








智东西(公众号:zhidxcom)
编译 | 子佩
编辑 | Panken
智东西1月7日消息,2021开年,顶着地表最强语言模型GPT-3的光环,OpenAI在自然语言处理领域一路高歌猛进,于昨日推出两个跨越文本与图像次元的模型:DALL·E和CLIP,前者可以基于文本生成图像,后者则可以基于文本对图片进行分类,两者都意在打破自然语言处理和计算机视觉两大门派“泾渭分明”的界限,实现多模态AI系统。
什么是多模态系统呢?
就像人类有视觉、嗅觉、听觉一样,AI也有自己“眼鼻嘴”,而为了研究的针对性和深入,科学家们通常会将其分为“计算机视觉”、“自然语言处理”、“语音识别”等研究领域,分门别类地解决不同的实际问题。
每一个研究领域也可以被称为一种模态,通常来说,多模态学习(MultiModal Learning)就是在不同的模态间构建联系,让AI学会“通感”。
一、GPT-3“继承者”:看文绘图的DALL·E
DALL·E的名字取自艺术家Salvador Dali和皮克斯动画片机器人总动员(WALL-E),而与GPT-3一样,它也是一个具有120亿参数的Transformer语言模型,不同的是,GPT-3生成的是文本,DALL·E生成的是图像。

▲Dali代表作《记忆的永恒》和机器人总动员海报。
在博客上,OpenAI也大秀了一把DALL·E的“超强想象力”,随意输入一句话,DALL·E就能生成相应图片,这个图片可能是网络上已经存在的图片,也可能是根据自己的理解“画”出的。

▲输入文本分别是:穿芭蕾舞裙遛狗的萝卜、牛油果形状的扶手椅、将上部的图片素描化
DALL·E是如何实现先理解文字,再创造图片的呢?
那首先要从理解token开始,语言学中对token的定义是词符,或者标记。对于英语来说,每个字母就是一个token,每一个单词就是一个tokens。
但在NLP中,tokens并不一定代表完整的单词,如re、ug等没有实际意义的字母组合也算一个tokens。
在最早提出Transformer架构的论文《Attention is all you need》里,就提到了BPE(Byte-Pair Encoding)编码方法,简单来说,BPE就是通过分析训练集中每个单词的组成,创建一个基础词汇表,词汇表里涵盖了一定数量最常用的tokens。
模型中tokens的数量是超参数,也就是训练模型中人为规定的。
DALL·E同时包含着BPE编码的文本和图像词汇表,分别涵盖了16384、8192个tokens。
当需要生成图片时,它以单一数据流的形式,接收1280个文本和图像的tokens(文本256个tokens,图像1024个tokens),建立回归模型。
与大多数Transformer模型一样,DALL·E也采用自注意力机制(Self-Attention),分析文本内部的联系。
在DALL·E的64层自注意层中,每层都有一个注意力mask,就是为了使图像的每个tokens都能匹配文本tokens。
OpenAI也表示,更具体的架构和详细训练过程会在之后的博客中公布。
二、普适的DALL·E:从改变物体关系到创造“不存在”
比起长篇累牍地描述自己模型的优越性,OpenAI则是用大量实测案例证明了自己。
1、改变单个物体的某个属性
如动图所示,我们可以通过简单地改变按钮选项,将钟改为花盆,再将绿色改为黄色,再将三角形改为正方形。

▲原输入文本:三角形绿色的钟
2、同时改变多个物体以及其位置关系
将上方的物块改成书,再将物体的上下叠放关系改成左右摆放。

当一句话含有多个主体时,例如“红色的物块放在绿色的物块上面”,DALL·E需要分辨出这两个物块是两个不同的物体,且他们之间的位置关系是上下叠放。
但OpenAI的研究人员也承认,随着输入文本中描述主体的增多和关系的复杂,DALL·E生成的图像会更不准确。

▲输入文本:一堆立方体,红色的立方体在绿色立方体的顶部,绿色立方体在中间,蓝色立方体在底部。
3、可视化透视与背景
如动图所示,将特写图改成前视图,将背景从草地改成山上。

▲原输入文本:特写图下,在草地的水豚
除了二维图像理解,DALL·E也能将某些类型的光学畸变(Optical Distortions)应用到具体场景中,展现出“鱼眼透视”或“球形全景态”图等效果。
4、内外部结构

▲输入文本:核桃横截面图
5、上下文推理
将文本目标“翻译”成图像这个问题,是没有唯一答案的,且语言中常含有字面所没有的引申义。
如“日出时,坐在田野上的水豚的绘画像”这一文本目标,其中并没有提到水豚的阴影,但根据经验我们也能知道,日出时,水豚必然会有由于阳光照射产生阴影。
因此,DALL·E就需要通过Transformer中的上下文推理,通过自己的“经验”,得到这一结论。

▲输入文本:日出时,坐在田野上的水豚的绘画像。
6、不存在的物品
DALL·E还具有将完全不同的物品合成起来的能力,创造一些现实世界不可能出现的物体。

▲输入文本:竖琴状的蜗牛
三、“zero-shot”践行者:按词分图的CLIP
如果说DALL·E是GPT-3在图像领域的延伸,那CLIP就是主打“zero-shot(零样本)”,攻破视觉领域的深度学习方法的三大难题。
1、训练所需大量数据集的采集和标注,会导致的较高成本。
2、训练好的视觉模型一般只擅长一类任务,迁移到其他任务需要花费巨大成本。
3、即使在基准测试中表现良好,在实际应用中可能也不如人意。
对此,OpenAI联合创始人Ilya Sutskever曾发文声称,语言模型或是一种解法,我们可以通过文本,来修改和生成图像。
基于这一愿景,CLIP应运而生。
CLIP全称是Contrastive Language-Image Pre-training,根据字面意思,就是对比文本-图像预训练模型,只需要提供图像类别的文本描述,就能将图像进行分类。
怎么分?为什么能分?
CLIP靠的就是预训练阶段,OpenAI从互联网中收集的4亿个文本-图像对。接着,凭着与GPT-2/3相似的“zero-shot”设计,CLIP在不直接针对基准进行优化的同时,表现出优越的性能:鲁棒性差距(robustness gap)缩小了75%,性能和深度残差网络ResNet50相当。
也就是说,CLIP无需使用ResNet50同样大的训练样本,就达到了原始ResNet50在ImageNet数据集上的精确度。
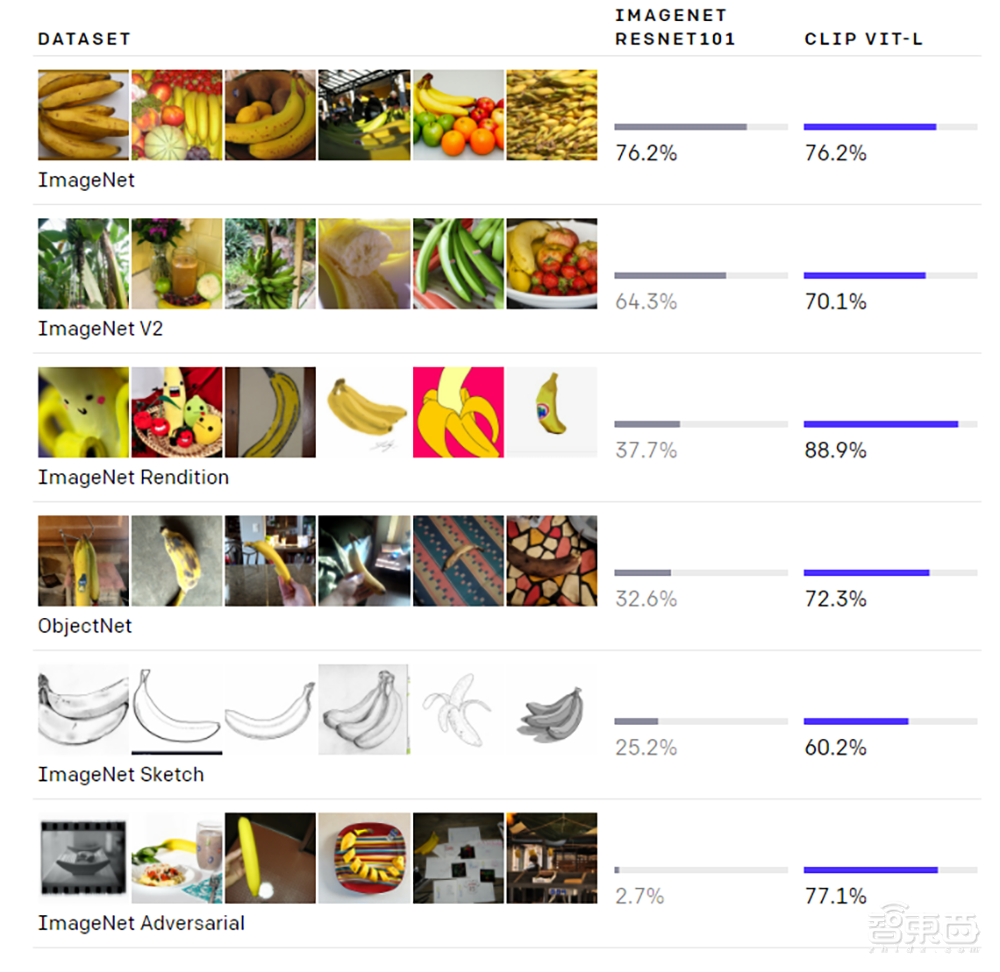
在众多数据集上,CLIP都有着可以与ResNet50升级版ResNet101媲美的精度,其中ObjectNet数据集代表模型识别物体不同形态和背景的能力,ImageNet Rendition和ImageNet Sketch代表模型识别抽象物体的能力。
虽然二者在ImageNet测试集上的表现相差无几,但非ImageNet设置更能代表CLIP优秀的泛化能力。
为了识别出未曾见过的类别(图像或文本),Zero-shot这一概念可以追溯到十年前,而目前计算机视觉领域应用的重点是,利用自然语言作为灵活的预测空间,实现泛化和迁移。
在2013年,斯坦福大学的Richer Socher教授就曾在训练CIFAR-10的模型时,在词向量嵌入空间中进行预测,并发现该模型可以预测两个“未见过”的类别。
刚刚登上历史舞台、用自然语言学习视觉概念的CLIP则带上了更多现代的架构,如用注意力机制理解文本的Transformer、探索自回归语言建模的Virtex、研究掩蔽语言建模的ICMLM等。
四、详细解析,CLIP的“足”与“不足”
在对CLIP有一个基本的认识后,我们将从四个方面详细剖析CLIP。
1、从CLIP流程,看三大问题如何解决
简单来说,CLIP的任务就是识别一张图像所出现的各种视觉概念,并且学会它的名称。比如当任务是对猫和狗的图片进行分类,CLIP模型就需要判断,目前处理的这张图片的文字描述是更偏向于“一张猫的照片”,还是一张狗的照片。
在具体实现上,有如下流程:预训练图像编码器和文本编码器,得到相互匹配的图像和文本,基于此,CLIP将转换为zero-shot分类器。此外,数据集的所有类会被转换为诸如“一只狗的照片”之类的标签,以此标签找到能够最佳配对的图像。
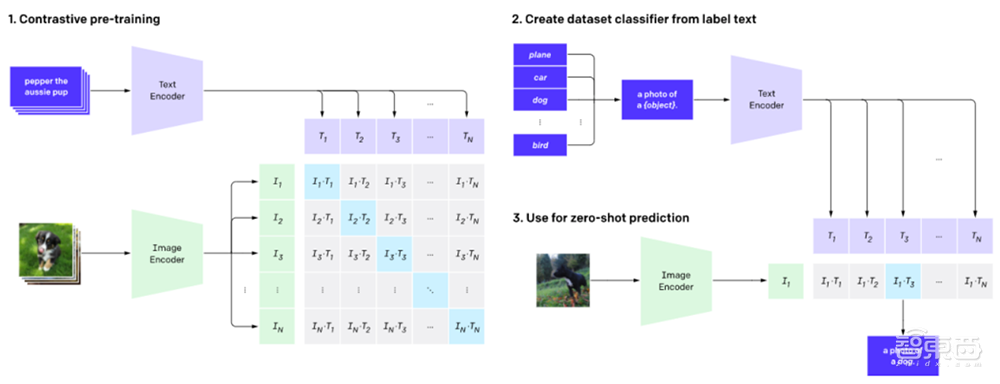
在这个过程中,CLIP也能解决之前提到的三大问题。
1、昂贵的数据集:25000人参与了ImageNet中1400万张图片的标注。与此相比,CLIP使用的是互联网上公开的文本-图像对,在标注方面,也利用自监督学习、对比方法、自训练方法以及生成建模等方法减少对人工标注的依赖。
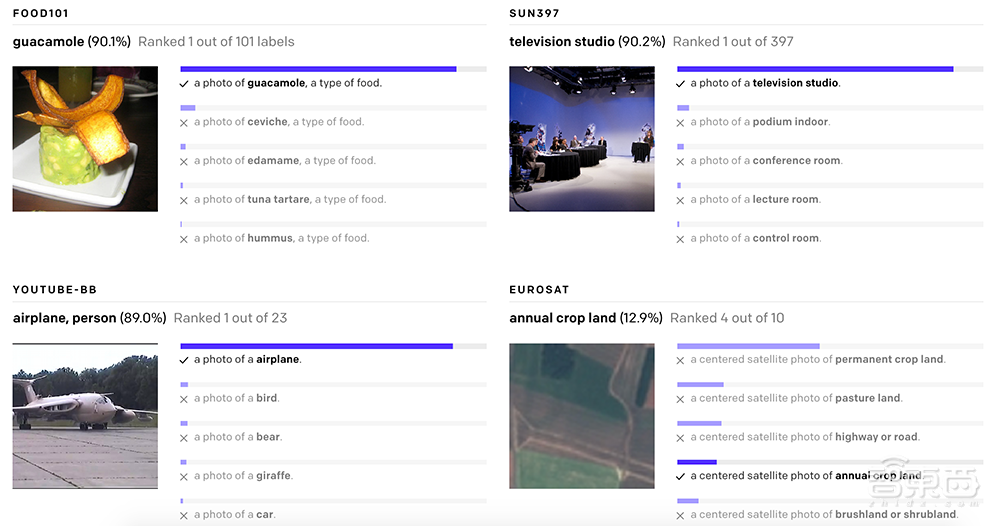
2、只适用于单一任务:由于已经学会图片中的各种视觉概念,所以CLIP可以执行各种视觉任务,而不需要额外的训练和调整。如下也展示了CLIP模型识别各类型图像中视觉概念,无论是食物、场景还是地图,都是有不错的表现。
3、实际应用性能不佳:基准测试中表现好的模型在实际应用中很可能并没有这么好的水平。就像学生为了准备考试,只重复复习之前考过的题型一样,模型往往也仅针对基准测试中的性能进行优化。但CLIP模型可以直接在基准上进行评估,而不必在数据上进行训练。
2、CLIP的“足”:高效且灵活通用。
CLIP需要从未经标注、变化多端的数据中进行预训练,且要在“zero-shot”,即零样本的情况下使用。GPT-2/3模型已经验证了该思路的可行性,但这类模型需要大量的模型计算,为了减少计算量,OpenAI的研究人员采用了两种算法:对比目标(contrastive objective)和Vision Transformer。前者是为了将文本和图像连接起来,后者使计算效率比标准分类模型提高了三倍。
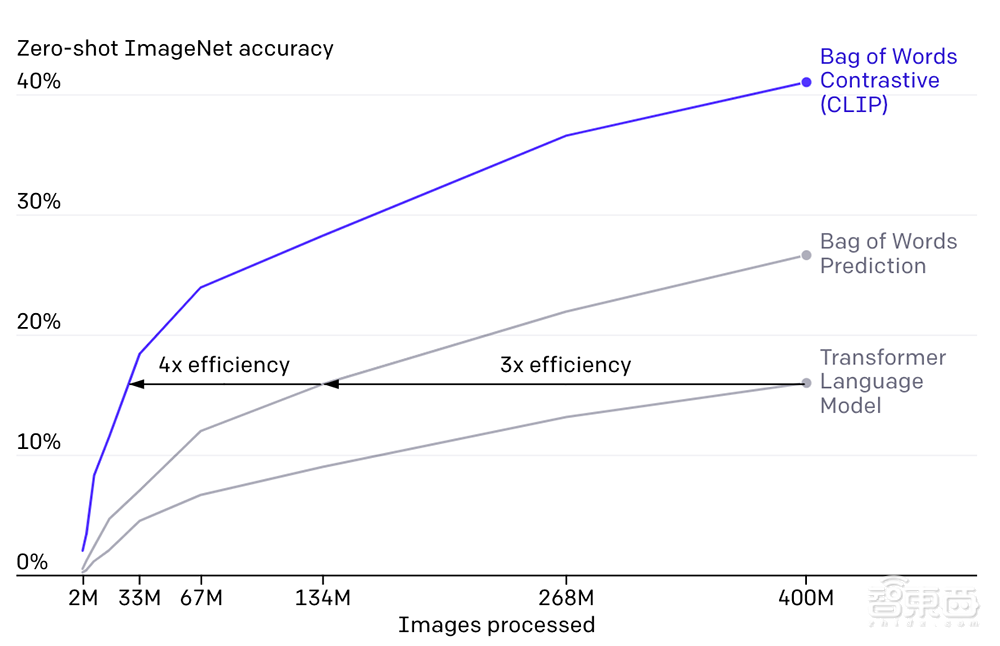
▲CLIP模型在准确率和处理图像大小上都优于其他两种算法。
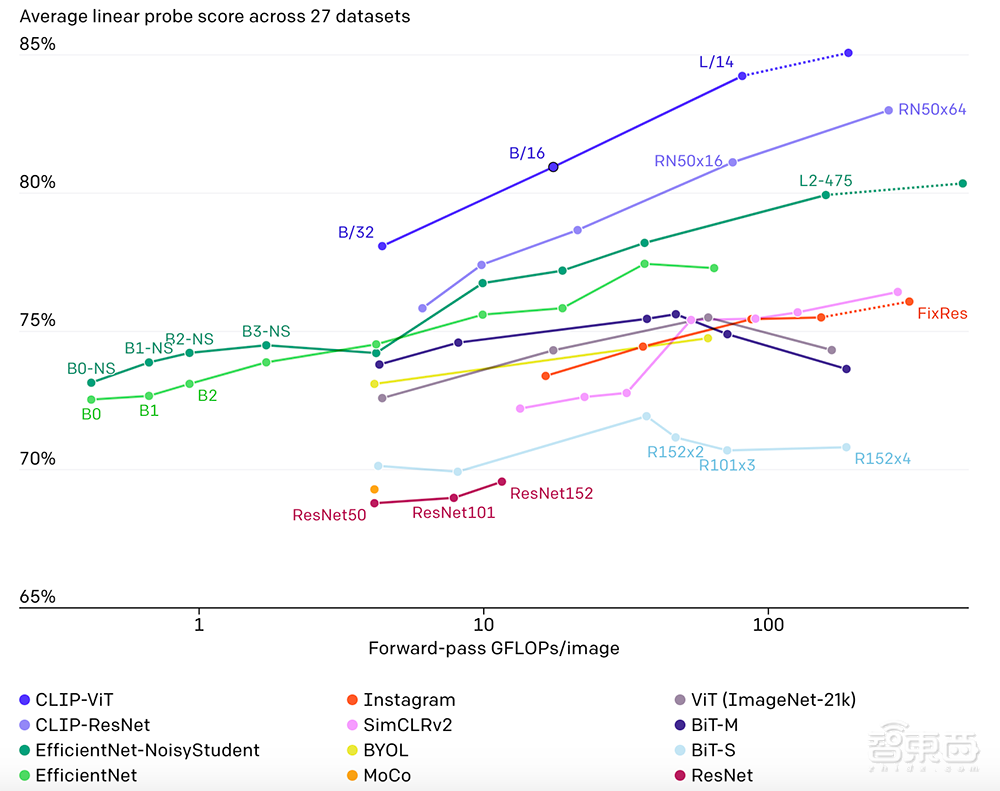
由于CLIP模型可以直接从自然语言中学习许多视觉概念,因此它们比现有的ImageNet模型更加灵活与通用。OpenAI的研究人员在30多个数据集上评估了CLIP的“zero-shot”性能,包括细粒度物体分类,地理定位,视频中的动作识别和OCR(光学字符识别)等。
下图也展示了12种模型在27种数据集准确率和处理图像大小的比较。CLIP-ViT和CLIP-ResNet两类CLIP方法都遥遥领先。
3、CLIP的“不足”:复杂任务仍有差距
尽管CLIP在识别常见物体上表现良好,但在如计算图像中物品数量、预测图片中物品的位置距离等更抽象、复杂的任务上,“zero-shot”CLIP表现仅略胜于随机分类,而在区分汽车模型、飞机型号或者花卉种类时,CLIP也不好。
且对于预训练阶段没有出现过的图像,CLIP泛化能力也很差。例如,尽管CLIP学习了OCR,但评估MNIST数据集的手写数字上,“zero-shot”CLIP准确率只达到了88%,远低于人类在数据集中的99.75%精确度。最后,研究人员发现,CLIP的“zero-shot”分类器对单词构造或短语构造比较敏感,但有时还是需要试验和错误“提示引擎”的辅助,才能表现良好。
4、CLIP未来:算法公正仍需努力
研究人员也在博客中提到,CLIP更大的潜力是允许人们设计自己的分类,无需使用特定任务的训练数据。因为分类的定义方法会影响模型的性能和偏差。
如果CLIP中添加的标签包括Fairface种族标签(FairFace是一个涵盖不同人种、性别的面部图像数据集)和少数负面名词,例如“犯罪”,“动物”等,那么很可能大约32.3%年龄为0至20岁的人像会被划分到负面类别中,但在添加“儿童”这一标签后,负面类别的比例大约下降到8.7%。
此外,由于CLIP不需要针对特定任务训练数据,所以能够更轻松地完成一些任务。但这些任务会不会涉及到特定的隐私和监视风险,需要进一步的研究。
结语:模型很厉害,监管需谨慎
无论是DALL·E还是CLIP,都采用不同的方法在多模态学习领域跨出了令人惊喜的一步。
但OpenAI的研究人员也反复强调,越强大的模型一旦失控,后果也越加可怕,所以两个模型后续的关于“公平性”、“隐私性”等问题研究也会继续进行。
今后,文本和图像的界限是否会进一步被打破,我们能否能顺畅地用文字“控制”图像的分类和生成,在现实生活中将会带来怎样的改变,都值得我们期待。
来源:OpenAI
