








芯东西(公众号:aichip001)
编辑 | 高歌
智东西6月4日消息,近日GTIC 2021嵌入式AI创新峰会在北京圆满收官!在这场全天座无虚席、全网直播观看人数逾150万次的高规格产业峰会上,来自产业链上下游的16位大佬共聚一堂,围绕嵌入式AI的软硬件生态创新、家居AIoT、移动机器人和工业制造产业4大版块地图,带来了深入浅出的分享。
会上,安谋中国AI技术高级市场经理吴彤以《构建AI智能“芯”生态》为题,对当前AI芯片发展趋势以及安谋自研人工智能专用处理器IP“周易”AIPU进行解读。
如今行业已进入以数据为驱动的计算时代,也称为第五波计算浪潮,从网络架构到计算架构都产生了大量需求。依托Arm世界领先的生态系统资源与技术优势,安谋中国面向国内市场独立研发了“周易”AIPU。
 ▲安谋中国AI技术高级市场经理吴彤
▲安谋中国AI技术高级市场经理吴彤
吴彤谈到当下AI芯片市场有四大发展趋势,一是端侧芯片市场增速非常高,二是未来5-10年端侧推理市场的增速最快,三是ASIC定制化芯片将成为未来的主流,四是细分市场规模将会保持高速增长。
另一方面,AI芯片行业专用架构(DSA)正在兴起,主流AI算法也呈现轻量化趋势。在这些趋势下,安谋中国自研的“周易”AIPU拥有完全自主可控、完整生态等特点,目前已经推出两代产品,分别为“周易”Z1和“周易”Z2。
其中,“周易”Z1是边缘计算通用的AI IP,面向IoT&Edge,基于“周易”Z1研发的全志R329智能语音芯片即将大规模商用;“周易”Z2面向边缘计算中高性能场景,基于“周易”Z2开发的芯片也即将应用落地,主要覆盖中高端安防和自动驾驶/智能座舱领域。
此外,吴彤还介绍了两款AI IP的应用案例,包括人体关键点检测、驾驶员疲劳监测(DMS) 和DTV超级分辨率应用等。
以下是吴彤的演讲实录整理:
一、第五波计算浪潮或助推Arm芯片出货超万亿
吴彤:首先感谢主办方智东西的邀请,我是安谋中国AI技术市场吴彤。今天给大家带来的分享主题《构建AI智能“芯”生态》。我的主题分享分为三部分,第一部分是介绍整个Arm架构的赋能情况,第二部分是一个对AI芯片以及AIoT市场简单的分析,最后一部分是我们整个安谋中国自研的AI IP“周易”两代产品的市场、技术情况。
首先,有一个概念叫做第五波计算浪潮,大家都知道在以前最开始的时候,我们有PC、个人计算、互联网和移动互联网,可以称之为前四波计算浪潮。什么叫第五波计算浪潮?一句话总结,一个以数据为驱动的计算时代。第五波计算浪潮主要特点除了芯片层面多样化的需求以外,从网络架构,包括从计算架构都有大量的需求产生。作为Arm的一家生态型公司,我们一直在思考怎么样在这个体系下通过和我们合作伙伴提供更多定制化的服务,包括架构以及芯片类的创新,能够赋能整个生态。
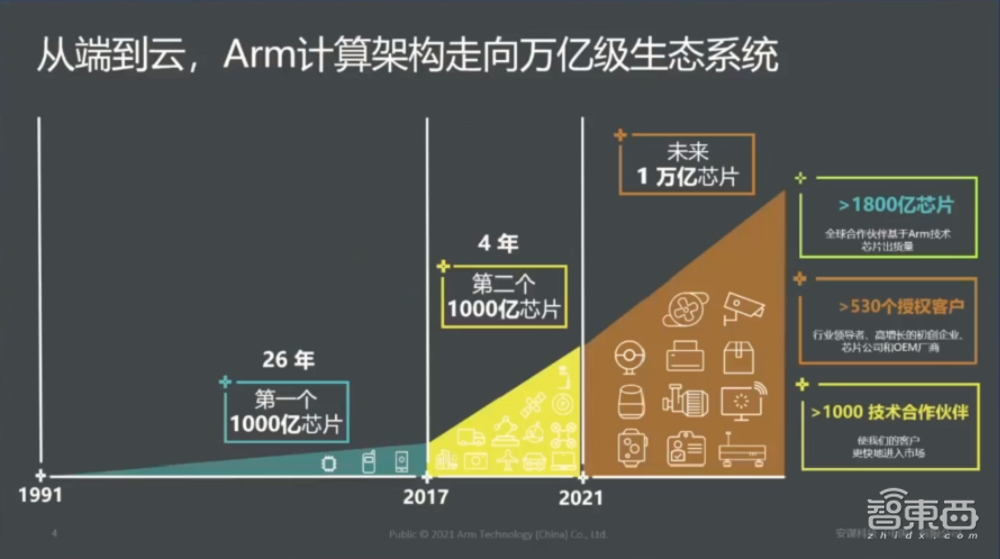
这是我们整个Arm的一个从1991年一直到现在Arm计算架构走向万亿级生态的图。大家可以看到,从1991年一直到2017年用了26年的时间,(Arm)达到了全球第一个一千亿芯片的出货量。从2017年到2021年,其实我们只用了四年时间就达到了第二个一千亿芯片的出货量,这个增长非常快。(在)第五代计算浪潮的驱动下,我们希望未来能达到一万亿芯片的出货量。
安谋中国从成立之初到现在,几年内,安谋中国在国内服务的客户超过两百家以上,在国内的(芯片)出货量将近两百亿。
二、端侧AI芯片增速快,领域专用架构兴起
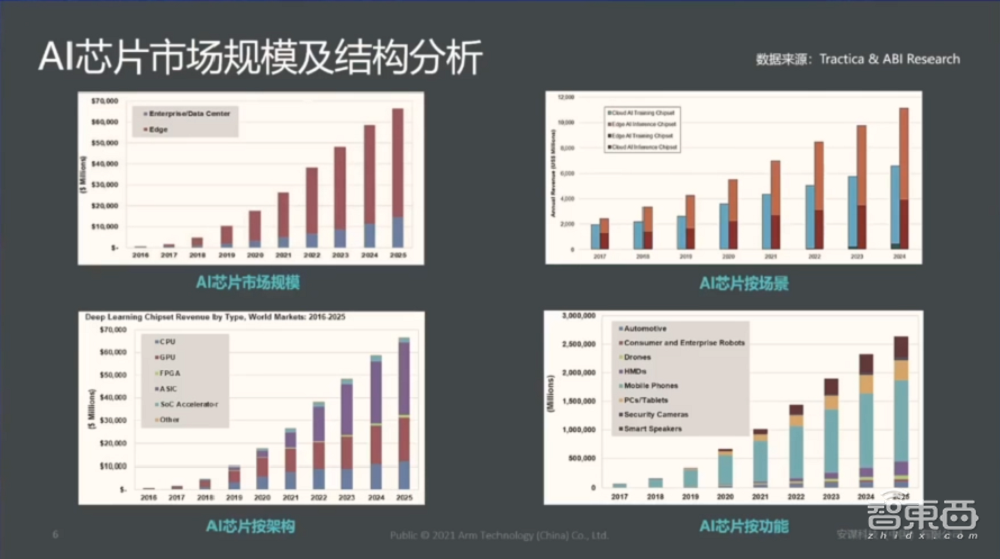
下面给大家分享一下AI芯片以及整个AIoT市场整体的情况。这里有四张图从AI芯片的市场规模、按场景、按架构、按应用层面对AI芯片的整体介绍。
1、AI芯片发展趋势:端侧增速最快
首先第一张图是整个AI人工智能芯片的市场规模,2017年到2025年接近十年的区间,有一个趋势可以看到,从红色数值可以看出,和云端相比,端侧AI芯片的市场增速非常高,尤其在未来的5—10年的区间之内。
第二张图是AI芯片按场景来划分的趋势,这个场景分成四块,两大部分。第一个维度是整个的云端,包括云端推理和云端训练。第二维度Edge端侧,包括推理和训练。这张图得出一个结论,在未来5—10年内,我们可以看到,在整个端侧包括云端还有Edge端推理市场的增速是最快的。
第三个图是AI芯片按架构划分,能够看到人工智能芯片所有看到的主流架构,包括GPU、FPGA、包括ASIC等等。从中也可以看到,ASIC定制类的芯片也会在未来的五到十年内成为市场上的一个主流。
最后一张图,是按照人工智能的细分垂直领域场景来看,这里面我们看到,手机端不用说了,也是Arm比较主流的一个行业,手机端依然保持相对比较高速的增长。同时像可穿戴设备、包括智能音箱几个细分市场未来几年之内也会保持比较高的增长。
2、AI芯片领域专用架构(DSA)开始流行
这个是从垂直市场的层面来讲,我们谈到,整个人工智能芯片有一个比较重要的概念叫DSA。谈到之前,我们先看一个很有意思的试验,这个试验是一个算法,这个算法主要以矩阵乘法为主。
我们可以看到,增速很快的这条曲线在不同的硬件环境包括软件环境下做的实验。从最开始在Python环境,第二个是在纯C的环境下做,再往后我们加入了很多并行计算包括memory优化、包括目前主流的SIMD助理,在不同的体系架构下,同一套算法从最原始的Python到最后的SIMD形式(的执行效率)增长63000多倍。
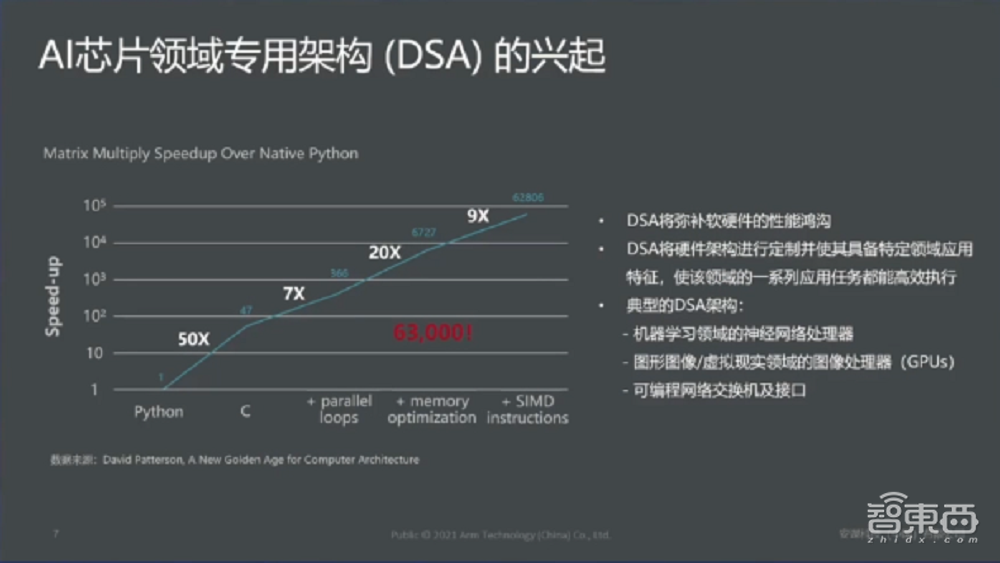
这个试验说明什么问题?在我们现在AI芯片领域里面,其实DSA也就是专用架构可以处理特定领域的一些问题,目前甚至将来应该会成为一个主流。这种DSA我给大家举一个例子,就是什么样的(架构)属于DSA呢?比较知名的像是NVIDIA GPU、包括很多网络处理器芯片、包括现在我们比较热门的NPU神经网络处理器都可以理解为一种处理某些特定领域问题的架构,我们都(可以)叫DSA。
这是我们看到的目前、包括未来有可能AI芯片架构整体技术演进的趋势。从最上面的GPU,以英伟达和AMD为代表,GPU本身做图形处理,最开始不是给AI人工智能来用,英伟达为代表的这些公司在GPU里面做了大量改进,加入HWA(Hard·Wired·Accelerator),也就是我们叫TensorCore,把它(GPU)变成面向人工智能领域很好的处理器芯片。
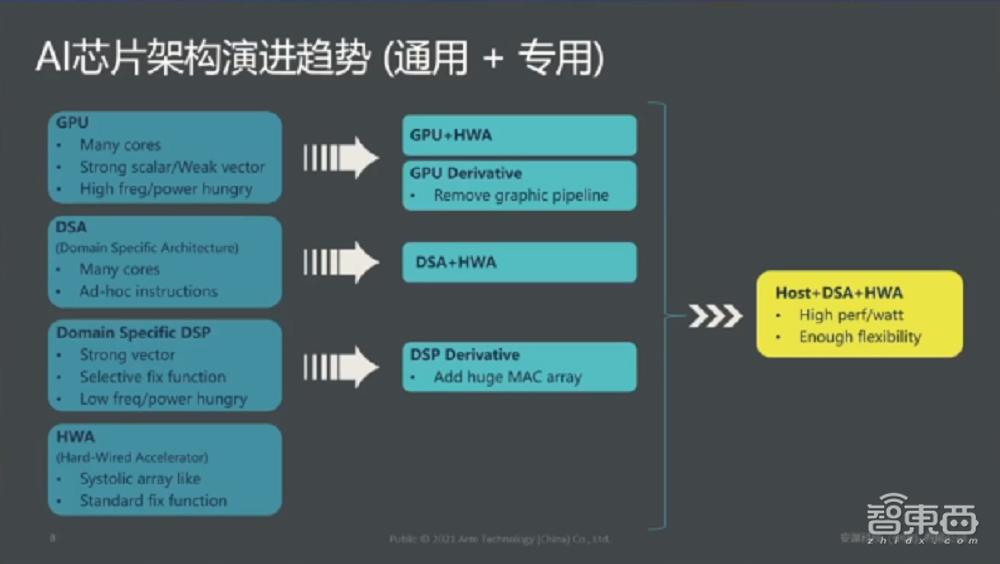
还有一类也是传统做信号处理的DSP,现在也有很多公司把它变成人工智能芯片,在DSP基础上加入大量的MAC阵列。比如英特尔收购的一家公司较Habana他们的架构也是基于这个架构设计的。
另有一类,以ARM为代表的异构计算,加了CPU,同时也有DSA的专用领域,加入专业面向矩阵加速的HWA加速器,构成了一种异构计算模式。这种模式我们认为,在目前包括未来将会成为主流,它可以同时满足很好的PPA(Power Perform Area),包括各种能效比都会达到很高的数值。
3、6大维度评判AI芯片
这里是我们根据很多客户的需求,我们大概总结了一下,当很多公司都在谈一款好的AI芯片,不管你自己设计还是用各种成熟的IP也好,什么样的芯片才能称之为好的AI芯片?我大概分了六个维度。
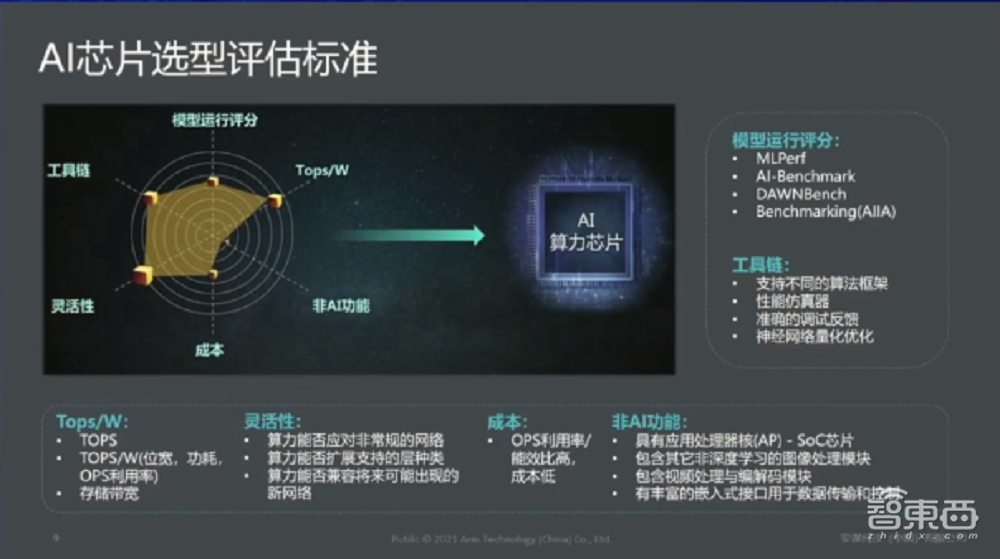
一颗好的AI芯片经过各种国际主流的benchmark评测,包括像MLPerf;像人工智能联盟的benchmark,也是在国内很知名的benchmark;还有等等。这个是衡量AI芯片算法模型很主流的评测标准。
还有一个,我们不光从硬件,我们还要从整个生态链、软件栈,也就是我们经常说的工具链(来看)。从工具链层面,很多公司尤其像我们设计了很完整的工具链体系。工具链的完整是衡量你AI芯片是否成熟的一个标准,同时也是看到你能够给客户提供什么样的这种支持。
还有一个很多媒体都在谈的,AI芯片一定要谈算力TOPS。其实TOPS不是唯一衡量AI芯片算力的标准,还有很多其它因素,比如有TOPS/瓦能效比,跟微观、功耗包括算力利用率都是有关的。还有很重要的因素,就是存储带宽。刚刚知存科技的王总也提到了,为什么我们现在存算一体芯片非常热门,就是它能够解决数据搬移的问题。
当然了,还有几个维度关于AI芯片这块。
首先AI芯片要有很好的灵活性,因为我们的算力不是固定的东西,需要支持常见的神经网络,同时有很强的扩展能力,比如客户能力很强,会自定义自己的算子,作为IP或者芯片供应商来说,我们需要能够支持客户做自定义算子的扩展。
当然了,还有除了AI层面的其它因素,我把它列了叫非AI功能。我们接触了很多客户后发现,客户对我们的需求不仅仅只在AI一个层面。比如对于安防场景来说,安防客户不仅仅需要你只提供一个AI芯片,希望你提供更多的Solution解决方案,比如需要ISP、VPU、视频处理等等。
其实很多非AI功能如果你能把它变成一个总体解决方案,在未来很多垂直领域是非常有竞争力的。目前安谋中国也在打造这样比较完整的IP组合平台。
4、AI算法正趋于轻量化
这是一个对AIoT芯片市场的分析。简单说,整个AIoT芯片刚才几位嘉宾也讲过,AIoT整个市场其实比较碎片化,目前看它的增速非常快,端侧的芯片增速也非常快。
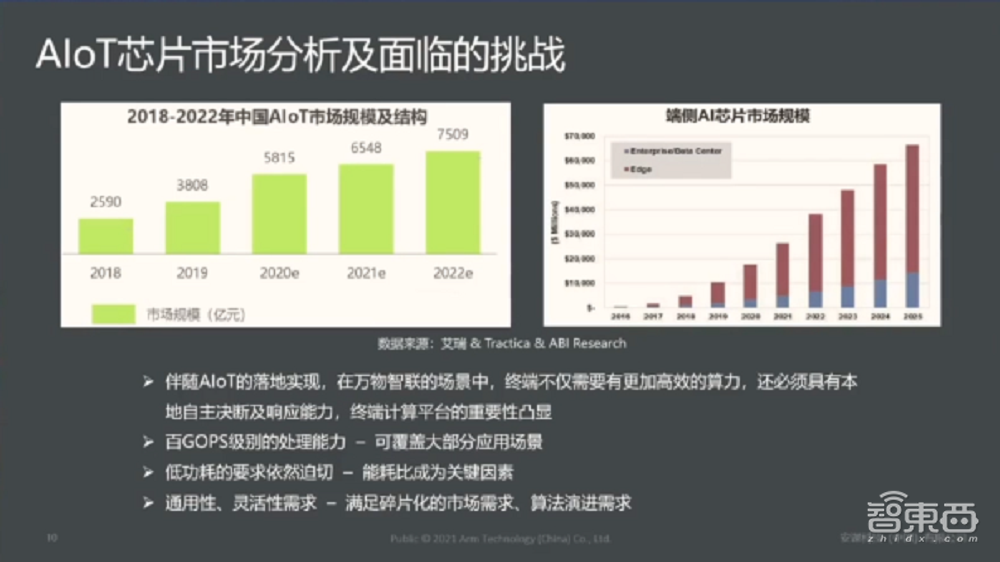
但是首先它有很多这种需求,比如对低功耗要求非常高,在很多低功耗的场景,甚至达到毫瓦级的水平,比如可穿戴设备等。同时,对于很多场景来讲,可能算力要求没有特别高,尤其对于AIoT领域,在100 GOPS下就可以覆盖大部分场景。

这个是我们看到的整个AI算法市场的一个轻量化趋势。左边这张图来说,2014年开始市面上主流的轻量化算法,对算力需求越来越低。我们看到,很多主流的算法轻量化趋势非常明显,它的计算量包括权重跟之前相比已经减少了几十倍左右。举个例子,我们做多目标检测的时候,如果想做30FPS Throughput(吞吐量),只需要大概百GOPS算力就可以了,每帧计算量可以降低到5GOPS以内。
此外,算法轻量化的趋势商汤的闫总也提到了,我们有大量模型轻量化的手段,都是一些很主流的量化、剪枝、共享、知识蒸馏等等。那么这种模型量化的手段是日益的在演进,也就把我们算法轻量化的趋势推的越来越明显。
三、“周易”AIPU:两代产品覆盖全场景、全栈平台
前面分享了Arm架构和AI芯片和AIoT芯片的趋势。后面重点讲一下安谋中国“周易”AIPU的一个整体情况。“周易”AIPU是安谋中国自研IP产品线中AI人工智能部分,我们还有CPU、ISP其他等等的产品线。
这是我们目前,“周易”也是AIPU产品线上看到的市场上几个比较热门的机会。第一个是比较热的安防,我们目前有客户和合作伙伴已经在基于我们的AIPU定制自己安防前端的芯片,应该很快产品就会出来。手机是ARM在手机端生态里面比较优势的一块,未来作为安谋中国自研“周易”AIPU将来关注的市场。
还有另外一个市场就是自动驾驶和智能座舱。如果大家去看各种峰会、媒体(报道),智能汽车已经成为目前最热的一个词,而不是之一。

从安谋中国来讲,我们对自动驾驶以及智能座舱领域非常关注。首先,Arm能够提供的IP组合通过级联等,做到几百体T(TOPS)以上的算力,同时我们可以提供的不仅仅是AI,而是包括AI完整的一套面向智能汽车完整的解决方案,(这)也是未来我们希望着力去发展的领域之一。而且目前我们有比较知名的合作伙伴,也会在今年或者明年推出基于我们AIPU的座舱类产品。
其他几种,像智能家居、机器人、新零售,目前智能家居已经有落地的芯片,今年年内有智能音箱的产品出来,也是一家TOP的公司。
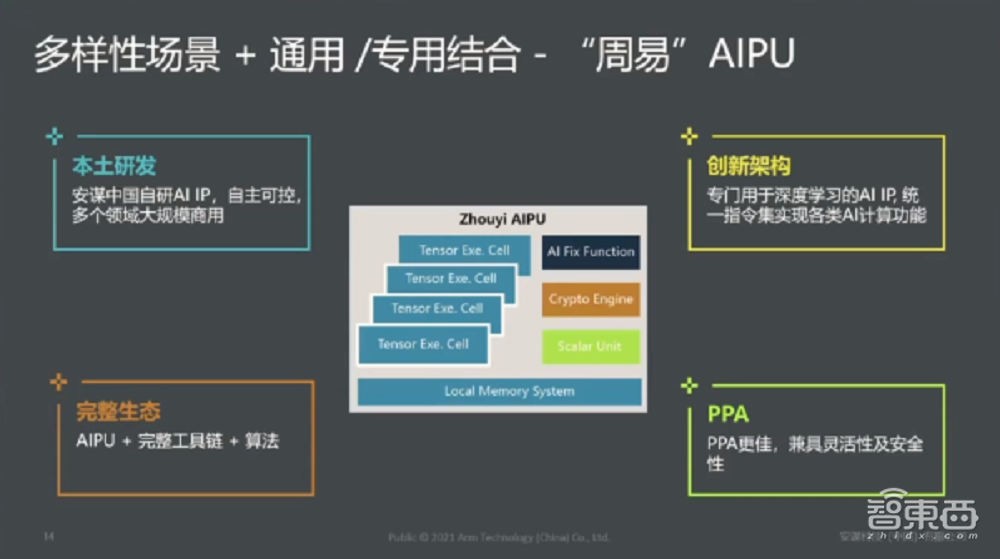
1、“周易”AIPU四大特点:本土研发、生态完整、架构创新、满足高PPA指标
安谋中国的“周易”AIPU有四个特点,这是我们硬件一个比较简单的框架图:
1)首先“周易”AIPU由中国本土团队研发,所有的知识产权完全自主可控,目前“周易”AIPU在几个比较重点的领域安防、汽车、智能语音领域开始即将大规模商用;
2)同时,我们会给客户、合作伙伴提供完整的技术生态,它是一个硬件加上完整的工具链以及适配整个硬件算法的体系;
3)从架构层面,自研一套专门面向深度学习的指令集架构,也是安谋中国技术团队自主研发;
4)从PPA的三个指标来讲,通过我们的实际测试和客户的反馈,可以达到很好的匹配。

这是我们整个“周易”架构相对比较详细的介绍。从技术层面,指令集层面分成三类,第一类指令集叫做张量指令集,也就是我们经常常见的向量Vector,能够对一般的神经网络进行运算和处理。
第二类我们把它叫做AI Fix Function,这一类有点类似硬件加速单元,它是针对卷积操作里面很常见的一些操作来做特定的硬件加速,能够提供很好的效率,比如像卷积、池化、激活等等。
最后一类属于算力需求比较低的我们叫标量,主要做一些循环跳转类的处理,有点类似CPU模式。“周易”从架构级层面来说,三种不同的处理混合在一起,能够满足客户从算力很低到算力很高不同的需求。同时,Arm还有一个知名度比较高的Trustzone可安全扩展,本身在“周易”里面也集成了我们的安全保护,可以有效保护用户信息,比如算法的数据等。
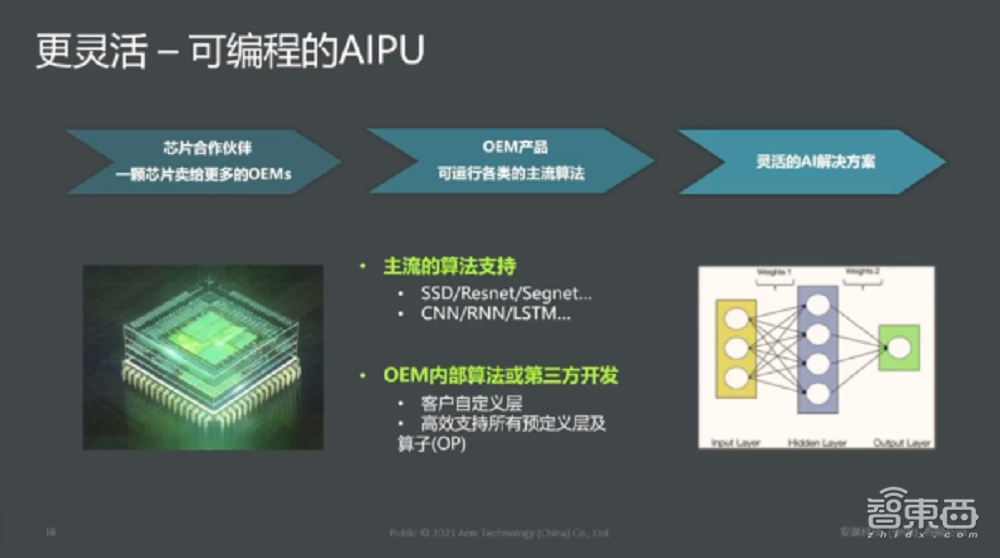
最后一点,也是比较关键的一点,我们跟很多客户接触中发现,很多客户如果选用比较成熟的IP做自己的SoC的时候,有很多客户的算法能力非常强,需要有算子自定义的需求。根据我们的调研,大概50%以上的客户有算子自定义的需求、本身我们的“周易”AIPU就有很好的支持客户算子的自定义扩展。
本身AIPU关键的一点就是灵活可编程。在设计一款芯片的时候,其生命周期在5年左右。在这5年的区间里,算法本身的迭代是非常快的。在设计芯片之初,就要考虑有很完整的算子支持,甚至IP的变化是完全可编程的,这才能满足算法的不同需求。本身我们的IP也是朝这个方向去做。

“周易”AIPU可以提供一个比较完整的可扩展能力。因为“周易”本身是比较通用的AIPU平台,可以提供从最小0.2T算力甚至上百T算力的组合。这里面对很多比如常见神经网络层,包括算子可以完全实现可编程,通过TEC张量来做的。
针对特定的卷积类操作,比如池化、激活、权重、特征图压缩等,我们通过一个特定的AI指令集也就是AI Fix Function来做,同时支持客户的扩展。
从工具链层面,我们会给客户提供完整易用的SDK。举个例子来说,我们有命令行甚至图形的方式让客户能够快速一键生成我们的模型,比如你有一个TensorFlow或者Caffe的模型,通过命令行输入,直接通过SDK一键转化,很快生成AIPU可执行的文件,整个操作非常方便。同时,从模型框架方面,目前支持现在市面上比较主流的一些模型,包括TensorFlow、Python、TensorFlowLite等。
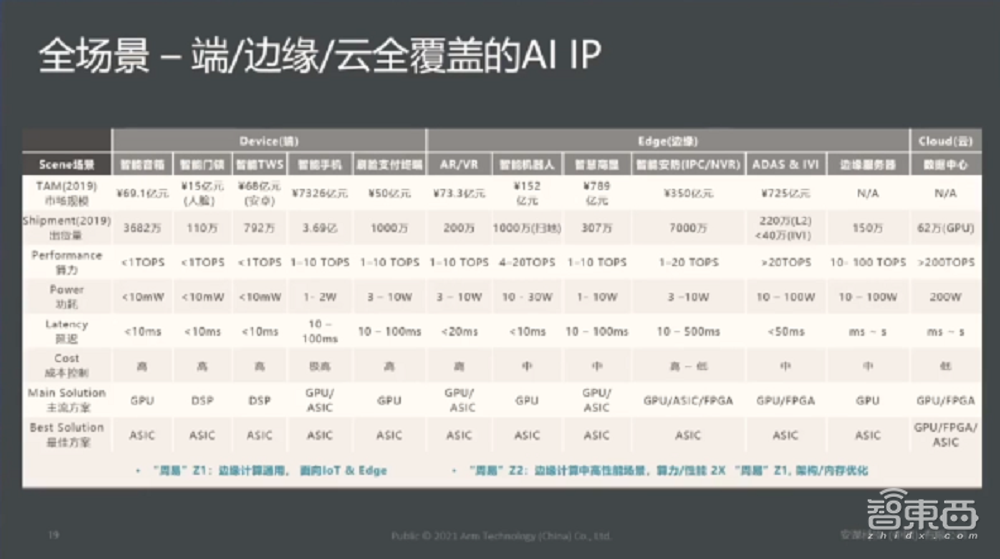
这是我们的总结,面向人工智能领域端、边、云三大类,“周易”基本可以覆盖全场景人工智能解决方案,从端侧、边缘侧、云端做一个总结。端侧有门锁、可穿戴设备,像TWS、智能音箱、包括手机智能终端等每年市场的规模,包括需要的算力需求以及它的功耗,我大概做了一个整体的分析。
从这里面,我们可以得出一个结论,目前市场主流的解决方案基本还是以GPU包括DSP为主,但是未来的趋势,也就是最佳的解决方案,面向所有的场景来说,ASIC定制化的芯片将成为主要的解决方案。对于“周易”AI IP来讲,两代产品包括今年年末发的第三代产品基本上可以覆盖从端侧到边缘侧所有的人工智能场景。
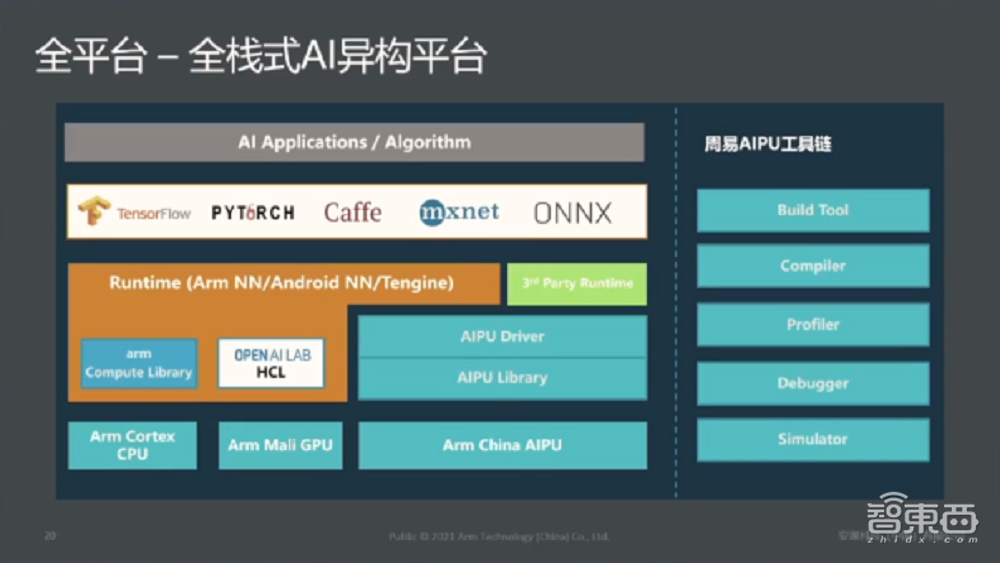
人工智能芯片除了硬件层面,整个软件栈就是我们的生态是非常重要的,这是目前“周易”全栈式异构平台的软件栈。最底层对Arm整体Cortex CPU、Mali GPU以及我们自研的AIPU硬件体系的支持;到上层很多计算库,包括合作伙伴完整的driver以及run time库,像Arm NN、Tengine的支持;到最上面像TensorFlow、Caffe、PyTorch等等支持,“周易”覆盖了整个软件站各个层面的支持。
从工具链层面,我们目前针对一颗芯片来说,所有的工具链全部都是支持的,包括Simulator、Debugger、Profiler、Compiler还有Build Tool,也是构建整个完整生态非常重要的一个环节。

这里面是我们刚刚讲的,“周易”是通用的AIPU平台,如果通用的话,我们一定要谈到对目前市场上主流的深度学习算子支持,内置的Model Zoo预训练模型的支持,涵盖了目前市面上可以看到的主流算法,比较热门的transformer等等。
在算子层面,“周易”的第二代产品支持超过120个以上的主流算子,而且还在持续的增加过程中。
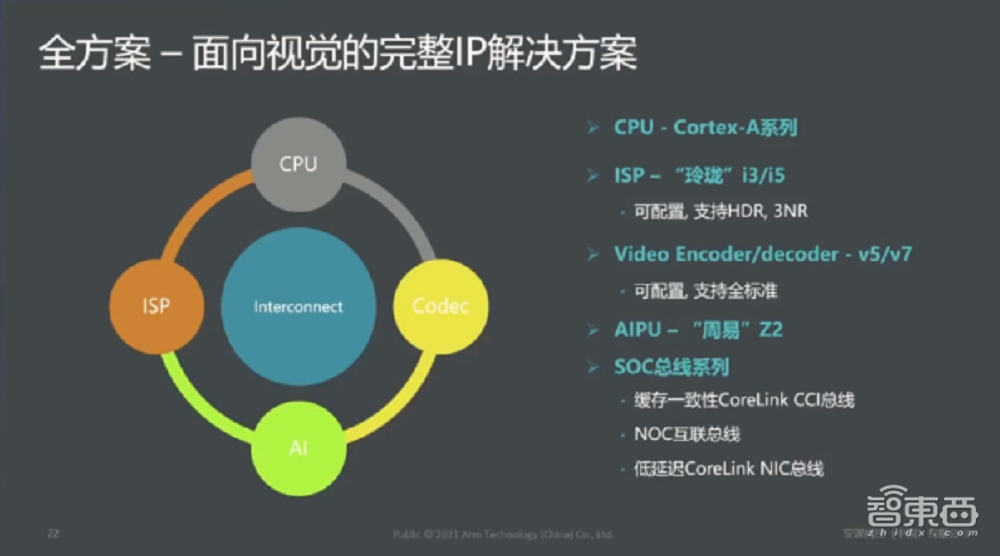
在安防、自动驾驶很多场景里面,客户需要完整的解决方案,针对客户需求我们打造了面向CV视觉领域完整的IP解决方案。这里面不仅仅包括AI,包括ISP、CPU,通过互联的方式组成完整的生态链。
Arm的M和A系列是完全支持的,ISP也有Arm中国自研的玲珑,(该产品)前段时间刚刚发布,ISP和“周易”、Video Encoder等一起,可以为客户提供一个完成比较完整的视觉IP解决方案。
2、“周易”Z1:边缘计算通用的AI IP,面向IoT&Edge
这是我们“周易”的第一代产品,叫“周易”Z1。这是我们跟全志科技(合作)已经正式量产,今年很快大规模商用。全志R329用的是周易Z1的AIPU,提供的算力在0.2TOPS左右。
这个算力也让我们看到了在智能音箱领域算力的一个趋势,我们可以看到,端到端的语音算法将会成为一个主流的趋势。

“周易”可以很快解决端到端的处理,把数据直接通过神经网络送进来,不需要单独像之前由DSP做前端处理,可以通过AIPU处理。通过试验对比,我们跟一些DSP做了一些测算。能效比包括算力(“周易”AIPU)相当于它(DSP)的七倍以上。
这也是“周易”Z1,可以提供不同的算力组合。这是我们做了一个人体关键点检测的应用案例,实际应用去跑,支持人脸关键检测的算法,像Open pose、Deep pose等,在1TOPS计算力环境下吞吐量基本可以做到80FPS。而且在这个环境下,我们的bandwidth(带宽)非常低,整个成本相较来说也比较低。
3、“周易”Z2:针对边缘计算中高端场景优化
“周易”Z2(是)第二代产品,跟Z1有一点不同,“周易”Z2更多面向边缘计算和中高端的场景,比如自动驾驶、中高端的安防等等。
Z2和上一代产品相比,它的特点在于单核算力是上一代产品的两倍甚至更高,同时支持多核级联,其算力在128TOPS左右,可以做到自动驾驶甚至中高端场景的需求,芯片面积Z2比上一代产品节省30%左右
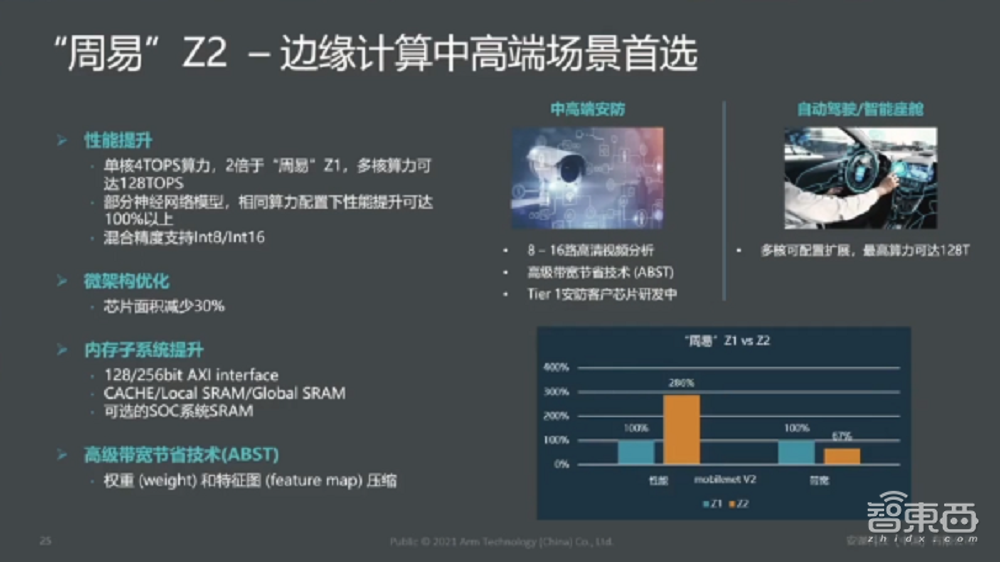
从算法层面来讲,“周易”Z2支持混合精度计算,同时在同等算力配置下,通过测算“周易”Z2比上一代产品针对某些网络模型的性能高很多,两代产品做了一个对比,找了一个比较知名的网络模型MobileNet V2,在带宽节省30%同时,性能提升接近3倍左右
“周易”Z2在今年或者明年也有一些合作伙伴,基于“周易”Z2 AI IP做应用和场景的落地,主要面向安防和智能汽车两个领域。

这是我们在“周易”Z2实际的应用环境做的智能汽车比较热的领域DMS驾驶员的疲劳监测。我们和主流的DMS公司做了算法的合作,涵盖了Face Detection、Face landmark、Head pose、Gaze等所有算法我们做了一个融合。“周易”Z2在1TOPS算力环境下,throughput做到了70fps左右。

这是另外一个应用,“周易”Z2做了超级分辨率DTV(的一个案例)。我们也是跟主流的超级分辨率公司做了合作,用的“周易”Z2 1T算力硬件环境,经过我们的测算能够做到4K 60帧左右,同时使用业内知名的图象或者质量评价工具WMAF,其评分达到93分。基本上(该应用的)93分是非常高的分值,一般做到80分以上就非常高了。
最后跟大家整体的总结一下,目前安谋中国基于全球Arm的标准,我们在这个基础上做了很多本土创新的工作。第一,我们的“周易”AIPU是面向安防、车载甚至移动很多IT场景的AI通用处理器。
还有其它的安谋中国自研产品,包括“山海”,是面向物联网领域的安全解决方案,目前很多客户在落地。还有两个是我们的CPU和ISP解决方案,一个是“星辰”(STAR),(一个是“玲珑”)。在TWS领域,OPPO用了我们“星辰”CPU IP(的产品),已经大规模量产和出货。“铃珑”是我们近期刚刚安谋中国推出的自研ISP解决方案,后面还会推出面向安防和智能汽车不同应用场景的解决方案。
我今天的介绍就到这里,谢谢大家。
以上是吴彤演讲内容的完整整理。
