








智东西(公众号:zhidxcom)
编辑 | 心缘
智东西4月19日报道,今日,阿里巴巴达摩院发布中文社区最大规模预训练语言模型PLUG,其参数规模达270亿。接下来,PLUG将扩大参数规模至2000亿级,并进一步提升文本生成质量。
与PLUG发布同步,达摩院宣布近期将开源阿里巴巴深度语言模型体系大部分重要模型。
PLUG全名为Pre-training for Language Understanding and Generation,集语言理解与生成能力于一身,在小说创作、诗歌生成、智能问答等长文本生成领域表现突出。
该语言模型的目标是通过超大模型的能力,大幅提升中文NLP各类任务的表现,取得超越人类表现的性能。
发布后,PLUG刷新了中文语言理解评测基准CLUE分类榜单历史纪录。
自去年OpenAI发布超大规模预训练语言模型GPT-3引发全球热议后,中文领域同类模型的训练进程备受关注。
与GPT-3类似,阿里达摩院本次发布的PLUG有望广泛应用于文本生成领域,成为“万能写作神器”。
更重要的是,此类超大模型拥有极强的通用性,被认为或将成为AI时代的新型基础设施之一。
相较GPT-3的改进之处在于,PLUG设计了一个简洁的模型框架,集成了达摩院自研的语言理解及语言生成双模型,并通过构建输入文本双向理解能力,显著提升了输出文本的相关性。
在语言理解任务上,PLUG以80.614分刷新了CLUE分类榜单纪录;在语言生成任务上,PLUG多项应用数据较业内最优水平提升了8%以上。
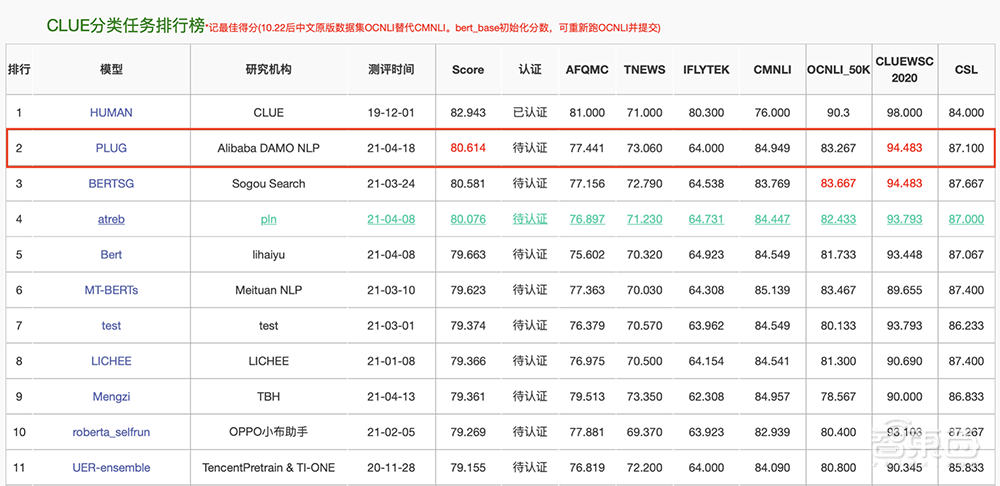 ▲4月19日,PLUG刷新CLUE分类榜单纪录,排名仅次于“人类”
▲4月19日,PLUG刷新CLUE分类榜单纪录,排名仅次于“人类”
据悉,PLUG采用了1TB以上高质量中文文本训练数据,涵盖新闻、小说、诗歌、问答等广泛类型及领域,其模型训练依托了阿里云EFLOPS高性能AI计算集群。
在超大规模预训练模型领域,除发布以中文为核心的PLUG外,阿里达摩院、阿里云计算平台团队还联合智源研究院、清华大学发布了面向认知的超大规模新型预训练模型“文汇”,以及联合清华大学发布了超大规模多模态预训练模型“M6”。
阿里达摩院语言技术实验室负责人司罗称:“达摩院NLP团队将进一步攻克自然语言处理领域科研难题,完善中文及跨语言人工智能基础设施,让AI没有难懂的语言,并探索通用人工智能之路。”

