








智东西(公众号:zhidxcom)
编译 | 贞逸
编辑 | 云鹏
智东西7月31日消息,据外媒报道,Open-Ended Learning Team(开放式学习小组)在Deepmid的Blog上发表了一篇关于训练一个无需与人类交互数据就能玩不同游戏的AI智能体(AI agents)的文章。
一般来说,需要先给智能体提供一部分新游戏的数据,再让它自我进行游戏训练,从而在该游戏中取得更好的成绩。但目前的智能体,如果不从头开始学习,它就无法完成新游戏或新任务。团队的目的是省略前面的步骤,创造出的智能体能直接在新游戏中自我探索,并在复杂的游戏环境中取得好成绩。
 ▲AI agents
▲AI agents
团队希望该文章能提供给其他研究人员另一条新思路,以创造更具适应性(more adaptive)、普遍能力(generally capable)更强的AI智能体。同时,他们邀请感兴趣的人士一同加入研究。
一、专门为训练AI造了个游戏场地
当AI智能体在训练游戏时,缺乏数据(每个游戏的数据都是单独的)是导致强化学习(reinforcement learning,RL)效果不佳的主要原因。这就意味着如果想让智能体可以完成所有任务,就需要让它把每一款游戏(任务)都训练了,否则它们在遇到新游戏的时候就只能“干瞪眼”。
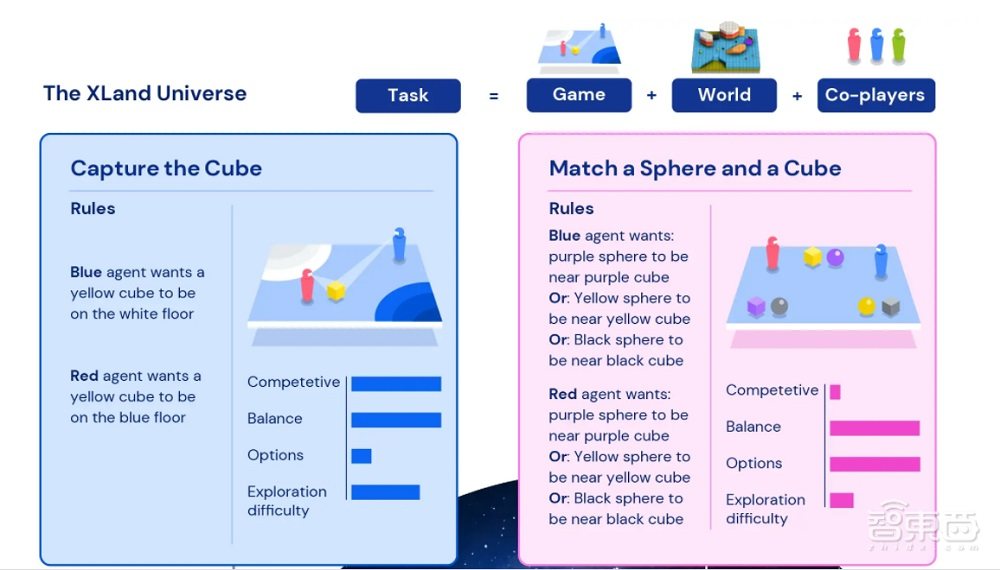
团队创建了一个3D游戏环境,称之为“XLand”,该环境能够容纳多位玩家共同游戏。这种环境使得团队能够制定新的学习算法,而这种算法能动态地控制一个智能体进行游戏训练。
 ▲Xland
▲Xland
因为XLand可以通过编程指定(programmatically specified),所以该游戏空间能够以自动和算法(automated and algorithmic)的方式生成数据(该数据可以训练智能体)。同时,XLand中的任务涉及多个玩家,其他玩家的行为会加大AI智能体所面临的挑战。这些复杂的非线性交互(随机性)为训练提供了理想的数据源,因为有时训练环境中的微小变化可能会给智能体带来不一样的挑战。
二、任务难度要“刚刚好”
团队研究的核心是深度强化学习在神经网络中的作用(尤其是在智能体的训练中)。团队使用的神经网络结构(neural network architecture)提供了一种关注智能体内部循环状态(internal recurrent state)的机制,通过预测智能体所玩游戏的子目标(subgoals)来帮助引导智能体的注意力(预测游戏任务并引导智能体前往)。团队发现这个目标关注智能体(goal-attentive agent,GOAT)有学习了一般能力的政策的能力(GOAT方案使得智能体更具适应性)。
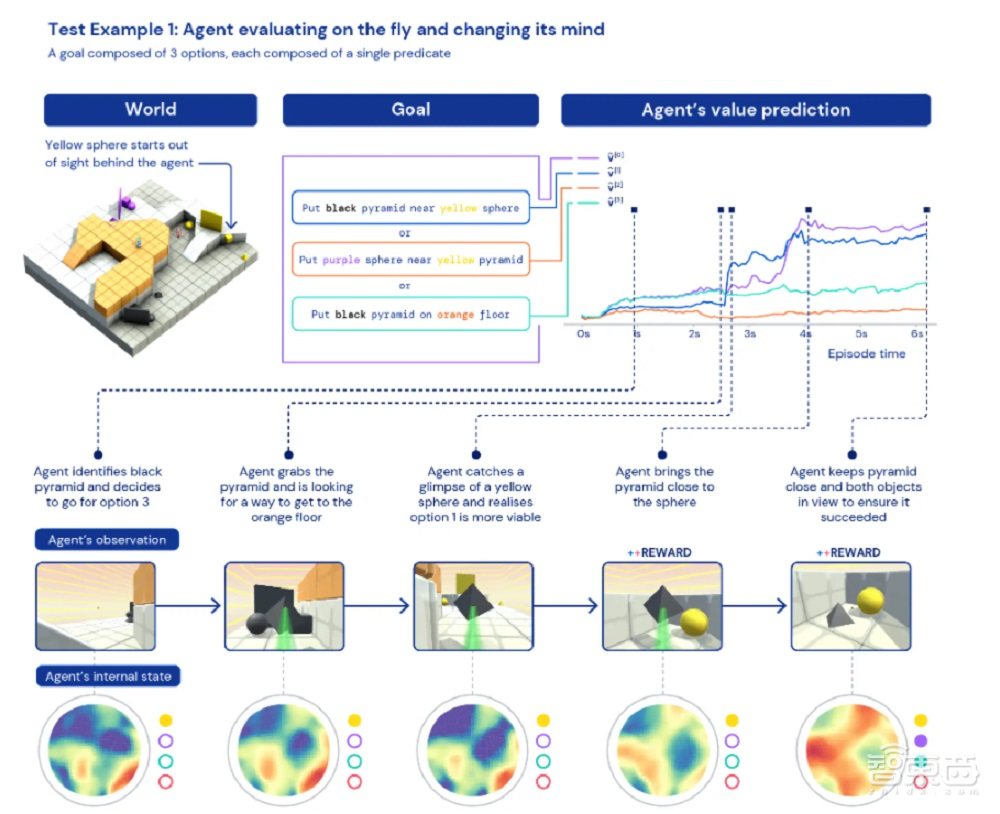 ▲预测智能体的子目标
▲预测智能体的子目标
团队还预测任务训练的难度会影响智能体的总体能力。因此,他们使用动态任务生成(dynamic task generation)对智能体的训练任务分配进行更改,并不断优化,生成的每个任务既不是太难也不是太容易,而是刚好适合训练。在这之后,他们使用基于群体的训练(population based training,PBT)来调整动态任务的生成参数,以提高智能体的总体能力。最后,团队将多个训练运行串联在一起,这样每一代智能体都可以从上一代智能体中启动(智能体迭代)。
三、智能体有启发式行为?
团队在对智能体进行了五代训练后,发现其学习能力和性能都在持续提升。在XLand的4,000个世界中玩过大约700,000个游戏后,最后一代的每个智能体都经历了2000亿次(200 billion)训练步骤,得到了340万(3.4 million)个任务的结果。
目前,团队的智能体已经能够顺利完成每次程序生成的测试任务,而且测试数据显示,智能体的能力(相比于上一代)有了整体的提高。
除此之外,团队还发现智能体表现出一般的启发式行为(heuristic behaviours),如实验(experimentation),该行为出现在于许多任务中,而不是专门针对单个任务的行为。团队有观察到智能体在游戏中使用不同的工具,包括利用障碍物来遮挡自己、利用物品创建坡道。随着训练的进展,智能体还偶尔会出现与其他玩家合作的行为,但目前团队还不能确认这是否是有意识的行为。
结语:“自学”让AI更智能
Open-Ended Learning Team正在训练一个新的智能体,它不需要从头开始训练数据,就能适应新的游戏。这个智能体将比仅使用强化学习方法的智能体更加“智能”。
大量的数据训练一直以来是人工智能发展绕不开的难题,此次如果能大量减少训练数据,并使其获得跨领域的自主学习能力,那么人工智能的能力将能得到进一步的提升。
来源:deepmind
