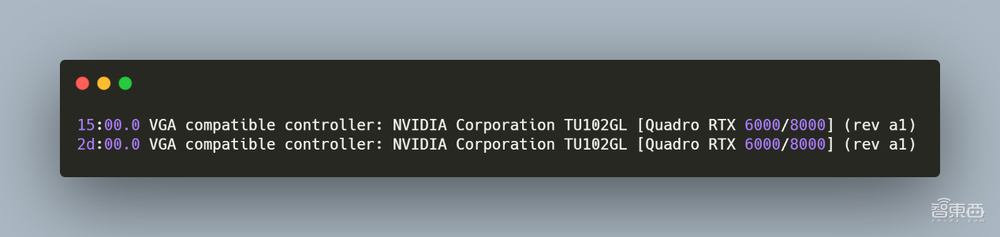
– GPU
图片中的②部分是两块NVIDIA Quadro RTX 8000处理器。NVIDIA Quadro RTX 8000采用了光线追踪技术,配备海量的48 GB超快速GDDR6显存和 NVIDIA NVLink™,可为深度学习带来超凡的性能和可扩展性。在Linux下可以通过命令lspci | grep -i vga看GPU信息。如下图所示。
48G的显存是什么概念呢?RTX 4000的显存是8G、RTX 3090的显存是24G,目前还没有其他的48G显存的GPU。而在深度学习模型训练过程中,48G的显存可以增大batch(批处理数,表示每次输入的图片数量)的大小,一定程度上可以提高模型的泛化能力以及稳定性。
-
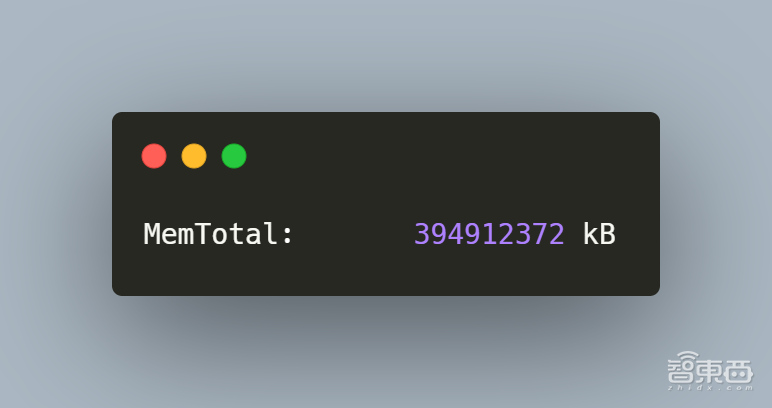
– 内存/硬盘
在侧面图右下角的位置,如图中的③所示,是4个3.5/2.5英寸存储托架,其中预装了2个企业级SATA 的4TB 7200RPM,留有2个可做扩展。同时具有384G内存+1T 大小的M.2 2280 PCIe NVMe TLC SSD,提供了高效的存储读写能力。并且在主机右上靠中间的光驱位还可以再加一块3.5寸大容量硬盘。在Linux下可以通过命令grep MemTotal /proc/meminfo看内存信息。如下图所示。
-
– 散热表现

由于强大的处理器性能,因此对整机的散热功能提出了挑战。HP Z8 G4工作站为每颗处理器都配备了高压风扇散热排,其整机前部和顶部也有多个出风口,后部则有一个大风扇和小风扇用于吸风,可以在保障高性能工作的基础上依然保持一个较低的温度。相比于以前用的电脑主机,没有烫手的温度,也没有“蒸桑拿”式的感受。在出风口处只有淡淡的暖风,并且没有风扇高速旋转的噪音,完全满足了室内工作环境安静的需求。
二、在深度学习模型训练上的表现
介绍完HP Z8 G4工作站的一些关键参数和散热表现后,下面给大家上“主菜”。
目前AI领域最成熟的技术可能就是计算机视觉了,因此也有着很多人开始转入计算机视觉相关的研发工作。而计算机视觉领域中,图像分类和目标检测是两个最基本任务,也是每一个计算机视觉研发人员必须要掌握的技能。下面就这两个任务,我将进行深度学习模型的训练,来实际看看HP Z8 G4工作站的性能到底如何。
1、基本的环境配置和参数
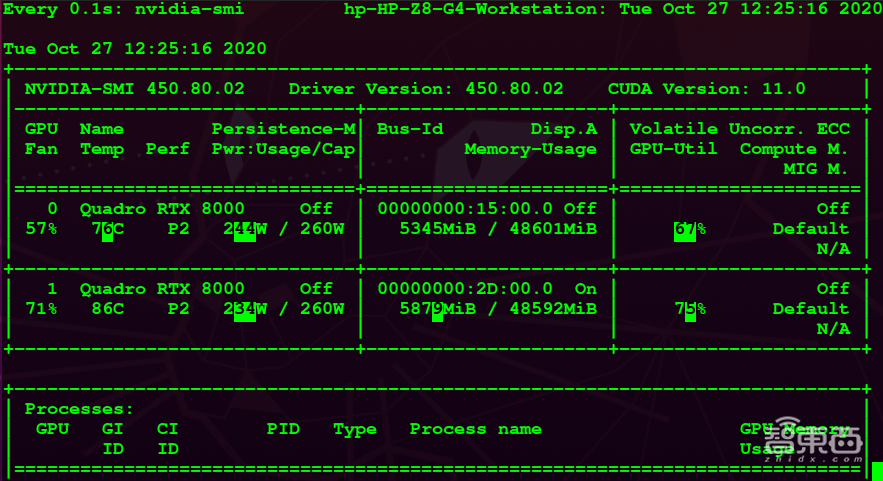
根据NVIDIA官网的推荐,针对NVIDIA Quadro RTX 8000我选取了450版本的驱动进行了安装,并安装了相应版本的CUDA 11.0,实现对GPU计算调用加速。在Linux下可以通过命令NVIDIA-SMI看GPU驱动以及CUDA版本信息。如下图所示。
通过CUDA自带的案例程序,也可以测试并查看一些基本的计算参数,如:
-
– CUDA核心数目
运行程序./NVIDIA_CUDA-11.1_Samples/1_Utilities/deviceQuery/deviceQuery,可查看CUDA信息。如下图。
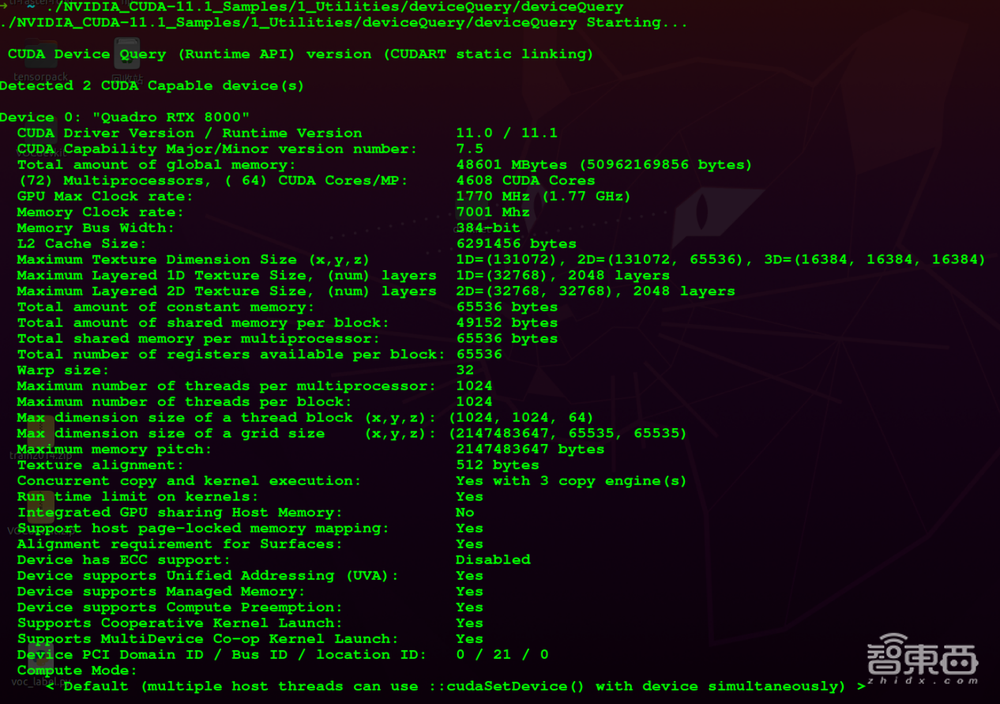
从图中的输出的信息来看,CUDA核心数目为4608个,同时提供48601MB的存储器,1.77GHZ的最大频率和7001MHZ的显卡频率。
-
– 浮点计算能力
运行程序./NVIDIA_CUDA-11.1_Samples/7_CUDALibraries/batchCUBLAS/batchCUBLAS,可测试GPU的单精度计算能力。如下图。
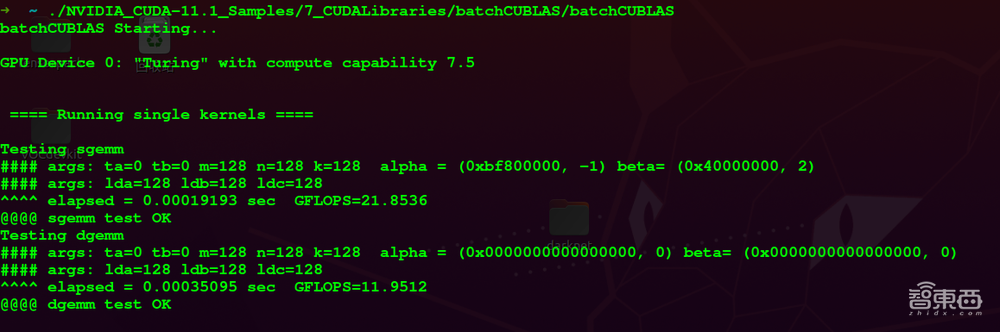
-
– 单精度浮点运算
运行程序./NVIDIA_CUDA-11.1_Samples/7_CUDALibraries/batchCUBLAS/batchCUBLAS可进行测试。如下图。
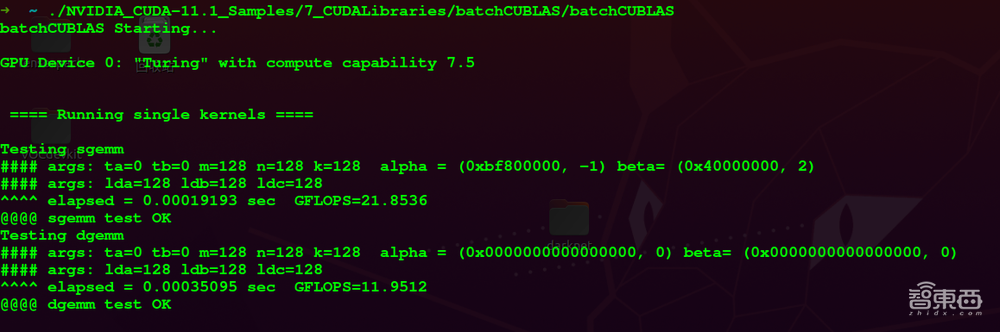
2、图像分类与目标检测模型的训练
(1)基于CIFAR-10和ImageNet数据集的分类模型训练
在本次的分类模型训练中,我分别使用了简单的CNN网络和经典的ResNet50网络,分别对CIFAR-10数据集和ImageNet数据集进行了分类训练。
-
– 模型介绍与数据集介绍
CNN(Convolutional Neural Networks,卷积神经网络)由于其出色的泛化能力,被广泛的应用于物体分类和物体检测等方面,在图像方面有着广泛的应用。而ResNet网络则是2015年由AI学术界大佬何凯明提出的一中卷积神经网络模型,获得了当年ImageNet大规模视觉识别竞赛中图像分类的冠军。
CIFAR-10数据集是一个比较小、也比较常见的图像分类数据集,其共有60000张32×32的彩色图片,图片分为10类,每类6000张图。其中有50000张用于训练,10000张用于测试。
ImageNet数据集则是一个用于视觉对象识别软件研究的大型可视化数据库,其中包含了20000多物体类别,共计约1400万张图像,是计算机视觉领域最具权威的数据集之一。
-
– 模型训练与结果
在本次的实验中,因为CIFAR-10数据集本身的数据量并不多,因此通过构建简单的CNN来进行训练,来直观感受一下HP Z8 G4工作站的计算能力。同时利用经典的ResNet网络,选择使用50层深度的ResNet50来对ImageNet数据集中的图像进行分类训练。训练结果如下。

(2)基于PASCAL VOC和MS COCO数据集的目标检测模型训练
由训练的结果可以看到,在数据量不大的CIFAR-10上的分类模型训练,当batch设置为5000的时候,仅仅只花费了7分钟的时间。在大型数据集ImageNet上,batch同样设置为5000的时候,也只花费了3.5个小时。当然这个准确率可能不太高,但本次实验主要希望得到的是HP Z8 G4工作站的模型训练能力,即计算能力,而不是算法的好坏。
-
– 模型介绍与数据集介绍
图像分类和目标检测是计算机视觉领域的基本任务,而图像分类也是目标检测的基本工作,相较于图像分类任务的复杂度,目标检测任务的复杂度更高,对计算的需求也更大。
在本次的试验中,我选择了目标检测领域经典的网络模型YOLOv3,并将使用它分别在PASCAL VOC和 MS COCO数据集上进行检测模型的训练。
PASCAL VOC和MS COCO都是目标检测领域比较常用的数据集。同时在使用PASCAL VOC数据集的时候,我同时选用了PASCAL VOC 2007和PASCAL VOC 2012并将其合并,包含了20类物体,共计约16万张训练数据,2G图像数据。而MS COCO比PASCAL VOC的数据更加复杂,其中包含了91个物体类别,共计约有20G的图像数据。
-
– 模型训练与结果
YOLOv3通过在PASCAL VOC和MS COCO数据上的检测训练,其训练结果如下。

三、总结
通过训练的结果来看,YOLOv3在较小的PASCAL VOC数据集上训练50020轮的时候,只需要花费5个小时的时间。在具有20G图像数据的MS COCO上训练50020轮的时候,需要花费34个小时,相当于1.5天,时间相对来说还是比较长的。不过因为本次训练只是看模型训练的能力,因此整体的训练效率还是比较高的。
HP Z8 G4工作站所提供的显存真的非常大。两块NVIDIA Quadro RTX 8000,提供2 x 48G的显存。在CIFAR-10分类模型训练过程中,我通过不断调整batch大小后发现,当batch=512的时候,才会产生显存不足的问题,从而导致无法正常训练。
虽然batch的增大会一定程度上提高模型的泛化能力和稳定性,但随着batch的增大,模型的性能反而会下降。因此一般情况batch的设置不会太大,常用的设置为32、64和128。而48G的显存在最大程度上提供了稳定性和提高batch的可能性。
最后从整体的使用体验来看,HP Z8 G4工作站凭借着两块NVIDIA Quadro RTX 8000为整个训练提供了足够的计算能力。完全可以满足中小型模型训练的算力需求。
同时因为其卓越冷却设计和惠普高效的散热解决方案,在整个训练过程中并没有出现很大的噪音和很大的热量,避免了影响其他同事的工作。
