








智东西(公众号:zhidxcom)
作者 | 心缘
编辑 | 漠影
从下面这张图,你能立即猜出用电脑工作的这个人是否有车、有没有结婚吗?

AI可以迅速锁定胳膊下压着的车钥匙和左手无名指上的戒指,由此推断出可能的答案:有车、已婚。
除了秒辨图片里有哪些内容外,AI已经开始挑战更高阶的“学霸”行为,即在看图和理解问题后,立即给出对应的关联信息。
这一高阶任务属于机器视觉问答(Visual Question Answering)领域。过去数年间,AI一直在挑战新的能力巅峰:2015年在视觉分类任务上超越人类成绩,2016年击败世界人类顶尖棋手,2018年文本阅读理解能力超人类基准……
如今,就在本周,AI终于在视觉问答VQA这一高阶任务上,取得了超越人类水平的最新突破。
在国际权威机器视觉问答榜单VQA Leaderboard上,阿里巴巴达摩院深度语言模型体系AliceMind以81.26%的准确率创造了新纪录,让AI在“读图会意”上首次超越人类基准线80.83%。第一位得分超越人类的AI选手诞生了。
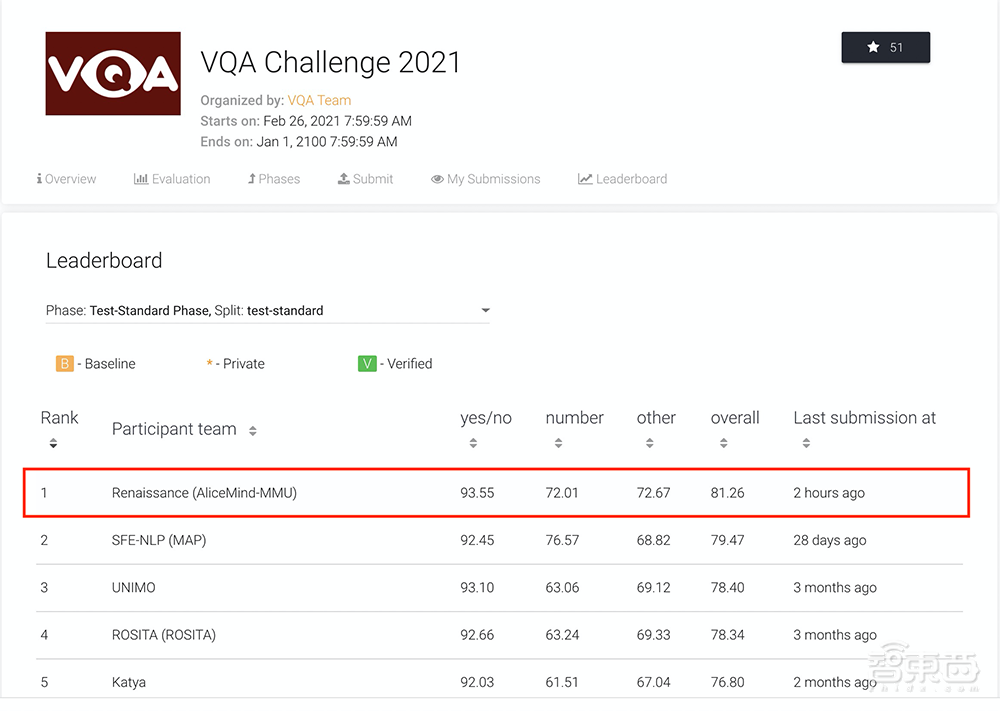 ▲达摩院AliceMind在VQA Leaderboard上创造首次超越人类的纪录
▲达摩院AliceMind在VQA Leaderboard上创造首次超越人类的纪录
一、VQA考卷有多难?堪称“变态”的侦探级推理
什么是视觉问答(VQA)?简单来说,给AI一张照片,AI不仅能用文字回答图片里有什么,还能通过推理回答出更多增量信息。
比如,下面这张图中,你能看见暖黄的灯光下,一个戴着眼镜的男子正枕在白色枕头上张嘴酣睡,他的左手侧,一只漂亮的猫咪正凝视着你。

那么问题来了,这只猫是什么品种?
AI能做到秒答:暹罗猫。
看图问答只是基本操作,AI的视觉问答能力范畴还包括:看见车胎就能回答其汽车品牌,看见一只熊就知道它的品种,看见士兵玩具和战斗场景就知道它出自星球大战电影……

VQA,这个将计算机视觉与自然语言技术交融的多模态领域前沿研究方向,对研发通用人工智能有重要意义。
但要让AI具备像侦探一样细致的观察能力、像百科全书一样全面的知识储备,可不是容易的事。
为了攻克这一难题,全球计算机视觉顶会CVPR从2015年起连续6年举办VQA挑战赛,形成了国际上规模最大、认可度最高的VQA数据集,其包含超20万张真实照片、110万道考题。
在测试中,AI需根据给定图片及自然语言问题,生成正确的自然语言回答。

说起来简单,但要取得漂亮的成绩,AI不仅要修炼好图像识别、文本识别、文本理解等基本功,还要解锁计数、读钟表、推理认知等附加技能。
基于此,AI首先获知所有图像信息,再结合对文本问题的理解,学习图文的关联性、精准定位相关图像信息,最后根据常识及推理回答问题。
当然,拥有百科全书的丰富常识,是能做到秒答问题的前情提要。
VQA考题有多难呢?举个例子,下图中的这些玩具是用来做什么的?

人类尚需通过观察和思考才能给出答案,而AI在检索图片后,根据小熊玩具上的礼服装饰,推断出一个可能的答案:婚礼。
微软、Facebook、斯坦福大学、阿里巴巴、百度等众多全球顶尖机构均在参与VQA挑战赛。
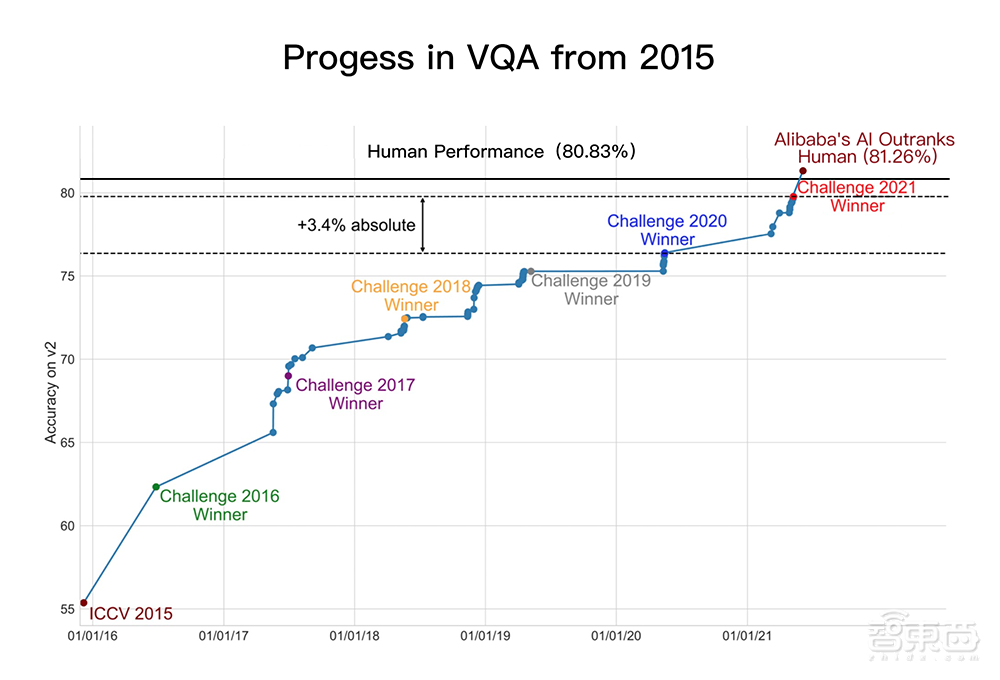 ▲自2015年以来VQA技术的进展
▲自2015年以来VQA技术的进展
今年6月,阿里达摩院在VQA 2021 Challenge的55支提交队伍中夺冠,成绩领先第二名约1个百分点、去年冠军3.4个百分点。
两个月后,就在本周,达摩院再次以81.26%的准确率创造VQA Leaderboard全球纪录,首次超越人类基准线80.83%。
这意味着,在封闭数据集内,AI的VQA表现已经媲美人类水准,向认知智能迈进关键一步。
在更开放的现实世界,AI虽然面临着更多挑战,但已经有相当方便的应用,正改变人们的生活。
二、从生活Tip到电商问答,VQA已开始落地商用
VQA技术能做什么?从图文阅读、跨模态搜索、盲人视觉问答、医疗问诊到智能驾驶、虚拟主播等应有尽有,正在改变着人机交互方式。
比如,给AI一张自助餐现场照,它能知道这是什么场所;让AI看一个披萨图,它能秒知披萨上撒了什么蔬菜;问照片中的棒球队来自哪座城市,它能马上回答:纽约。
 ▲AI能从图中推断出棒球队来自纽约
▲AI能从图中推断出棒球队来自纽约
再比如这张图,如果你问左边女生穿什么颜色的T恤、图中展示什么酒、人们在参加什么活动?AI会准确地回复:黑色、红酒、品酒。

而且,AI还能避开一些“挖坑”问题,假如你问上图中为什么人们戴着帽子?AI会老实回答:他们没戴。
除了作为生活答题小能手外,AI已经实现了大范围的商业应用落地。
以阿里平台为例,目前,VQA技术已在阿里内部应用于商品图文理解、智能客服等场景。
截至今日,数万家淘宝天猫商家已开通店小蜜客服VQA视觉问答功能,当消费者对商品进行提问时,AI客服可通过理解、检索信息丰富的商品详情海报进行回答,包括裁切一张小图作为答案。

这一方面为消费者带来了更好的交互体验,另一方面为卖家节省了大量配置成本,帮店家提升了提问解决率。盒马、考拉的客服场景,闲鱼的图文同款匹配场景也接入了VQA能力。
VQA还能回答非事实类、有主观色彩的问题:

此外,VQA技术也被应用于智能直播间等多模态人机交互场景中,帮助解决直播中多模态剧本构建、多模态语义问答等问题。
基于创新性的多模态预训练方法,达摩院还为AliExpress训练了电商多模态通用模型,应用于搜索query相关性排序等需要图文理解的场景,有效提升了搜索相关性。
据悉,VQA技术在电商领域成熟运用后,阿里计划将其推广至医疗问诊等更广泛的应用领域。
三、VQA分数首超人类,达摩院是怎么做到的?
VQA挑战的核心难点在于,需在单模态精准理解的基础上,整合多模态的信息进行联合推理认知,最终实现跨模态理解,即在统一模型里做不同模态的语义映射和对齐。
据悉,为了解决VQA挑战,基于阿里云PAI平台及EFLOPS框架的工程底座,达摩院语言技术实验室及视觉实验室对AI视觉-文本推理体系进行了系统性的设计,融合了大量算法创新,包括:
(1)多样性的视觉特征表示:从各方面刻画图片的局部和全局语义信息,同时使用Region,Grid,Patch等视觉特征表示,以更精准地进行单模态理解;
(2)多模态预训练模型:基于海量图文数据和多粒度视觉特征的多模态预训练,用于更好地进行多模态信息融合和语义映射,创新性地提出了SemVLP,Grid-VLP,E2E-VLP和Fusion-VLP等预训练模型;
(3)自适应的跨模态语义融合和对齐技术:创新性地在多模态预训练模型中加入Learning to Attend机制来进行跨模态信息地高效深度融合;
(4)知识驱动的多技能AI集成:采用Mixture of Experts (MOE)技术进行知识驱动的多技能AI集成。
这些技术正让AI“读图会意”水平上了一个新台阶。
其中自研的多模态预训练模型E2E-VLP,StructuralLM已被国际顶级会议ACL2021接受。
论文链接:
1、 E2E-VLP: End-to-End Vision-Language Pre-training Enhanced by Visual Learning, ACL2021
2、 A Structural Pre-trained Model for Table and Form Understanding, ACL 2021
3、 SemVLP: Vision-Language Pre-training by Aligning Semantics at Multiple Levels
模型大图如下:

结语:今年达摩院连秀AI底层技术实力
2018年,作为业界最早投入预训练语言模型研究的机构之一,达摩院前身IDST曾在斯坦福SQuAD挑战赛中让机器阅读理解首次超越人类。
3年后的今天,达摩院VQA技术在视觉-文本跨模态理解及推理上媲美人类的水平。
而这只是达摩院展示的AI底层技术实力之一,自今年3月起,达摩院先后发布了首个超大规模多模态预训练模型M6及首个超大规模中文语言模型PLUG,并开源了历时3年打造、曾登顶GLUE等六大国际权威NLP榜单的深度语言模型体系AliceMind。
随着VQA技术的能力不断打磨和提升,我们期待看到这一技术在现实世界中发挥更大的价值。
