








芯东西(ID:aichip001)
作者 | 心缘
编辑 | 漠影
芯东西4月22日报道,NVIDIA面向企业级服务器最新推出的A30和A10 GPU两大数据中心推理新品,今日完成性能首秀,并创下推理新纪录。
在业界公认的AI性能衡量基准——MLPerf基准测试中,NVIDIA GPU在所有类别刷新记录。

绝大多数参与数据中心及边缘推理测试的系统均采用NVIDIA GPU作为AI加速器,少数则采用高通、赛灵思、Neuchips、Centaur、Arm等其他芯片商的加速器。
NVIDIA的两款新GPU集高性能与低功耗于一身,可成为企业在AI推理、训练、图形和传统企业级计算工作负载等诸多方面的主流选择。思科、戴尔科技、慧与、浪潮和联想预计会从今年夏季开始将这两款GPU集成到其最高容量的服务器中。
链接:https://mlcommons.org/en/inference-datacenter-10/
一、NVIDIA在六类算法测试均刷新纪录
MLPerf基准测试由图灵奖得主David Patterson联合科技公司和全球顶级高校于2018年发起,是业界首套衡量机器学习软硬件性能的通用基准,能展示不同CPU、GPU、加速器组合做展示出的不同性能表现,如今MLPerf已成为业界评测AI性能的最主流标准之一。
“随着AI持续为各行各业带来变革,MLPerf也成为企业的一项重要工具,能够助力其在IT基础设施投资方面做出明智的决策。”NVIDIA加速计算部门总经理兼副总裁Ian Buck说,“如今,所有主要OEM厂商都提交了MLPerf测试结果。”
除NVIDIA公司提交的测试结果外,阿里云、戴尔科技、富士通、技嘉科技、慧与、浪潮、联想和超微等多家NVIDIA合作伙伴也提交了共360多项基于NVIDIA GPU的测试结果。
最新公布的测试结果显示,NVIDIA是唯一一家针对数据中心和边缘类别中的每项测试都提交结果的公司,并在所有MLPerf工作负载中均展现出领先的性能。
例如,在数据中心基准测试中,NVIDIA A100的性能表现相较CPU提高17-314倍,最新发布的A10和A30也展现出不错的测试结果。
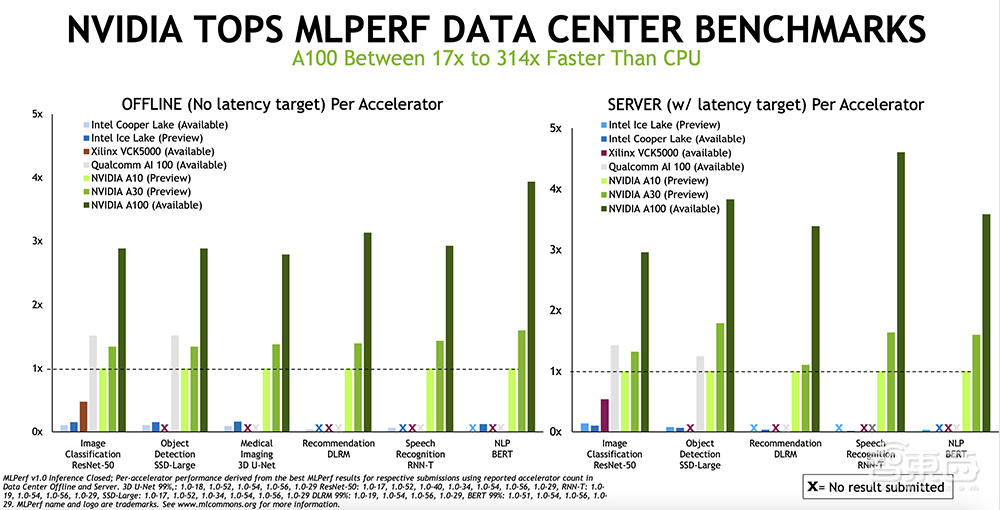
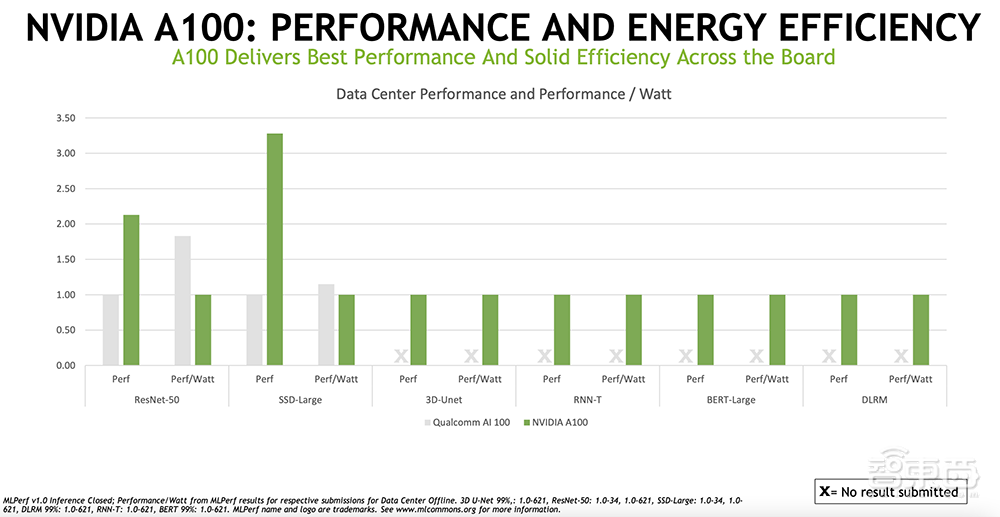
相比高通Cloud AI 100,NVIDIA A100在ResNet-50和SSD-Large算法中均展现出更高的性能。
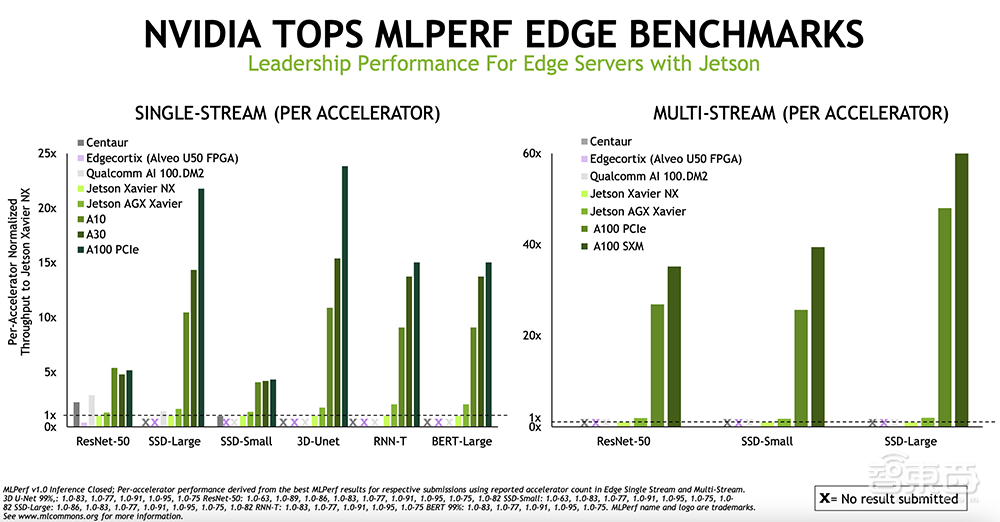
NVIDIA A100、Jetson系列在边缘基准测试中展示了全部六类算法测试的结果。
此外,NVIDIA还开创性地使用NVIDIA Ampere架构的多实例GPU性能,在单一GPU上使用7个MIG实例,同时运行所有7项MLPerf离线测试。该配置实现了与单一MIG实例独立运行几乎相同(98%)的性能。
这些提交结果展示了MIG的性能和通用性。基础设施经理可以针对特定应用,配置适当数量的GPU计算,从而让每个数据中心GPU都能发挥最大的效用。
多项提交结果还基于NVIDIA Triton推理服务器。该推理服务器支持来自所有主要框架的模型,可在GPU及CPU上运行,并针对批处理、实时和串流传输等不同的查询类型进行了优化,能简化在应用中部署AI的复杂性,同时保证领先的性能。
在配置相当的情况下,采用Triton的提交结果所达到的性能接近于最优化的GPU实现及CPU实现能够达到的性能。
二、A30和A10今夏商用
NVIDIA能够取得如此佳绩,得益于NVIDIA AI平台的广度。
该AI平台包含多种类型的GPU以及经优化后能实现AI加速的全栈NVIDIA软件,包括TensorRT和NVIDIA Triton推理服务器。微软、Pinterest、Postmates、T-Mobile、USPS、微信等企业都部署了NVIDIA AI平台。
A30和A10 GPU是NVIDIA AI平台中的最新成员。

A30能够为行业标准服务器提供通用的性能,支持广泛的AI推理和主流企业级计算工作负载,如推荐系统、对话式AI和计算机视觉。
A10可加速深度学习推理、交互式渲染、计算机辅助设计和云游戏,使企业能够基于通用基础设施,为混合型AI和图形工作负载提供支持。通过采用NVIDIA虚拟GPU软件,可改进管理,为设计师、工程师、艺术家和科学家所用的虚拟桌面提高利用率并完善配置。
NVIDIA Jetson平台基于NVIDIA Xavier系统级模块,可在边缘提供服务器级的AI性能,助力机器人、医疗健康、零售等领域实现更多的创新应用。Jetson基于NVIDIA的统一架构和CUDA-X软件堆栈,是唯一采用紧凑型设计、能够运行所有边缘工作负载且功耗低于30W的平台。
过去6个月,NVIDIA端到端AI平台在MLPerf的性能提升达45%。
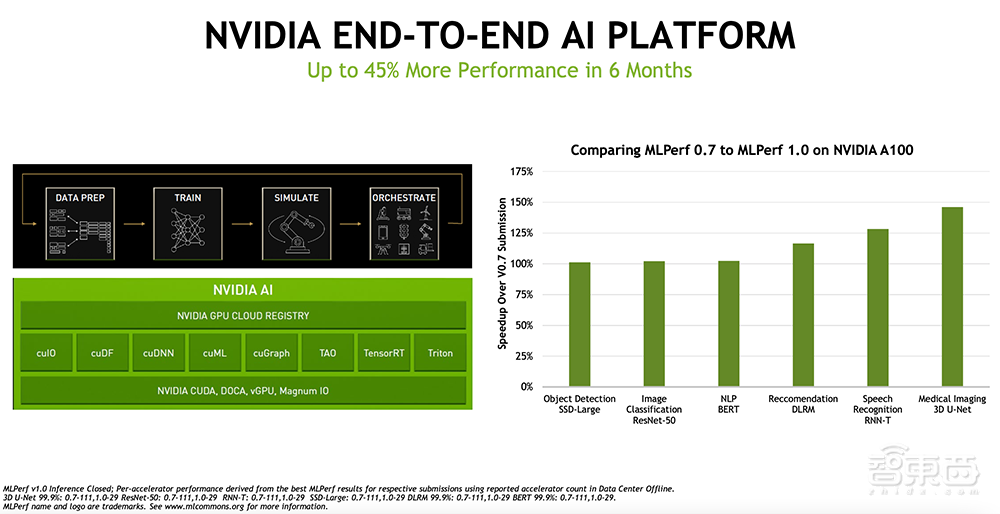
NVIDIA A100 GPU搭载于领先服务器制造商的服务器、所有主要云服务提供商的云端,以及NVIDIA DGX系统产品组合(包括NVIDIA DGX Station A100、NVIDIA DGX A100和NVIDIA DGX SuperPOD)。
A30和A10(功耗分别为165W和150W)预计将从今夏起用于各类服务器中,包括经严格测试以确保在各类工作负载下均可实现高性能的NVIDIA认证系统。
NVIDIA Jetson AGX Xavier和Jetson Xavier NX系统级模块已通过全球经销商供货。
NVIDIA Triton和NVIDIA TensorRT均可通过NVIDIA的软件目录NGC获取。
结语:MLPerf参与者集中于芯片大厂
总体来看,参与MLPerf基准测试的AI加速器主要来自NVIDIA、高通、赛灵思等芯片巨头,尤其是NVIDIA GPU几乎刷屏数据中心及边缘的加速器一列,相对而言,我们鲜少看见AI硬件初创公司的身影。
NVIDIA加速计算部门总经理兼副总裁Ian Buck说:“NVIDIA及合作伙伴的关注点不仅在于实现全球领先的AI性能,同时还注重通过即将面市的一系列搭载A30和A10 GPU的企业级服务器来实现AI普及化。”
