








智东西(公众号:zhidxcom)
编译 | 子佩
编辑 | Panken
智东西12月24日消息,继AlphaGo扬名海外后,DeepMind再推新模型MuZero,该模型可以在不知道游戏规则的情况下,自学围棋、国际象棋、日本将棋和Atari游戏并制定最佳获胜策略,论文今日发表至《Nature》。

论文链接:https://arxiv.org/pdf/1911.08265.pdf
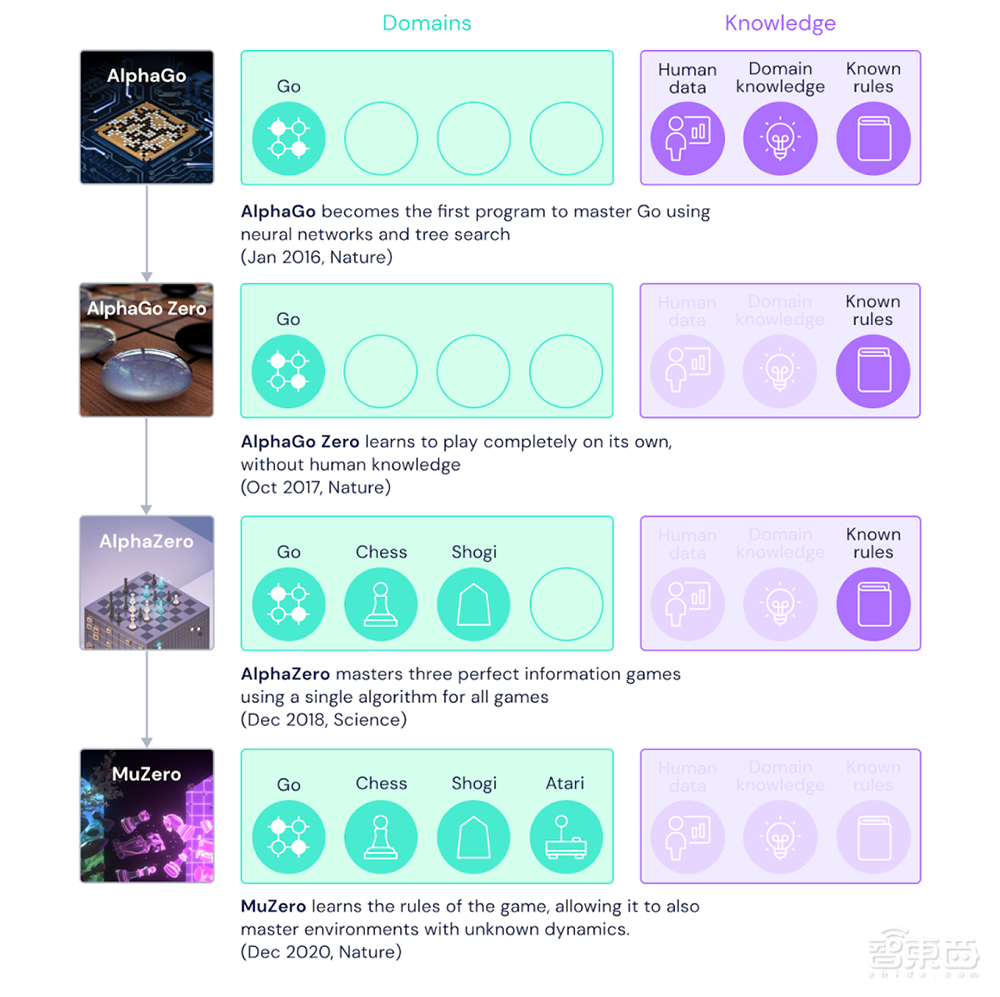
自2016年,令柯洁流泪、让李世石沉默的AlphaGo横空出世,打遍棋坛无人能敌后,AI棋手的名号就此一炮打响,而其背后的发明家DeepMind却没有因此止步,四年之内迭代了四代AI棋手,次次都有新突破。
始祖AlphaGo基于人类棋手的训练数据和游戏规则,采用了神经网络和树状搜索方法,成为了第一个精通围棋的AI棋手。
二代AlphaGo Zero于2017年在《Nature》发表,与上代相比,不需要人类棋手比赛数据作为训练集,而是通过自对抗的方式自己训练出最佳模型。
三代AlphaZero在2018年诞生,将适应领域拓宽至国际象棋和日本将棋,而不是仅限于围棋。
第四代、也就是今天新公布MuZero最大的突破就在于可以在不知道游戏规则的情况下自学规则,不仅在更灵活、更多变化的Atari游戏上代表了AI的最强水平,同时在围棋、国际象棋、日本将棋领域也保持了相应的优势地位。
一、从未知中学习:三要素搭建动态模型
与机器擅长重复性的计算和牢固的记忆不同,人类最大的优势就是预测能力,也就是通过环境、经验等相关信息,推测可能会发生的事情。
比如,当我们看到乌云密布,我们会推测今天可能有雨,然后再重新考虑是否要出门。即使对于仅有几岁的孩子而言,学会这种预测方式,然后推广到生活的方方面面也是很容易,但这对于机器来说并不简单。
对此,DeepMind研究人员提出了两种方案:前向搜索和基于模型的规划算法。
前向搜索在二代AlphaZero中就已经应用过了,它借助对游戏规则或模拟复盘的深刻理解,制定如跳棋、国际象棋和扑克等经典游戏的最佳策略。但这些的基础是已知游戏规则及对可能出现的状况大量模拟,并不适用情况相对混乱的Atari游戏,或者未知游戏规则的情况。
基于模型的规划则是通过学习环境动态进行精准建模,再给予模型给出最佳策略。但对于环境建模是很复杂的,也不适用于Atari等视觉动画极多的游戏。目前来看,能够在Atari游戏中获得最好结果的模型(如DQN、R2D2和Agent57),都是无模型系统,也就是不使用学习过的模型,而是基于预测来采取下一步行动。
也是由于以上两个方法中的优劣,MuZero没有对环境中所有的要素进行建模,而是仅针对三个重要的要素:
1、价值:当前处境的好坏情况;
2、策略:目前能采取的最佳行动;
3、奖励:最后一个动作完成后情况的好坏。
那接下来,我们就来看看MuZero是如何通过这三个要素进行建模。
MuZero从当前位置开始(动画顶部),使用表示功能H将目前状况映射到神经网络中的嵌入层(S0),并使用动态函数(G)和预测函数(F)来预测下一步应该采取的动作序列(A)。

▲基于蒙特卡洛树状搜索和MuZero神经网络进行规划
那如何知道这一步行动好不好呢?
MuZero会与环境进行互动,也是模拟对手下一步的走向。

▲MuZero通过模拟下棋走向训练神经网络。
而每一步棋对于整体棋局的贡献都会被累加,成为本次棋局最后的奖励。
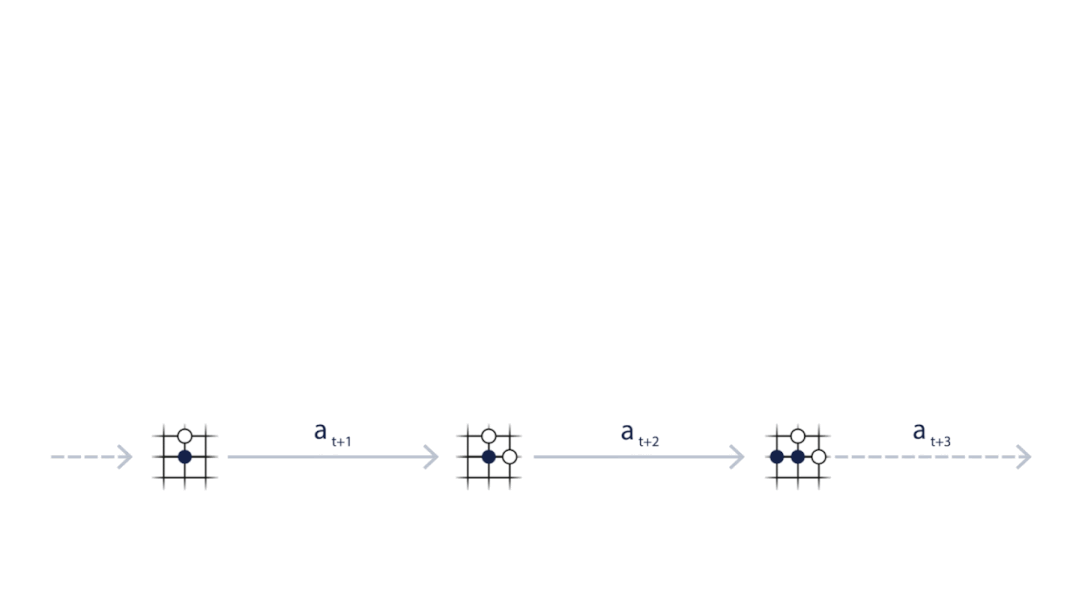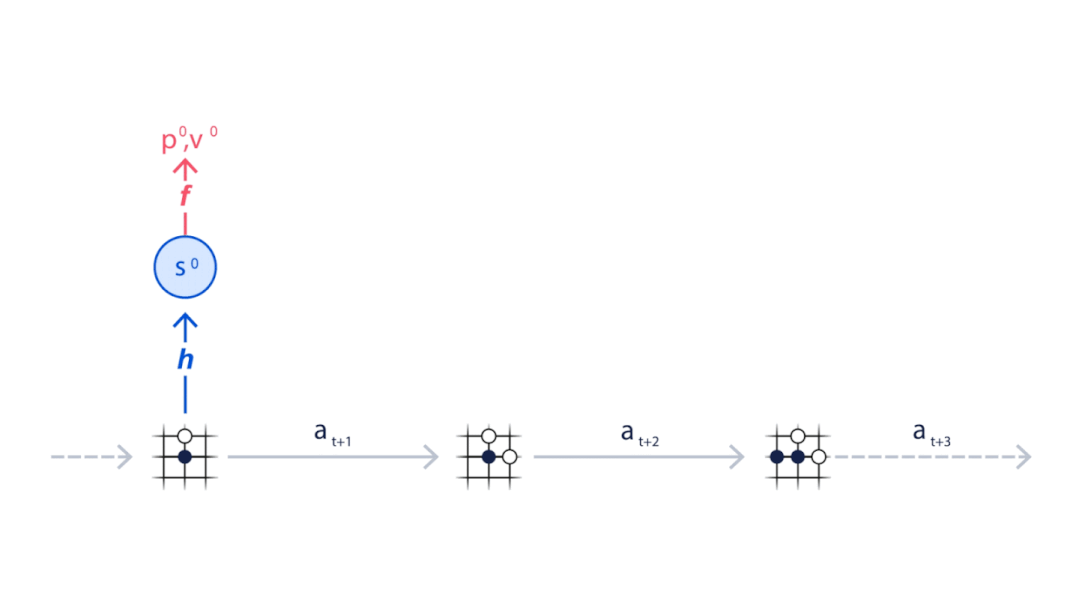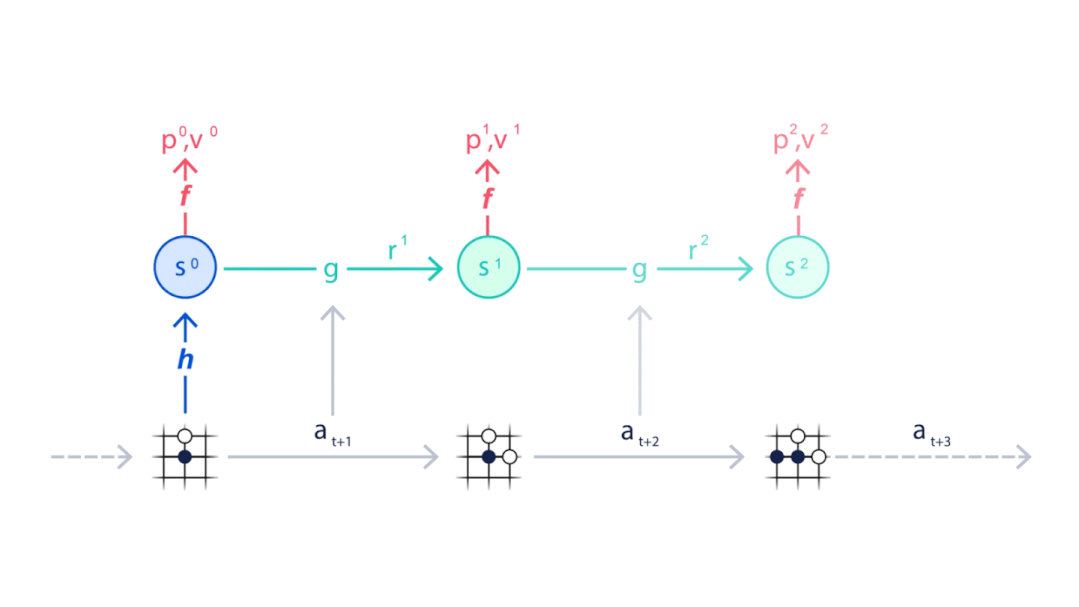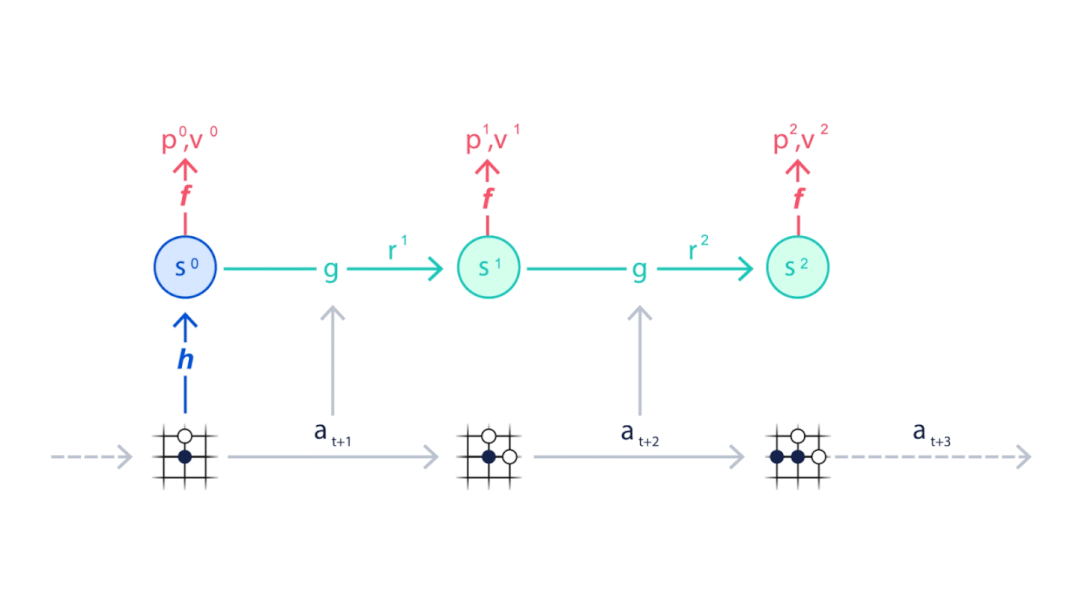
▲策略函数P得到每一步预测下法,价值函数V得到每一步的奖励。
出了减少建模工作量外,这种方法的另一个主要优点就是可以不断复盘,而不需要得到外界的新数据。这样的优势也很明显,在Atari的测试中,名为MuZero Reanalyze的变体可以利用90%的时间使用学习过的模型进行重新规划,找到更优策略。
二、MuZero强在哪?追平前辈,拓宽Atari游戏战场
MuZero模型分别自学了围棋、国际象棋、日本将棋以及Atari游戏,前三者用来评估模型在规划问题上的表现,Atari则用来评估模型面对视觉游戏时的表现。
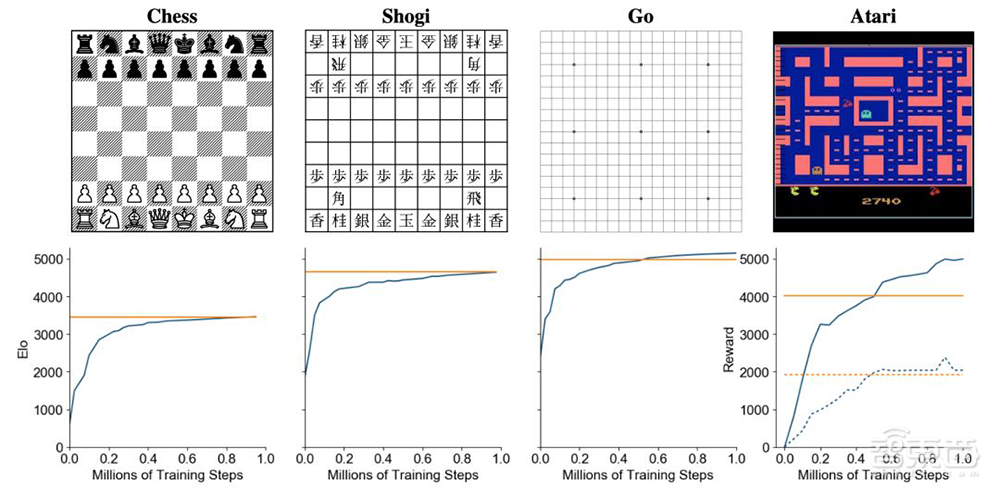
▲MuZero分别在国际象棋、日本将棋、围棋和Atari游戏训练中的评估结果。横坐标表示训练步骤数量,纵坐标表示 Elo评分。黄色线代表AlphaZero(在Atari游戏中代表人类表现),蓝色线代表MuZero。
在围棋、国际象棋和日本将棋中,MuZero不仅在多训练步骤的情况下达到甚至超过了“前辈”AlphaZero的水平,在Atari游戏中,MuZero也表现突出。
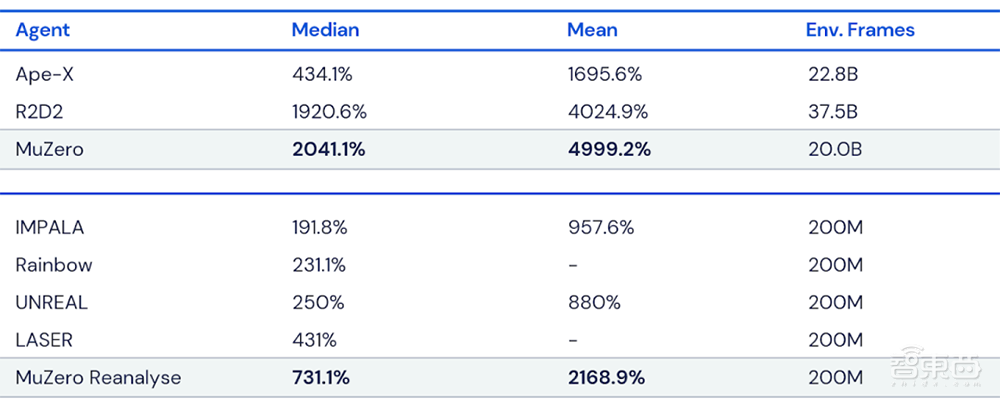
▲MuZero在Atari游戏中的性能。所有得分均根据人类测试的性能进行了归一化,最佳结果以粗体显示。
为了进一步评估MuZero模型的精确规划能力,DeepMind的研究人员还进行了围棋中经典的高精度规划挑战,即指下一步就判断胜负。
为了证实更多的训练时间能使MuZero模型更强大,DeepMind进行了如下面左图实验,当每一步的判断时间从0.1秒延长到50秒,评价玩家技能的Elo指标能增加1000,相当于业余棋手和最强职业棋手之间的区别。
而在右图的Atari游戏Ms Pac-Man(吃豆小姐)的测试中,也能很明显地看出训练时长越长时,模型表现越好。
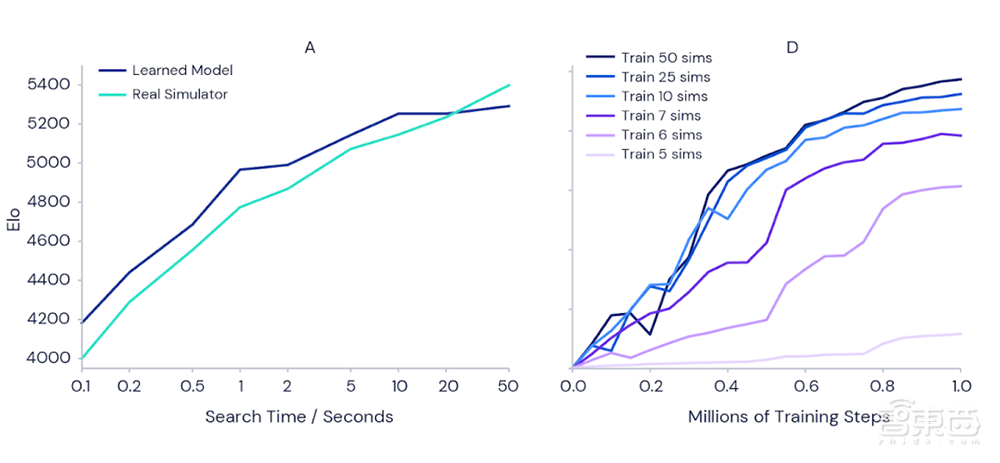
▲左图:随着步骤判断时间增加,围棋Elo指标上涨;右图:训练时长越长,模型表现越好
结语:出身于游戏,期待更多应用
基于环境要素建模的MuZero,用在多个游戏上的“超人”表现证明了卓越的规划能力,也象征着DeepMind又一在强化学习和通用算法方面的重大进步。
它的前辈AlphaZero也已投身于化学、量子物理学等领域,切身实地地为人类科学家们解决一系列复杂问题。在未来,MuZero是否可以继承“家业”,应对机器人、工业制造、未知“游戏规则”的现实问题所带来的挑战,我们拭目以待。
来源:DeepMind
