








GPU是Graphics Processing Unit(图形处理器)的简称,它是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上运行绘图运算工作的微处理器。图形处理器是NVIDIA公司(NVIDIA)在1999年8月发表NVIDIA GeForce 256(GeForce 256)绘图处理芯片时首先提出的概念,在此之前,电脑中处理影像输出的显示芯片,通常很少被视为是一个独立的运算单元。而对手冶天科技(ATi)亦提出视觉处理器(Visual Processing Unit)概念。图形处理器使显卡减少对中央处理器(CPU)的依赖,并分担部分原本是由中央处理器所担当的工作,尤其是在进行三维绘图运算时,功效更加明显。图形处理器所采用的核心技术有硬件坐标转换与光源、立体环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等。
图形处理器可单独与专用电路板以及附属组件组成显卡,或单独一片芯片直接内嵌入到主板上,或者内置于主板的北桥芯片中,现在也有内置于CPU上组成SoC的。个人电脑领域中,在2007年,90%以上的新型台式机和笔记本电脑拥有嵌入式绘图芯片,但是在性能上往往低于不少独立显卡。但2009年以后,AMD和英特尔都各自大力发展内置于中央处理器内的高性能集成式图形处理核心,它们的性能在2012年时已经胜于那些低端独立显卡,这使得不少低端的独立显卡逐渐失去市场需求,两大个人电脑图形处理器研发巨头中,AMD以AMD APU产品线取代旗下大部分的低端独立显示核心产品线。而在手持设备领域上,随着一些如平板电脑等设备对图形处理能力的需求越来越高,不少厂商像是高通(Qualcomm)、Imagination、ARM、NVIDIA等,也在这个领域“大显身手”。
GPU不同于传统的CPU,如Intel i5或i7处理器,其内核数量较少,专为通用计算而设计。相反,GPU是一种特殊类型的处理器,具有数百或数千个内核,经过优化,可并行运行大量计算。虽然GPU在游戏中以3D渲染而闻名,但它们对运行分析、深度学习和机器学习算法尤其有用。GPU允许某些计算比传统CPU上运行相同的计算速度快10倍至100倍。
本期的智能内参,我们推荐方正证券的报告《GPU研究框架》,从GPU的底层技术、产业链发展情况和国产GPU的自主之路三方面全面解析GPU及其产业。
本期内参来源:方正证券
原标题:
《GPU研究框架》
作者:陈杭 等
一、GPU:专用计算时代的“画师”
GPU(graphics processing unit)图形处理器,又称显示核心、视觉处理器、显示芯片,是一种在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。GPU通常包括图形显存控制器、压缩单元、BIOS、图形和计算整列、总线接口、电源管理单元、视频管理单元、显示界面。GPU的出现使计算机减少了对CPU的依赖,并解放了部分原本CPU的工作。在3D图形处理时,GPU采用的核心技术有硬件T&L(几何转换和光照处理)、立方环境材质贴图和顶点混合、纹理压缩和凹凸映射贴图、双重纹理四像素256位渲染引擎等,而硬件T&L技术可以说是GPU的标志。
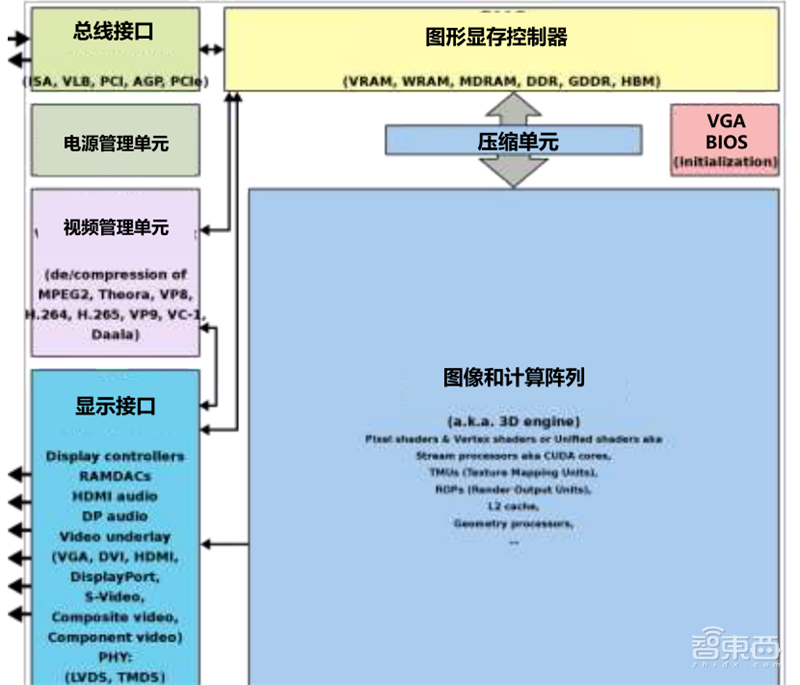
▲GPU的内部组成部分

▲GPU核心及PCB板
GPU的微架构(Micro Architecture)是一种给定的指令集和图形函数集合在处理器中执行的方法。图形函数主要用于绘制各种图形所需要的运算。当前和像素、光影处理、3D坐标变换等相关运算由GPU硬件加速来实现。相同的指令集和图形函数集合可以在不同的微架构中执行,但实施的目的和效果可能不同。优秀的微架构对GPU性能和效能的提升发挥着至关重要的作用,GPU体系是GPU微架构和图形API的集合。
以目前最新的英伟达安培微架构为例,GPU微架构的运算部份由流处理器(Stream Processor,SP)、纹理单元(Texture mapping unit, TMU)、张量单元(Tensor Core)、光线追踪单元(RT Cores)、光栅化处理单元(ROPs)组成。这些运算单元中,张量单元,光线追踪单元由NVIDIA在伏特/图灵微架构引入。
除了上述运算单元外,GPU的微架构还包含L0/L1操作缓存、Warp调度器、分配单元(Dispatch Unit)、寄存器堆(register file)、特殊功能单元(Special function unit,SFU)、存取单元、显卡互联单元(NV Link)、PCIe总线接口、L2缓存、二代高位宽显存(HBM2)等接口。
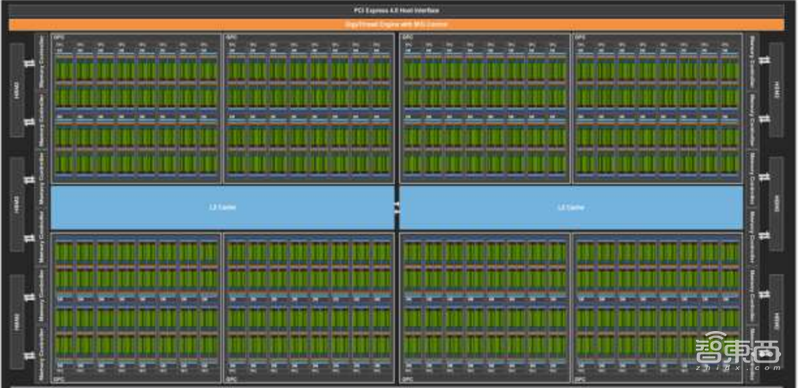
▲英伟达安培内核概览
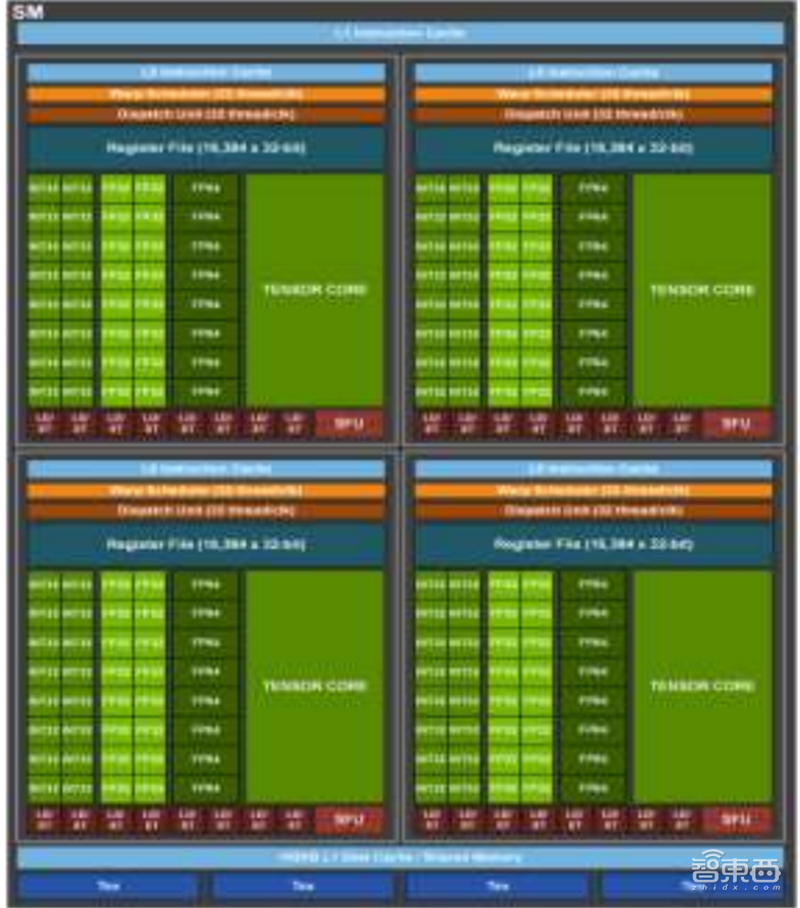
▲英伟达安培内核“SM”单元
GPU的流处理器单元是NVIDIA对其统一架构GPU内通用标量着色器的命名。SP单元是全新的全能渲染单元,是继Pixel Pipelines(像素管线)和Vertex Pipelines(顶点管线)之后新一代的显卡渲染技术指标。SP单元既可以完成VS(Vertex Shader,顶点着色器)运算,也可以完成PS(Pixel Shader,像素着色器)运算,而且可以根据需要组成任意VS/PS比例,从而给开发者更广阔的发挥空间。
流处理器单元首次出现于DirectX 10时代的G80核心的Nvidia GeForce 8800GTX显卡,是显卡发展史上一次重大的革新。之后AMD/ATI的显卡也引入了这一概念,但是流处理器在横向和纵向都不可类比,大量的流处理器是GPU性能强劲的必要非充分条件。
纹理映射单元(TMU)作为GPU的部件,它能够对二进制图像旋转、缩放、扭曲,然后将其作为纹理放置到给定3D模型的任意平面,这个过程称为纹理映射。纹理映射单元不可简单跨平台横向比较,大量的纹理映射单元是GPU性能强劲的必要非充分条件。
光栅化处理单元(ROPs)主要负责游戏中的光线和反射运算,兼顾AA、高分辨率、烟雾、火焰等效果。游戏里的抗锯齿和光影效果越厉害,对ROPs的性能要求就越高,否则可能导致帧数的急剧下降。NVIDIA的ROPs单元是和流处理器进行捆绑的,二者同比例增减。在AMD GPU中,ROPs单元和流处理器单元没有直接捆绑关系。
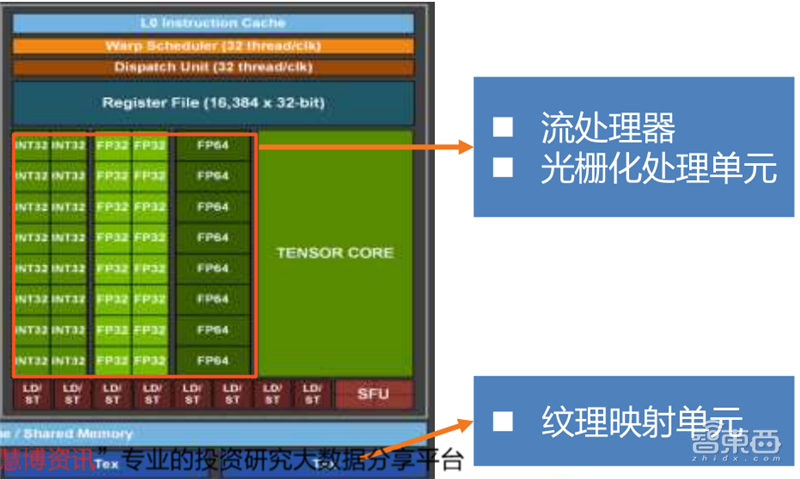
▲英伟达安培内核SP、ROPs、TMU拆解
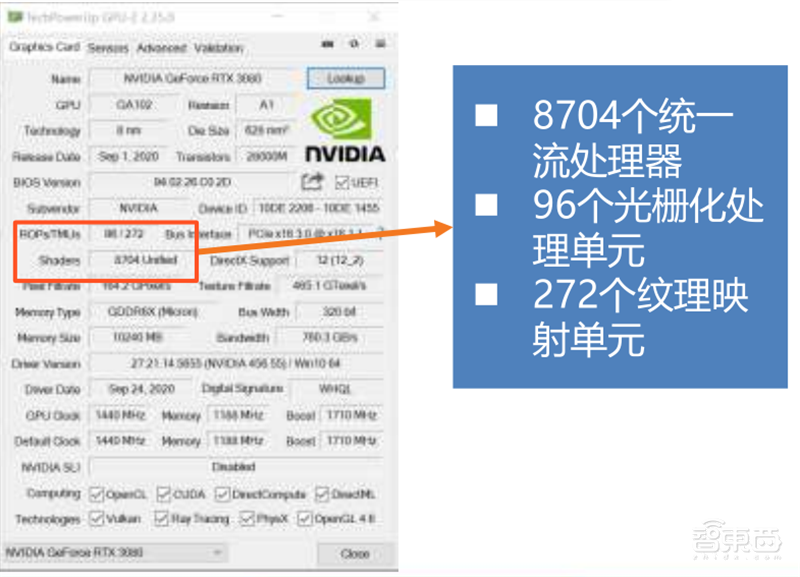
▲英伟达RTX 3080 GPU-Z参数
消费GPU的实时光线追踪在2018年由英伟达的“图灵”GPU首次引入,光追单元(RT Cores)在此过程中发挥着决定性的作用。图灵GPU的光追单元支持边界体积层次加速,实时阴影、环境光、照明和反射,光追单元和光栅单元可以协同工作,进一步提高帧数和阴影的真实感。
光追单元在英伟达的RTX光线追踪技术、微软DXR API、英伟达Optix API和Vulkan光追API的支持下可以充分发挥性能。拥有68个光追单元的RTX2080Ti在光线处理性能上较无光追单元的GTX1080Ti强10倍。
张量单元(Tensor Core)在2017年由英伟达的“伏特”GPU中被首次引入。张量单元主要用于实时深度学习,服务于人工智能,大型矩阵运算和深度学习超级采样(DLSS),可以带来惊人的游戏和专业图像显示,同时提供基于云系统的快速人工智能。
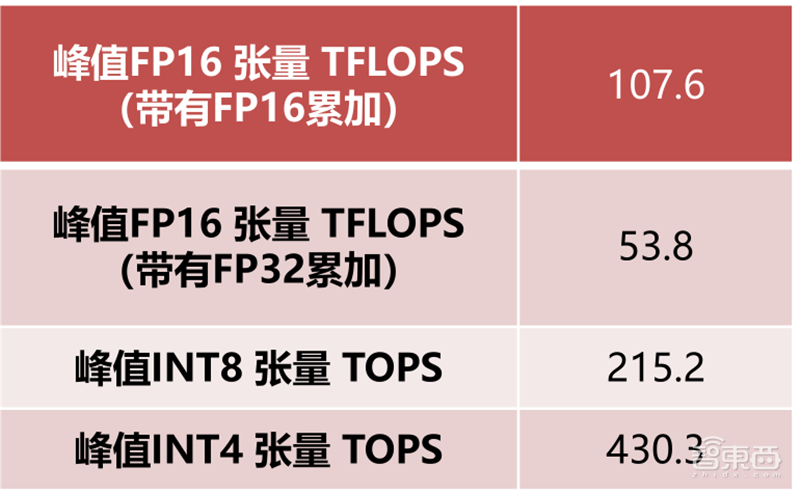
▲英伟达RTX2080Ti张量单元算力
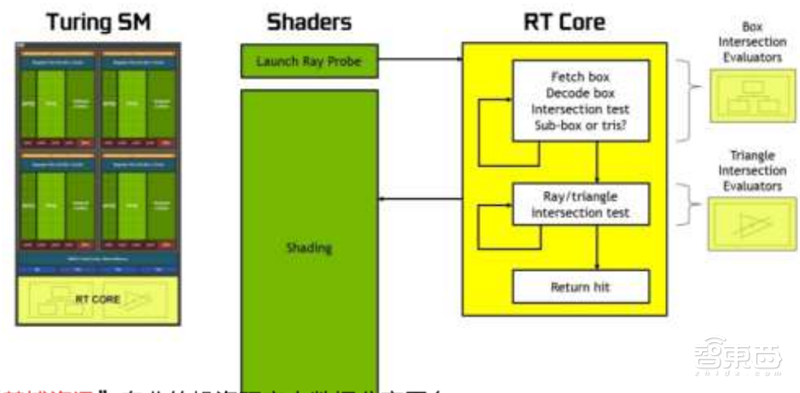
▲英伟达图灵GPU光追单元运作流程
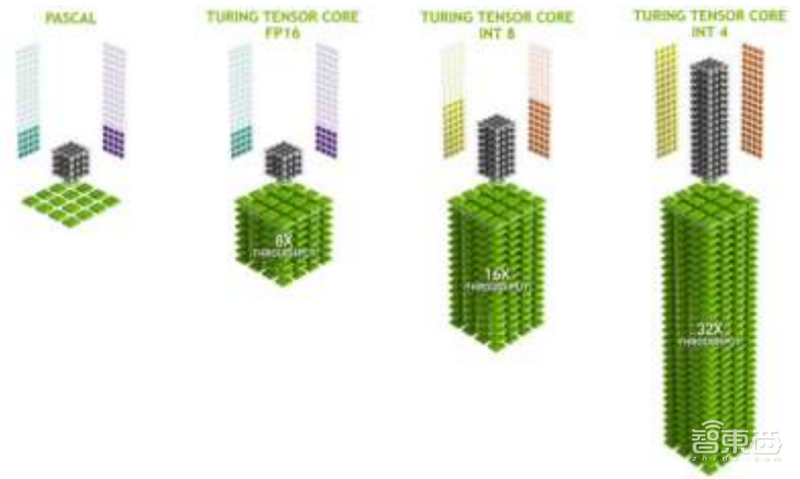
▲英伟达图灵GPU张量单元提供多精度AI
GPU的API(Application Programming Interface)应用程序接口发挥着连接应用程序和显卡驱动的桥梁作用。不过随着系统优化的深入,API也可以直接统筹管理高级语言、显卡驱动和底层汇编语言。
3D API能够让编程人员所设计的3D软件只需调动其API内的程序,让API自动和硬件的驱动程序沟通,启动3D芯片内强大的3D图形处理功能,从而大幅地提高3D程序的设计效率。同样的,GPU厂家也可以根据API标准来设计GPU芯片,以达到在API调用硬件资源时的最优化,获得更好的性能。3D API可以实现不同厂家的硬件、软件最大范围兼容。如果没有API,那么开发人员必须对不同的硬件进行一对一的编码,这样会带来大量的软件适配问题和编码成本。
目前GPU API可以分为2大阵营和若干其他类。2大阵营分别是微软的DirectX标准和KhronosGroup标准,其他类包括苹果的Metal API、AMD的Mantle(地幔)API、英特尔的One API等。
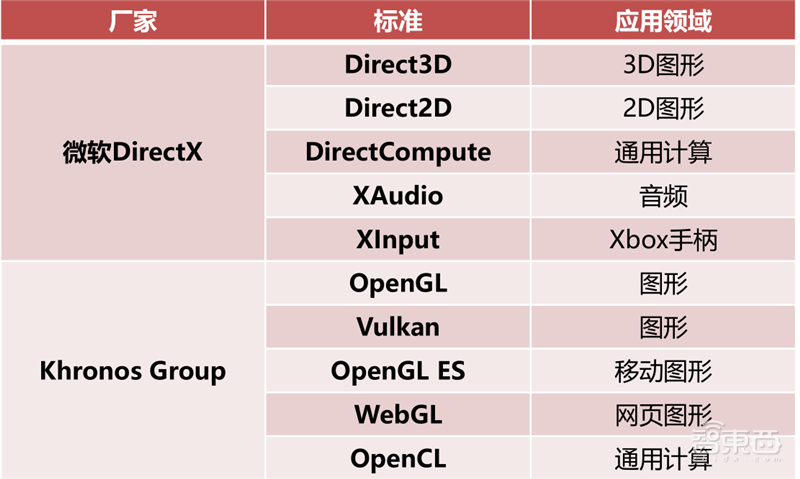
▲微软DirectX和Khronos Group API组合对比
DirectX是Direct eXtension的简称,作为一种API,是由微软公司创建的多媒体编程接口。DirectX可以让以Windows为平台的游戏或多媒体程序获得更高的执行效率,加强3D图形和声音效果,并提供设计人员一个共同的硬件驱动标准,让游戏开发者不必为每一品牌的硬件来写不同的驱动程序,也降低用户安装及设置硬件的复杂度。DirectX已被广泛使用于Windows操作系统和Xbox主机的电子游戏开发。
OpenGL是Open Graphics Library的简称,是用于渲染2D、3D矢量图形的跨语言、跨平台的应用程序编程接口(API),相比DirectX更加开放。这个接口由近350个不同的函数调用组成,用来绘制从简单的二维图形到复杂的三维景象。OpenGL常用于CAD、虚拟现实、科学可视化程序和电子游戏开发。
正是由于OpenGL的开放,所以它可以被运行在Windows、MacOS、Linux、安卓、iOS等多个操作系统上,学习门槛也比DirectX更低。但是,效率低是OpenGL的主要缺点。
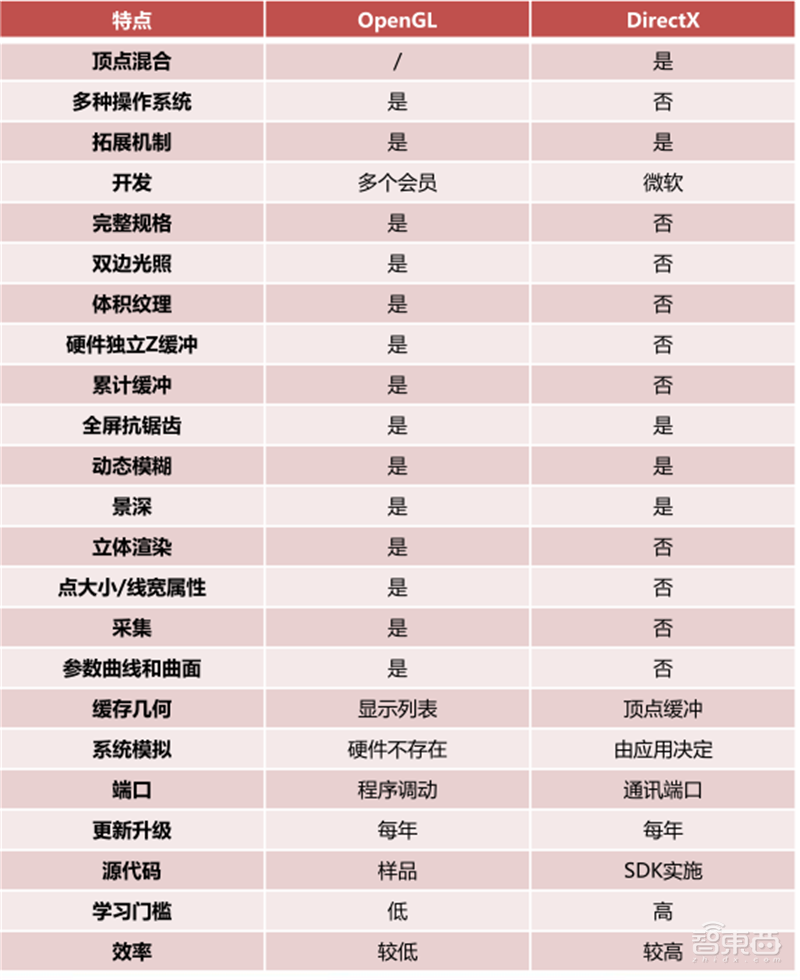
▲DirectX和OpenGL特点对比
Metal是Apple在2014年创建的接近底层的,低开销的硬件加速3D图形和计算着色器API。Metal在iOS 8中首次亮相。Metal在一个API中结合了类似于OpenGL和OpenCL的功能。它旨在通过为iOS,iPadOS,macOS和tvOS上的应用程序提供对GPU硬件的底层访问来提高性能。相较于OpenGL ES,Metal减少了10倍的代码拥挤,提供了更好的解决方案,并将会在苹果设备中取代OpenGL。Metal也支持英特尔HD和IRIS系列GPU、AMD的GCN和RDNA GPU、NVIDIA GPU。Metal也是可以使用Swift或Objective-C编程语言调用的面向对象的API。GPU的全部操作是通过Metal着色语言控制的。
2017年,苹果推出了Metal的升级版Metal2,兼容前代Metal硬件,支持iOS11,MacOS和tvOS11。Metal2可以在Xcode中更有效地进行配置和调试,加快机器学习速度,降低CPU工作量,在MacOS上支持VR,充分发挥A11 GPU的特性。
Vulkan是一种低开销,跨平台的3D图像和计算API。Vulkan面向跨所有平台的高性能实时3D图形应用程序,如视频游戏和交互式媒体。与OpenGL,Direct3D 11和Metal相比,Vulkan旨在提供更高的性能和更平衡的CPU/GPU用法。除了较低的CPU使用外,Vulkan还旨在使开发人员更好地在多核CPU中分配工作。
Vulkan源自并基于AMD的Mantle API组件,最初的版本被称为OpenGL的下一代。最新的Vulkan1.2发布于2020年1月15日,该版本整合了23个额外经常被使用的Vulkan拓展。
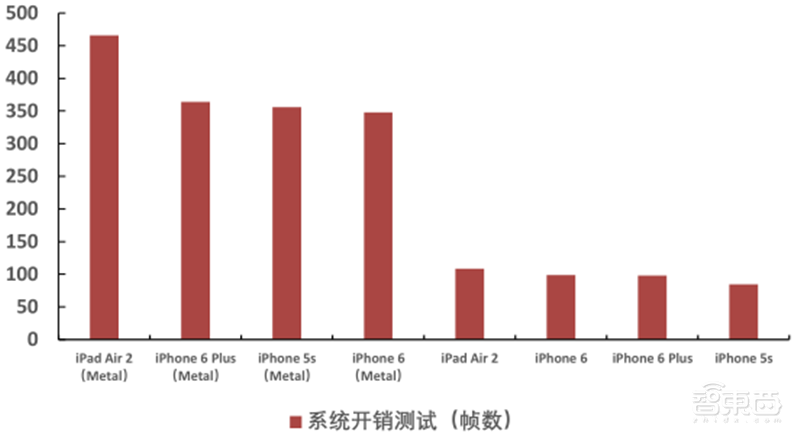
▲Metal与OpenGL性能对比
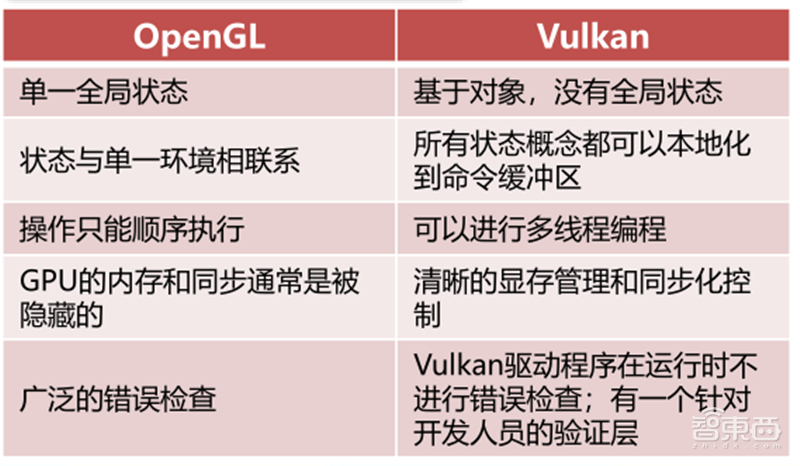
▲OpenGL和Vulkan对比
软件生态方面,GPU无法单独工作,必须由CPU进行控制调用才能工作,而CPU在处理大量类型一致的数据时,则可调用GPU进行并行计算。所以,GPU的生态和CPU的生态是高度相关的。
近年来,在摩尔定律演进的放缓和GPU在通用计算领域的高速发展的此消彼长之下,通用图形处理器(GPGPU)逐渐“反客为主”,利用GPU来计算原本由CPU处理的通用计算任务。
目前,各个GPU厂商的GPGPU的实现方法不尽相同,如NVIDIA使用的CUDA(compute unified device architecture)技术、原ATI的ATI Stream技术、Open CL联盟、微软的DirectCompute技术。这些技术可以让GPU在媒体编码加速、视频补帧与画面优化、人工智能与深度学习、科研领域、超级计算机等方面发挥异构加速的优势。以上4种技术中,只有OpenCL支持跨平台和开放标注的特性,还可以使用专门的可编程电路来加速计算,业界支持非常广泛。
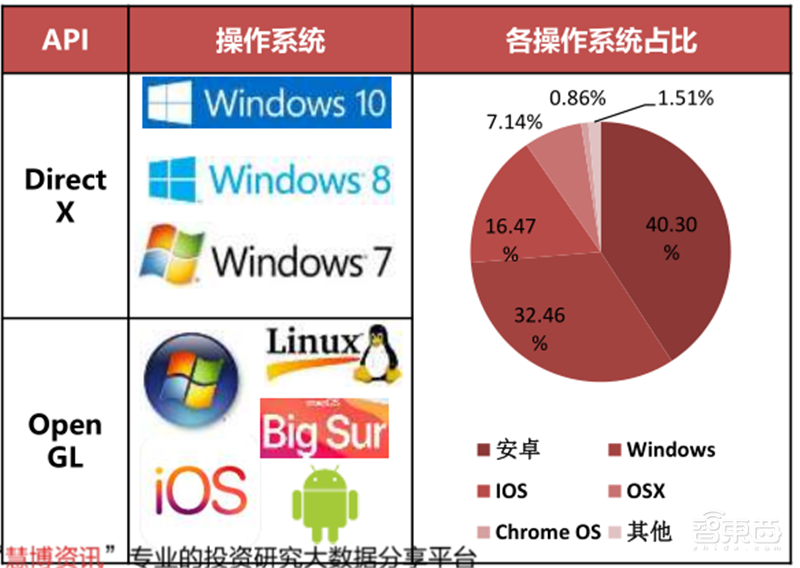
▲DirectX和OpenGL生态对比

▲OpenCL联盟生态
GPU根据接入方式可以划分为独立GPU和集成GPU。独立GPU一般封装在独立的显卡电路板上,拥有独立显存,而集成GPU常和CPU共用一个Die,共享系统内存。GPU根据接入方式可以划分为独立GPU和集成GPU。独立GPU一般封装在独立的显卡电路板上,拥有独立显存,而集成GPU常和CPU共用一个Die,共享系统内存。
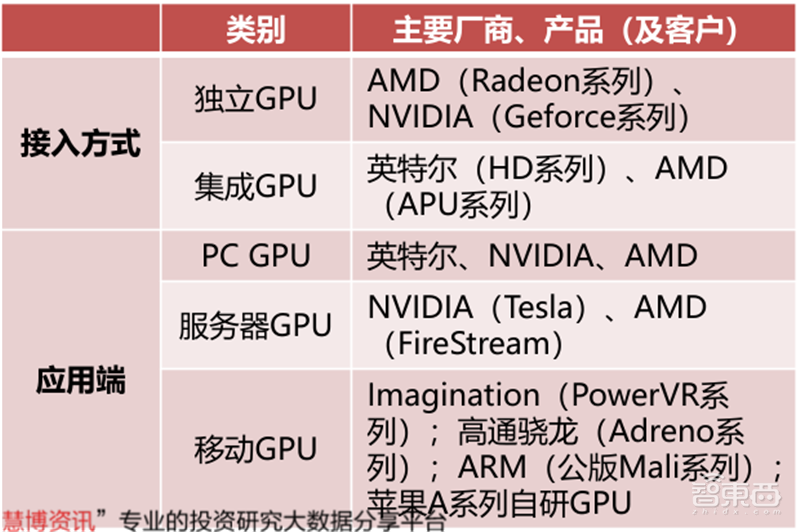
▲GPU的主要分类

▲独立GPU
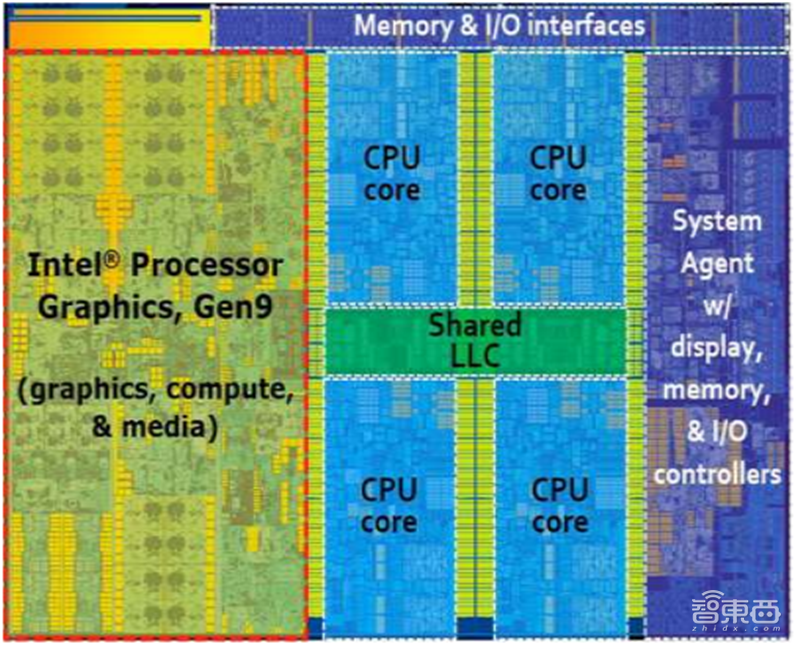
▲集成GPU Die
GPU显存是用来存储显卡芯片处理过或者即将提取的渲染数据,是GPU正常运作不可或缺的核心部件之一。GPU的显存可以分为独立显存和集成显存两种。目前,独立显存主要采用GDDR3、GDDR5、GDDR5X、GDDR6,而集成显存主要采用DDR3、DDR4。服务器GPU偏好使用Chiplet形式的HBM显存,最大化吞吐量。
集成显存受制于64位操作系统的限制,即便组成2通道甚至4通道,与独立显存的带宽仍有相当差距。通常这也造成了独立GPU的性能强于集成GPU。
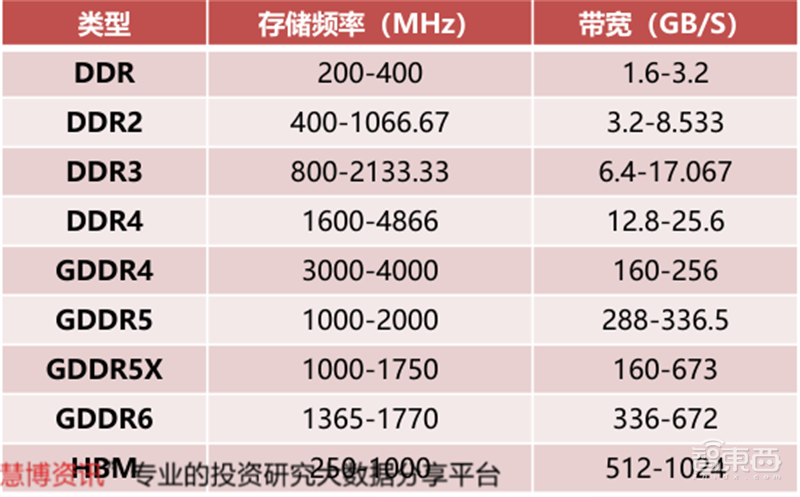
▲显存的主要分类
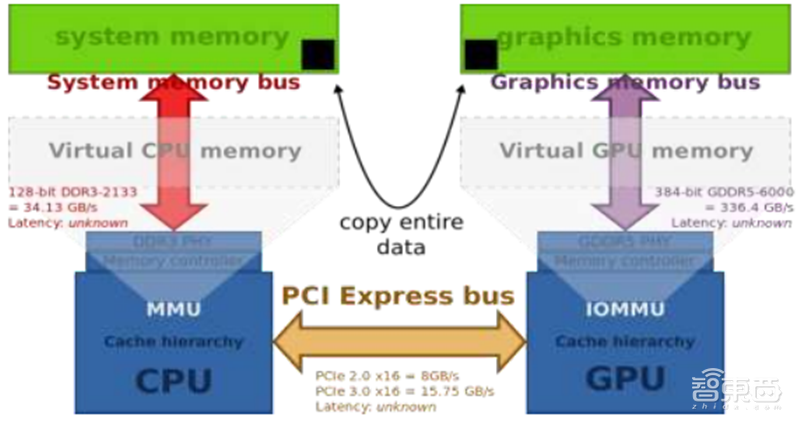
▲独立显存的工作方式
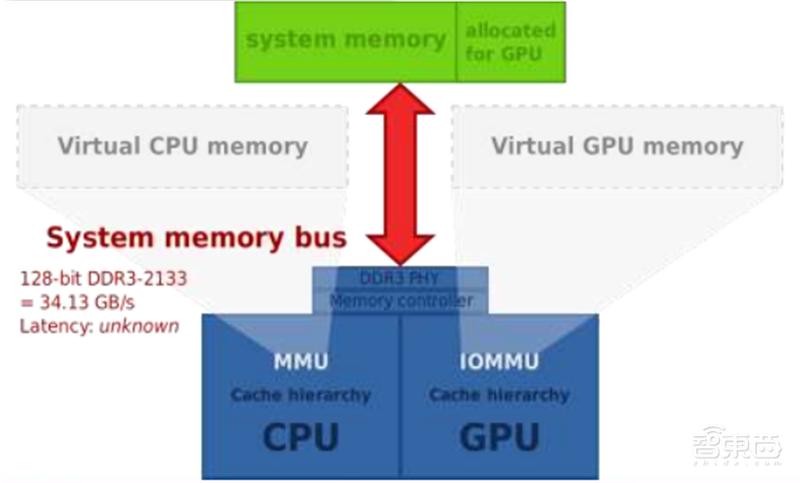
▲独立显存的工作方式
集成显卡是指一般不带显存,而是使用系统的一部分主内存作为显存的显卡。集成显卡可以被整合进主板作为北桥芯片的一部分,也可以和CPU集成在同一个Die中。集成显卡的显存一般根据系统软件和应用软件的需求自动调整。如果显卡运行需要占用大量内存空间,那么整个系统运行会受限,此外系统内存的频率通常比独立显卡的显存低很多,因此集成显卡的性能比独立显卡要逊色一些。
独立显卡是将显示芯片及相关器件制作成一个独立于电脑主板的板卡,成为专业的图像处理硬件设备。独立显卡因为具备高位宽、高频独立显存和更多的处理单元,性能远比集成显卡优越,不仅可用于一般性的工作,还具有完善的2D效果和很强的3D水平,因此常应用于高性能台式机和笔记本电脑,主要的接口为PCIe。
如今,独立显卡与集成显卡已经不是2个完全割裂,各自为营的图像处理单元了。二者在微软DX12的支持下也可以实现独核显交火,同时AMD和NVIDIA的显卡也可实现混合交火。
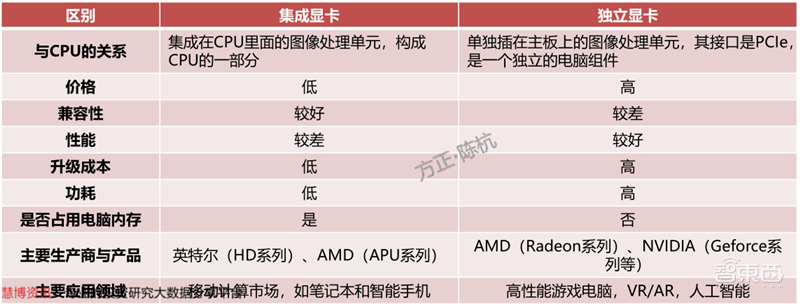
▲集成显卡和独立显卡对比
GPU对比CPU:从芯片设计思路看,CPU是以低延迟为导向的计算单元,通常由专为串行处理而优化的几个核心组成,而GPU是以吞吐量为导向的计算单元,由数以千计的更小、更高效的核心组成,专为并行多任务设计。
CPU和GPU设计思路的不同导致微架构的不同。CPU的缓存大于GPU,但在线程数,寄存器数和SIMD(单指令多数据流)方面GPU远强于CPU。
微架构的不同最终导致CPU中大部分的晶体管用于构建控制电路和缓存,只有少部分的晶体管完成实际的运算工作,功能模块很多,擅长分支预测等复杂操作。GPU的流处理器和显存控制器占据了绝大部分晶体管,而控制器相对简单,擅长对大量数据进行简单操作,拥有远胜于CPU的强大浮点计算能力。
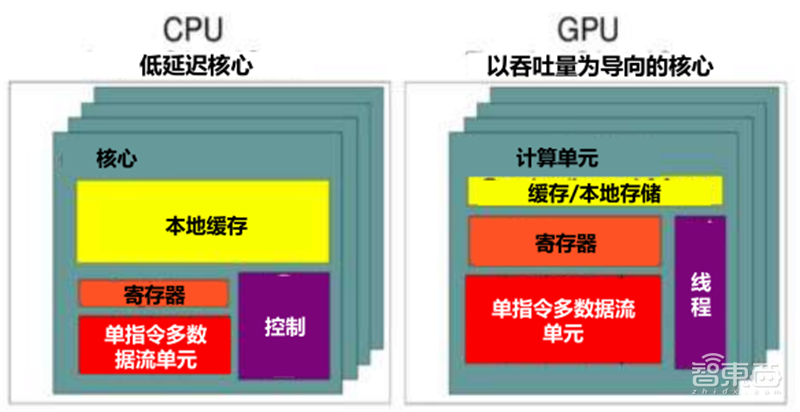
▲GPU和CPU的核心设计思路对比

▲GPU和CPU的核心对比
后摩尔时代,随着GPU的可编程性不断增强,GPU的应用能力已经远远超出了图形渲染,部份GPU被用于图形渲染以外领域的计算成为GPGPU。与此同时,CPU为了追求通用性,只有少部分晶体管被用于完成运算,而大部分晶体管被用于构建控制电路和高速缓存。但是由于GPU对CPU的依附性以及GPU相较CPU更高的开发难度,所以GPU不可能完全取代CPU。我们认为未来计算架构将是GPU+CPU的异构运算体系。
在GPU+CPU的异构运算中,GPU和CPU之间可以无缝地共享数据,而无需内存拷贝和缓存刷新,因为任务以极低的开销被调度到合适的处理器上。CPU凭借多个专为串行处理而优化的核心运行程序的串行部份,而GPU使用数以千计的小核心运行程序的并行部分,充分发挥协同效应和比较优势。
异构运算除了需要相关的CPU和GPU等硬件支持,还需要能将它们有效组织的软件编程。OpenCL是(OpenComputing Language)的简称,它是第一个为异构系统的通用并行编程而产生的统一的、免费的标准。OpenCL支持由多核的CPU、GPU、Cell架构以及信号处理器(DSP)等其他并行设备组成的异构系统。
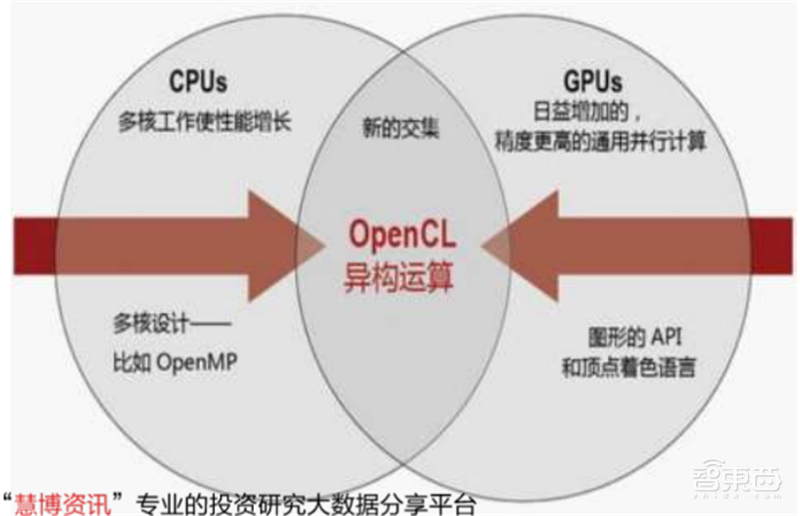
▲OpenCL异构运算构成
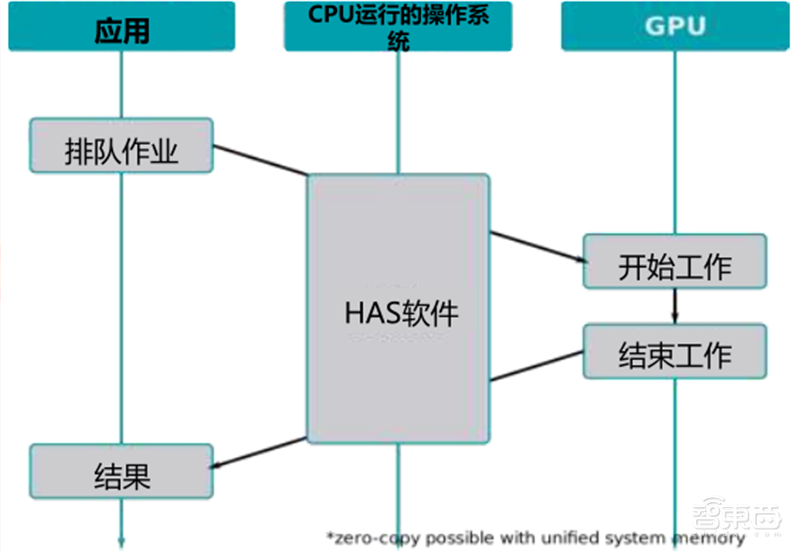
▲异构运算下的GPU工作流程
GPU与ASIC和FPGA的对比:数据、算力和算法是AI三大要素,CPU配合加速芯片的模式成为典型的AI部署方案,CPU提供算力,加速芯片提升算力并助推算法的产生。常见的AI加速芯片包括GPU、FPGA、ASIC三类。
GPU用于大量重复计算,由数以千计的更小、更高效的核心组成大规模并行计算架构,配备GPU的服务器可取代数百台通用CPU服务器来处理HPC和AI业务。
FPGA是一种半定制芯片,灵活性强集成度高,但运算量小,量产成本高,适用于算法更新频繁或市场规模小的专用领域。
ASIC专用性强,市场需求量大的专用领域,但开发周期较长且难度极高。
在AI训练阶段需要大量数据运算,GPU预计占64%左右市场份额,FPGA和ASIC分别为22%和14%。推理阶段无需大量数据运算,GPU将占据42%左右市场,FPGA和ASIC分别为34%和24%。
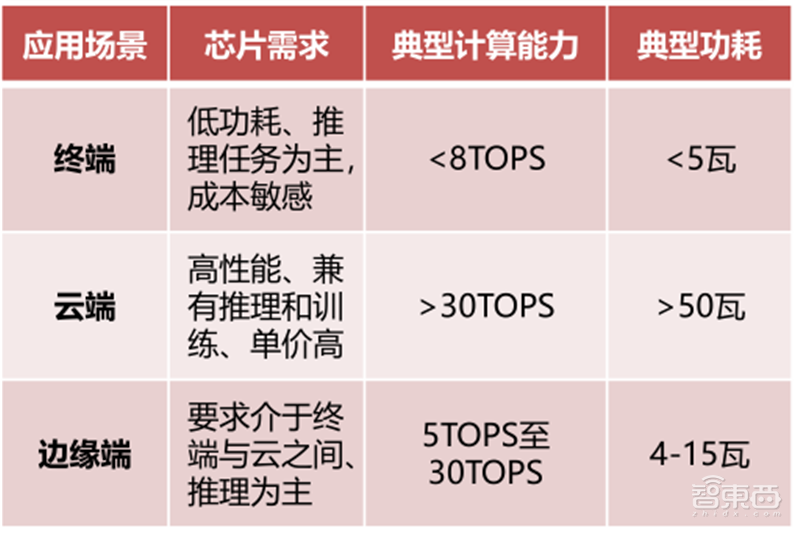
▲不同应用场景AI芯片性能需求和具体指标
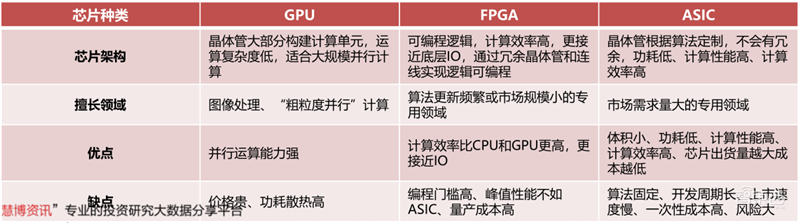
▲GPU、FPGA、ASIC AI芯片对比
在PC诞生之初,并不存在GPU的概念,所有的图形和多媒体运算都由CPU负责。但是由于X86 CPU的暂存器数量有限,适合串行计算而不适合并行计算,虽然以英特尔为代表的厂商多次推出SSE等多媒体拓展指令集试图弥补CPU的缺陷,但是仅仅在指令集方面的改进不能起到根本效果,所以诞生了图形加速器作为CPU的辅助运算单元。
GPU的发展史概括说来就是NVIDIA、AMD(ATI)的发展史,在此过程中曾经的GPU巨头Imagination、3dfx、东芝等纷纷被后辈超越。如今独立显卡领域主要由英伟达和AMD控制,而集成显卡领域由英特尔和AMD控制。
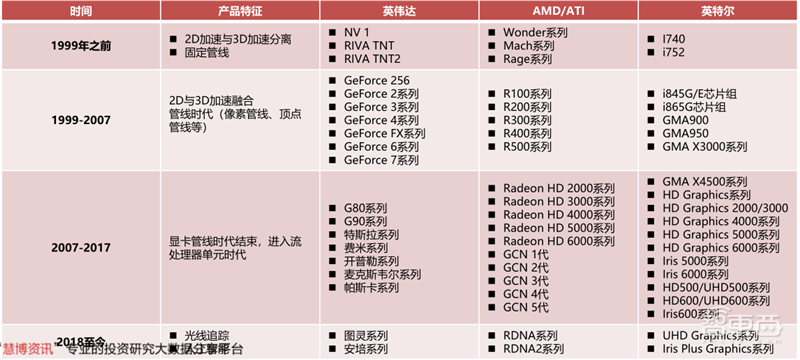
▲GPU的发展史
英伟达的GPU架构自2008年以来几乎一直保持着每2年一次大更新的节奏,带来更多更新的运算单元和更好的API适配性。在每次的大换代之间,不乏有一次的小升级,如采用开普勒二代微架构的GK110核心相较于采用初代开普勒微架构的GK104核心,升级了显卡智能动态超频技术,CUDA运算能力提升至3.5代,极致流式多处理器(SMX)的浮点运算单元提升8倍,加入了Hyper-Q技术提高GPU的利用率并削减了闲置,更新了网格管理单元(Grid Management Unit),为动态并行技术提供了灵活性。
英伟达GPU微架构的持续更新,使英伟达GPU的能效提升了数十倍,占领了独立显卡技术的制高点。
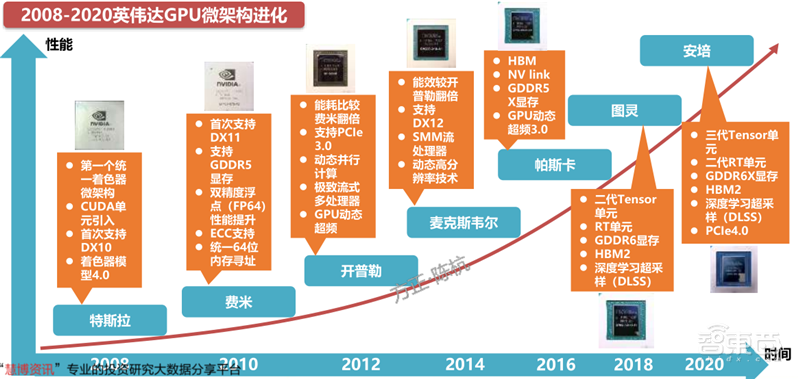
▲2008-2020英伟达GPU微架构进化
图形API在GPU的运算过程中发挥着连接高级语言、显卡驱动乃至底层汇编语言的作用,充当GPU运行和开发的“桥梁”和“翻译官”。微软DirectX标准可以划分为显示部份、声音部份、输入部分和网络部分,其中与GPU具有最直接关系的是显示部分。显示部份可分为DirectDraw和Direct3D等标准,前者主要负责2D图像加速,后者主要负责3D效果显示。
从1995年发布的初代DirectX 1.0开始微软的DirectX已经更新到了DirectX 12。在此过程中,DirectX不断完善对各类GPU的兼容,增加开发人员的权限,提高GPU的显示质量和运行帧数。
DirectX一般和Windows操作系统同步更新,如Windows 7推出了DX11、Windows 10推出了DX12。
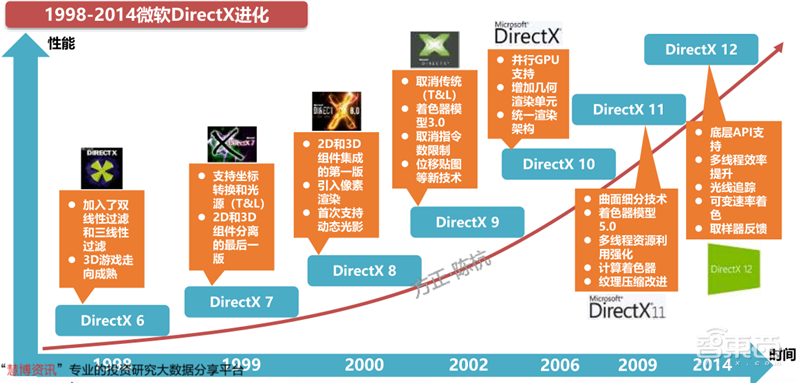
▲1998-2014微软DirectX进化
GPU和CPU都是以先进制程为导向的数字芯片。先进制程可以在控制发热和电能消耗的同时,在有限的Die中放入尽可能多的晶体管,提高GPU的性能和能效。
NVIDIA的GPU从2008年GT200系列的65纳米制程历经12年逐步升级到了RTX3000系列的7/8纳米制程,在整个过程中,晶体管数量提升了20多倍,逐步确立了在独立GPU的市场龙头地位。
同时在整个过程中,NVIDIA一直坚持不采用IDM的模式,而是让台积电负责GPU的制造,自生专注于芯片设计,充分发挥比较优势。
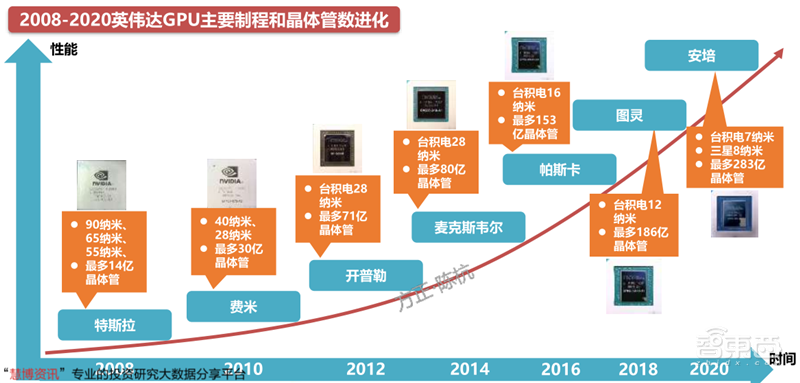
▲2008-2020英伟达GPU主要制程和晶体管数进化
根据前12年的GPU发展轨迹来看,GPU微架构的升级趋势可以简要地概括为”更多”、”更专”、”更智能”。“更多”是指晶体管数量和运算单元的增加,其中包括流处理器单元、纹理单元、光栅单元等数量上升。“更专”是指除了常规的计算单元,GPU还会增加新的运算单元。例如,英伟达的图灵架构相较于帕斯卡架构新增加了光追单元和张量单元,分别处理实时光线追踪和人工智能运算。“更智能”是指GPU的AI运算能力上升。如第三代的张量单元相较于上代在吞吐量上提升了1倍。
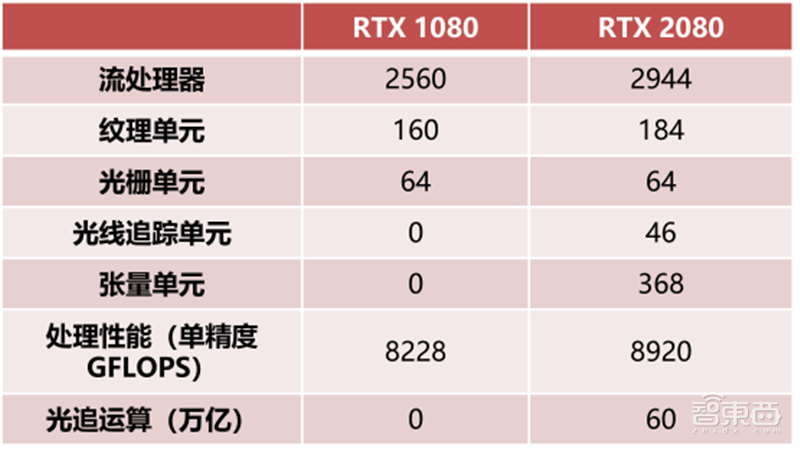
▲英伟达GTX1080对比RTX2080
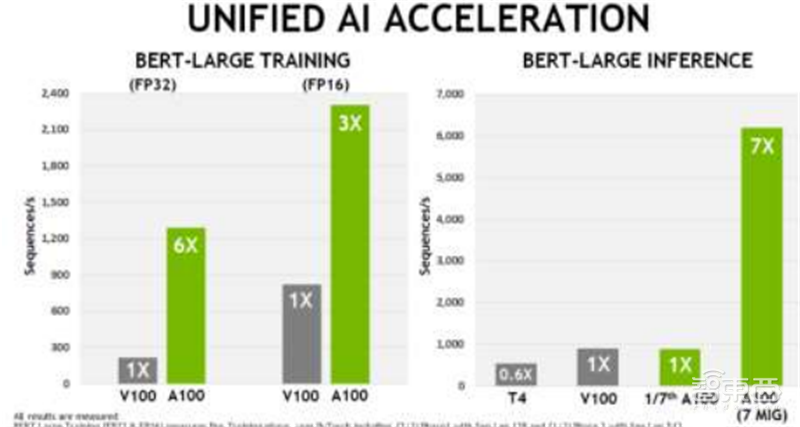
▲英伟达伏特微架构对比安培微架构AI加速性能

▲英伟达安培架构提升
综合分析微软的DirectX12、苹果的Metal2、Khronos Group的Vulkan API分别相较于前代DirectX11、Metal、OpenGL的升级,我们认为GPU API的升级趋势是提高GPU的运行效率、增加高级语言和显卡驱动之间的连接、优化视觉特效等。其中,提供更底层的支持:统筹高级语言、显卡驱动和底层语言是几乎所有API升级的主要方向。
不过提供更底层的支持只是更高的帧数或更好的画质的必要非充分条件。在整个软件的开发过程中,软件开发商需要比驱动程序和系统层更好地调度硬件资源,才能充分发挥底层API的效果。
在显示质量方面,DirectX 12 Ultimate采用当下最新的图形硬件技术,支持光线追踪、网格着色器和可变速率着色,PC和Xbox共用同一个API,堪称次世代游戏的全新黄金标准。
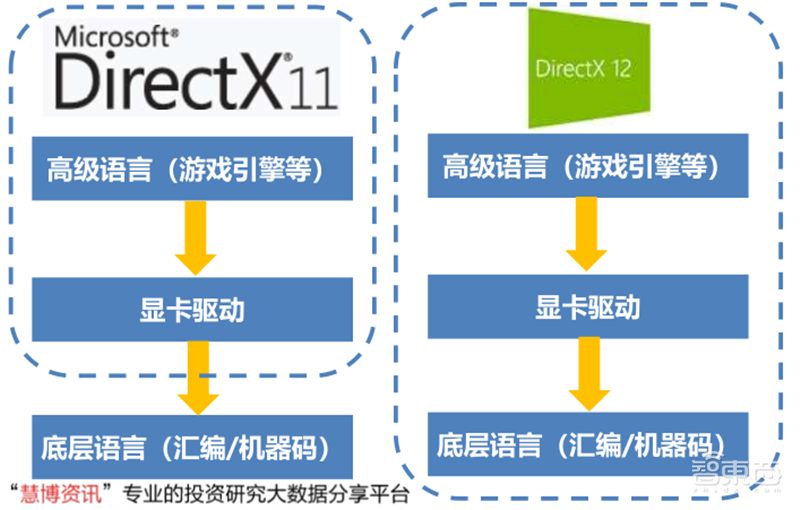
▲非底层DirectX 11对比底层DirectX 12
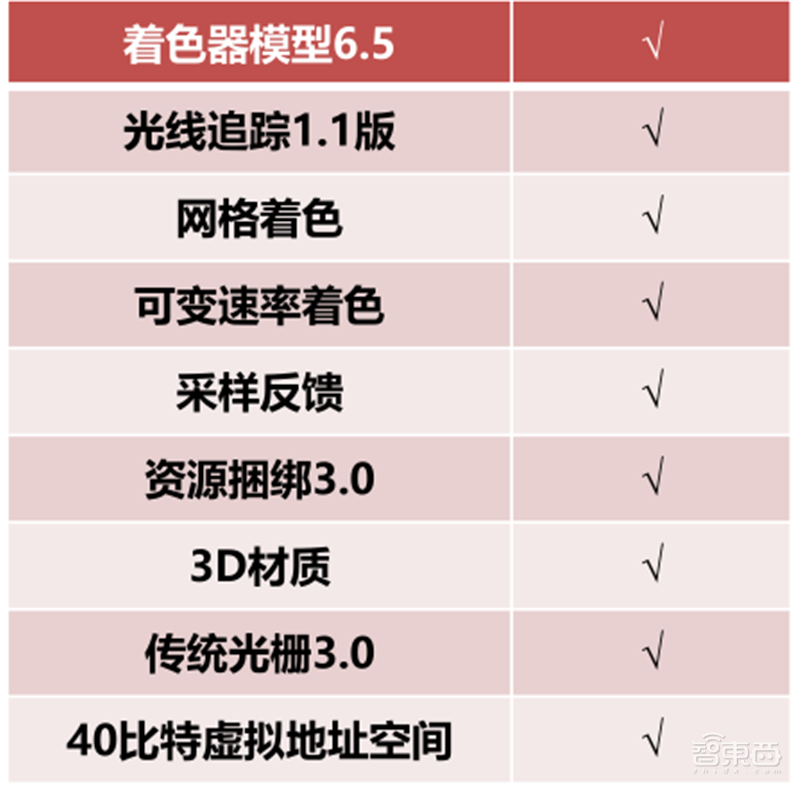
▲DirectX 12 Ultimate新特性
GPU制造升级趋势:以先进制程为导向。GPU性能的三大决定因素为主频、微架构、API。这些因素中主频通常是由GPU的制程决定的。制程在过去通常表示晶体管或栅极长度等特征尺寸,不过出于营销的需要,现在的制程已经偏离了本意,因此单纯比较纳米数没有意义。按英特尔的观点,每平方毫米内的晶体管数(百万)更能衡量制程。据此,台积电和三星的7nm工艺更接近英特尔的10nm工艺。
先进的制程可以降低每一个晶体管的成本,提升晶体管密度,在GPU Die体积不变下实现更高的性能;先进制程可以提升处理器的效能,在性能不变的情况下,减少发热或在发热不变的情况下,通过提升主频来拉高性能。
先进制程的主要目的是降低平面结构带来的漏电率问题,提升方案可以通过改变工艺,如采用FinFET(鳍式场效应晶体管)或GAA(环绕式栅极);或采用特殊材料,如FD-SOI(基于SOI的超薄绝缘层上硅体技术)。
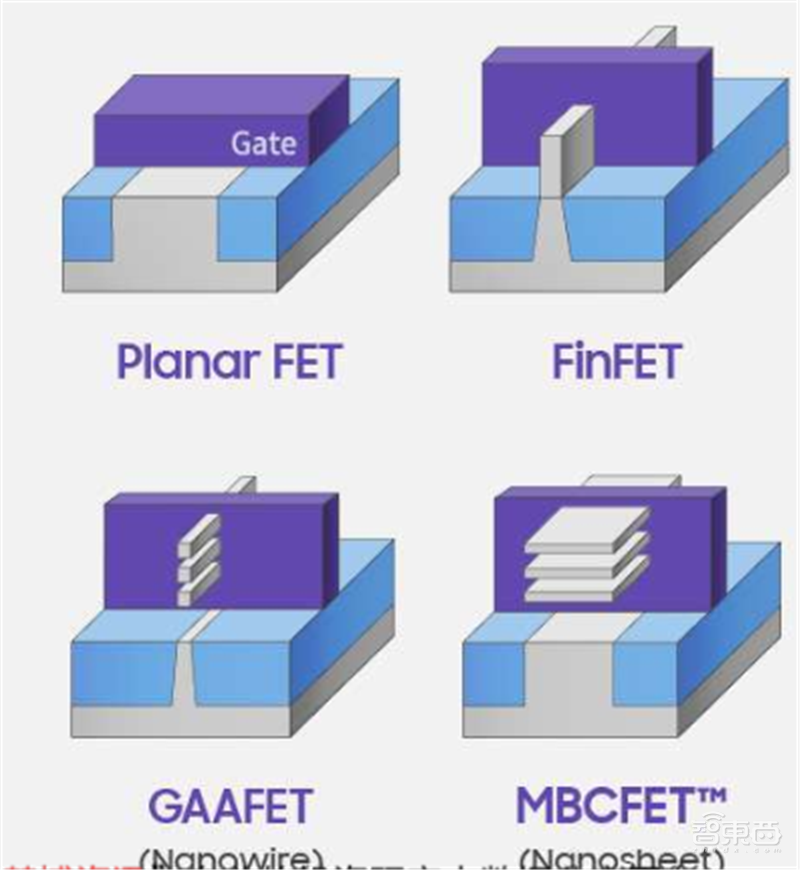
▲先进制程工艺之FinFET
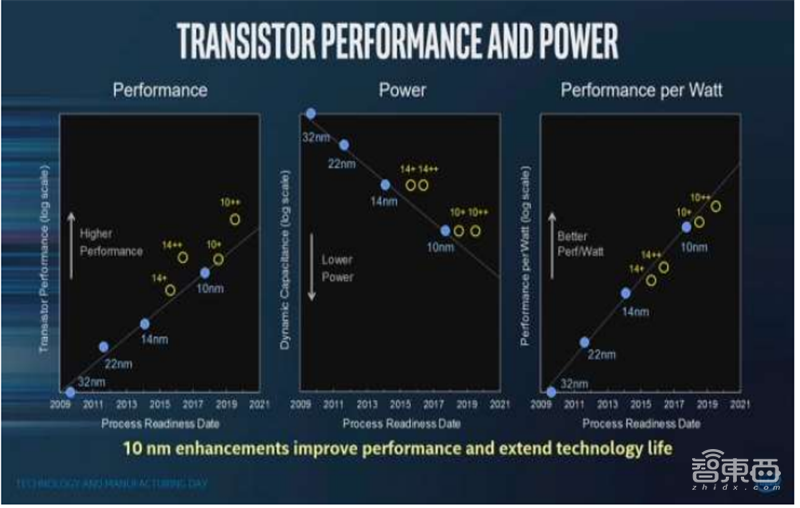
▲英特尔10nm先进制程带来的性能和效能提升
GPU制造升级趋势:Chiplet化。高位宽内存(HBM)是小芯片(Chiplet)在GPU中的常见应用。HBM是一种高速计算机存储器3D堆栈SDRAM接口。首款HBM于2013年推出,第二代HBM2已于2016年被JEDEC接受。目前,HBM主要应用在高端独立显卡和服务器显卡。
HBM通过3D堆叠4个DRAM Die和1片逻辑Die组成一个Chiplet,其中每片DRAM具有2个128位通道,通过TSV(硅通孔)相连。所以,一片Chiplet总共8个128位通道,总位宽1024比特。每片Chiplet又与GPU封装在同一中介层(Interposer)连接GPU芯片。相比之下,GDDR5内存的总线宽度为32位,带有512位内存接口的显卡也只有16个通道,而且采用传统的FBGA封装。HBM与GDDR5相比,每GB的表面积减少94%,每GB/S带宽的能效提升2倍多。
HBM支持最多每个Chiplet 4GB的存储,HBM2在HBM的基础上将每片Chiplet的最大容量提升至了8GB,显存主频提升1倍,同时总位宽保持不变。

▲HBM的GPU应用
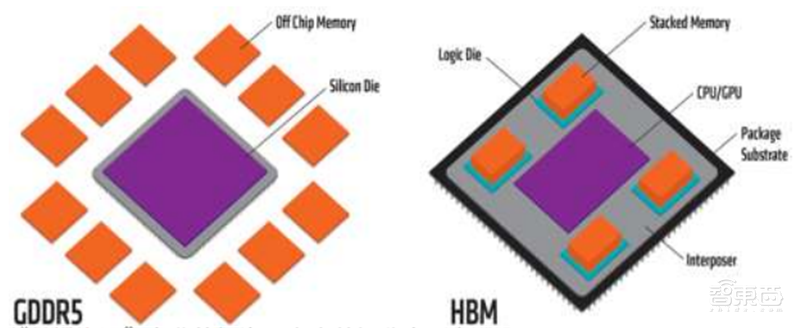
▲GDDR5对比HBM
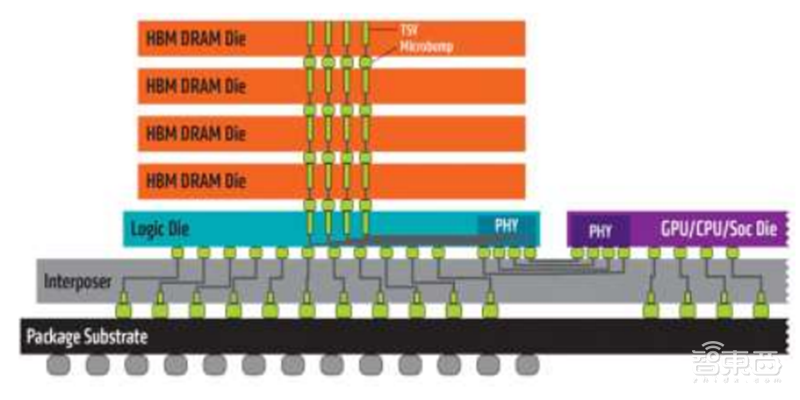
▲HBM先进封装结构
GPU制造可分为IDM和Fab+Fabless。IDM集芯片设计、芯片制造、芯片封装和测试等多个产业链环节于一身。英特尔为IDM的代表。
Fabless只负责芯片的电路设计与销售,将生产、测试、封装等环节外包。苹果和AMD为Fabless的代表。Foundry只负责制造,不负责芯片设计,可以同时为多家设计公司服务,但受制于公司间的竞争关系。台积电为Foundry的代表。目前英特尔GPU落后的主要原因是GPU制程的落后,根本原因是英特尔受困于IDM运作模式。随着28纳米以下先进制程的发展,芯片的制造成本和设计成本成指数级上升。同时,一条12英寸晶圆的生产线从建设到生产的周期约2年,投资至少30-50亿美元,资本支出占比80%,整体风险非常大。英特尔以有限的资源不支持它持续的设计和生产的的两线作战。
Fab+Fabless的模式通过充分发挥比较优势,分散了GPU设计和制造的风险,符合半导体分工的大趋势。
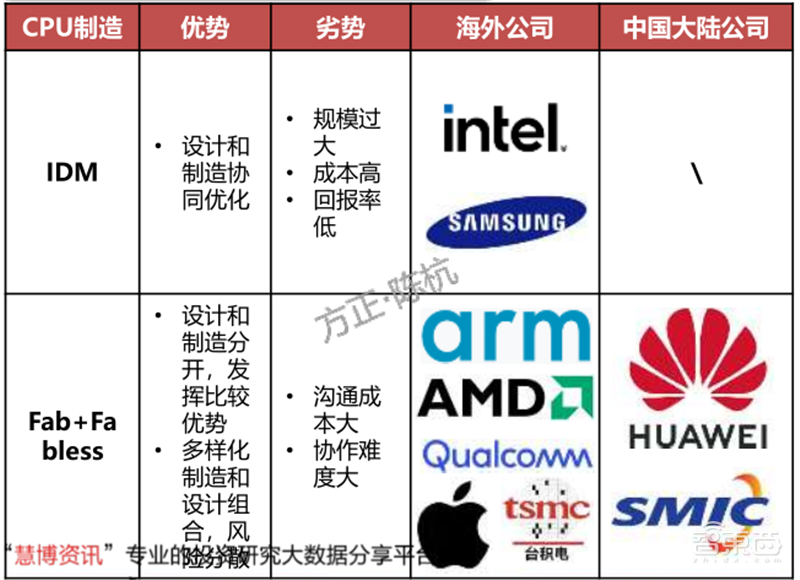
▲IDM与Fab+Fabless对比
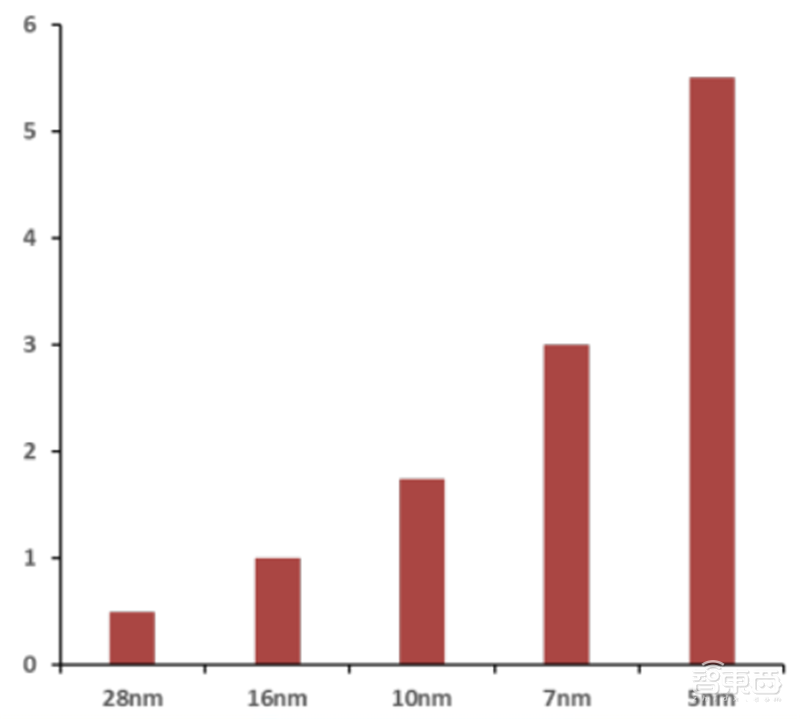
▲芯片设计费用趋势(亿美元)
过去20多年里,GPU的基本需求源于视频加速,2D/3D游戏。随后GPU运用自身在并行处理和通用计算的优势,逐步开拓服务器、汽车、矿机、人工智能、边缘计算等领域的衍生需求。虽然GPU无法离开CPU独立运作,但是在当前“云化”加速的时代,离开了GPU的CPU也无法胜任庞大的计算需求。所以GPU和CPU组成了异构运算体系,从底层经由系统软件和驱动层支持着上层的各种应用。GPU已经成为了专用计算时代的刚需。

▲现代云计算中GPU加速的刚需
二、GPU的全球格局
2020年全球GPU市场价值预计为254.1亿美元,预计2027年将达到1853.1亿美元,年平均增速为32.82%。按GPU的类型进行划分,市场可以细分为独立、集成和混合。2019年,集成GPU占GPU市场的主导地位,但是由于混合GPU同时拥有集成和专用GPU的能力,所以混合细分市场预计实现最高复合增长率。
按GPU的设备进行划分,市场可细分为计算机、平板电脑、智能手机、游戏机、电视、其他。就收入而言,智能手机细分市场占比最大,在未来也将保持这一趋势。但是,由于医疗等其他设备中对小型GPU的需求不断增加,预计未来的年复合增长率将最高。
按GPU的行业进行划分,市场可细分为电子、IT与电信、国防与情报、媒体与娱乐、汽车、其他。由于GPU在设计和工程应用中的广泛使用,预计汽车细分行业的年复合增长率最高。
按GPU的地理区域划分,市场可细分为北美、欧洲、亚太和其他地区。亚太地区在2019年主导了全球GPU市场,预计在整个预测期内将保持主导地位。
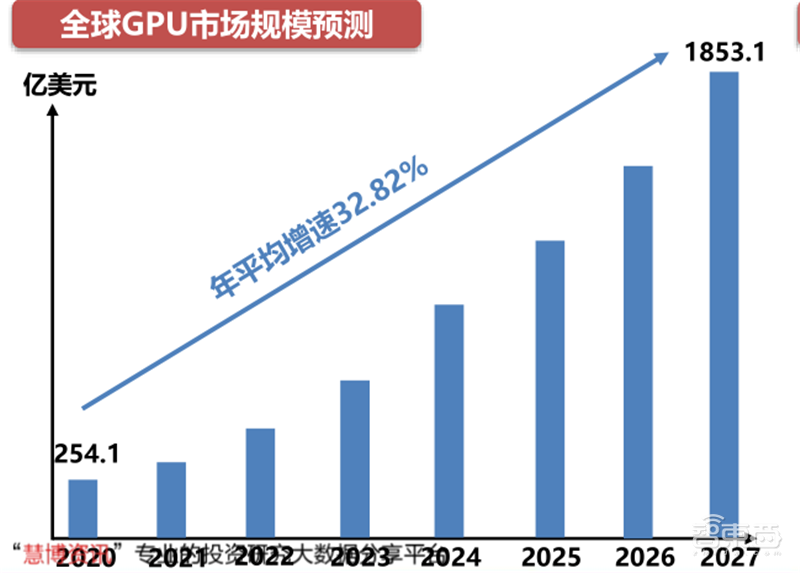
▲全球GPU市场规模预测
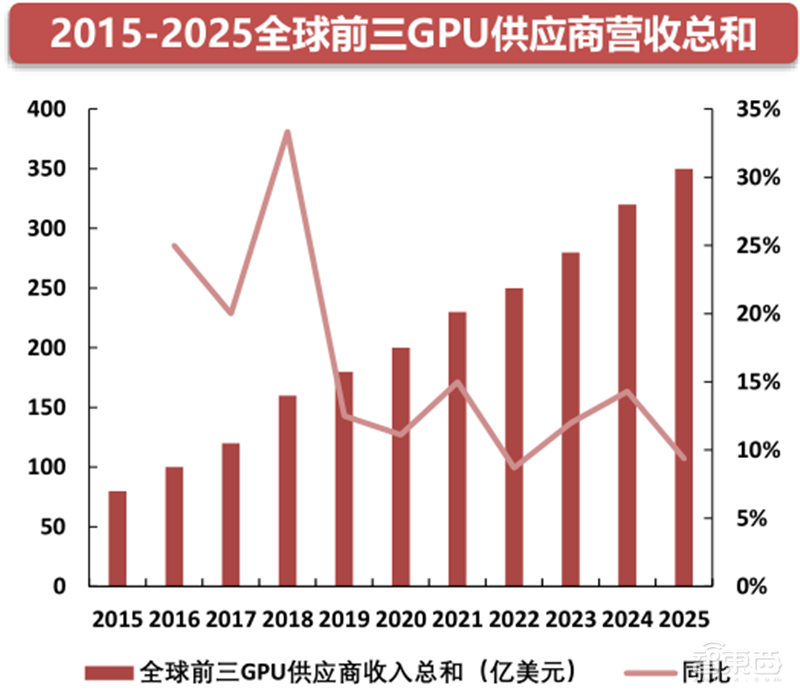
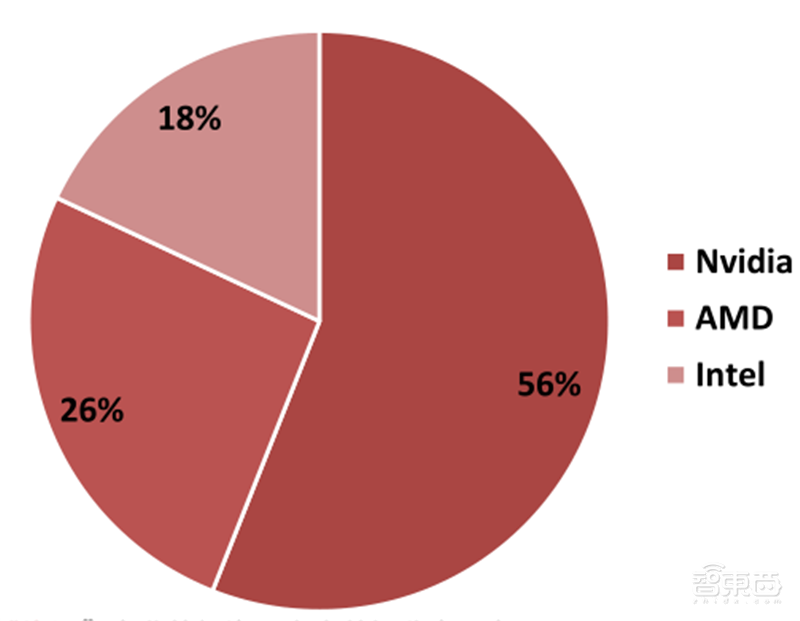
▲2015-2025全球前三GPU供应商营收总和
全球GPU已经进入了寡头垄断的格局。在传统GPU市场中,排名前三的Nvidia、AMD、Intel的营收几乎可以代表整个GPU行业收入。英伟达的收入占56%、AMD占26%、英特尔占18%。
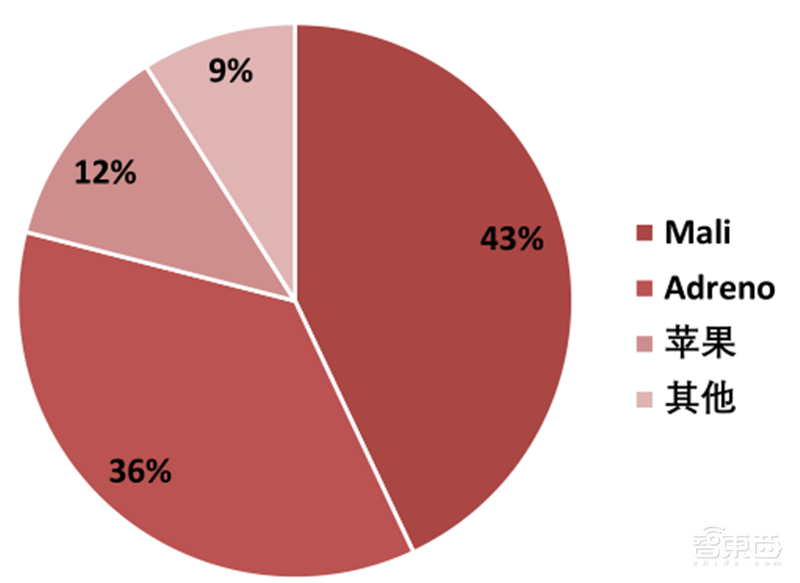
在手机和平板GPU方面,联发科、海思麒麟、三星Exynos的GPU设计主要基于公版ARM MaliGPU或PowerVR微架构。高通骁龙Adreno和苹果A系列采用自研GPU微架构。2019Q2,ARM、高通、苹果、Imagination科技、英特尔是全球智能手机和平板的前五大GPU供应商。同期ARM Mali在以上五大GPU供应商中占43%的市场份额,高通Adreno占36%的份额,苹果占12%的份额。
▲2019前三家GPU供应商收入份额对比
▲2019 Q2手机和平板GPU供应商份额
1、英伟达
英伟达公司成立于1993年,于1999年率先推出“GPU”的图形解决方案。公司主要设计游戏和专业市场的GPU,移动计算和自动驾驶汽车的SoC,是GPU计算领域公认的全球领导者。它主要的GPU产线“GeForce”和AMD的“Radeon”形成直接竞争。同时,英伟达为了拓展移动游戏平台,推出了掌机Shield、Shield平板、Shield电视盒子和云游戏服务GeForce Now。目前,公司已经完成了由芯片供应商向计算平台的转型。
英伟达的四大增长驱动力分别是游戏业务、数据中心业务、专业视觉业务、自动驾驶业务,各业务的代表性GPU方案分别是GeForce,DGX、EGX、HGX,Quadro、AGX。
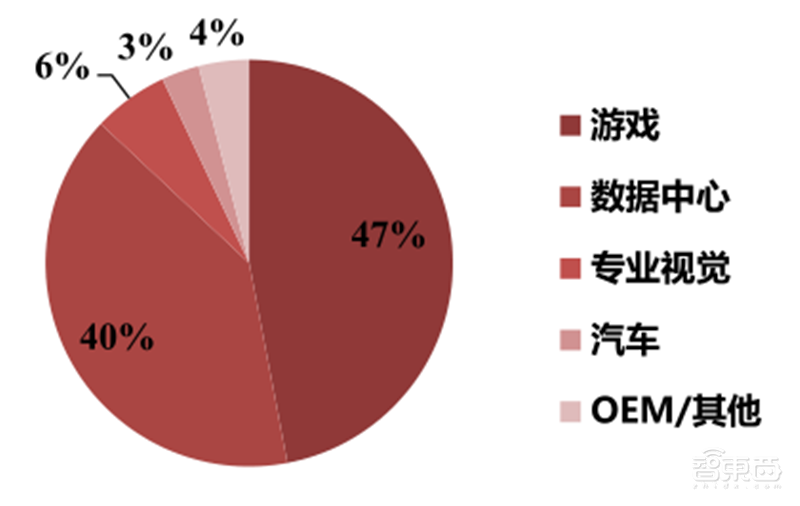
英伟达2021财年营收167亿美元,其中游戏、数据中心、专业视觉、自动驾驶业务在2020财年分别贡献了营收的47%、40%、6%、3%。公司继2014年毛利率突破50%后,于2021财年毛利率突破60%。
▲英伟达2021财年的业务构成
▲英伟达的主要增长驱动力
英伟达的游戏业务由GeForce和Shield组成。其中Shield面向移动端和云,GeForce面向PC。游戏笔记本和云游戏是公司拓展市场的2大方向。GeForce是英伟达游戏业务的核心。GeForce是全球最大的游戏平台,拥有超过2亿名玩家。在PC游戏领域,英伟达的营收是其他主要GPU供应商的三倍多。GeForce已经来到了RTX30系列,采用第二代NVIDIA RTX架构-NVIDIA安培架构,搭载全新的RT Core、Tensor Core及流式多处理器,拥有RTX游戏、DLSS、G-SYNC、DirectX12等先进技术,可带来逼真的光线追踪效果和先进的AI性能。
除了PC游戏市场,英伟达也向合作伙伴–任天堂Switch主机提供定制版Tegra SoC。作为合作的一部分,Shield主机可以畅享任天堂的游戏,GameStream串流游戏和热门游戏,实现4KHDR画质,支持百度DuerOS对话式人工智能。
英伟达的数据中心业务的技术根源是CUDA(统一计算设备架构)。CUDA首次推出于2006年的G80核心,隶属于通用并行计算架构,创造了GPGPU。在“安培”时代,CUDA核心已经进化到了8.0,被运用在几乎所有的英伟达产品线。
CUDA兼容DirectCompute、OpenCL等计算接口。与Direct3D、OpenGL等高级图形API相比,CUDA可以使开发者更容易使用GPU资源。当前,CUDA在广义上既代表GPU的硬件平台又代表GPU的软件平台。
在硬件平台方面,CUDA包含了CUDA指令集以及GPU内部的并行计算引擎。GPU平台的矢量运算如INT、FP32、FP64都由CUDA承担。开发人员可以使用C语言和Fortran语言为CUDA编写程序。
在软件平台方面,基于CUDA的CUDA-X加速库、工具和科技集合,向上对接不同的行业应用需求。在英伟达的软件栈体系中,分为CUDA-X AI和CUDA-X HPC,分别面向AI和HPC两大领域,可以在人工智能和高性能计算方面提供远超其他竞品的性能。CUDA-X的开发者已经超过100万。
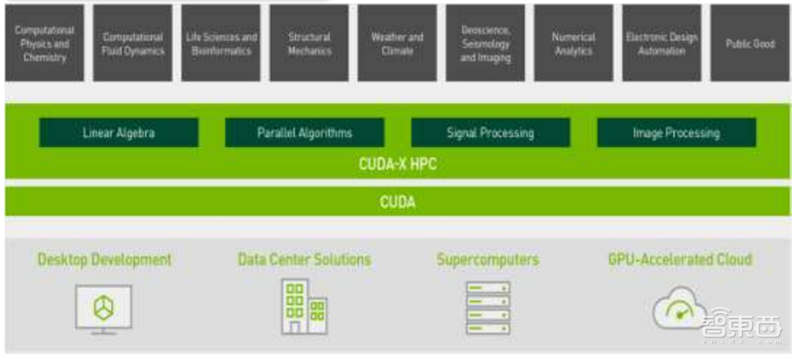
▲英伟达CUDA-X HPC
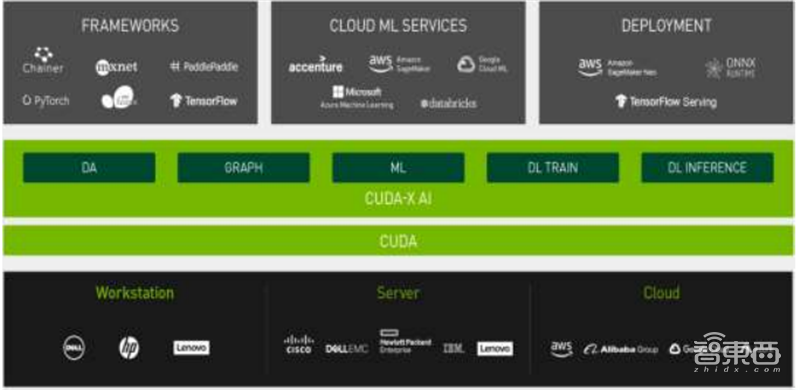
▲英伟达CUDA-X AI
英伟达数据中心的产品包括适用于AI的DGX系统,适用于边缘计算的EGX平台,适用于超算的HGX平台、适用于数据处理的DPU、简化深度学习,机器学习,高性能计算的NGC目录。相关的GPU加速器有采用安培架构的A100、A40,采用图灵架构的T4、RTX6000、RTX8000,采用伏特架构的V100。
过去5个财年中,英伟达数据中心的营收从8.3亿美元上升至66.96亿美元,年复合增速69%。同时,公司的注册开发者超过200万,与主要的云供应商如谷歌、腾讯、阿里建立了供应关系,世界500强超算中的份额从6%上升至70%。
▲英伟达主要云合作伙伴
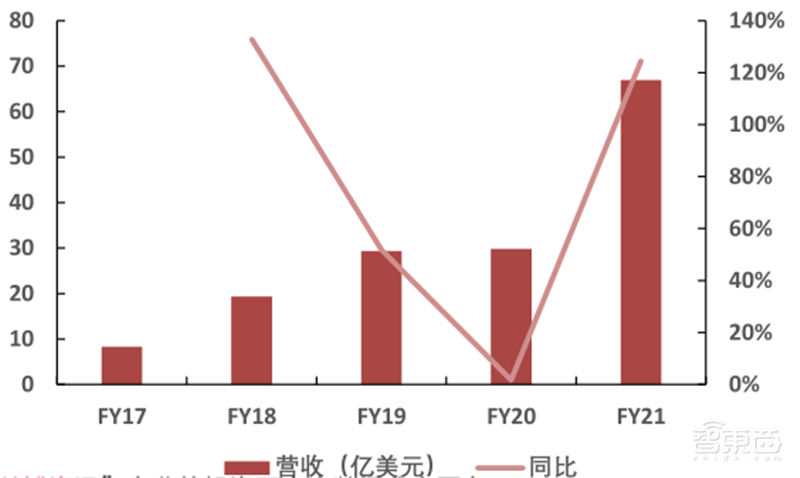
▲英伟达数据中心营收趋势
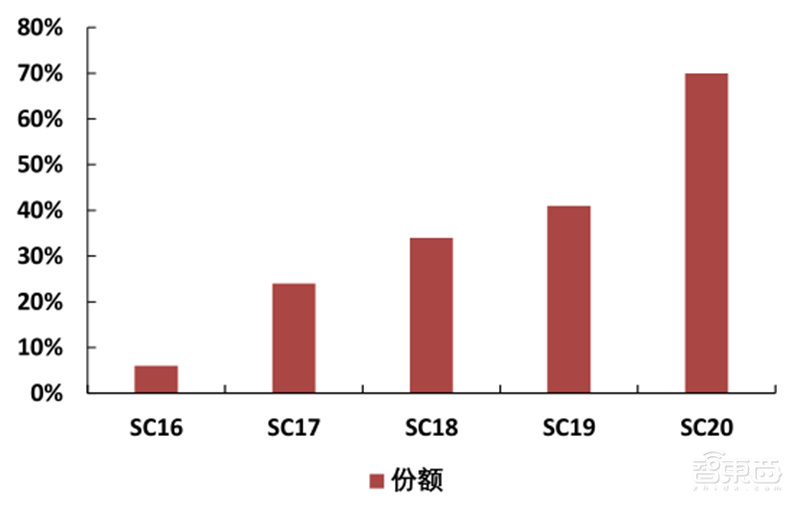
▲英伟达在超算500强中份额
英伟达专业视觉业务主要由Quadro产品线组成。Quadro在GeForce的基础上加强了NVLink、GPU的通用计算性能和显存容量,拥有Iray、Omniverse平台、材质定义语言等特有技术。Quadro被广泛应用在台式工作站、笔记本电脑、EGX服务器、虚拟工作空间、云端、定制化方案中。英伟达Quadro方案有超过50种应用、4000万设计用户和2000万企业用户,并正在不断解锁新市场。
在过去的5个财年,英伟达专业视觉的营收从8.35亿美元上升至10.53亿美元,年复合增速6%。

▲英伟达专业视觉GPU加速合作伙伴
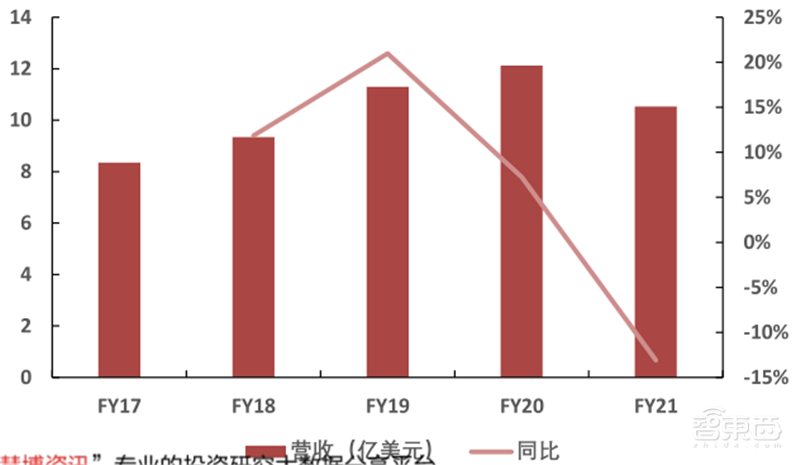
▲英伟达专业视觉营收趋势

▲英伟达专业视觉方案
英伟达的汽车产品包括相关驾驶软件、驾驶基础设计、AGX平台,提供训练、模拟、智能驾驶舱体验、高清地图和定位等解决方案。在绝对性能方面,搭载4颗Drive AGX Origin的蔚来ADAM超算平台支持L4以上自动驾驶,超过7个特斯拉FSD算力总和。
不同于特斯拉自动驾驶追求软硬件的高度契合,英伟达的方案更追求开放性。公司在汽车领域的合作伙伴以软件服务和轿车居多,分别达到了76家和42家。同时,公司与大众、丰田、本田、奔驰、宝马、奥迪、沃尔沃、马牌、滴滴、采埃孚、蔚来、小鹏、图森等世界知名公司建立了强力的生态。
在过去的5个财年,英伟达自动驾驶的营收从4.87亿美元上升至5.36亿美元,年复合增速3%。
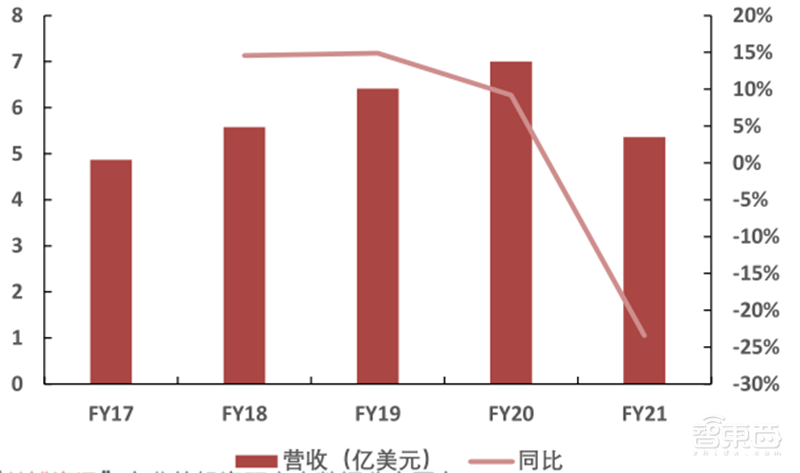
▲英伟达自动驾驶营收趋势
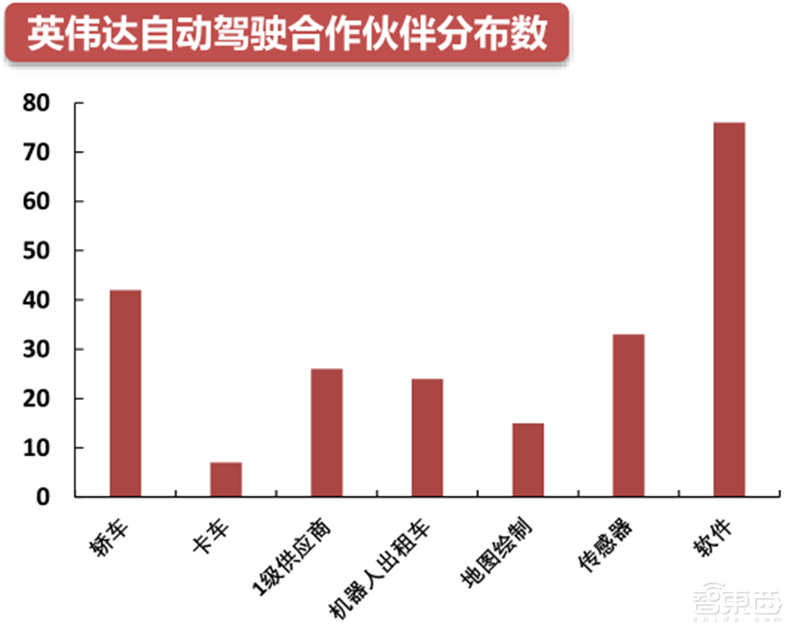
▲英伟达自动驾驶合作伙伴分布数
2020年9月13日,NVIDIA宣布以400亿美元收购ARM。本次收购意义可以细分为以下5个方面:
1. 创造AI时代的世界级计算公司,将英伟达领先的AI计算平台和ARM庞大的CPU生态相结合;
2. 通过英伟达在移动端和PC等大型终端市场的科技拓展ARM的IP授权组合;
3. 加速ARM的服务器CPU、数据中心、边缘AI、IoT发展;
4. 将英伟达计算平台的开发者由200万提升至超过1500万;
5. 并购可以立即增加英伟达的非GAAP毛利率和非GAAP每股收益;
合并后的英伟达将把计算从云、智能手机、PC、自动驾驶车和机器人技术推进到了边缘物联网,将AI计算拓展到全球,在拓展大规模、高增长市场的同时加速创新。
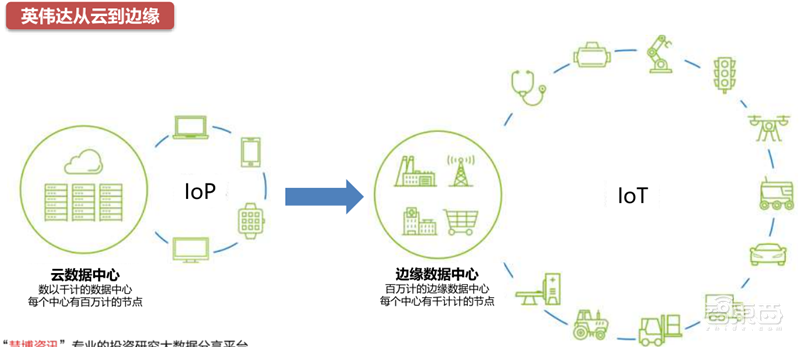
▲英伟达从云到边缘
2、全球GPU先驱:AMD
AMD是全球唯一可以同时提供高性能GPU和CPU的企业。AMD的显卡来源于2006年并购的ATI科技。在这之后的4年中,AMD继续使用ATI作为显卡品牌。直到2010年,AMD才抛弃原ATI的品牌命名方式。
目前,AMD同时提供独立GPU和集成GPU,其集成GPU主要运用在Ryzen APU、嵌入式、半定制平台中,独立GPU分为Radeon和Instinct系列,主要用于游戏、专业视觉、服务器等应用。
过去六年,AMD的计算和图形收入的营收由18.05亿美元上升至64.32亿美元,年复合增速29%。
未来五年,AMD计划成为高性能计算的领导者,提供颠覆性的CPU和GPU方案。
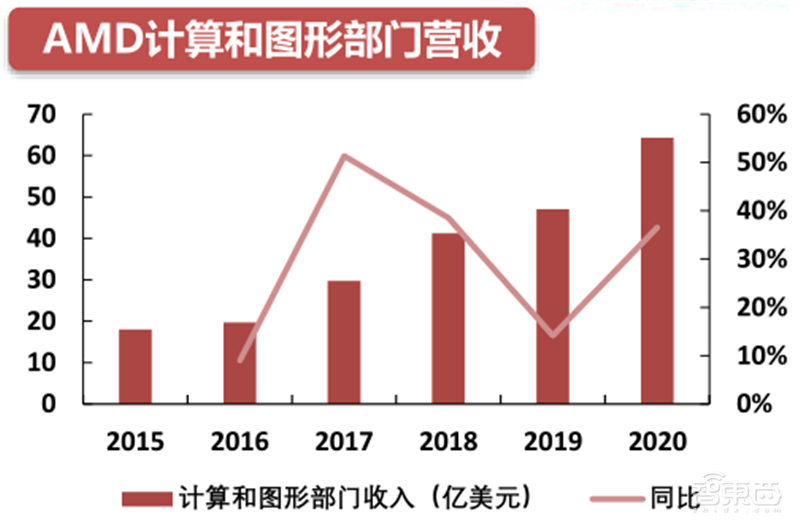
▲AMD计算和图形部门营收

▲AMD GPU的聚焦领域
AMD的集成GPU主要被运用在台式机和笔记本的APU产品中,和CPU组成异构运算单元。台式和笔记本APU的GPU部份共用微架构和核心技术,二者GPU的主要差异在于TDP和处理单元的数量,台式强于笔记本。
“Renior”APU的GPU继续使用Vega微架构,但受益于7纳米制程,每个处理单元效能显著提升。
7纳米Vega的提升包括:数据网络翻倍、优化低功耗状态转换、25%主频提升、77%存储位宽提升。这些提升带来了在保持15W功耗不变的前提下,每个计算单元59%的性能提升、1.79TFLOPS的32位浮点峰值吞吐。
在3DMark Time Spy(DX12)的跑分中,7纳米的Ryzen 4800U的GPU表现超过10纳米i7-1065G7,是14纳米i7-10710U的2倍以上。

▲AMD “RENIOR”APU
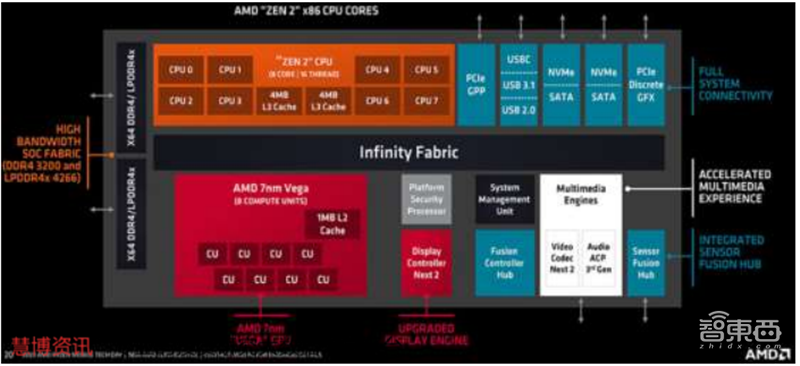
▲AMD “RENIOR”APU内核解析
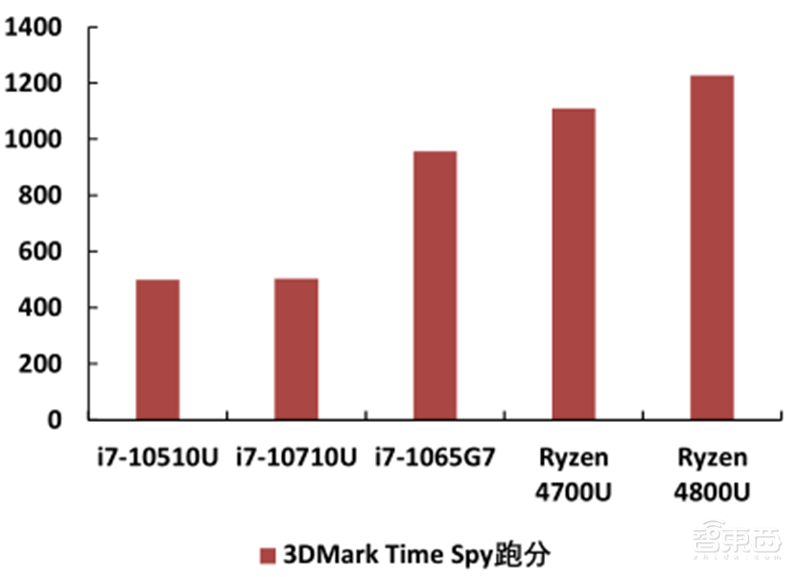
▲AMD “RENIOR”APU跑分对比
AMD的Radeon系列游戏独立GPU按微架构推出时间依次递减可以分为RX6000系列、RX5000系列、Radeon 7、 RX500系列。以上四大系列中,除RX500系列外均采用台积电7纳米制程。
2020年11月推出的RDNA2微架构相较于前代RDNA绝对性能最高提升一倍,能效提高54%,支持DirectX12 Ultimate,硬件光线追踪和可变速率着色器等先进技术。搭载16GBGDDR6显存和128MB InfinityCache高速缓存的RX 6900XT的游戏性能接近英伟达的RTX 3090。
为了发挥AMD CPU和GPU的协同效应,Radeon拥有AMD SmartAccess Memory技术,锐龙CPU和显卡之间能实现更出色的通信。RX6800系列显卡在部分游戏中4K画质性能额外提升最高可达7%。
2022年前,AMD将基于更先进的制程打造RDNA3微架构,进一步强化光追等计算表现。
除了传统的BGA显存封装,AMD还积极运用HBM系列显存。在Radeon7中,16GB的HBM2显存拥有1TB/S的带宽,超过同期Titan RTX 50%。

▲AMD独立游戏GPU路线图

▲AMD独立游戏GPU产品线
AMD的数据中心GPU业务由Radeon Instinct加速器系列、以客户为核心的数据中心解决方案和ROCm组成。AMD的主要合作伙伴包括戴尔、惠普等OEM,同时AMD也向微软AZURE和亚马逊网络服务提供视觉云解决方案。
ROCm是全球首个针对加速式计算且不限定编程语言的超大规模开源平台,遵循UNIX的选择哲学、极简主义以及针对GPU计算的模块化软件开发。
ROCm适合大规模计算,支持多路GPU,有丰富的系统运行库,包括框架、库、编程模型、互联和Linux Kernel上游支持,提供各种重要功能来支持大规模应用、编译器和语言运行库的开发。
AMD正与美国能源部、橡树岭国家实验室和Cray公司合作,使用EPYC(霄龙)CPU、Radeon Instinct GPU和ROCm打造超过150亿亿次FLOPS的全球最快超算平台。

▲AMD ROCm开源软件生态

▲AMD数据中心GPU产品线
Radeon Instinct MI 100加速器采用专注计算的CDNA微架构,在计算和连接方面实现了巨大飞跃,与AMD上一代加速器相比,高性能计算工作负载(FP32矩阵)性能提升近3.5倍,而人工智能工作负载(FP16)性能提升近7倍。InstinctMI 100在FP32和FP64的峰值TFLOPS中超越了同期英伟达安培A100,同时功耗比后者低100瓦。
为了满足多路GPU的互联通讯需求,AMD研发了InfinityFabric技术。Infinity Fabric拥有先进的平台连接性和可拓展性,最多支持4路GPU互联。P2P带宽是PCIe 4.0的2倍,四GPU集群的P2P带宽最高可达552GB/s。
未来,AMD将基于更先进的制程打造CDNA2微架构,进入百亿亿级时代。
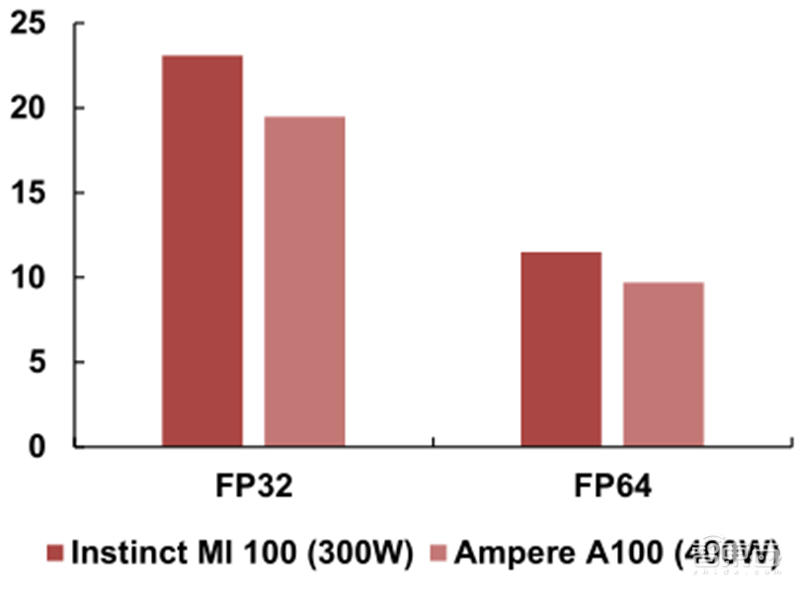
▲Instinct MI 100与安培A100对比

▲AMD数据中心GPU路线图

▲AMD Infinity Fabric互联
AMD的其他独立GPU主要包括嵌入式、半定制化、Radeon Pro工作站显卡。半定制化独立显卡主要倍运用在索尼、微软的本世代和次世代主机中。如今,AMD的技术存在于2.2亿个家庭畅享游戏和视频娱乐时所用设备的核心。
嵌入式GPU的特点包括卓越的图形性能、多屏显示、外形紧凑、高能效、长期供货。嵌入式GPU分为超高性能嵌入式GPU、高性能嵌入式GPU、高能效嵌入式GPU,它们主要使用14纳米的GCN 1.4北极星微架构,TDP覆盖20W-135W范围。
Radeon Pro系列显卡被广泛应用于建筑工程、设计制造、媒体娱乐等领域,拥有AMD远程工作站、AMD Eyefinity多屏显示技术、AMD Radeon ProRender等技术。Radeon Pro系列采用Vega微架构,7或14纳米制程,直接竞争对手是英伟达的Quadro系列。Radeon Pro移动和台式工作站的合作伙伴包括苹果、戴尔、惠普等。
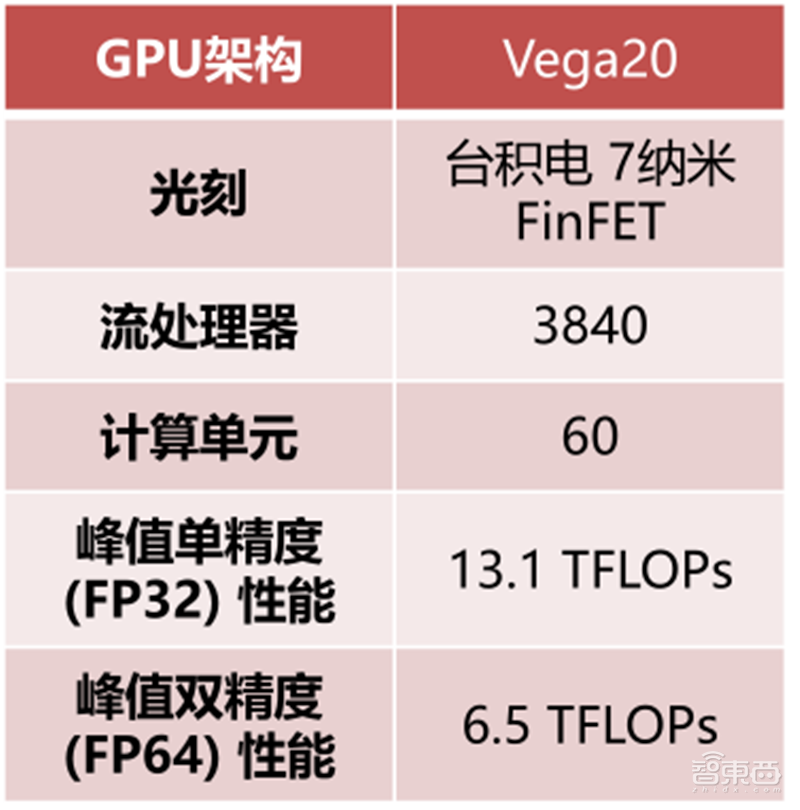
▲Radeon™ Pro VII GPU规格
3、英特尔:全球GPU追赶者
英特尔是全球最大的PC GPU供应商,也是PC和服务器显卡唯一的IDM厂商。英特尔的GPU最早可以追溯到1998年的i740,但是由于羸弱的性能和缓慢的更新速度,一直没有非常大的起色。进入Core i时代后,英特尔通过将核芯显卡和CPU进行捆绑销售,利用CPU的庞大市场份额,确立了公司在集成GPU领域的寡头垄断地位,在此过程中AMD的APU一直是酷睿的直接竞争对手。
2020年,英特尔推出了第12代GPGPU,采用全新的Xe微架构和10纳米Super Fin制程。相较于第11代核显,Xe-LP在保持电压不变的前提下,大幅提升主频,能效显著提高。搭载Xe-LP的i7 1185G7在GPU性能方面已经超过同期AMD的Vega核显和英伟达的MX系列独显。
Xe系列可以细分为,集成/低功耗的Xe-LP、娱乐/游戏的Xe-HPG、数据中心/高性能的Xe-HP、高性能计算的Xe-HPC。
目前,Xe-LP的集成版本已经被第11代酷睿所采用。Xe-LP的移动独立GPU版本DG1和服务器独立GPU版本SG1也已发布。独显版在核显版的基础上进一步提升主频,并加入了128位4GB LPDDR4X-4266独立显存,单精度浮点算力提升15%。
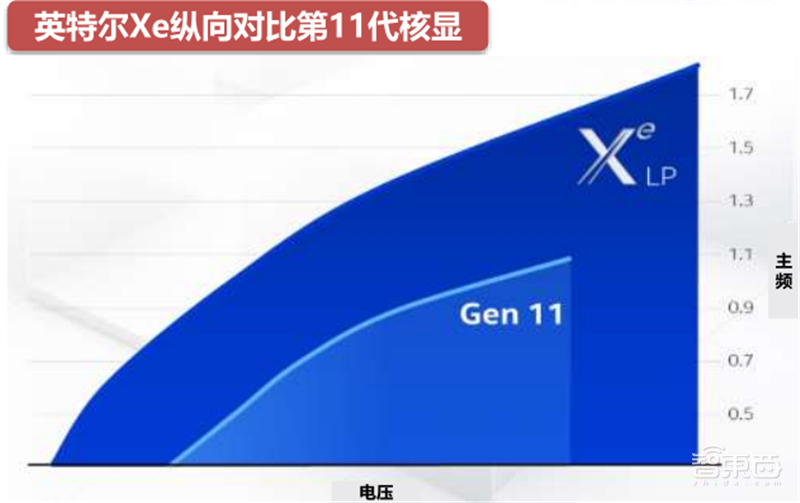
▲英特尔Xe纵向对比第11代核显

▲英特尔Xe产品线
英特尔的集成GPU在形式上表现为核芯显卡。核芯显卡使用系统DRAM作为非独立显存,通过处理器内部的环状总线与CPU连接,负责处理游戏、视频娱乐等图像负载。
英特尔Xe核显借助10纳米SuperFin的优势,将处理单元最高提升至96个,相较于Icelake的64个提升了50%,并且将连接CPU和GPU的总线带宽提升一倍,独立最终缓存(LLC)提高50%,支持最高86GB/s的存储带宽。以上这些提升使i7-1185G7的3DMark跑分较前代i7-1065G7提升接近一倍,超过AMD的R74800U和同期英伟达的MX350。
Xe核显的显示引擎和媒体引擎也都得到加强。接口方面,内部支持双eDP,外部支持DP1.4、HDMI2.0、雷电4、USB4 Type-C。画质方面,支持8K、HDR10、12比特BT2020色域、360赫兹刷新率等。
英特尔Xe核心显卡和CPU经由自家One API驱动中间层框架和上层应用。英特尔One API解决了编码模型在不同微架构间的壁垒,最大化跨平台表现和最小化开发成本。
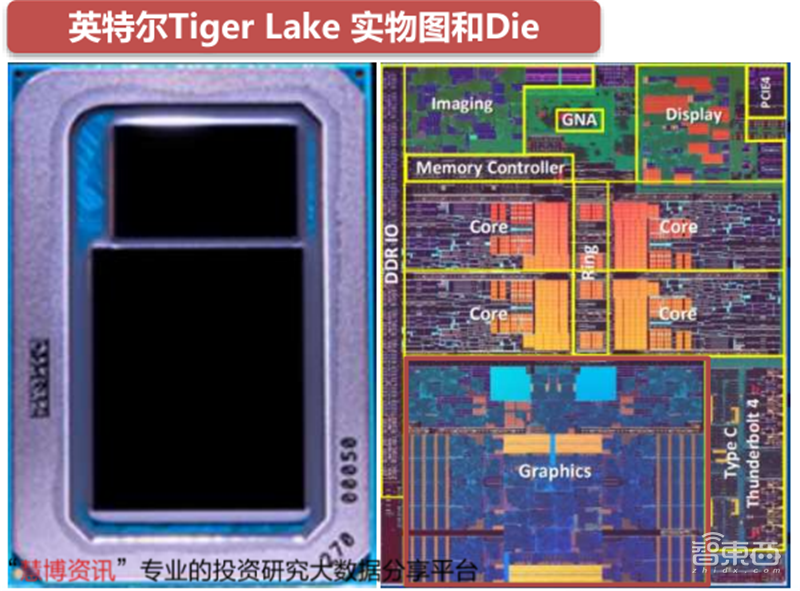
▲英特尔Tiger Lake 实物图和Die
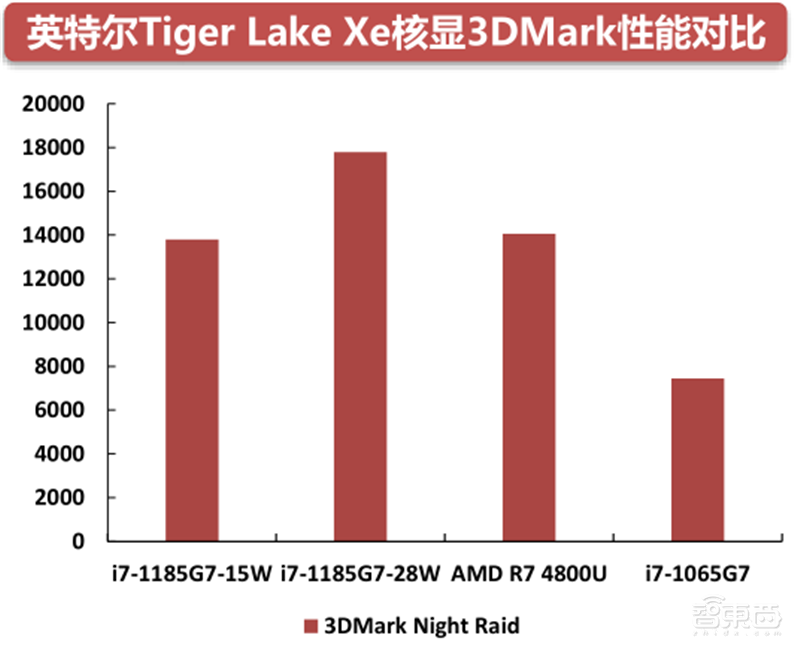
▲英特尔Tiger Lake Xe核显3DMark性能对比
英特尔独立GPU分为锐炬Xe MAX和服务器GPU,均隶属于Xe LP系列,微架构与核显Xe相同,采用标准封装和10纳米SuperFin制程。
目前,锐炬Xe MAX是第一款基于英特尔 Xe 架构的面向轻薄型笔记本电脑的GPU。锐炬Xe MAX在Xe集成GPU的基础上增加了4GBLPDDR4X-4266的独立显存,TDP 25W,峰值主频1650MHz,单精度浮点性能2.46TFLOPs。锐炬Xe MAX可以和11代酷睿处理器、锐炬Xe GPU同时工作。借助英特尔Deep Link技术,获得具有强大性能和经过功耗优化的集成系统,以改进创造力和游戏体验。
目前,英特尔服务器GPU在Xe核显的基础上,TDP提升到23W,增加了8GB LPDDR4的独立显存,支持高密度、低延迟的安卓云游戏和高密度媒体转码/编码,以实现实时的OTT视频直播。同时,英特尔服务器GPU支持2颗、4颗独立GPU的聚合,成倍提高性能。
未来,英特尔还将推出面向游戏和高性能桌面的Xe HPG产品线,增加了光线追踪等硬件支持,采用传统封装,外包生产。英特尔服务器GPU将使用Xe HPC、Xe HP微架构,采用2.5D和3D先进封装,10纳米SuperFin及更先进自家或外包工艺。
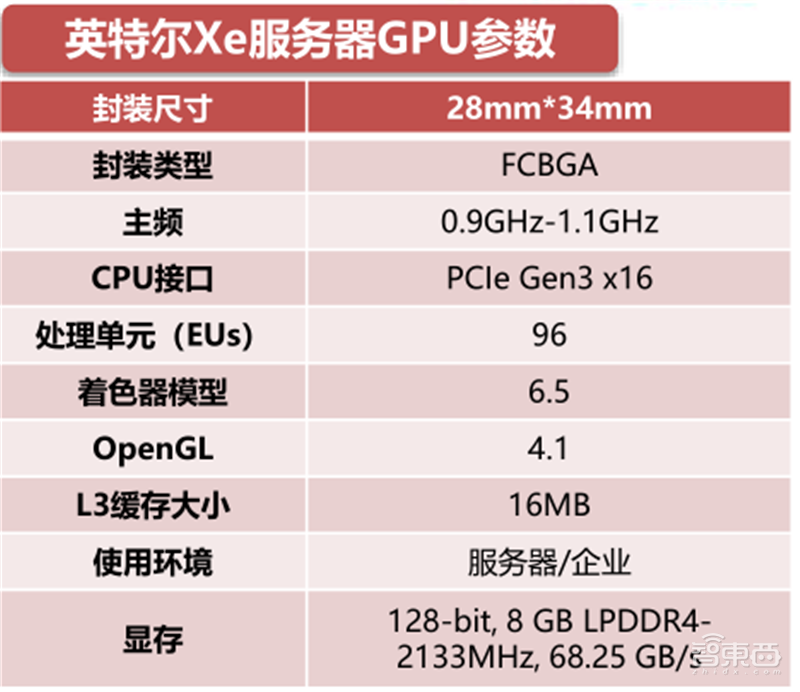
▲英特尔Xe服务器GPU参数

▲英特尔Xe产品、封装、制程

▲英特尔锐炬Xe MAX
4、ARM Mali:全球GPU IP巨头
ARM是全球最大的半导体IP提供商。全世界超过95%的智能手机和平板电脑都采用ARM架构。2019Q2,全球近43%的手机和平板GPU由Mali驱动。2020第四季度,ARM半导体合作伙伴基于ARM技术的芯片出货量达到67亿颗,再创历史新高,超过其他所有流行的CPU指令集架构—X86、ARC、Power、MIPS的总和。
国产SoC中,有95%是基于ARM处理器技术,ARM中国授权客户超过150家,基于ARM架构的国产芯片出货量已经超过184亿。
ARM的Mali GPU按性能可以分为3大类,分别是高性能、主流、高能效。
▲ARM IP组合和SoC设计

▲ARM Mali GPU路线图
Arm Mali-G78 GPU是用于高端设备的第二代基于Valhall架构的GPU。Mali-G78是性能最高的ArmGPU,可支持复杂的应用,例如适用于Vulkan和OpenCL等所有最新API的游戏图形和机器学习(ML)。
Mali-G78与上一代设备相比,GPU性能提高了25%,并增强了设备上的ML功能,从而有助于将高度复杂的游戏带入移动设备。Mali-G78最多支持24个内核,并包含异步顶级功能,可确保性能有效地分布在各个内核上,从而使图形运行更加流畅。全新执行引擎中的新型融合乘加(FMA)单元可进一步降低30%的单元能耗。
在GFXBench Aztec Ruin的跑分中,使用台积电5纳米工艺,搭载24个Mali-G78内核的麒麟9000 SoCGPU的帧数强于骁龙865的Adreno 650,但仍落后于苹果A14。
▲ARM Mali-G78

▲麒麟9000系列的ARM Mali-G78应用
Imagination Technologies是一家总部在英国,专注于半导体和相关知识产权许可,销售PowerVR移动图形处理器,MIPS嵌入式微处理器和消费电子产品。公司还提供无线基带处理,网络,数字信号处理器,视频和音频硬件,IP语音软件,云计算,以及芯片和系统设计服务。2017年,董事会宣布公司被中资的Canyon Bridge收购。
Imagination在GPU领域历史悠久,在其超过25年的历史中,Imagination先后推出过多代GPU产品,已积累超过1500项GPU专利,曾为苹果供应图像处理器(GPU),在图像处理器(GPU)领域与高通、ARM三分天下,曾占GPU市场大约占据三分之一的份额,在汽车领域更是达到43%。带有Imagination IP的芯片产品累计出货量已超过110亿。
Imagination的IP包括图形处理器和视觉与人工智能2类。公司Power VR产品被广泛应用于移动设备(智能手机、平板)、汽车(仪表、信息娱乐、辅助驾驶)、沉浸式体验(AR/VR)、消费电子(电视、机顶盒)。
根据Imagination的GPU路线图,在A系列GPU性能最高提升2.5倍之后,B系列到D系列GPU的年复合增速在30%左右。2021年的C系列GPU将首次加入L4级别的光线追踪,从硬件层面支持一致性分类的层次包围体(BVH)和复杂光线处理,相比目前英伟达和AMD的L3级别光线追踪方案可显著提升能效,实现更好的用户体验。

▲IMG系列GPU路线图
5、全球GPU IP巨头:Imagination
2020年10月,Imagination推出了全新的IMG B系列GPU,这是公司第一个包含新多核架构的GPU IP系列,也是首次采用RISC-V,可提供最高的性能密度。得益于多核架构和Imagination图像压缩技(IMGIC),B系列相比A系列,功耗降低30%,带宽降低35%、面积缩减25%,AI算力达到24 TOPS,且填充率比竞品IP内核高2.5倍。与A系列相似,B系列GPU也支持AI协同技术,在提供图形处理功能的同时,可用备用资源来处理可编程AI等任务。
IMG B系列GPU共有IMG BXE、IMG BXM、IMG BXT、IMG BXS四种系列。其中IMG BXE面向高清显示应用,IMG BXM主打图形处理体验,IMG BXT面向高性能应用,IMG BXS面向未来汽车。
BXS系列符合ISO 26262标准,也是迄今为止所开发的最先进汽车GPU IP内核。BXS提供了一个完整的产品系列,从入门到高端,可为下一代人机界面(HMI)、UI显示、信息娱乐系统、数字驾舱、环绕视图提供解决方案。高计算能力的配置可支持自动驾驶和ADAS。
凭借核心可扩展的优势,IMG B系列适用于传统移动设备、消费类设备、物联网、微控制器、数字电视(DTV)和汽车等市场领域。IMG B系列也可扩展至桌面GPU、云端GPU服务器,且支持自动驾驶和辅助驾驶等。
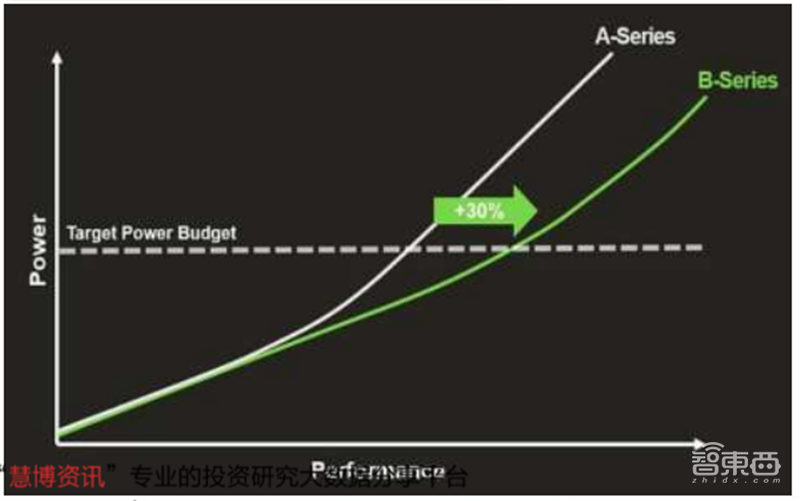
▲IMG B系列对比A系列能效提升

▲Imagination GPU组合
6、高通Adreno:全球移动GPU先驱
高通的自研GPU Adreno源于收购的AMD移动GPU Imageon系列。早期的Adreno 100系列只有2D图形加速和有限的多媒体功能。2008年发布的Adreno 200是首款被集成到骁龙SoC中的GPU,并加入了3D硬件加速功能。
2020年12月,高通推出了搭载Adreno 660的骁龙888 SoC。Adreno 660继承了Adreno650的微架构,采用了三星5纳米LPE工艺,大幅提高主频,使图形渲染性能提高35%,能效提高20%。Adreno 660全面支持Qualcomm® Snapdragon Elite Gaming和Qualcomm® Game Quick Touch ,二者将可变速率渲染和响应速度分别提升30%和20%。
在GFXBench Aztec Ruin 1080P测试中,Adreno 660的峰值帧数追平麒麟9000,但相较苹果A14仍有近20%的差距。
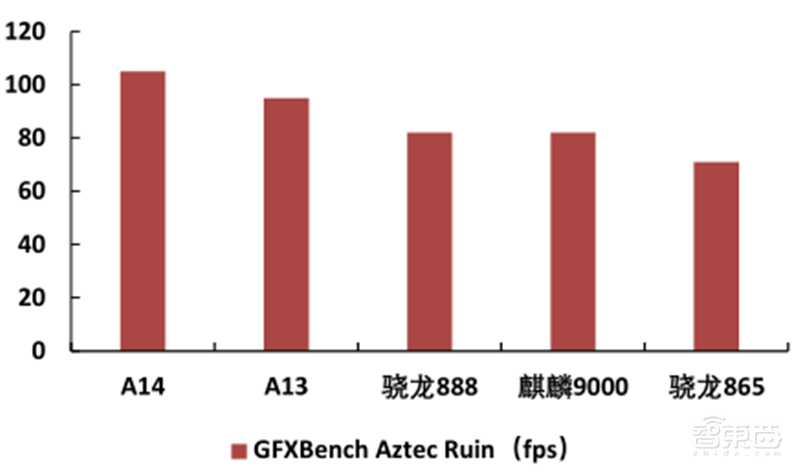
▲高通Adreno 660 1080P性能对比

▲高通Adreno 660 GPU
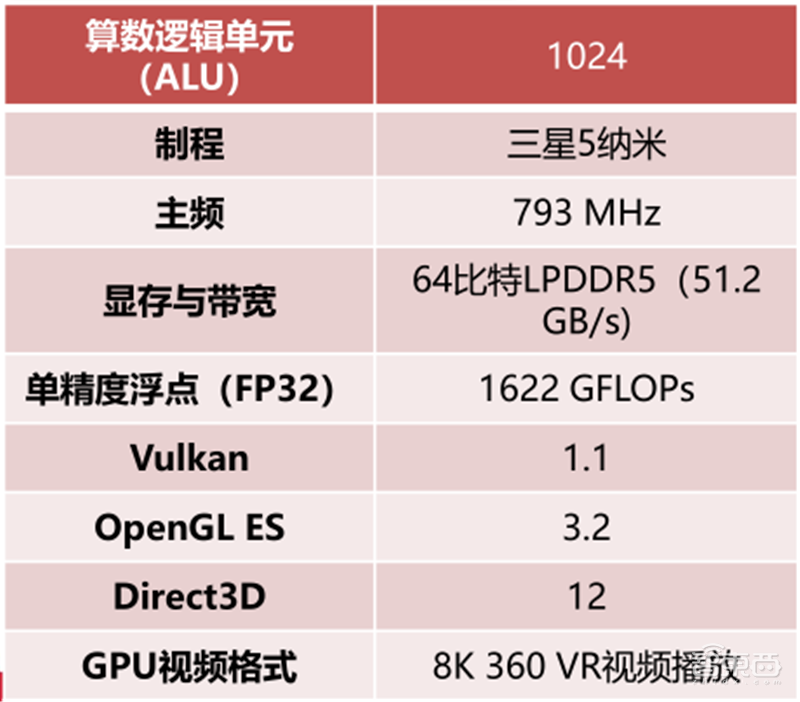
▲高通Adreno 660参数
7、苹果:全球移动GPU新秀
苹果的自研GPU首次出现于2017年的A11 SoC。A11的三核心GPU作为苹果的首款自研GPU,其性能超过采用Power VR GT7600+的A10 GPU 30%。其后,所有的A系列SoC的GPU均为苹果自研。
2020年,苹果推出了5纳米制程的M1芯片,该款SoC基于A14芯片,在CPU、GPU、NPU、缓存等各方面都进行了强化,用于驱动苹果的Mac产品。M1芯片的发布标志着苹果继2005年放弃IBM的PowerPC指令集转向Intel的X86指令集后的又一大PC领域转换。
采用8核GPU的M1拥有128个执行单元,可以同步运行近25000个线程,单精度浮点算力达到2.6 TFLOPs。M1 GPU的能效表现是当时同类PC中集成GPU的三倍,峰值性能最高可达其他GPU的2倍。
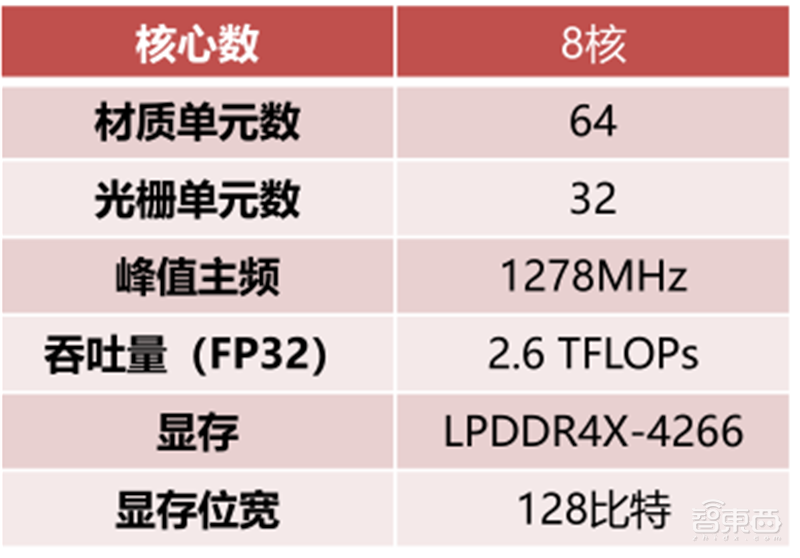
▲苹果M1 GPU参数
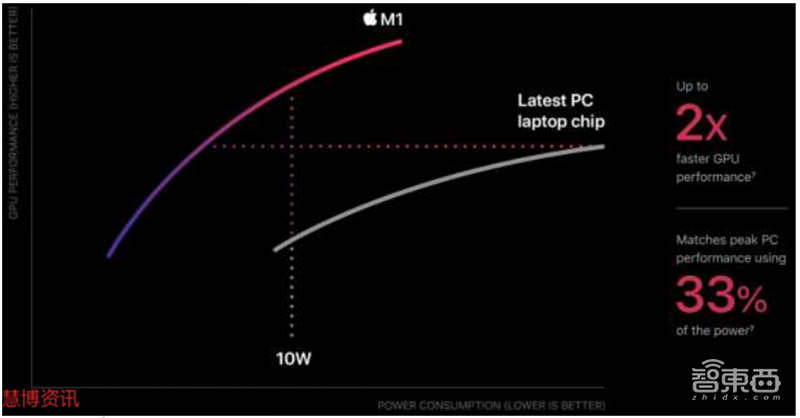
▲苹果M1能效对比
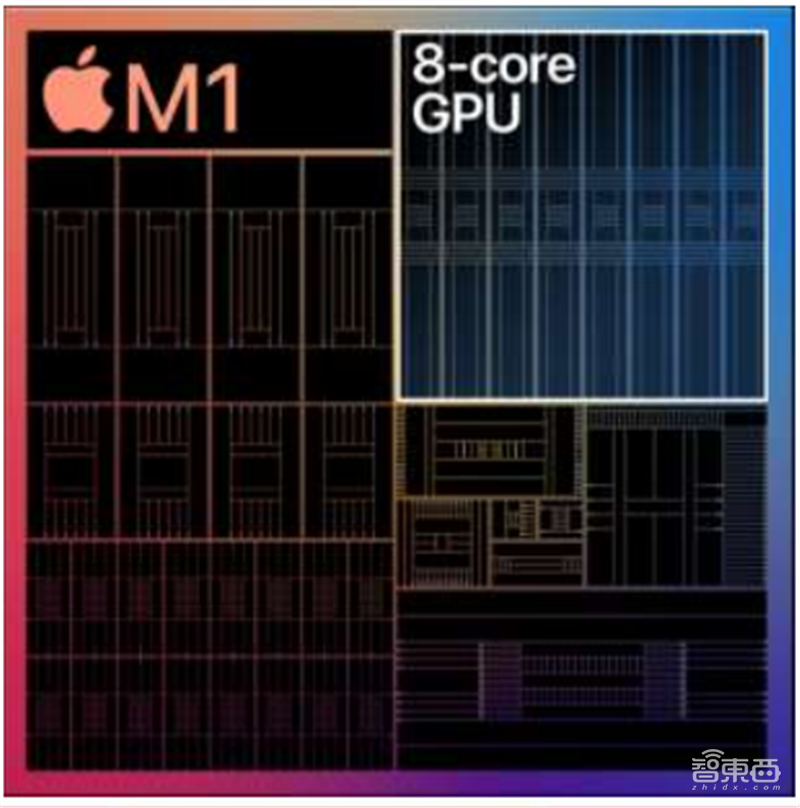
▲苹果M1 8核GPU
三、国产GPU自主之路
国产GPU的发展落后于国产CPU,直到2014年4月,景嘉微才成功研发出国内首款国产高性能、低功耗GPU芯片—JM5400。在国产GPU的开发中,GPU对CPU的依赖性和GPU的高研发难度,阻碍了该产业的快速发展。
首先,GPU对CPU有依赖性。GPU结构没有控制器,必须由CPU进行控制调用才能工作,否则GPU无法单独工作。所以国产CPU较国产GPU先行一步是符合芯片产业发展逻辑的。
再者,GPU技术难度很高。Moor Insights & Strategy首席分析师莫海德曾表示:“相比CPU,开发GPU要更加困难,而GPU设计师、工程师和驱动程序的作者都要更少。”国内人才缺口也是国产GPU发展缓慢的重要原因之一。在芯片行业,一般来说,培养一位拥有丰富经验并且能够根据市场动态及时修改芯片设计方案的成熟工程师,至少需要10年。
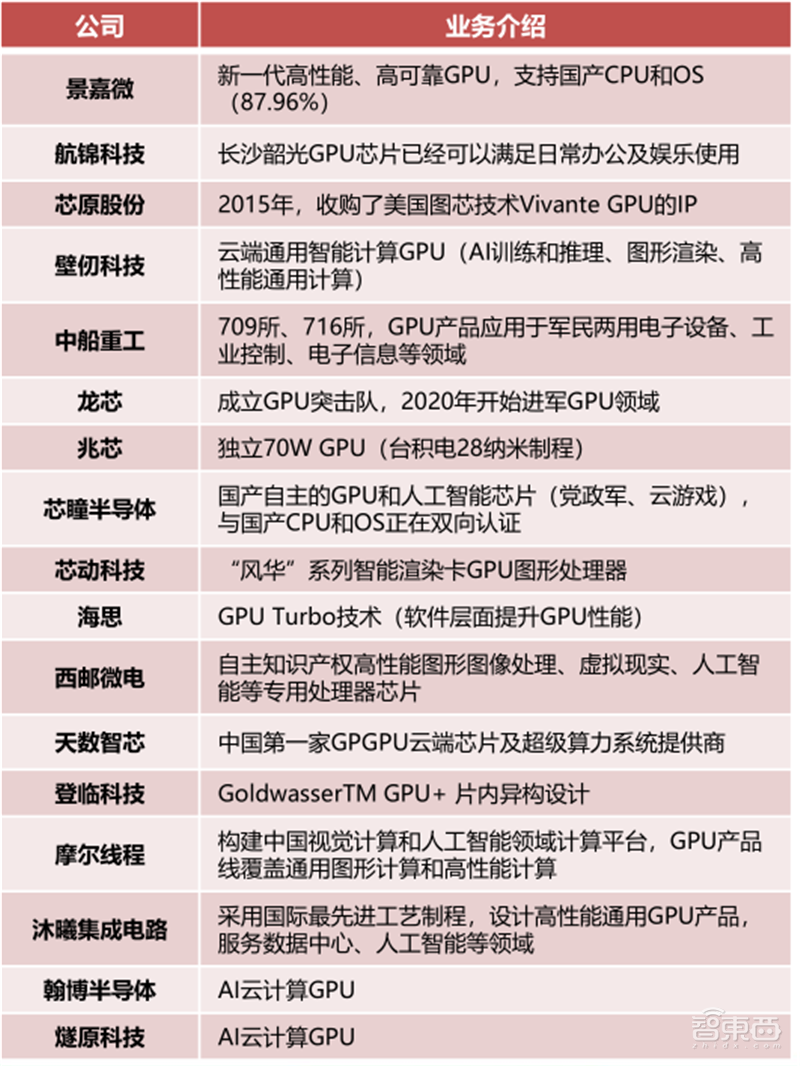
▲国产GPU公司及其业务简介
中国GPU市场规模和潜力非常大,庞大的整机制造能力意味着巨量的GPU采购。虽然近些年,计算机整机和智能手机产量增长都出现瓶颈,但由于这两类产品体量庞大,2019年国内智能手机出货量为3.72亿部,电子计算机整机年产量达到3.56亿台,GPU的需求量大且单品价值非常高,市场规模依然非常可观。
同时,服务器GPU伴随着整机出货的快速成长,需求量增长也较为迅速。据统计,2018年国内服务器出货量达到330.4万台,同比增长26%,其中互联网、电信、金融和服务业等行业的出货量增速也均超过20%。另外,国内在物联网、车联网、人工智能等新兴计算领域,对GPU也存在海量的需求。
据统计,近年来中国集成电路自给率不断提升,2018年为13%,预计2020年有望提升至15%,但仍然处于较低水平。根据国务院印发的《新时期促进集成电路产业和软件产业高质量发展的若干政策》等文件,中国芯片自给率要在2025年达到70%,这将产生8000亿元的国产芯片需求。中国芯片产业发展空间非常大。
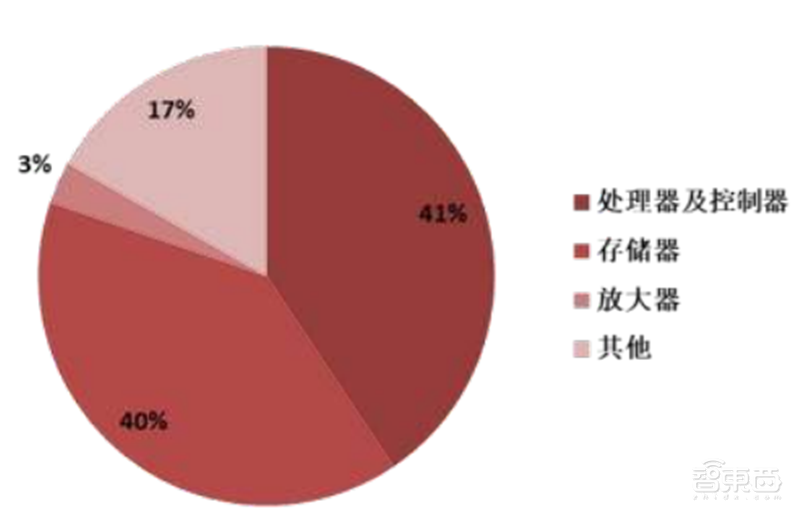
▲2019年中国大陆集成电路进口额结构
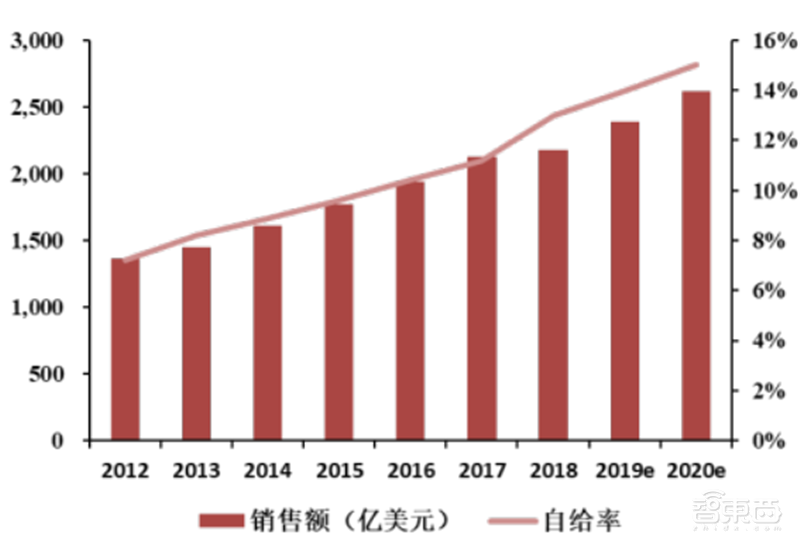
▲2012-2020年中国大陆集成电路自给率
1、景嘉微:具有完全自主知识产权,打破国外GPU长期垄断
长沙景嘉微电子股份有限公司成立于2006年4月,位于长沙市高新技术开发区,公司拥有经验丰富的集成电路设计团队,是国产GPU的主要参与者,也是唯一自主开发并已经大规模商用的企业。
2014年4月,成功研发出国内首款国产高可靠、低功耗GPU芯片-JM5400,具有完全自主知识产权,打破了国外产品长期垄断我国GPU市场的局面,在多个国家重点项目中得到了成功的应用;
2018年8月,公司自主研发的新一代高性能、高可靠GPU芯片-JM7200流片成功,将国产GPU的技术发展提高到新的水平,可为各类信息系统提供强大的显示能力;
2019年,公司在JM7200基础上,推出了商用版本-JM7201,满足桌面系统高性能显示需求,并全面支持国产CPU和国产操作系统,推动国产计算机的生态构建和进一步完善。
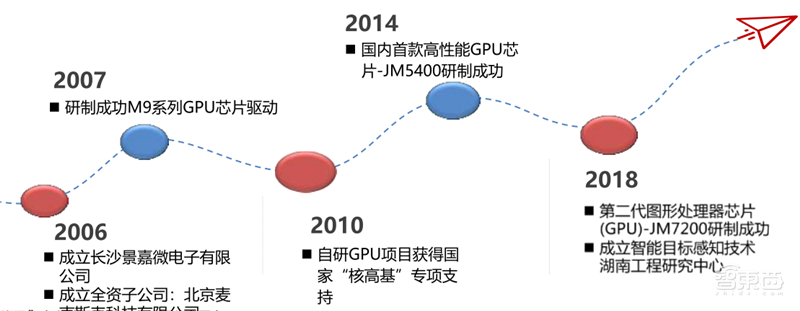
▲景嘉微发展历程
景嘉微已完成两个系列、三款GPU的量产应用,产品覆盖军用和民用两大市场。景嘉微第一代GPU JM5400主要运用于军用市场,替代原ATI M9、M54、M72等美系GPU芯片。景嘉微第二代GPU JM7200在产品性能和工艺设计上较JM5400有较大提升,是首例进入民用市场的图形芯片。公司与国内主要CPU厂商和计算机整机厂商已建立合作关系。JM7201在JM7200的基础上对民用市场的桌面应用进行了优化,推出标准MXM和标准PCIE显卡,在保证性能的同时,降低了功耗,缩小了体积。

▲景嘉微国产GPU芯片产品线
景嘉微的第二代GPU JM7200系列于2018年8月流片成功,并在2019年3月获得首个订单。相较于前代JM5400,JM7200在理论性能上有翻倍的提升,同时制程也进化到了28纳米。但是JM7200在显存带宽、像素填充率、浮点性能等方面较2012年发售,采用完整版GK107核心的英伟达GT640还有相当差距。
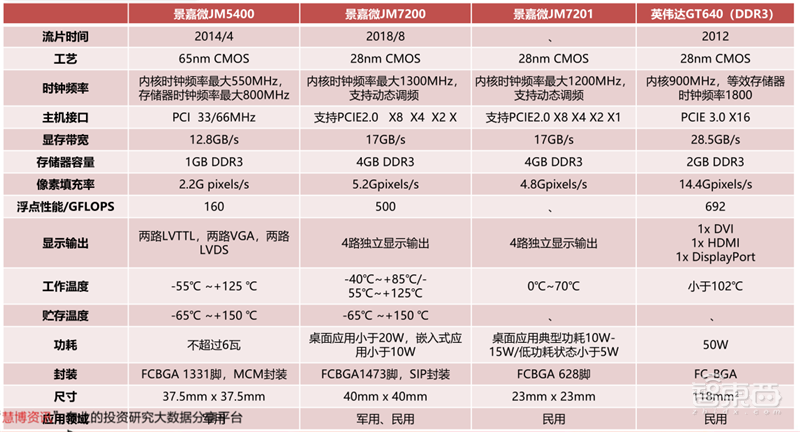
▲各景嘉微GPU参数对比
2018年12月,景嘉微定增募集10.88亿元,用于高性能通用图形处理器和面向消费电子领域的通用类芯片研发和产业化项目。其中,高性能通用图形处理器项目包括JM9231和JM9271两款GPU芯片,分别面向不同应用领域的中、高档系列产品。据公司2020年中报显示,下一代图形处理器研发处于后端设计阶段,研发进程一切顺利。
景嘉微JM9系列是继JM5400和JM7200局部渲染计算内核之后,首次采用统一渲染结构的GPU,并且增加了可编程计算模块数量。JM9231和JM9271在性能表现分别与英伟达于2016年推出的GTX1050和GTX1080相近。JM9系列的推出将使公司GPU水平与海外龙头水平缩短至5年,大幅提升公司在GPU领域的竞争力。
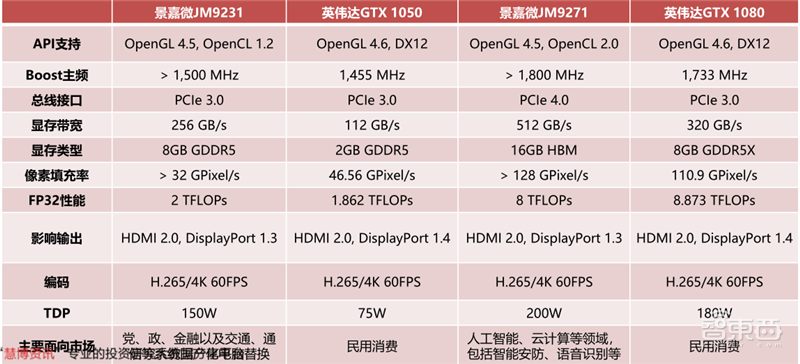
▲景嘉微后续高性能通用GPU性能参数对比
2、芯原微电子:国产GPU IP龙头
芯原微电子是依托自主半导体IP,为客户提供平台化、全方位、一站式芯片定制服务和半导体IP授权服务的企业。公司至今拥有高清视频、高清音频及语音、车载娱乐系统处理器、视频监控、物联网连接、数据中心等多种一站式芯片定制解决方案,以及5类自主可控的处理器IP,分别为图形处理器IP、神经网络处理器IP、视频处理器IP、数字信号处理器IP和图像信号处理器IP,以及1,400多个数模混合IP和射频IP,年均流片项目超过40个。主营业务的应用领域广泛包括消费电子、汽车电子、计算机及周边、工业、数据处理、物联网等,主要客户包括IDM、芯片设计公司,以及系统厂商、大型物联网公司等。
芯原在传统CMOS、先进FinFET和FD-SOI等全球主流半导体工艺节点上都具有优秀的设计能力,先进工艺制程覆盖14nm/10nm/7nm FinFET和28nm/22nm FD-SOI,并已开始进行5nm FinFET 芯片的设计研发和新一代 FD-SOI 工艺节点芯片的设计预研。
此外,根据Ipnest统计,芯原是2019年中国大陆排名第一、全球排名第七的半导体IP授权服务供应商,全球市场占有率约为1.8%。

▲芯原股份发展历程
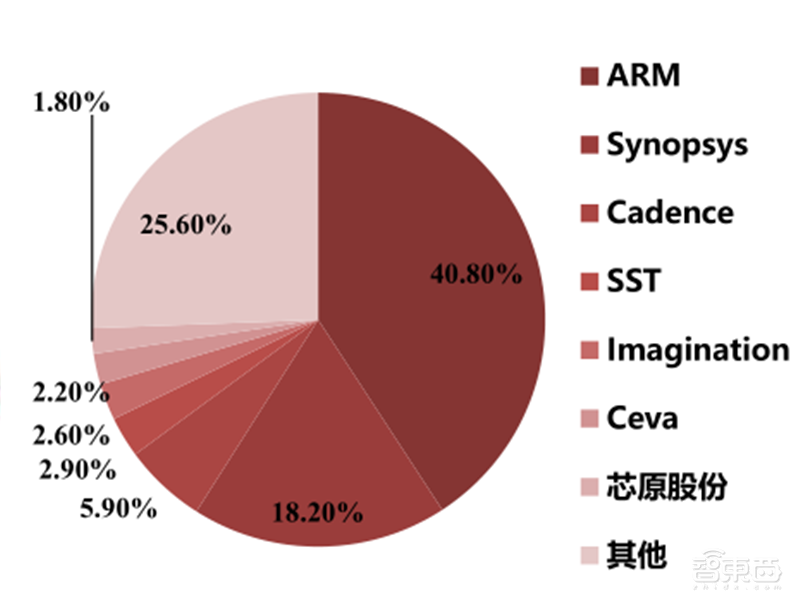
▲2019全球IP企业市占率排名
芯原GPU IP源于公司在2016年收购的美国嵌入式GPU设计商图芯技术(Vivante)。芯原在GPU IP领域已经掌握了支持主流图形加速标准、自主可控指令集和可拓展性强,性能范围广泛等核心技术,可广泛应用于IOT、汽车电子、PC等市场。根据 IPnest 报告,芯原GPU IP(含 ISP)市场占有率排名全球前三,仅次于ARM和Imagination,2019 年全球市场占有率约为 11.8%。
目前,芯原在图形处理器技术的研发课题包括通用图形处理器运算内核的持续优化和矢量图形处理器DDR-Less技术。矢量GPU DDR-Less技术可以在不使用外部存储器DDR的基础上,实现架构清晰、分工明确、易于使用、软件控制流程简单等优点,适用于物联网、可穿戴设备和车载设备。
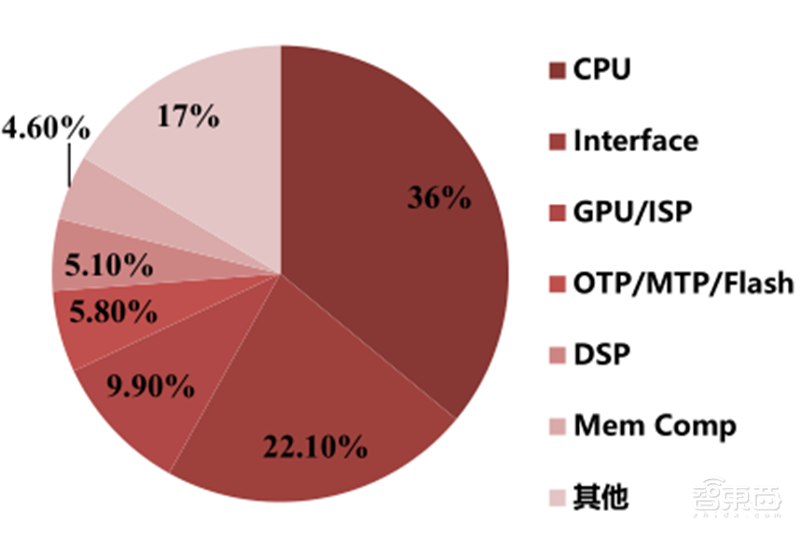
▲2019全球IP设计分类

▲芯原GPU IP的核心技术和典型应用示例
芯原可拓展Vivante GPU IP应用涵盖从低功耗的小型物联网MCU(GPU Nano IP系列)到面向汽车和计算机应用的强大SoC(GPUArcturus图形IP),可满足各种芯片尺寸和功耗预算,是具有成本效益的优质图形处理器解决方案。
芯原的的图形处理器技术支持业界主流的嵌入式图形加速标准Vulkan1.0、OpenGL3.2、OpenCL1.2 EP/FP和OpenVX1.2等,具有自主可控的指令集及专用编译器,支持每秒2500亿次的浮点运算能力及128个并行着色器处理单元。
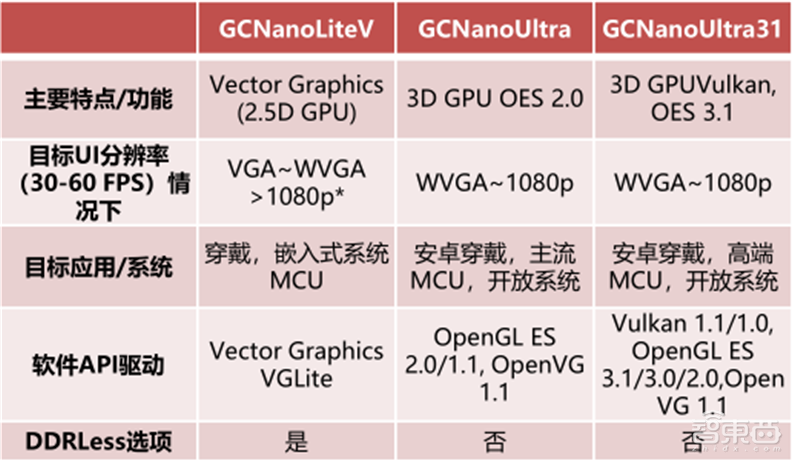
▲芯原GPU Nano IP产品线及其可应用场景
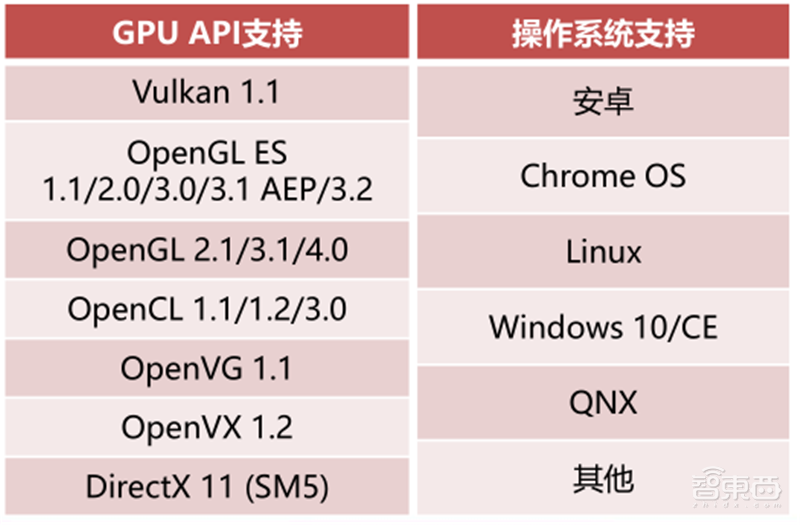
▲芯原GPU IP API和操作系统兼容性
芯原股份现有的半导体IP分为处理器IP、数模混合IP及射频IP,其中GPU IP隶属于处理器IP。整体来看,2017-2019芯原得益于不断丰富的IP储备及一站式芯片定制业务的协同效应,公司半导体IP授权业务收入持续上升,GPU IP的年复合增速达13%。2019年GPU IP的营收占公司半导体IP营收的31.29%,主要由于其他类型IP收入上升,GPU IP比重相对下降。
芯原在图形处理器技术方面的研发包括高性能的通用图形处理器GC8400 IP,该IP适用于汽车电子,目前仍处IP设计验证阶段,拟达到每秒1万亿次的浮点运算能力双倍精密度,512个并行着色器处理单元 。
3、航锦科技
航锦科技是一家大型化工生产基地,公司的前身是锦西化工总厂。2017下半年,航锦科技通过收购长沙韶关和威科电子两家军工企业,挺进电子产业,形成化工+电子双主业发展模式,构建起三个支撑板块(化工、电子、金融)。
航锦科技电子板块以芯片为核心产品,围绕高端芯片与通信两大领域,覆盖高端芯片(图形处理芯片/特种FPGA/存储芯片/总线接口芯片)、北斗3芯片以及通信射频三大主要产业。坚持军民两用为发展方向,产品广泛应用于航空、航天、兵器、船舶、电子等领域,拥有广阔的市场空间。
航锦科技的GPU技术源于并购的长沙韶光。2018年,长沙韶光自主研发和合作研发的第一代及第二代图形处理芯片(GPU)获得集成电路布图设计登记证书;2019年,长沙韶光自主研发的第二代改进型图形处理芯片在自主可控设备领域的应用得到验证,并收获相关订单。
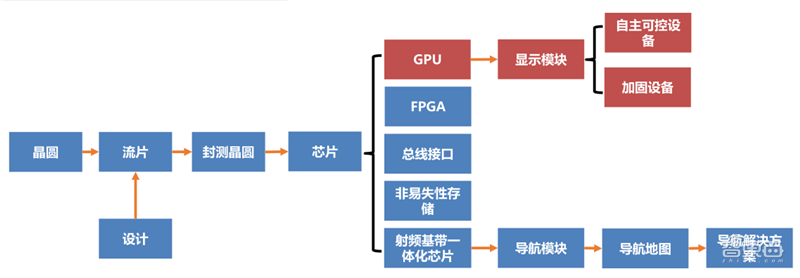
▲航锦科技自主可控芯片板块示意图
4、兆芯:同时掌握CPU、GPU、芯片组三大核心技术
上海兆芯集成电路有限公司,简称“兆芯”,由上海联合投资有限公司(上海市国资委完全出资)和中国台湾威盛电子共同成立,也是世界上第三家拥有X86授权的微处理器公司,总部位于上海张江,在北京、西安、武汉、深圳等地设有研发中心和分支机构。
公司同时掌握CPU、GPU、芯片组三大核心技术,且具备三大核心芯片及相关IP设计与研发的能力,致力于通过技术创新与兼容主流的发展路线,推动信息产业的整体发展,并获评了“高新技术企业资质”。兆芯提供了桌面整机,服务器,工业主板,工业平台,系统级解决方案,在党政办公,交通,金融,能源,教育,网络安全方面有着广泛的应用。
2019Q2,兆芯发布了全新的用于PC的处理器KX-6000系列。KX-6000是业内第一款完整集成CPU、GPU、芯片组的SoC单芯片国产通用处理器。
KX-6000系列处理器采用16纳米制程,集成高性能显卡,支持DP/HDMI/VGA输出,兼容DirectX、OpenGL、OpenCL等主流API,最高可同时输出3台显示器,分辨率可达4K。
全新的KX-6000系列处理器拥有出色的兼容性和应用体验,包括Windows操作系统,日常办公应用,4K视频解码和主流游戏。

▲兆芯KX-6000系列兼容性和应用体验
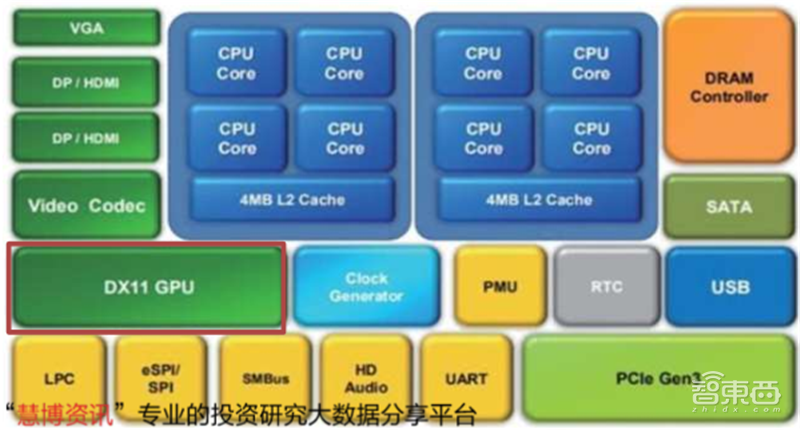
▲兆芯KX-6000处理器芯片架构
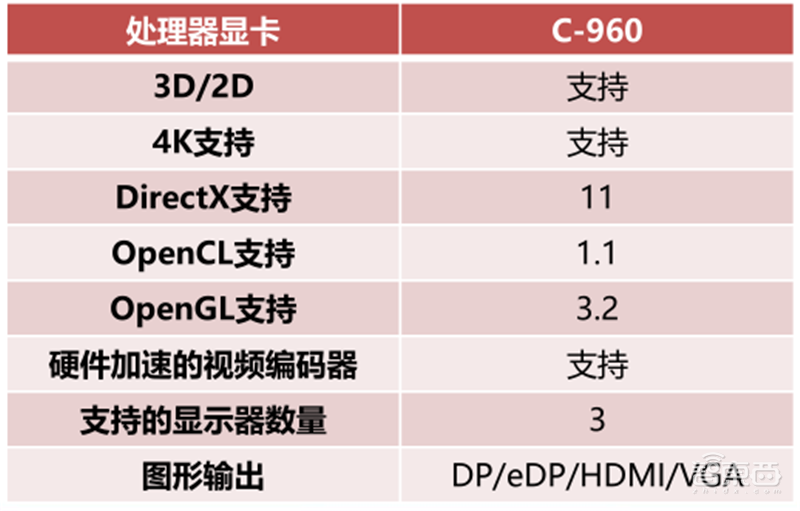
▲兆芯KX-6000处理器集成显卡参数
兆芯KX-6000的C-960 GPU在使用惠普兆芯图形DCH驱动的情况下,Dota 2游戏性能表现远落后英特尔酷睿i5-7400的UHD 630。未来,兆芯还会对KX系列处理器进行进一步的更新,使用全新的CPU架构,将内存从DDR4升级为DDR5,将总线从PCIe3.0升级至PCIe4.0。内存和总线的升级分别可以提高显卡的带宽和CPU与GPU间的通讯速度。
除了以上集成GPU外,兆芯还计划发布一款采用台积电28纳米工艺,TDP 70瓦的独立GPU。
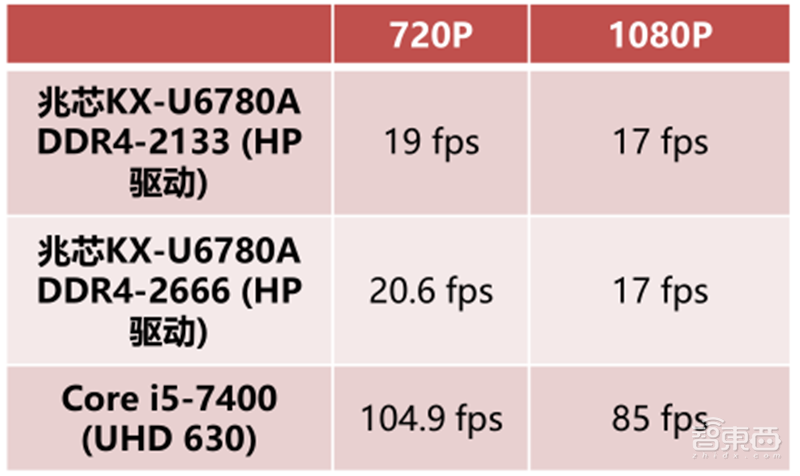
▲兆芯KX6000 GPU游戏性能对比
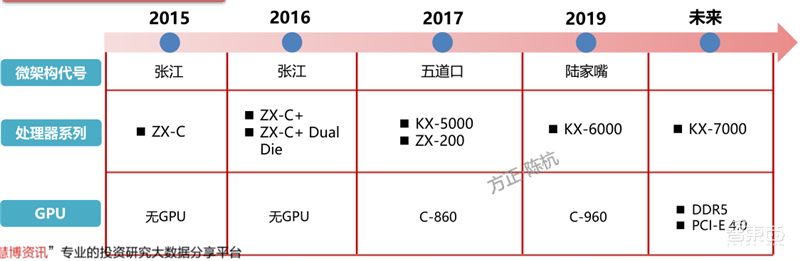
▲兆芯处理器发展路线图
5、凌久电子GPU
凌久电子创立于1983年,是中国船舶重工集团公司第七〇九研究所控股的高新技术企业。
凌久电子以嵌入式实时信号处理与高性能计算技术为基础,面向船舶、航空、航天、兵器等国防电子领域及轨道交通、海工装备、能源电力、半导体制造等民用高科技领域提供芯片级、模块级、设备级、系统级等软硬件产品;面向科研院所、部队及军校提供作定制化军事仿真服务。
凌久电子产品包括元器件类产品、基础硬件设备、基础支撑软件、应用类产品四大类。其中国产通用GPU GP101隶属于元器件类产品。
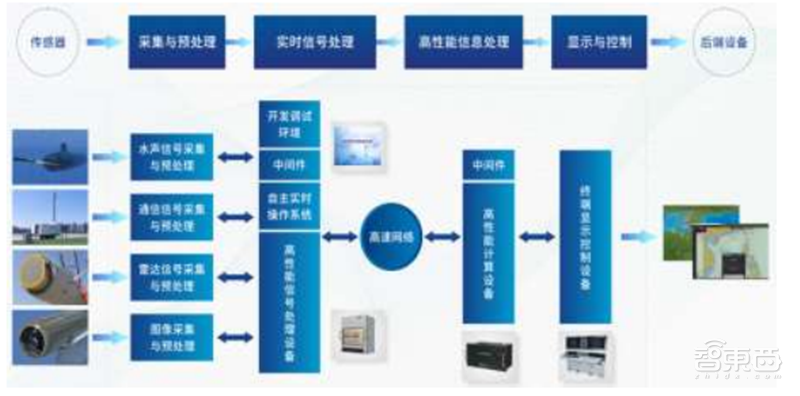
▲凌久电子平台产品
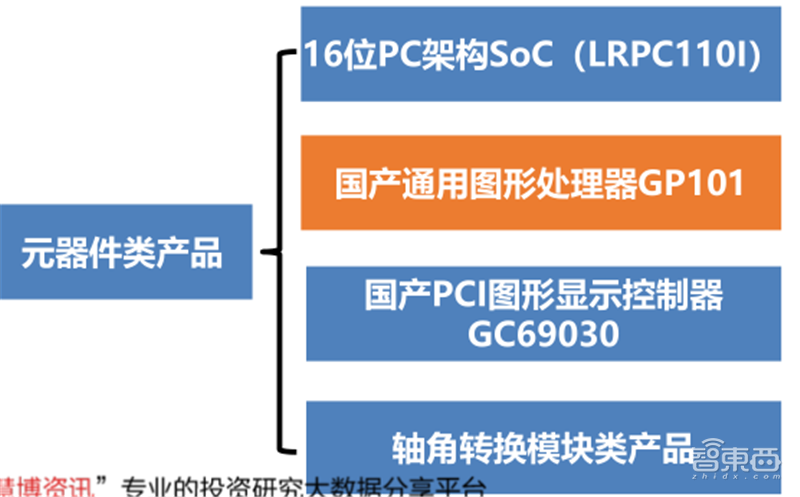
▲凌久电子元器件类产品分类
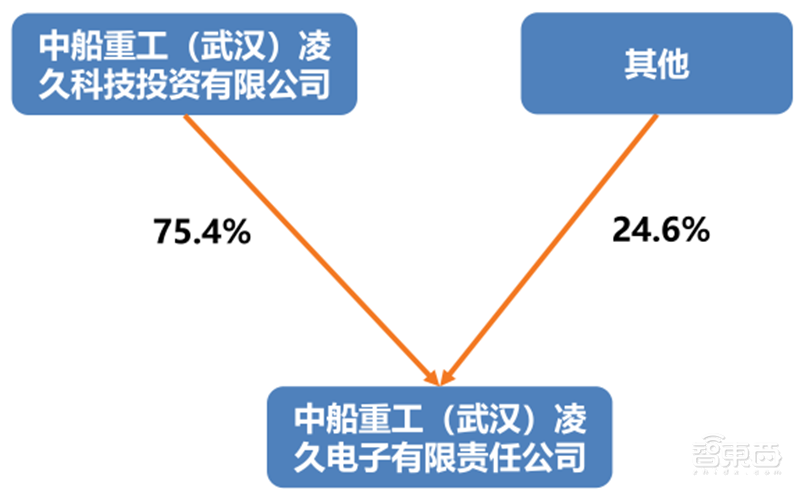
▲凌久电子股权结构
GP101是由中国船舶重工集团第709研究所控股的凌久电子研制,具备完全自主知识产权的图形处理器芯片。GP101支持2D/3D图形加速,支持二维矢量图形加速,支持4K分辨率、视频解码和硬件图层处理等功能GP101支持VxWorks、Linux、Windows等通用操作系统,支持中标麒麟、道等国产操作系统,支持龙芯、飞腾、申威等国产处理器。
GP101实现了我国通用3D显卡零的突破,在信息安全和供货能力方便有充分的保障,可以广泛应用于军民多个领域。
6、中船重工716研究所:JARI G12 GPU
七一六所自主研发的JARI G12是2018年性能最强的国产通用图形处理器。该处理器采用混合渲染架构,兼顾数据带宽和渲染延时需求,极大地增强了芯片的灵活性和适应性;
提供PCIe 3.0总线,支持x86处理器和龙芯、飞腾、申威等国产处理器;支持4路数字通道和1路VGA输出,提供DP、eDP、HDMI、DVI等通用显示介面,单路数字通道最大输出分辨率为3840×2160@60fps,支持扩展、复制显示和“扩展+复制”显示模式;
内建视频编解码硬核,支持2路3840×2160分辨率视频的编码、解码功能;
支持OpenGL 4.5和OpenGL ES 3.0,满足高性能3D加速和VR显示需求;
支持OpenCL 2.0,满足并行计算和云计算的使用需求;
集成张量加速计算硬核,支持AI计算加速。该GPU支持Windows、Linux、VxWorks等主流操作系统,同时支持中标麒麟、JARI-Works、道等国内自主可控操作系统,具备健全的生态环境体系。
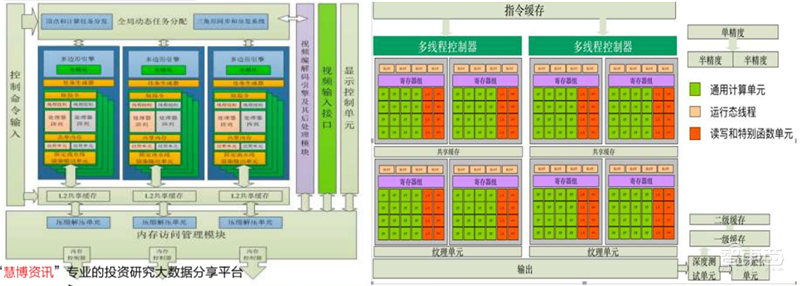
▲JARI G12架构示意图
7、芯动科技:国产IP和芯片定制先驱
芯动科技是中国一站式IP和芯片定制领军企业,提供全球6大工艺厂(台积电/三星/格芯/中芯国际/联华电子/英特尔)从130nm到5纳米全套高速混合电路IP核和ASIC定制解决方案,聚焦先进制程。
芯动科技15年来立足本土发展,所有IP和产品全自主可控,连续十年中国市场份额领先。公司客户群涵盖华为海思、中兴通讯、瑞芯微、全志、君正、AMD、Microsoft、Amazon、Microchip、Cypress等全球知名企业。
在高性能计算/多媒体&汽车电子/IoT物联网等领域,芯动解决方案具有国际先进水平,涵盖DDR5/4、LPDDR5/4、GDDR6/GDDR6X、HBM2e/3、Chiplet、HDMI2.1、32G/56G SerDes(含
PCIe5/4/USB3.2/SATA/RapidIO/GMII等)、ADC/DAC、智能图像处理器GPU和多媒体处理内核等多种技术。芯动科技的芯片定制,跨工艺跨封装,涉及从需求到产品, 能端到端为客户加速从规格、设计到流片量产,及封装成型全流程。
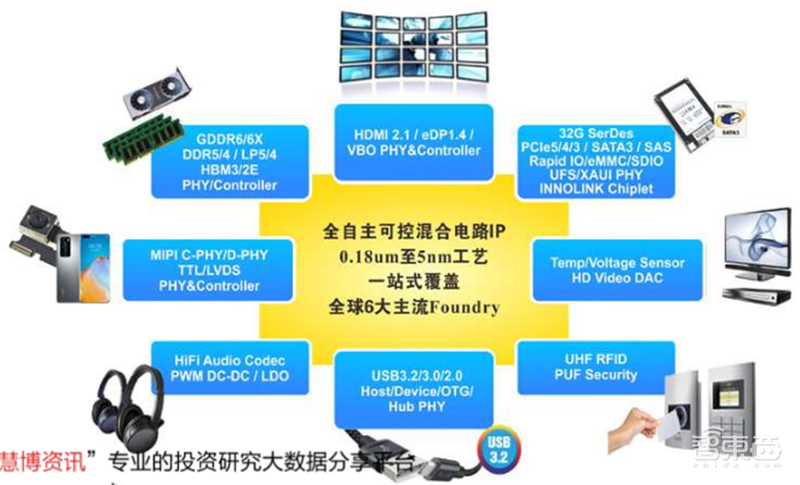
▲芯动科技一站式IP系列

▲芯动科技高性能计算平台IP
2020年10月13日,芯动科技与Imagination达成合作。采用最前沿的多晶粒芯片(chiplet)和GDDR6高速显存等SOC创新,芯动科技将全球首发Imagination全新顶配BXT多核架构。
在信创和算力安全方面,“风华”系列GPU内置国产物理不可克隆iUnique Security PUF信息安全加密技术,提升数据安全和算力抗攻击性,支持桌面电脑和数据中心GPU计算自主可控生态。
“风华”系列GPU自带浮点和智能3D图形处理功能,全定制多级流水计算内核,兼具高性能渲染和智能AI算力,还可级联组合多颗芯片合并处理能力,灵活性强,适配国产桌面市场1080P/4K/8K高品质显示,支持VR/AR/AI,多路服务器云桌面、5G数据中心、云教育、云游戏、云办公等中国新基建5G风口下的大数据图形应用场景。
8、华为海思:GPU Turbo
GPU Turbo是一种软硬协同的图形加速技术,可以减少无用渲染次数,优化或合并渲染区域。通过算法,将相关运算放在一个或相邻的寄存器中,以此来优化图形处理效率。
GPU Turbo技术打通了EMUI操作系统以及GPU和CPU之间的处理瓶颈,在系统底层对传统的图形处理框架进行了重构,实现了软硬件协同,使得GPU图形处理整体效率得到大幅提升。
2018年6月发布了GPU Turbo 1.0,图形处理效率提高60%,同时做到更省电,保证高画质。
2018年9月发布了GPU Turbo 2.0,游戏场景下功耗下降可达13.6%,新增支持多款主流游戏,同时针对支持的游戏中关键&极限场景(如团战、载具等)进行了重点打磨与优化。
2019年4月GPU Turbo全新升级,不仅带来主流游戏接近满帧运行的酣畅体验,功耗的持续降低也带来了续航时间的提升。累计支持60款国内游戏。
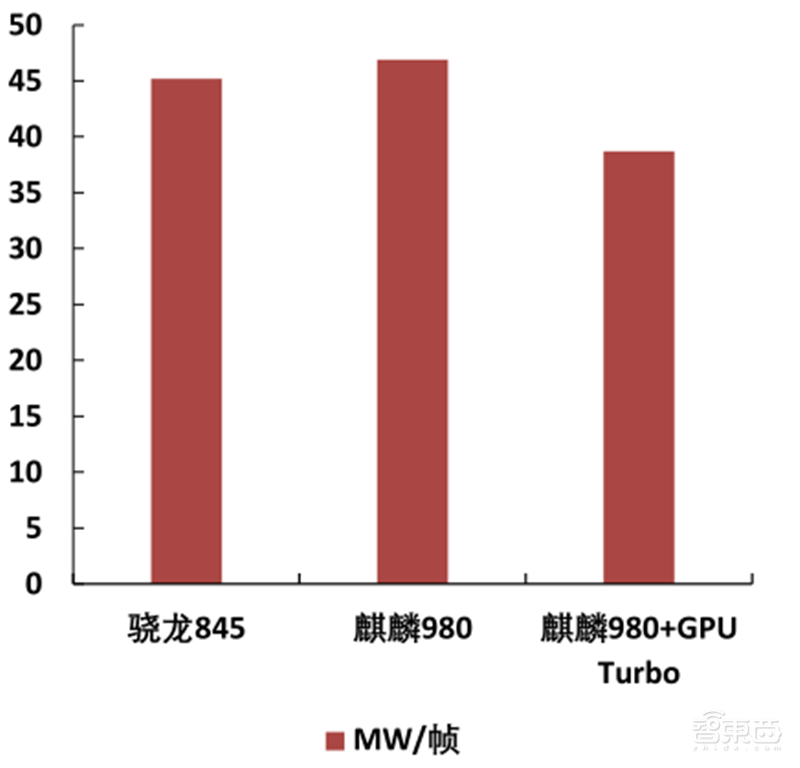
▲GPU Turbo 2.0能效对比
9、龙芯:GPU突击队
中科院计算所于2001年成立龙芯课题组,开始研制龙芯系列处理器,得到了中科院、863、973、核高基等项目大力支持,完成了十年的核心技术积累。2010年4月,中国科学院和北京市共同牵头出资入股,成立龙芯中科技术有限公司,龙芯正式从研发走向产业化。
目前,龙芯自主研发的GPU集成在7A1000桥片中。龙芯7A1000桥片是面向龙芯3号处理器的芯片组,通过HT3.0接口与处理器相连,集成GPU、显示控制器和独立显存接口,外围接口包括32路PCIE2.0、2路GMAC、3路SATA2.0、6路USB2.0和其它低速接口,可以满足桌面和服务器领域对IO接口的应用需求,并通过外接独立显卡的方式支持高性能图形应用需求。
虽然龙芯7A1000桥片的GPU性能一般,但是桥片作为CPU产业链的一环,龙芯已经实现CPU、桥片和GPU上完全自主化,打通了CPU产业链上每一个环节。
2020年,龙芯成立六支研发突击队,分别为3A5000突击队、3C5000突击队、7A2000突击队、2K2000突击队、GPU突击队、PCIE突击队。这六支突击队的目的就是要把2-3年的工作,在一年内干完!

▲龙芯7A1000
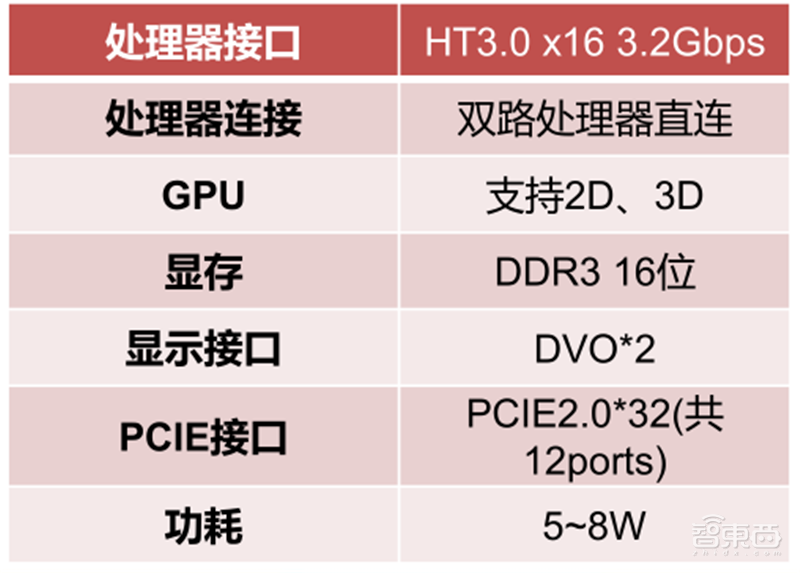
▲龙芯7A1000 GPU相关参数
10、芯瞳半导体:高性能GPU设计新星
芯瞳半导体成立于2019年,主要业务包括GPU芯片设计、异构计算平台方案、嵌入式显示系统解决方案、GPU应用部署解决方案。公司着力于研发高性能的GPU芯片,为用户提供以自研GPU芯片为核心的解决方案,致力于打造业界领先的GPU芯片设计平台,目标是成为国际一流的GPU芯片设计企业。公司创始团队在GPU领域有着超过10年的学术和工程经验,是一支软硬件全栈式支持的研发团队。
公司的GPU架构采用了业界主流的统一渲染架构,并具有高度可扩展的互联结构和计算阵列,便于芯片后续迭代升级。经过多年的积累,团队构建了芯片建模虚拟平台,通过该虚拟平台,团队可以快速地完成GPU相关软件的研发和软件生态的部署,与此同时,在该虚拟平台上快速地对芯片架构进行验证,从而缩短GPU芯片的设计验证周期,提升GPU芯片的设计效能。
公司第一代GPU芯片(GenBu01)初测已成功,已与统信、麒麟及昆仑完成适配,目前正在为小批量量产做最终测试。 GenBu01主要面向的客户为需要定制嵌入式计算机产品的客户以及为国产替代领域提供信创办公PC的ODM/OEM厂商。
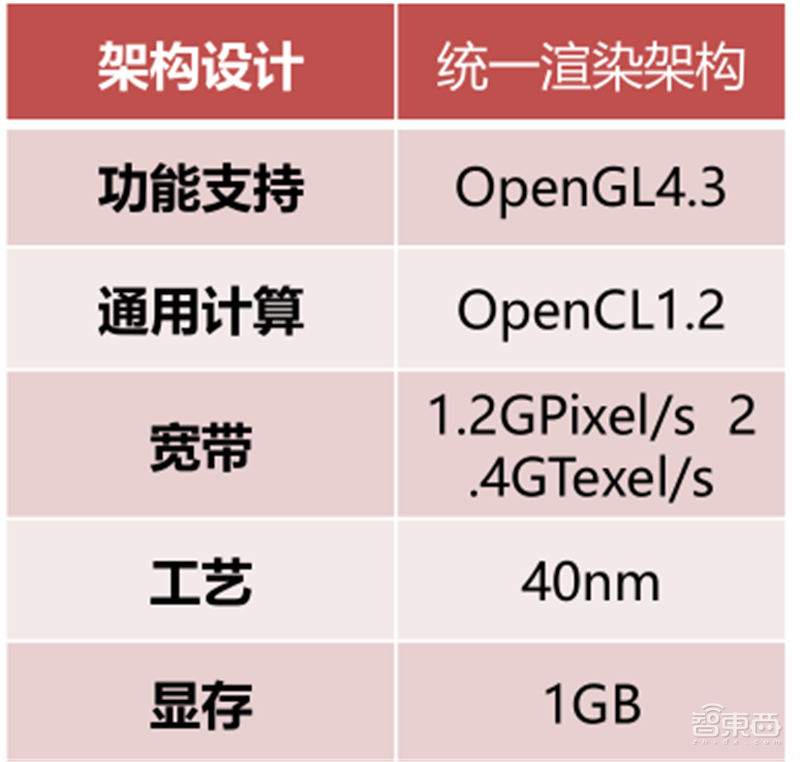
▲芯瞳GenBu01参数
11、天数智芯:国产GPGPU领跑者
天数智芯于2018年正式启动GPGPU芯片设计,是中国第一家GPGPU高端芯片及超级算力提供商。天数智芯重点打造自主可控、国际一流的通用、标准、高性能云端计算芯片GPGPU,从芯片端解决计算力问题;并推出面向5G技术需求的边缘云端推理GPGPU,提供对当前进口主流GPGPU体系的无缝兼容和市场化选择。2021年1月15日,天数智芯成功点亮自研7纳米制程GPGPU云端训练芯片,性能达市场主流产品的两倍。该芯片量产后将广泛应用于AI训练、高性能计算(HPC)等场景,服务于教育、互联网、金融、自动驾驶、医疗、安防等各相关行业,赋能AI智能社会。
天数智芯7纳米GPGPU高端自研云端训练芯片的产品优势包括:全方位生态兼容、高性能有效算力、指令集编程架构、软硬件全栈支持、全自主知识产权。
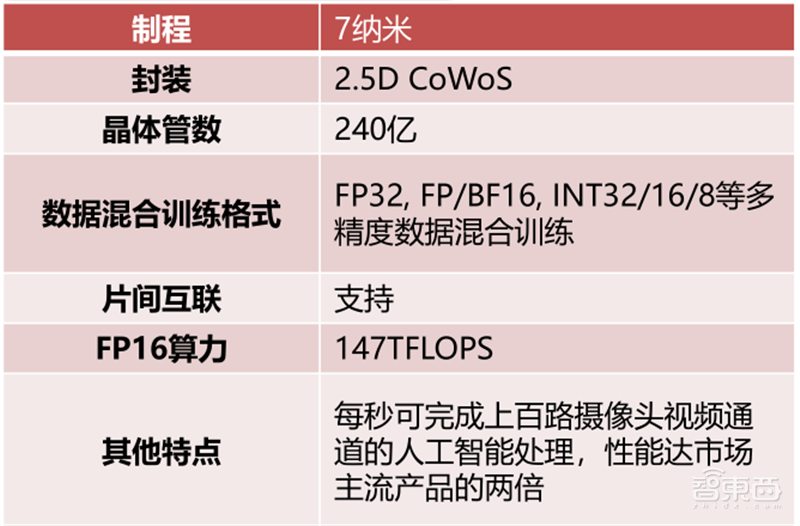
▲天数智芯GPGPU BI芯片参数
12、壁仞科技和沐曦集成电路
壁仞科技创立于2019年,团队由国内外芯片和云计算领域核心专业人员、研发人员组成,在GPU、DSA(专用加速器)和计算机体系结构等领域具有深厚的技术积累和独到的行业洞见。
壁仞科技致力于开发原创性的通用计算体系,建立高效的软硬件平台,同时在智能计算领域提供一体化的解决方案。从发展路径上,壁仞科技将首先聚焦云端通用智能计算,逐步在人工智能训练和推理、图形渲染、高性能通用计算等多个领域赶超现有解决方案,实现国产高端通用智能计算芯片的突破。
沐曦集成电路专注于设计具有完全自主知识产权,针对异构计算等各类应用的高性能通用GPU芯片。公司致力于打造国内最强商用GPU芯片,产品主要应用方向包含传统GPU及移动应用,人工智能、云计算、数据中心等高性能异构计算领域。
对于研发的方向,沐曦表示将采用业界最先进的5nm工艺技术,研发全兼容CUDA及ROCm生态的国产高性能GPU芯片,满足HPC、数据中心及AI等方面的计算需求。GPU将采用原创专利保护的可重构GPU架构,突破传统GPU芯片能效瓶颈;采用数据压缩,数据广播以及共享硬件加速单元等先进技术,大幅度优化核心算力能耗比。

▲沐曦高性能GPU研发项目
12、登临科技和摩尔线程
登临科技成立于2017年11月,是一家专注于为新兴计算领域提供高性能、高功效计算平台的高科技企业。公司的产品是以芯片为核心的系统解决方案,在所有核心IP上坚持自研路线。登临科技已完成由元禾璞华、元生资本联合领投的A+轮融资,包括北极光在内的老股东持续在本轮加码跟进。登临科技的首款GPU+(软件定义的片内异构通用人工智能处理器)产品已成功回片通过测试,开始客户送样,公司团队具备架构、系统、软件、硬件、芯片、验证等方面的综合能力。
登临科技GoldwasserTM GPU+产品在现有市场主流的GPU架构上,创新采用软硬件协同的异构设计。GPU+异构设计让产品在对客户实际业务继承在现有生态上的投入、在保证极高兼容性的同时,相比传统GPU在AI计算上性能和能效均有明显提升,大大降低了外部带宽的需求,显著降低客户总拥有成本。
摩尔线程创立于2020年10月,去年12月获得天使轮融资,今年2月22日获得Pre-A轮融资。摩尔线程致力于构建中国视觉计算和人工智能领域计算平台,研发全球领先的自主创新GPU知识产权,其GPU产品线覆盖通用图形计算和高性能计算。公司核心成员主要来自英伟达、微软、英特尔、AMD、ARM等,覆盖GPU研发设计、生产制造、市场销售、服务支持等完整架构。
13、国产GPU新星:翰博半导体
翰博半导体成立于2018年12月,立志于发展成为国际顶尖的芯片公司,立足于中国市场,填补国内市场国产芯片的空白,为智能应用提供高效算力,为人工智能创新以及应用落地赋能。
翰博半导体拥有国内外专家组成的团队。公司核心员工来自世界顶级的高科技公司,平均拥有15年以上的相关芯片,软件设计经验。
瀚博的产品注重计算机视觉及视频处理的优化,提供丰富的特性,高效的性能/功耗;适用多个人工智能领域。产品覆盖从边到云,SOC及服务器市场。
翰博半导体CEO—钱军拥有25年以上高端芯片设计经验和40多款芯片设计和量产的经验,带队设计量产业界第一颗7纳米图像处理器和AI服务器芯片,曾任AMD高管Senior Director,直接负责设计团队超过800人,全面负责GPU( 图像处理器和AI服务器)芯片设计和生产,现在市场上所有AMD Radeon图像处理器和AI服务器都是由其带队开发,包括多个系列DGPU和MI系列产品。
14、国产GPU新星:燧原科技
燧原科技成立于2018年3月,专注于人工智能领域云端算力平台,致力为人工智能产业发展提供普惠的基础设施解决方案,提供自主知识产权的高算力、高能效比、可编程的通用人工智能训练和推理产品。
燧原科技的产品技术由训练、推理、软件平台构成。其中,训练业务包含加速卡 “云燧T10” 和“云燧T11”;推理业务包含加速卡 “云燧i10”;软件平台包含“驭算”。
“云燧”系列加速卡采用自研DTU架构,支持ESL高速互联和开放生态。 “云燧”芯片采用格罗方德的12nm FinFET工艺,结合 2.5D先进封装,拥有141亿晶体管和16GB HBM2显存,在FP32的算力和能效比方面领先GPU。
计算及编程平台“驭算”,由燧原自主研发,支持主流深度学习框架,并针对邃思芯片进行了针对性优化。
智东西认为,GPU设计之初是为了图像处理,但是随着技术的不断迭代升级,GPU的功能已经不仅限于“画图”,凭借在并行处理和通用计算的优势,GPU在服务器、汽车、人工智能、边缘计算等领域已经开始大放异彩。现阶段,虽然国产GPU与英伟达、AMD等世界巨头差距明显,但在一些空白的细分领域或许有很大的“弯道超车”空间。
