








智东西(公众号:zhidxcom)
编译 | 子佩
编辑 | Panken
智东西11月26日消息,3D渲染的人物头像已经是电影和游戏中的重要组成部分,但如何快速、高效、低成本地生成表情丰富的3D人脸,一直是技术上的“老大难”。
近期,迪士尼和麻省理工学院的研究人员合作研发了一种基于深度神经网络的语义面部模型,用于快速制造多个具有细节特征的人物头像,该论文《深度语义面部模型(Semantic Deep Face Models)》发表至3D视觉国际会议。

论文链接:https://studios.disneyresearch.com/app/uploads/2020/11/Semantic-Deep-Face-Models.pdf
一、3D人像技术迭出,精细情绪仍难表达
从早期,通过主成分分析等简化方法建立人脸三维变化模型,再到后期,基于多尺度方法扩展有细节和变化的人脸模型,关于如何渲染出逼真人像的这个问题,研究者已经走了很长的一段路。
如今,动画特效师已经可以快速制作出高清、逼真的3D人脸,但是人类微表情中的微妙区别,仍难以摹拟。
就以微笑为例,你可以轻松分辨出,身边熟悉的朋友是因为开心真正地大笑,还是只是敷衍应酬的假笑,但要让虚拟人物面部能表达出这种因为情绪产生的细微区别,并不容易。
现在常用的线性面部模型为了工业制造中所需要的快速和标准化,牺牲了这种情绪上的细微表达;新型神经网络模型通过层层数据的反馈,可以让模型自己学会“读情绪”,但像同型模型一样,他们由于参数复杂和计算量巨大,难以直接让创作者上手,应用在动画、电影和游戏制作中。
对此,迪士尼研究院和麻省理工学院合作,提出了一种语义可控、非线性、参数化的人脸模型,通过分离不同维度的特征信息,对三维人脸进行语义分割,从而通过简单地调整参数,让特效动画师能够方便地制作具有细节的人脸模型。
二、面孔、情绪两套编码,通过权重改表情
该套模型的基础逻辑是,将同一张图像中的面部信息和情绪表情分开,然后只关注于不同情绪间“微妙”的变化,最后通过加上色彩光照信息,为虚拟人物赋予生命。
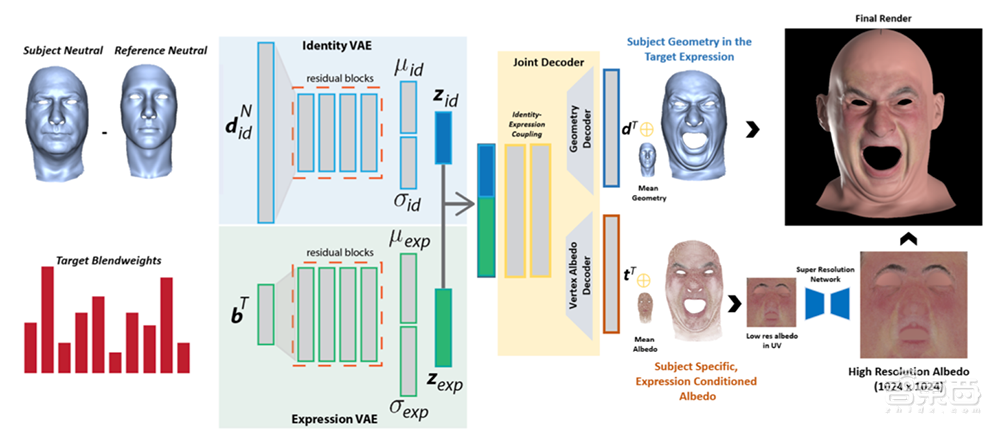
▲深度语义面部模型架构图
该模型所采用的数据集是,224名不同种族、性别、年龄和BMI的受试者,在固定光源、多镜头的环境下,做出的24种情绪表情,最终得到了5376组静态图片,每组也采集了7300帧左右的动态视频。
在剔除不符合要求的数据后,研究人员将每个受试者的24个表情数据作为输入,动态视频作为输出,以最小二乘法作为损失函数,得到每个表情的权重。
为了模拟人物在不同表情下面部光照变化,图像中每一个像素都会进行反照率颜色采样,并存储RGB信息构建六维向量,从而构建出可以反推人物图像色彩变化的反照率模型。
随后,研究人员通过面部、表情两种变分编码器,将人物的面部特征和情绪表情完全分开。

▲不同人物同一情绪
在设计虚拟人物的阶段,动画特效师只需要为人物输入设定的表情,并通过调整表情间的权重,让人物得以表达更为丰富准确的情绪,最后套用训练好的反照率模型,让虚拟人物更为生动逼真,即可快速生成情绪细腻的虚拟人物。
结语:从非0则100,到更精细的情绪表达
深度语义面部模型结合了线性模型和神经网络模型两者的优势。
在线性模型中,虚拟人物们只能表达悲伤或者高兴,或者更简单地比喻,它只能表达出0或者100。神经网络模型则提供了,在悲伤和高兴之间,一百种已经学习过的情绪。
在学习不同语义的表情过后,该模型可以提供0到100之间所有的实数,所以动画特效师可以自由地在任何3D面孔上像滑动滑块一样,选择0到100之间任何情绪。
动画特效师可以快速生成一千个具有长相、肤色各异的面孔,然后赋予不同表情,而无需进行任何额外的工作,这会为游戏、影视行业在降低工作量的同时,提升游戏和观影体验。
但这也不是一劳永逸的万能药,精细情绪表达只是3D人物制作的一部分,无标记面部跟踪、更自然的皮肤形变、逼真的眼部运动以及许多其他有趣的领域,依旧等待着新的变革。
来源:TechCrunch
