








芯东西(ID:aichip001)
作者 | 心缘
编辑 | 漠影
芯东西4月19日报道,上周六,鲲云科技推出新一代的星空X9加速卡,峰值性能52.4TOPS,实测算力最高可达到英伟达T4的4.47倍。
该加速卡面向高性能AI服务器提供高性能、低延时、高算力性价比的人工智能(AI)计算加速解决方案,助力智算中心、云计算中心、高性能计算等典型场景的应用和建设。
目前,星空X9加速卡已完成量产,将于近期同浪潮完成产品适配,推出搭载星空X9加速卡的智算中心AI服务器。
 ▲鲲云创始人兼CEO牛昕宇博士展示星空X9加速卡
▲鲲云创始人兼CEO牛昕宇博士展示星空X9加速卡
一、AI芯片应能大幅降低AI应用的落地成本
在发布鲲云X9加速卡的现场,鲲云科技创始人兼CEO牛昕宇分享道,AI芯片的价值应是能大幅降低智慧城市、自动驾驶、智能工业等各类AI应用落地的成本。
他举了一个简单的例子,如果想做一个智慧世博园的项目,要通过25000路录像的输入,实现人脸门禁、研究统计、垃圾管理各种智慧化功能,都需要通过服务器、计算来提供算力。
假设现在这台服务器基于最先进的国际巨头产品,一台服务器可以支持250路视频的分析,部署整个智慧世博园的项目,则需100台服务器来支持这25000路摄像头的分析,这100台服务器就是整个人工智能应用落地的刚性服务。
而现在,有这样一颗产品,相比于现有服务器产品,它可以在成本不变的情况下,将性能提升4.47倍,从以前250路一台服务器分析的能力变成超过1000路的视频分析能力。落地同样的应用、实现同样的功能,现在只需22台服务器,即成本降低了接近80%,实现的功能几近相同。
星空X9加速卡即是这样一款加速卡。
二、搭载4颗CAISA芯片,芯片利用率最高提升11.05倍
星空X9加速卡搭载4颗CAISA芯片,全高全长,采用无风扇的被动散热设计,内置32GB内存。
 ▲星空X9加速卡产品规格
▲星空X9加速卡产品规格
CAISA芯片为鲲云科技去年6月发布的全球首款定制数据流AI芯片,较同类产品在芯片利用率上有较大的技术突破,最高提升11.05倍,在实际应用中可以提供更高的有效算力。
据介绍,最新的实测数据显示,X9加速卡仅用不到1/2的峰值算力,可实现英伟达T4最高4.47倍的实测性能提升,其算力性价比、芯片利用率、实测性能和处理延时等指标均实现业界领先。
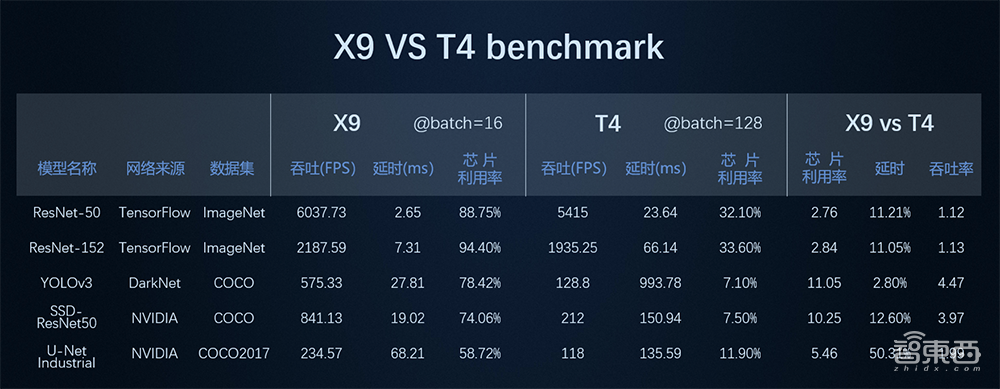 ▲X9 vs T4 benchmark
▲X9 vs T4 benchmark
相比英伟达旗舰推理卡T4,星空X9加速卡在运行ResNet50, YOLO v3等算法模型时的芯片利用率提升了2.76-11.05倍,最高可以实现94.4%的芯片利用率。
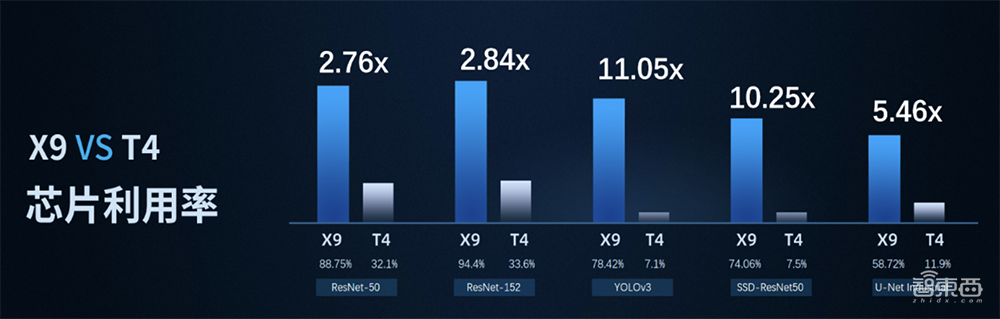 ▲X9 vs T4芯片利用率
▲X9 vs T4芯片利用率
在性能方面,X9在运行ResNet50网络时性能可以达到6037.73FPS,相较T4性能提升1.12倍,运行YOLO v3、U-Net Industrial检测分割网络性能有1.99-4.47倍提升。
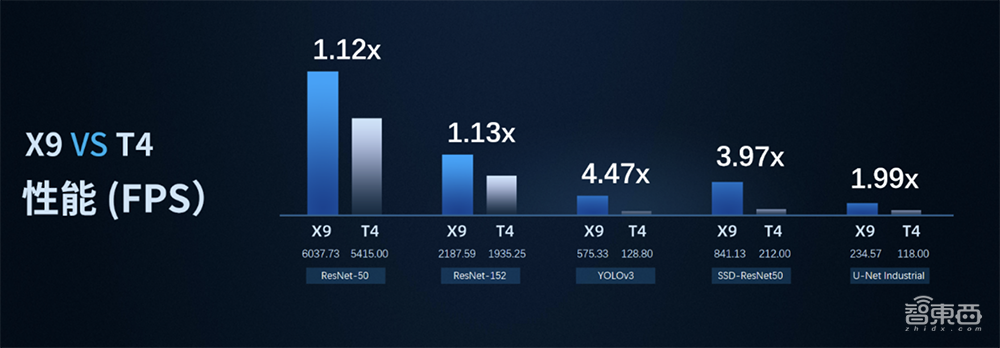 ▲X9 vs T4 性能(FPS)
▲X9 vs T4 性能(FPS)
在达到最优性能时,X9处理延时最低可达到2.65ms,处理速度相比T4提升35.73倍,适用于智算中心、云计算中心、高性能计算等对低延时有要求的高性能AI计算加速场景。
 ▲X9 vs T4 延时(ms)
▲X9 vs T4 延时(ms)
鲲云科技还在现场展出了星空X3加速卡、星空X6A智能小站等AI硬件产品及智慧油田、智能安监、智能电网、智能制造等行业解决方案。
三、实现数据流AI芯片的三个挑战
牛昕宇说,芯片实测性能与两个指标有关,一是峰值算力,二是芯片利用率。峰值算力并不代表实测性能,还要乘以一个衡量多少性能被用户实际用到的系数,即芯片利用率。
之所以星空X9加速卡能实现较高的实测性能提升,得益于其自研数据流AI芯片CAISA3.0。
CAISA3.0芯片基于底层的数据流技术路线,整个架构中没有任何指令。不同于传统的冯·诺依曼体系,数据流架构依靠数据的流动次序来控制计算次序,简单可理解成数据搬运和计算是重叠的。
在这样一个重叠的计算方式下,鲲云可以最大化发挥出每时每刻每个时钟周期的性能,把这颗芯片极限的100%的物理性能逼出来。
 ▲鲲云创始人兼CEO牛昕宇博士展示CAISA芯片
▲鲲云创始人兼CEO牛昕宇博士展示CAISA芯片
据牛昕宇分享,要实现这样一颗芯片,主要有三个挑战:
第一,保证每一个时钟周期都用来做计算,而且每个时钟周期的数据搬运和计算的次序是准确的,确保整个架构的通用性能够支持各种各样的算法,并能保持软件的易用性。
用时钟精确的计算,来保证在每个周期计算和传输是像齿轮一样紧紧耦合的,所以既能保证每个周期性能,又能提升它计算的准确率。
第二,架构上,通过动态的数据重组,针对不同的算法,形成不同的定制化流水线,这样针对人工智能的每个算法性能会很高,而且针是一个通用化的计算平台。
第三,它可以端到端地将不同的算法部署在上面,实现整个软件的易用性和可部署。
而鲲云CAISA3.0芯片的芯片利用率可达95.4%,在同样的测试环境下,对标国际巨头的产品有3-6倍的实际性能提升。
结语:走底层架构技术创新的路线
牛昕宇提到,AI芯片有两条路,一条是跟随已有的国际巨头;另一条是走出一条全新的底层架构的技术创新路线。“鲲云一直走得是底层架构技术创新的路线,这可以给我们带来架构上的优势,从而在峰值算力更低的成本下,实现更高的性能。”
星空X9加速卡的发布,是鲲云在这条道路上的进一步前行,据悉该加速卡已在智能制造、工业安监、自动驾驶等领域实现了落地。接下来,鲲云还将与更多的合作伙伴合作,以性能更高、成本更低、更好用的下一代AI计算平台,与更多合作伙伴一起支持各类人工智能应用的落地。
