








芯东西(公众号:aichip001)
作者 | 心缘
编辑 | 漠影
芯东西7月7日报道,在2021世界人工智能大会期间,上海燧原科技推出第二代云端AI训练芯片邃思2.0及训练产品云燧T20/T21,以及全新升级的驭算Topsrider 2.0软件平台。
邃思2.0是迄今中国最大的AI计算芯片,采用日月光2.5D封装的极限,在国内率先支持TF32精度,单精度张量TF32算力可达160TFLOPS。同时,邃思2.0也是首个支持最先进内存HBM2E的产品。
 ▲邃思2.0部分性能
▲邃思2.0部分性能
云燧T20/T21基于邃思2.0而打造,由8000多张第二代云燧训练卡组成的云燧智算集群2.0,单精度最高算力达1.3EFLOPS,即130000TFLOPS。
燧原科技成立于2018年3月,此前已相继推出首款云端AI训练芯片邃思、首款云端AI训练加速卡云燧T10和AI推理加速卡云燧i10,以及配套的“驭算”软件平台。
 ▲燧原发展历程
▲燧原发展历程
成立至今,燧原科技连续获得过5轮融资,累计融资额近32亿元人民币。其最新一笔融资为今年1月完成的18亿人民币C轮融资,由中信产业基金、中金资本旗下基金、春华资本领投。
 ▲燧原科技CEO赵立东(左)与燧原科技COO张亚林(右)共同发布云燧T20训练加速卡和邃思2.0芯片
▲燧原科技CEO赵立东(左)与燧原科技COO张亚林(右)共同发布云燧T20训练加速卡和邃思2.0芯片
一、公布最新五年产品路线图
燧原科技创始人、COO张亚林公布了燧原产品定理:燧原的每一代产品必须比前一代在“平均业务”中每瓦性能提升超3倍,软件后向兼容可靠。
 ▲燧原产品定理
▲燧原产品定理
现场,张亚林还发布了燧原科技的最新路线图。
到2023年,燧原科技计划打造3款云端训练计算产品、3款云端推理计算产品,将性能功耗比提升至初代的14倍,并同步升级Matrix集群。
 ▲燧原云端训练计算产品路线图
▲燧原云端训练计算产品路线图
同一时期,驭算Topsrider软件平台从全栈模块发展到训推一体,继而走向泛AI生态。
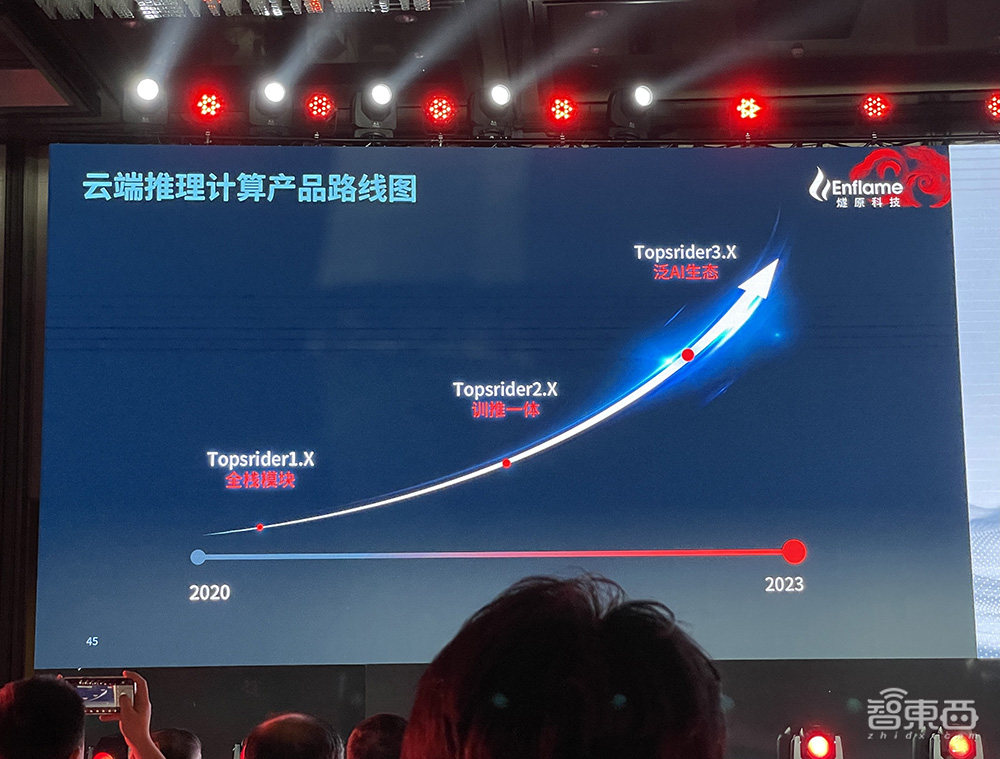 ▲燧原驭算Topsrider软件平台路线图
▲燧原驭算Topsrider软件平台路线图
燧原科技创始人兼CEO赵立东分享道,下面这些落地场景将形成燧原科技今年的收入。

▲燧原产品商业落地场景
燧原研发团队的主要成员均拥有15年以上的高端芯片及相关软件生态系统开发和量产经验,曾成功开发并量产多颗大型芯片。
截至今年5月,其团队规模已经超过500人,其中近90%为研发团队,博士及硕士占比近70%。
目前燧原已获得52项专利,其中包括45项发明专利,同时有近30项专利正在申请中。这些专利内容涵盖了芯片的运算单元、核心功能模块、到封装及系统集群,以及软件的架构和优化。
二、超大规模智算集群,最高算力达1.3E
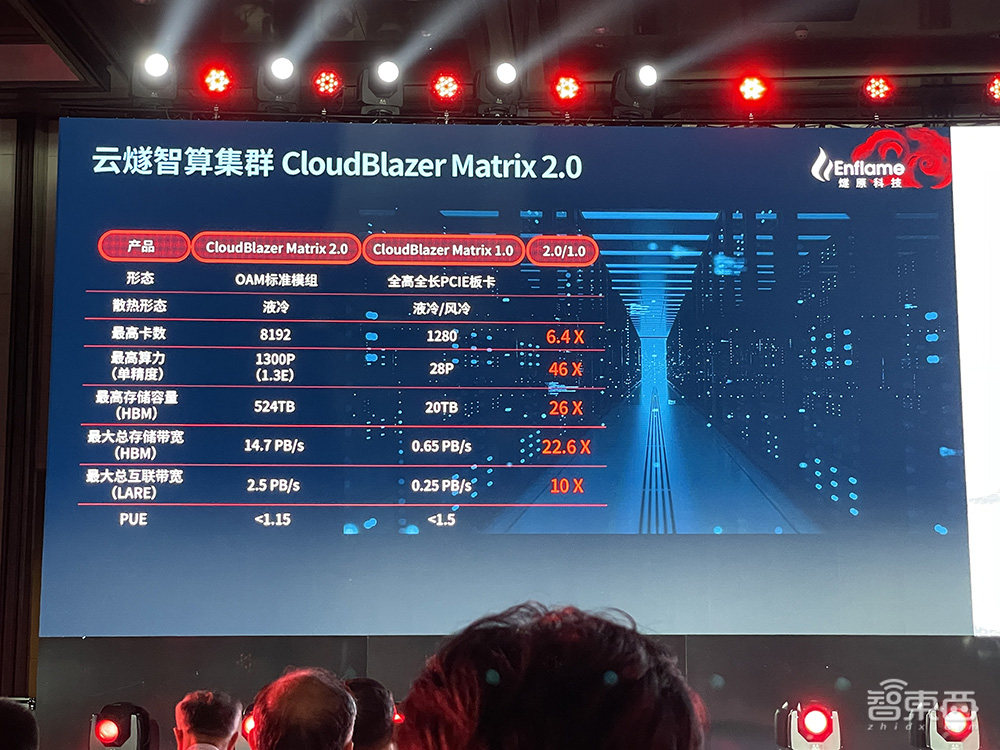
今天,燧原科技推出与友商合作打造的全新产品品牌云燧智算集群CloudBlazer Matrix 2.0,集合8192张云燧训练卡,可实现最高1.3E(130000T)的单精度智能算力集群。
 ▲云燧智算集群介绍
▲云燧智算集群介绍
“在全世界还没有人能达到在单精度算力上用8000张卡实现超过1E的算力。”张亚林说,这代表着燧原科技正式用集群化产品登上中国智能计算和新基建算力的舞台。
同时,云燧智算集群能驱动绿色数字化,液冷PUE可降到1.5以下,大幅提升整个集群的能效。
燧原与合作伙伴的联合开发,一起构建超大规模的液冷智能数据中心,以响应国家“低碳算力”和“绿色一体化智能计算”的战略方向。
三、国内最大AI芯片,五大特性解读
燧原云燧智算集群2.0包括邃思DTU 2.0、云燧T20和T21训练产品、新一代驭算软件,能有效降低AI超算集群的整体复杂度和成本。
其中,燧原科技第二代云端AI训练芯片邃思DTU 2.0经过了全新升级迭代,其计算能力、存储和带宽、互联能力较第一代训练产品有巨大提升,对超大规模的模型支持能力获得显著增强。
 ▲邃思2.0实物图
▲邃思2.0实物图
1、封装:中国最大的计算芯片
张亚林介绍道,邃思2.0是中国最大尺寸的计算芯片,采用2.5D高级封装技术,突破了台湾顶级封装合作伙伴的封装历史极限,共整合9颗芯片,实现57.5mm x 57.5mm的封装尺寸。

2、计算:TF32精度峰值算力达160TFLOPS
邃思2.0进行了大规模的架构升级,新一代全自研的GCU-CARA全域计算架构针对AI计算的特性进行深度优化,夯实了支持通用异构计算的基础。
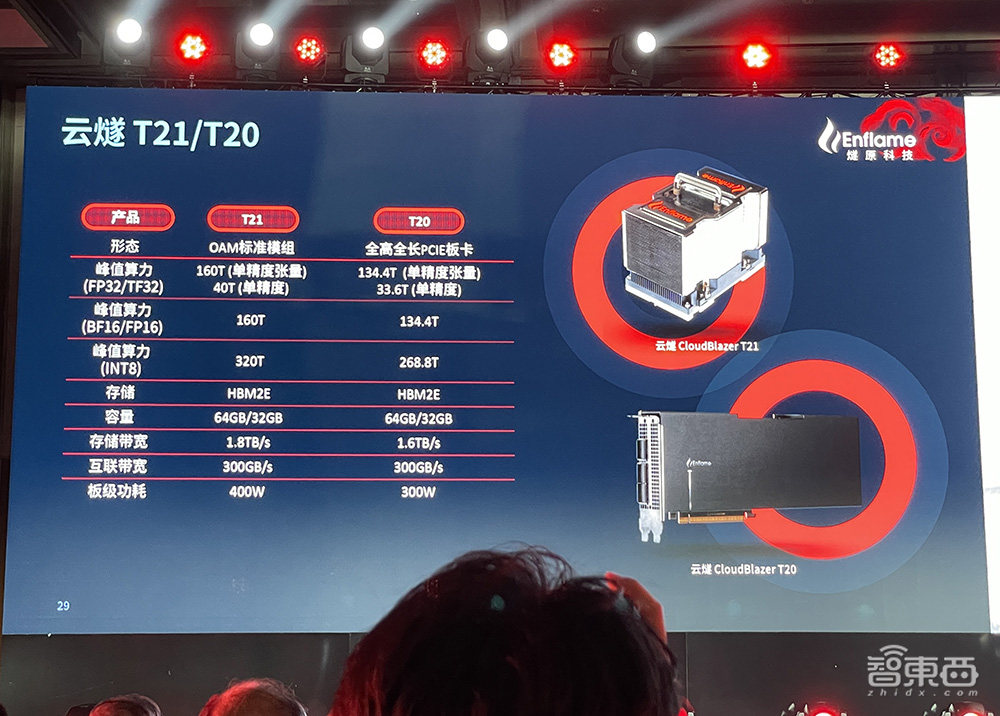
该芯片支持全面的计算精度,涵盖从FP32、TF32、FP16、BF16到INT8。张亚林说,这是中国首款支持单精度张量TF32数据精度的AI芯片,算力达160TFLOPS。在单精度FP32下,邃思2.0的峰值算力达到40 TFLOPS;同时该芯片支持定点整数精度,峰值算力达320TOPS。

3、数据:植入完全可编程的数据流
数据被认为是AI在芯片处理上仅次于计算的部分,因为数据流的处理会直接决定计算的效率,燧原科技在整个芯片内部,植入了完全可编程的数据流。
软件指令驱动的传输和数据计算,保证了数据的吞吐量,以及不同模型下的效率,完全支撑标量、向量和张量的高效数据处理,以及多地址广播。
4、存储:率先支持HBM2E先进存储
邃思2.0的中心是主芯片,在边缘有4颗三星最先进的存储芯片HBM2E,高配支持64GB内存,最大带宽达1.8TB/s。据悉,这是中国首款支持世界最先进存储HBM2E和单芯片64GB内存的产品。
5、互联:高速互联支撑算力扩展
GCU-LARE全域互联技术是燧原专为AI训练集群研发的互联技术,提供双向300 GB/s互联带宽,支持数千张云燧CloudBlazer加速卡互联,可实现优异的线性加速比。

四、训练卡算力比肩友商旗舰
云燧T20和云燧T21是基于邃思2.0打造的两款AI训练加速板卡。具体参数如下:
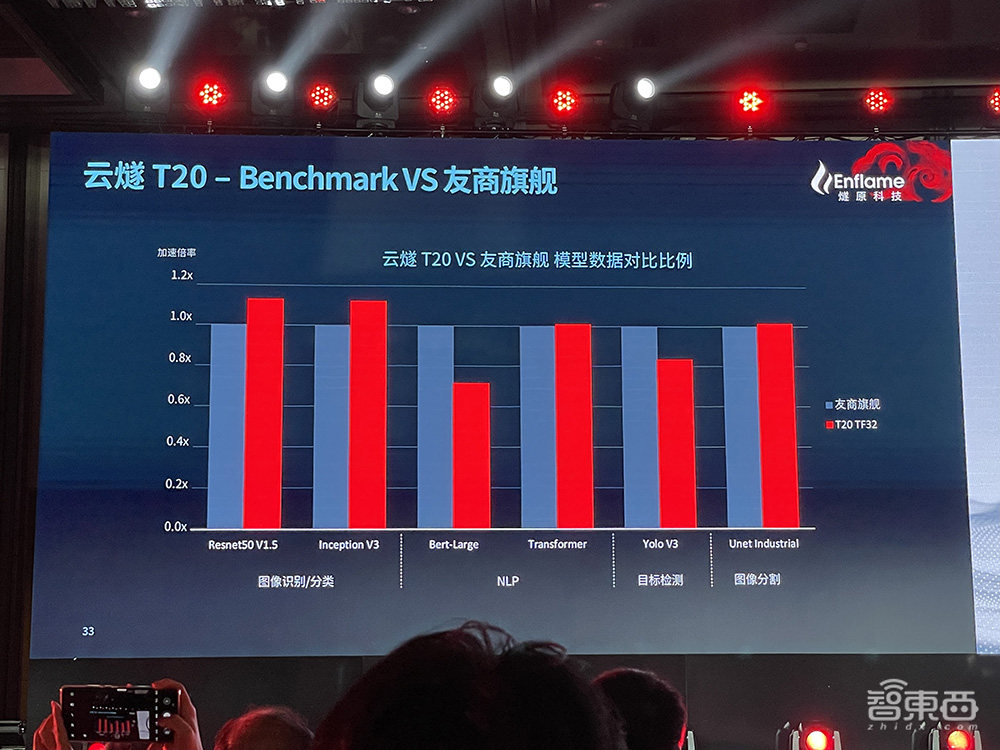
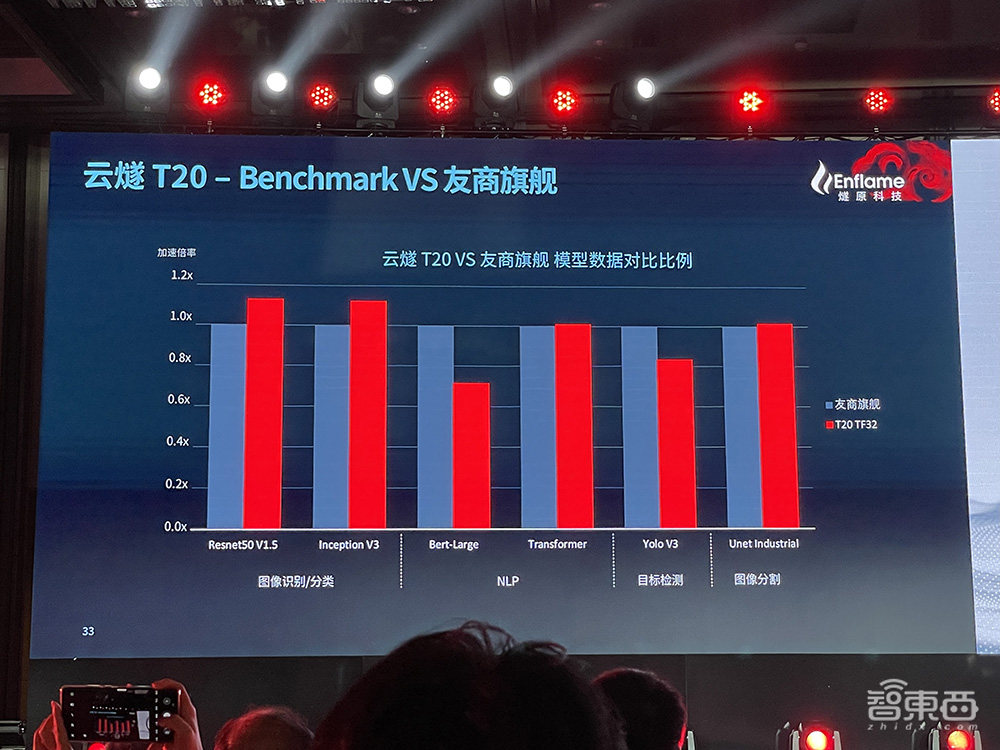
燧原科技还现场展示了T20的Benchmark,由图可见,云燧T20 TF32精度性能平均2.5倍于友商次旗舰。
在多类模型测试中,云燧T20与友商旗舰性能几乎不分伯仲。
五、软件平台同步升级:更高更快更通用
此次同步升级的驭算Topsrider,是燧原科技自主知识产权的计算及编程平台。张亚林介绍道:“升级后的驭算软件平台更加便捷易用和客户友好,燧原科技也可针对客户的场景和业务模型提供软件定制化服务和优化,打造差异化解决方案。”
 ▲驭算Topsrider2.0架构
▲驭算Topsrider2.0架构
总体来说,驭算Topsrider2.0有三大特点:更高性能算力、更便捷高效开发、更灵活通用支持。
升级的驭算平台通过软硬件协同架构设计,充分发挥邃思2.0的性能,并借助侧写工具、自动化调整等功能进一步释放硬件算力,同时,其高效并行通信库支持超大集群高线性加速比。
该平台对开发者很友好。开放升级的编程模型和可扩展的算子接口,为客户模型的优化提供了快捷的自定义算子开发能力。驭算也提供完善编译器和工具链支持、开箱即用的图形化整合开发环境、动态形状自动编译和高性能运行支持。
当前驭算Topsrider2.0基于算子泛化技术及图优化策略,可支持主流深度学习框架下的各类模型训练和ONNX模型转换;设备虚拟化方面,最大可支持4个MID用户。
六、公布“燎原”计划,构建通用异构计算生态
面向生态建设,燧原科技创始人兼CEO赵立东宣布推出燧原异构计算生态“燎原”计划,有原始创新、标准化、生态共建三大特征。
这一计划的目标是以AI为起点,构建通用异构计算生态,构建标准化技术体系,共建完整生态服务数字中国。

除了在深度学习计算、通用人工智能领域外,燎原计划还会透过通用异构计算来涵盖科学和工程计算,以及视觉计算相关的视频编解码和图形渲染等。赵立东说,这个表列将根据市场发展和需求不断增加。
 ▲燧原的生态朋友圈
▲燧原的生态朋友圈
“燧原已经在原始创新的路上了,但是,所有的事情必须要脚踏实地。”赵立东说,“这才能够使得我们真正实现自主可控、原始创新,真正建立中国强大的人工智能算力。路虽远,行则将至。事虽难,不做不成。”
结语:国产云端AI芯片走向落地新竞赛
完全自研的软硬件架构,使得燧原科技在知识产权和产品升级迭代上可以自主掌控方向和节奏。
成立三年以来,燧原科技严格遵循每年推出一款云端计算新品的节奏,完成了大芯片、软件全栈、系统集群从产品定义、设计验证、流片到产品的最终商业落地。这样的研发速度和落地能力,在国内云端AI芯片创企中当属前排。
如今云端AI芯片赛道持续受到资本的青睐,更多的新兴初创公司选择涌入其中,赛道正变得愈发拥挤。与此同时,随着更多云端AI芯片产品开始走向落地,谁能脱颖而出,将交给市场来说话。
