








智东西(公众号:zhidxcom)
编辑 | 孙悦
智东西6月5日消息,近日GTIC 2021嵌入式AI创新峰会在北京圆满收官!在这场全天座无虚席、全网直播观看人数逾150万次的高规格产业峰会上,来自产业链上下游的16位大佬共聚一堂,围绕嵌入式AI的软硬件生态创新、家居AIoT、移动机器人和工业制造产业4大版块地图,带来了深入浅出的分享。
会上,商汤科技副总裁、通用智能技术负责人闫俊杰博士发表了《极致灵活的深度学习模型优化与部署》的主题演讲。

▲商汤科技副总裁、研究院副院⻓、通⽤智能负责⼈闫俊杰
商汤推出Spring.NART模型部署框架,支持代码级别、算子级别及网络级别等不同的接入级别,以通过统一的接入框架适配多种深度学习芯片。据称,该框架支持16类不同硬件设备,能保证算法方案灵活跑在各类设备上。
同时,商汤通过编译优化技术及一套量化模型生产工具,使模型在Arm框架和英伟达GPU上都能实现低bit量化;同时,除了系统层面的优化,商汤今年还提出了媲美在线量化的离线量化算法BRECQ,首次将4bit离线量化的效果做到接近量化训练,以此实现高效的模型自动化部署。
另外,在软硬件协同方面,商汤兼顾结构、推理库和硬件,建立了一个计算数据库Spring.GPDB(Graph Performance DataBase),基于这一软硬件协同的数据库对已有模型做诊断并改进,使模型得到较好的精度和速度提升。
总的来说,针对硬件多样化、模型压缩、模型自动化部署三大挑战,商汤试图让深度学习模型在嵌入式设备上灵活优化和部署。
以下为闫俊杰演讲实录整理:
大家好,非常高兴有机会跟大家分享过去几年我们在深度学习模型的优化和部署上做的工作。首先我们给一个定义:深度学习模型生产的流水线。首先从数据经过训练系统,得到一个设备无关的模型,这个模型只包含一些参数和网络结构。接下来需要通过部署系统和硬件做一些适配,得到设备绑定的模型。最后加上深度学习算法之外的串联,就可以得到在各种不同设备如服务器、边缘设备、AIoT设备上来使用的完整解决方案。
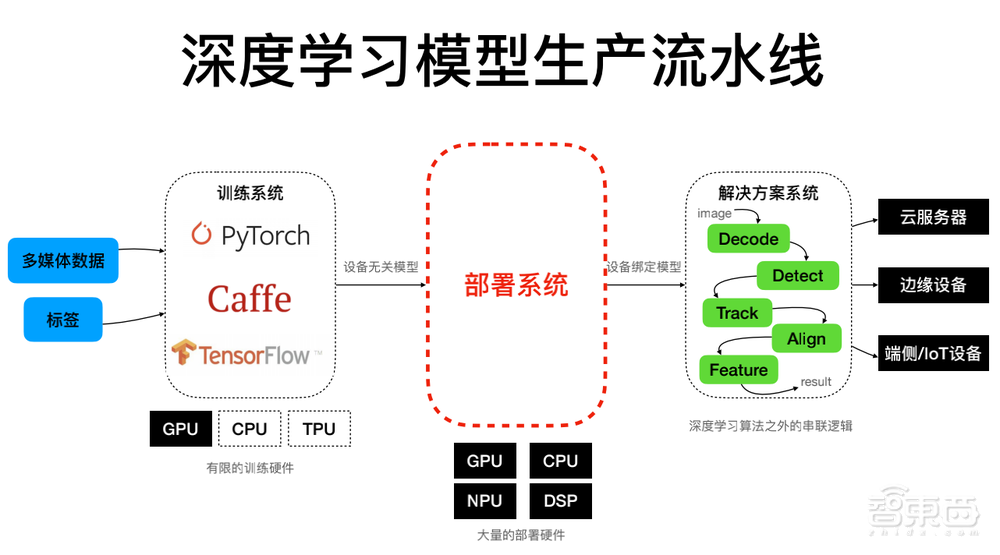
一、深度学习模型的三大挑战:设备、性能、自动化能力
这里的假设是我们得到了一个模型,这个模型可能用在各种各样的设备上,包含任意的芯片。我们需要有一套好的方案,让这个模型非常灵活地部署在任意的芯片上,同时还要有较高的部署效率。那这里面有哪些挑战?经过过去几年的实践,我们总结主要有三点。
(1)支持多款硬件设备。商汤科技从2017年开始,首次把深度学习的人脸检测放到相机上。当时芯片比较少,边缘上只有Arm可以用,没有NPU。随着近几年的发展,在边缘设备上可用的芯片越来越多,同时也出现了另一个问题:怎么让同一模型能够灵活地配适于任意的设备上?这是我们需要解决的第一个挑战。
(2)其次是高效能。这一点在边缘设备上尤其明显,边缘设备的功耗很低,计算能力没有那么高。怎么能在边缘设备上发挥极致的性能?这就需要进一步进行量化或者稀疏的工作。
(3)最后是自动化。如果只需要部署一个模型,这没有什么挑战,实在不行手工来调就好了。但是在工业化的时代,比如像商汤这样的公司每天需要产出几百个模型,显然不可能全部靠人来手工部署,我们需要有一套自动化的系统。而这套自动化系统需要能够处理各种hard case和corner case,因此面临很多新的挑战。
首先给大家介绍我们怎么解决多设备的问题?假如设备可控,基于代码生成的方案是最简单的,比如TVM,类似这样的技术提供了非常灵活的框架。现在大部分能用的芯片一般都会提供网络编译器,但是网络编译器只提供网络级别的支持,不会提供到指令级别的支持。除了Arm或者英伟达非常成熟的硬件能够提供指令级,大部分国产化芯片属于网络级别的编译器,完全基于代码生成的方案在实际中对大多数芯片很难走得通。
商汤主要使用的是其他厂商的芯片,过去几年我们适配了近20种芯片,可以发现不同芯片所提供的接入级别非常不一样。有代码级别,比如Arm、X86、cuda;还有算子级别,比如cuDNN计算库;还有提供网络级别的芯片,比如TensorRT、华为的一些芯片等。我们需要一套系统能够灵活接入代码级别、网络级别、算子级别,只有这样才能实现统一的自由框架。

这套系统在我们内部命名为NART,其全称是Nart is Not A Runtime。NART主要包含两部分:一部分是编译器、一部分是运行时。它主要有如下特点:第一点:多算子级别。代码、算子、网络都可以是一个算子。第二点:编译器和运行时解藕。运行时主要是包含大量已实现好的算子,现在已经有上百种算子。编译器部分主要是处理一些量化校准、图优化和格式转换相关的问题。第三点:混合运行时。这一点在工业级使用中非常重要,一方面可以将NPU上不支持的算子灵活回退到次级设备。比如在华为海思的处理器上,NNIE不能支持的算子可以直接回退到Arm上处理,实现非常灵活的接入,不需要等着芯片厂商的排期。并且在实操过程中,我们发现这样的处理方式既简单又高效,同时整个生产周期也非常快。另一方面混合运行时便于实现混合精度,在不同精度的算子间自动切换,保证模型的效果。
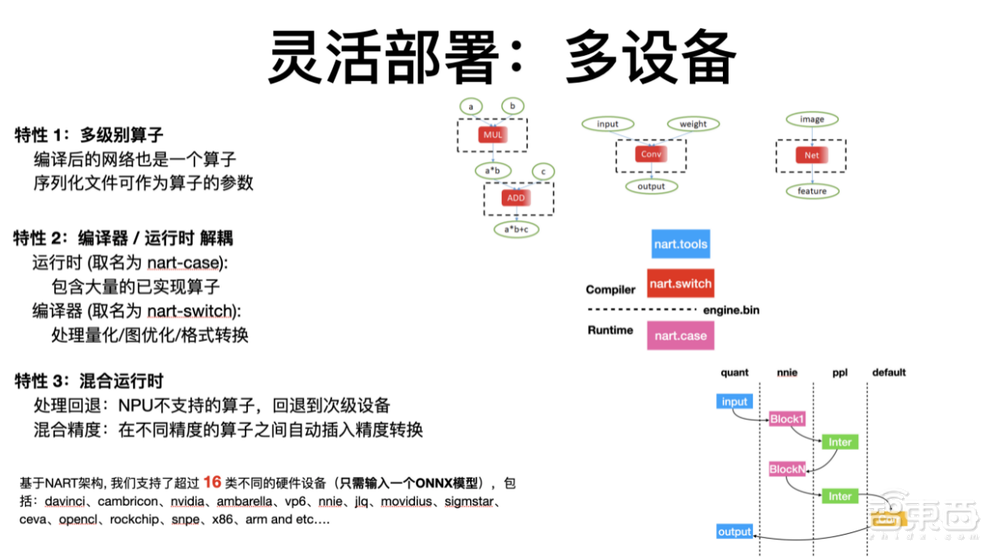
现在我们已经支持了超过16类不同的硬件设备,大家看到的市场上主流的硬件都使用这一套框架来支持。这保证了商汤的算法方案可以灵活的跑在任意一个市场上已有的设备上。
二、实现低bit量化,提高自动化部署效率
模型量化,是一种比较高效的处理方法,与之对应的还有其他的如网络结构优化等方案。量化属于最常用的技术,这里重点分享一下我们在量化上做的工作,主要是为了达到极致的效率。
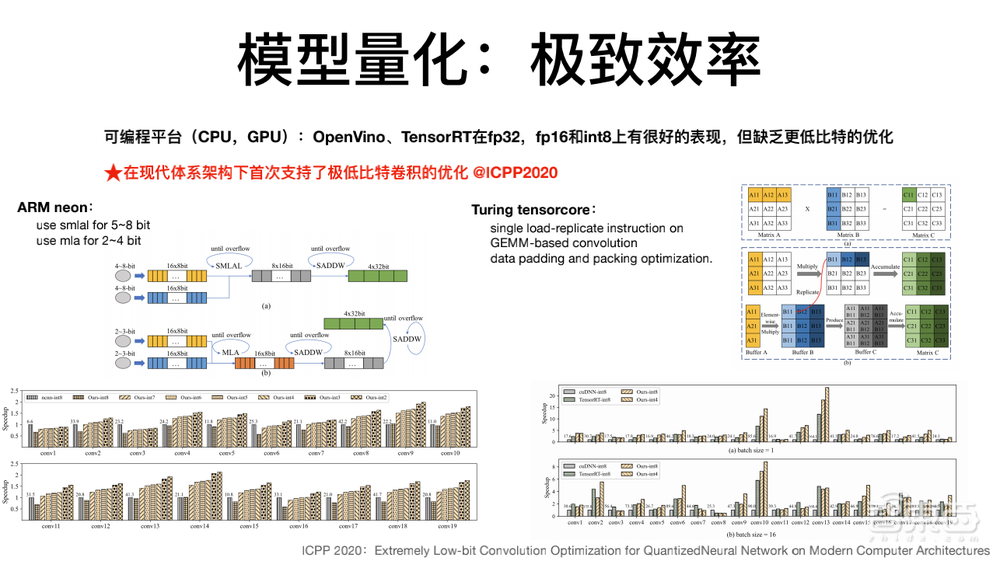
现在INT8的量化很常用,在绝大多数芯片上都支持,效率确实有所提升。但问题是随着算法的进展,它可以做到比8bit更低的4bit,但是却很少能支持8bit以下的计算方案。
为了解决这个问题,我们做了很多研究,在现代体系结构下首次实现极低比特量化,并且能够带来很好的效率提升。
简单来说我们实现了2个平台的极低比特模型部署,一个在Arm上,一个在GPU上。在Arm上使用5-8bit或1-4bit卷积都是可以的。通过对比ResNet18中各层的性能,可以发现大部分层的提升都是非常明显的。在英伟达的GPU上,也针对tensorecore实现了超低比特的优化。从右下角的图表可以看出,在batch=1的情况下对于大型网络提速非常明显。
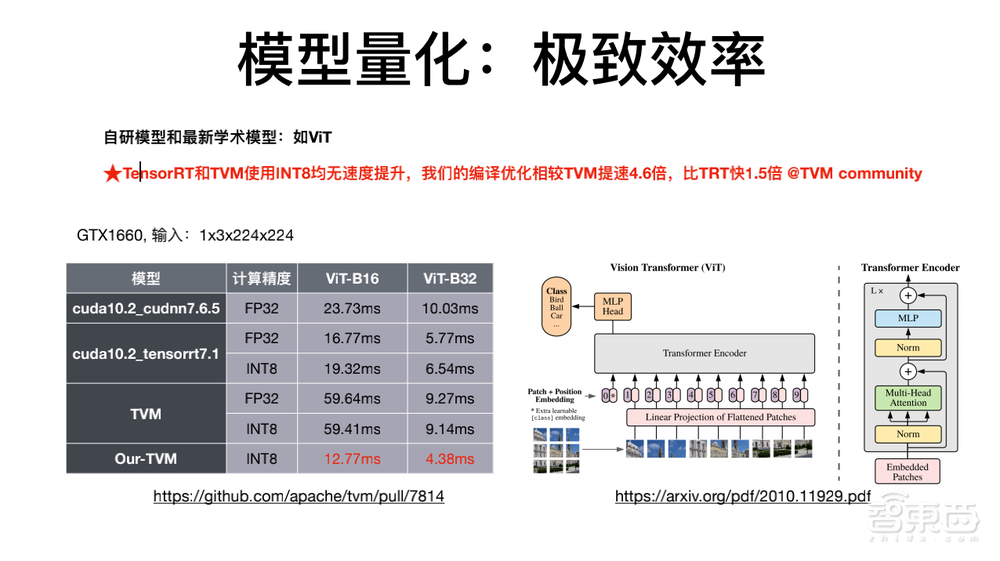
在量化这块我们还观察到一个状态,现在很多厂商会提供一些标准的库比如英伟达的TensorRT。但问题是对于很多新的模型,他们提速不明显,更新会比较慢。举个例子,最近在计算机视觉领域非常火的ViT(Visual Transformer)。我们发现,对于ViT现有的方案比如TensorRT/TVM,使用8bit不会有效率的提升。而我们通过编译优化,在ViT上实现了相比TVM快4.6倍,相比TRT快1.5倍的速度提升。关于这一块我们做了一些社区贡献,相关的提交已经被社区合并。
将量化做到工业化,不光需要使速度达到极致,而且需要有一套生产工具。
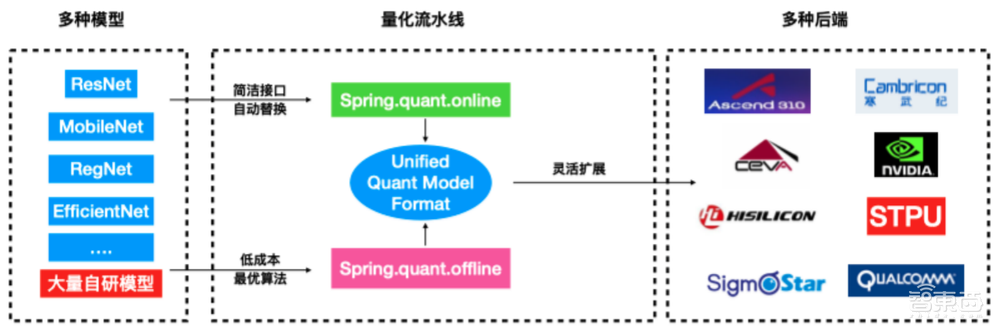
因为每天处理的问题实在太多了,为了满足工业级的量化需求,我们实现了一套统一的生产工具,它的输入是不同类型的模型,包括学术界大家都知道的网络如ResNet,还有大量商汤自研的网络结构。
基于此,我们有两种量化选择,一种是在线量化,需要一些训练进行Finetune,这种情况要求接口尽可能的简单;第二种是离线量化,不能重新训练,但是可以基于已有数据做出调整,针对这种情况需要低成本,性能尽可能好。针对这两种选择,我们提供了统一量化的接口,并把它适配到不同的芯片上,因为不同芯片的量化方案是不一样的,因此需要适应各种后端,这是量化部分的整体设计。
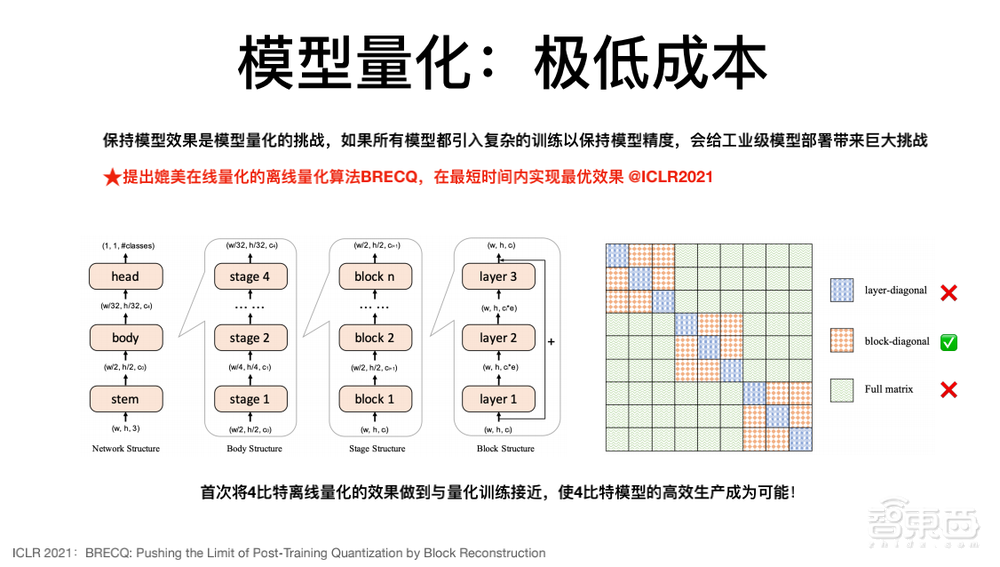
除了系统层面优化之外,我们今年在ICLR上提出了BRECQ算法,这个算法是我们目前已知的第一个能够实现媲美在线量化精度效果的离线量化算法;算法的原理也比较简单,之前大家优化一层,我们扩展到了一个块。
通过很多实验和理论,我们证明了块是一个更好的粒度。同时除了确定量化参数,也可以对权重进行微调,因此通过块的设置和更好的权重调整,实现更优效果。这个算法在内部走通之后经过了大量验证,证明了离线量化可以很好的保证精度。这是我们认为比较有用的一个算法,因此给大家进行一个简单的介绍。
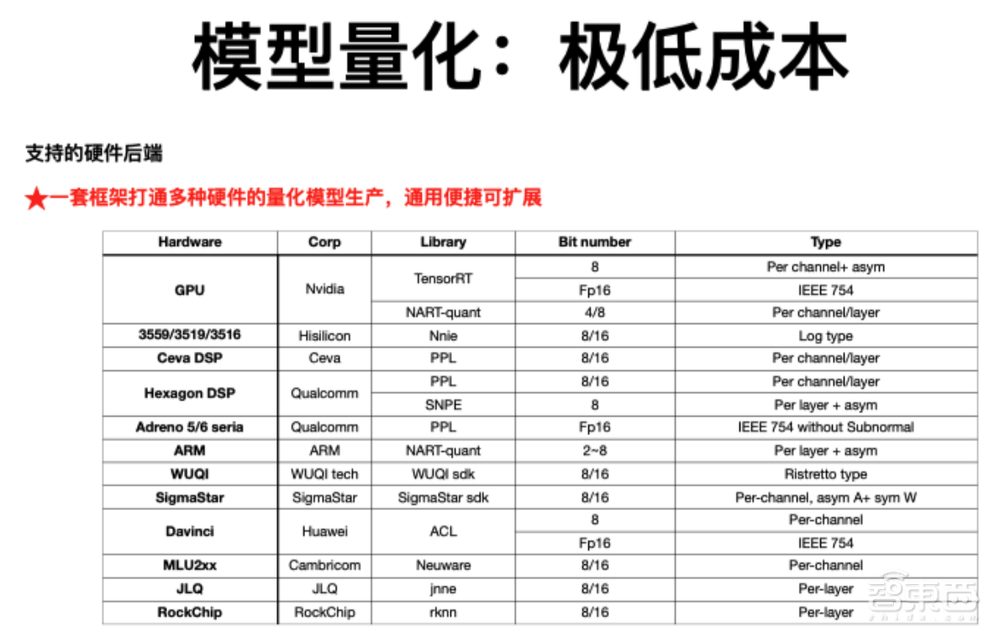
此外,各家厂商的硬件采用了非常不同的量化方案。包括gpu的、dsp的、arm的以及一些国产化芯片。这对算法提出了很大挑战,但是通过我们在算法上的、系统上的、架构设计上的工作,可以很好的以一套框架打通多种硬件的量化模型生产。
三、兼顾结构、推理库和硬件,完善软硬件协同
最后再给大家介绍一下我们过去几年实践总结出来的经验:做软硬件的协同。
但是这个软硬件协同不是设计芯片时需要考虑算法,我们认为的软硬件协同主要从以下三个方面考虑:我们内部支撑各种各样的芯片,大量的推理库,还有非常多网络结构。我们结合结构、推理库还有硬件,这三方面建立一个庞大的数据库,分析三者之间的关系。
基于这样的数据库,我们能够方便、快速地找到在一个特定的硬件上最优的网络结构是什么样的;或者说在一个特定的硬件上,针对一个推理库,最优的结构应该怎么设计?这些都对我们的实际模型生产,带来非常多的帮助。
这个事情具体怎么来做?
首先对不同的硬件定义了三个层级:L1、L2、L3。
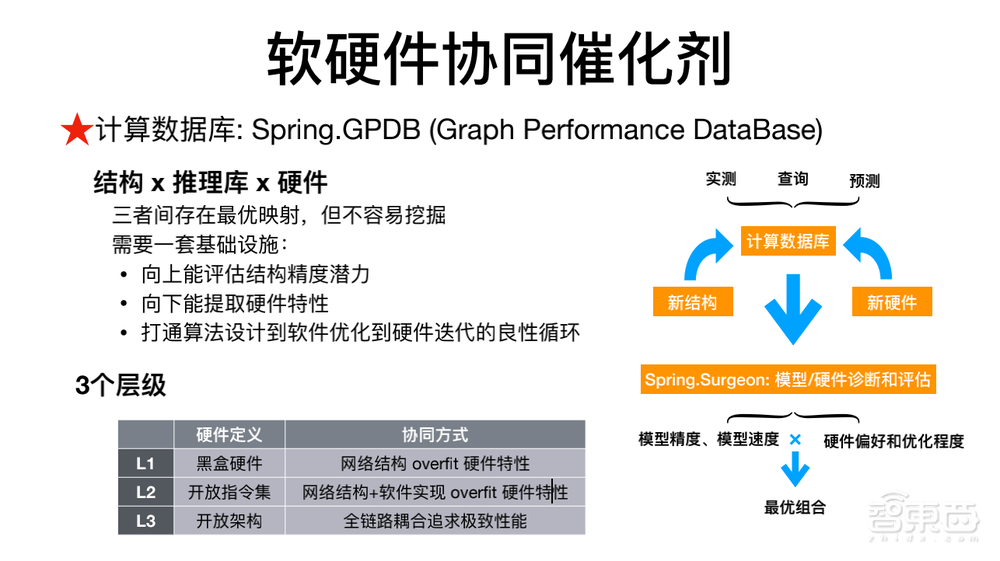
L1指的是黑盒硬件,我们需要网络结构能够来overfit硬件特性,针对黑盒硬件找到最好的网络硬件。
L2指的是开放式指令集,芯片的指令集是开放的,因此可以用网络结构+软件实现来overfit具体硬件。
L3指的是整个硬件的架构完全开放,针对这样一种设置可以做全链路耦合的方式,从结构、推理、硬件一起推动。商汤作为一家算法为核心的公司,我们同时支持三种层级的软硬件协同优化。
经过商汤历史上训练的超过20万个模型,累计有10万个不同的网络结构,同时也支持11种不同的硬件。我们基于这些信息建了一个数据库。有了这个数据库之后,针对一个新的网络结构可以快速地通过实测查询或者算法预测的方式,得到非常高效的计算数据库。
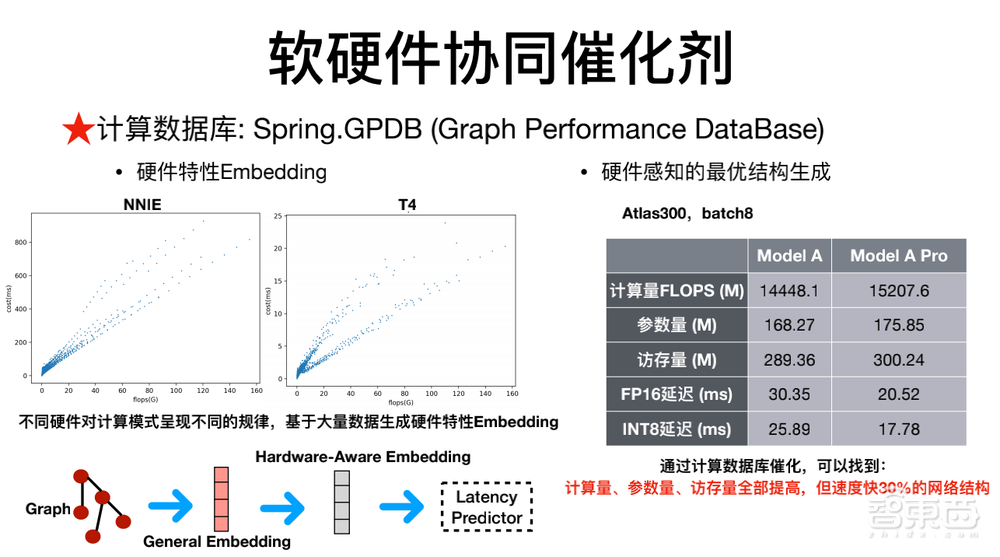
基于这样的数据库,我们可以针对已经训练好的模型帮它做各种诊断,使它推导出来的模型综合考虑到精度、速度、硬件偏好和选择程度等因素后得到最优的组合。这样一个组合在实际生产中,它的精度将会有很大提升。
比如ModelA和Model Pro,ModelA是靠研究员手工设计的结构,它的Flops、参数量、访存量如图,通过软硬件协同的数据库优化,可以推导出ModelA Pro,它的Flops、参数量、访存量都比ModelA大,但速度比ModelA要小。之前网络设计是依赖于人的经验,现在变成依赖于数据库和算法,通过数据库和算法帮助研究员设计出更好的网络结构。当我们训练出的模型到了十万量级以后,它能带来非常好的提升。
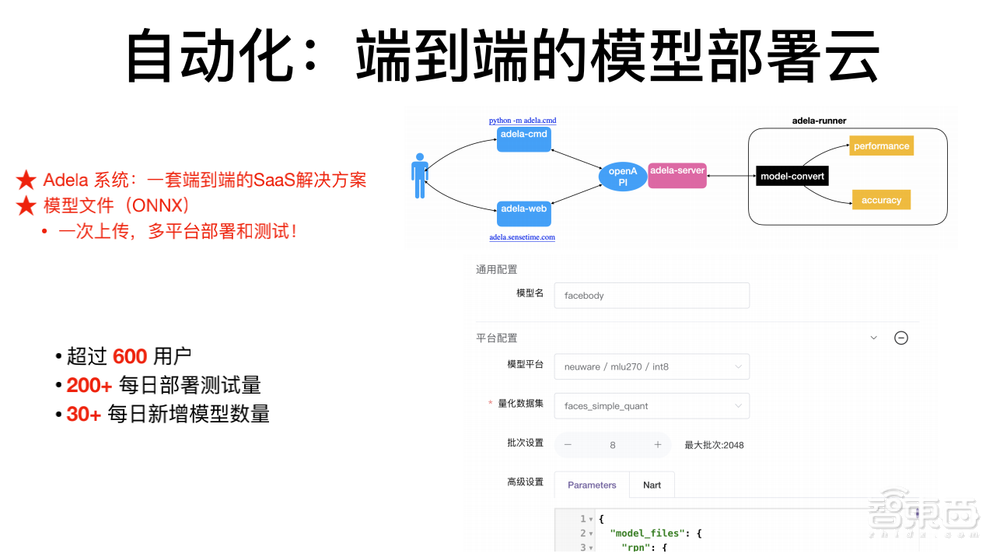
公司内部每天有600多个业务员部署模型,最开始有些人工靠人力来支持训练部署模型。
后面由于我们的模型越来越多,人力支撑不上,最终衍生出一套端到端的SaaS解决方案。它的核心是做端到端的模型部署,把格式的转换、量化以及网络级的优化混到一起,实现一次模型上传、多平台部署测试、一次性搞定。
这套系统在内部叫Adela系统,现在每天支持600多名公司内部用户,支持商汤目前超过90%的内部模型发布。
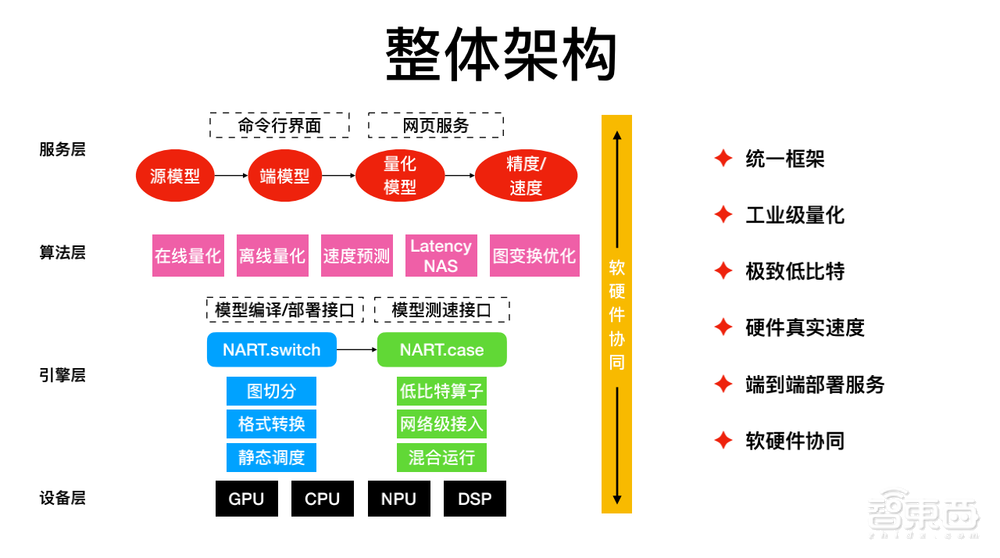
这套服务架构分成四层,第一层设备层,这一层不太可控,主要以支持外部任意设备为主。
第二层引擎层,我们会接入低比特的算子,网络运行时,支持混合运行,然后会做很多图切分、格式转换、静态调度。
通过引擎层上面做一些封装,封装成模型编译部署接口、测速接口,在上面提供很多算法:包括在线量化、离线量化,还包括速度的预测、网络结构的搜索、图变换的优化等等。
再往上到了服务层,从原始模型文件到端模型到量化模型再到速度和精度更优的模型,提供非常统一的框架。提供统一框架之后,通过一个命令行或者网页上简单的交互,就可以实现全自动的业务模型部署。
为了进一步促进学术研究跟工业界的结合,我们目前也在计划把两个核心的服务对外开放,一个是模型的自动量化,另一个是模型在特定硬件上的优化建议。
量化上包含了目前我们认为较好的学术界算法,以及自己研发的使工业界模型量化更加落地的算法,跟现在市面上主流推理引擎做了对接,适配大部分深度学习的硬件和后端,这样可以非常方便研究员验证这个算法是不是真的可以实际部署,也方便我们的硬件厂商来进行最新算法的跟进工作。
同时把计算数据库GPDB服务的能力逐步提供出来,不仅方便研究员验证结构在实际设备上的速度,还方便硬件厂商来寻找各种性能的缺陷和瓶颈。
目前我们在准备一些开源的流程,希望更多人能够得到相关技术的收益。我们有一个专门负责这部分工作的内部研究团队叫工具链团队,平常也会写一些专栏,欢迎大家关注。

以上是闫俊杰演讲内容的完整整理。
