








芯东西(公众号:aichip001)
作者 | 心缘
编辑 | 漠影
芯东西9月15日报道,今日,在百度科技沙龙“AI呀,我去”第二期活动上,拥有多年从业经验的百度昆仑芯商业分析师宋春晓围绕芯片生产制造和应用环节进行分享,并透露了刚从百度独立出的AI芯片公司昆仑芯科技的产品路线规划。
昆仑芯科技前身是百度智能芯片及架构部,于2021年3月完成了独立融资,6月顺利完成分拆,成立了昆仑芯(北京)科技有限公司,目前估值约130亿元。在刚刚闭幕的”服贸会”上,昆仑芯与北京市海淀区政府签订合作协议,将为区域发展注入”芯动能”。
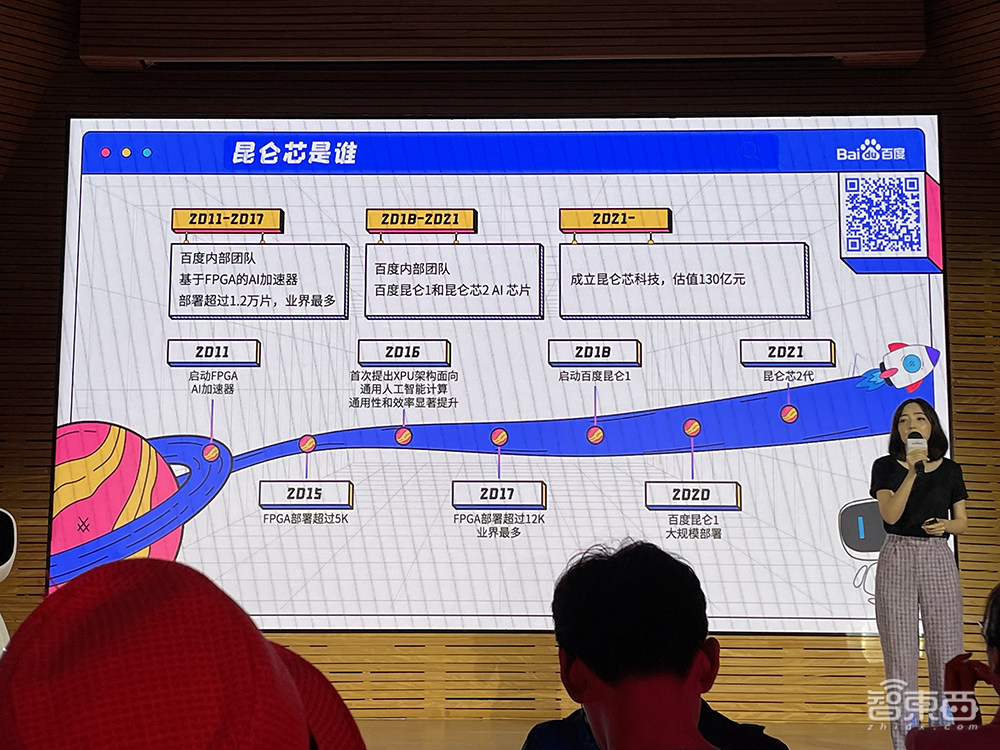
宋春晓完整回顾了昆仑芯科技发展历程、历代AI芯片产品和昆仑芯的使命与愿景,并提及接下来昆仑芯的产品路线图。
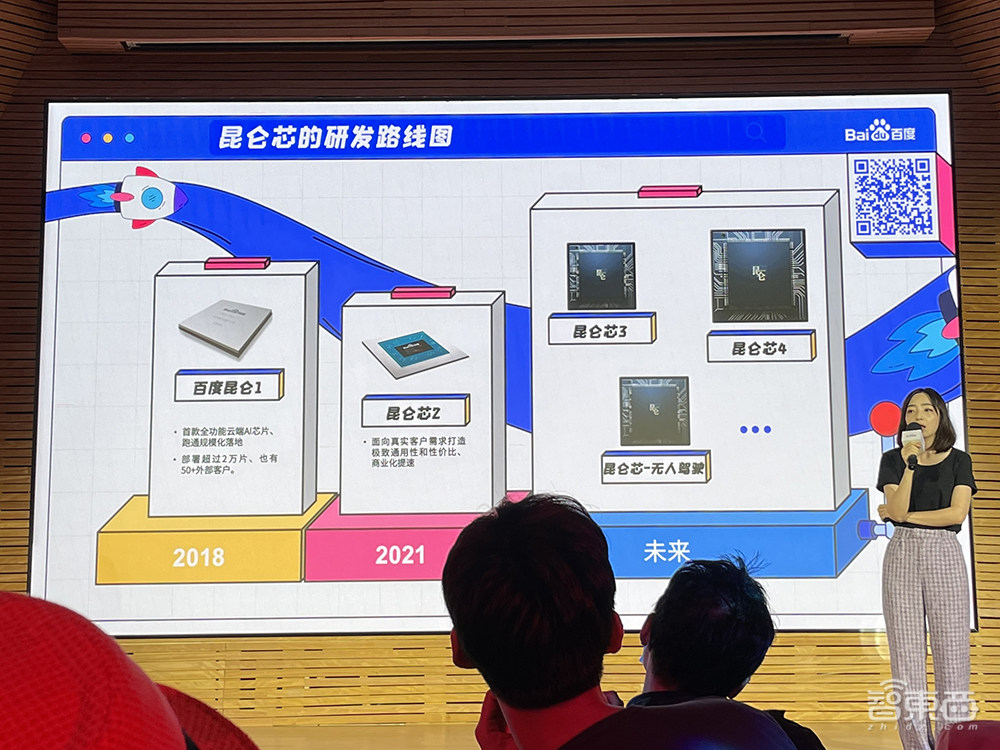
继2018年推出云端AI芯片百度昆仑1、2021年推出昆仑芯2后,昆仑芯科技计划在未来推出昆仑芯3、用于无人驾驶的昆仑芯和昆仑芯4。
一、AI芯片竞争的终极指标
在活动期间,宋春晓分享道,芯片纳米越小不一定越好,过分关注单芯片的算力、只用算力指标去评判芯片“厉不厉害”,是片面的。通用性、易用性及性价比,才是AI芯片之间竞争的终极指标。
纳米(nm)是芯片制程工艺的一种命名方式,数值越小未必代表越先进。纳米的命名更像是工艺代际、甚至是商业和市场角度的命名,是个定性的对晶体管集成度的表述。
各种新的技术的出现,比如晶体管的形状、排列方式发生了改变,摩尔定律放缓了,命名也就没有了同一标准。
为什么造芯这么难?宋春晓为大家介绍了芯片的整体研发和生产流程。一款芯片的前端和后端设计要耗时1~3年,设计完成后的流片环节,需要3~6个月,还会有流片失败一切重来的风险。流片失败3-5次是非常正常的现象。如果流片成功,仍然还需要经过3~12个月的测试调优,才能实现最终的量产。
所以,一款芯片的真正量产,一般要经历2~5年。而百度昆仑芯两代产品均在一年半左右完成设计,都是一次流片成功,这在一定程度上体现了百度昆仑芯的研发实力和务实态度。
二、深耕造芯10余年,有完整国产化解决方案
对于昆仑芯的下一步发展,宋春晓用实现更快(至少要延续摩尔定律)、更强(用计算赋能更多可能)、更省(让更多产业享受计算的红利)来概括,她提到未来是计算机体系结构的黄金时代,昆仑芯科技将从架构、芯片实现、软件和应用各个层次创新来践行“用科技让复杂的世界变简单”的使命。
据宋春晓分享,昆仑芯公司的愿景是成为划时代、全球领先的智能计算公司。
百度从2011年起布局AI加速领域,截至目前,昆仑芯团队深耕FPGA到ASIC芯片已10余年,在体系结构、芯片实现、软件系统和场景应用均有深厚积累。
2016年,昆仑芯团队首次提出100%自研核心架构XPU,面向通用AI计算,通用性和效率显著提升。
昆仑芯片产品是团队十年磨一剑的成果。芯片研发的复杂程度注定了这是一场时间与耐力的比拼,百度昆仑芯起步早、进展快,现已成为AI芯片行业的领军玩家。
昆仑芯片可用做推理和常规训练,支持通用AI算法,在计算机视觉、语音识别、自然语言处理和推荐的算法上的性能指标高效且稳定。
作为百度AI平台的核心组件,百度昆仑芯AI芯片原生支持国内生态最领先的开源深度学习框架飞桨、百度机器学习平台(BML)及各垂类的AI能力引擎。
值得一提的是,昆仑芯不仅支持全球主流CPU、操作系统、PyTorch和TensorFlow等深度学习框架,还有完整的国产化解决方案,和多款国产通用处理器(包括飞腾、申威、海光等)、国产操作系统(麒麟、统信、深度)、国产深度学习框架(飞桨)完成端到端的系统适配。
三、昆仑芯1代量产超2万片,2代性能提升2-3倍
截至目前,昆仑芯1代至今已量产超过2万片,在百度搜索引擎、小度和广告业务中部署超过2万片,服务有50多家外部客户,是国内唯一一款支撑了互联网大规模核心推荐算法的AI芯片。
昆仑1代AI计算处理器(Baidu KUNLUN AI Computing Processor)为云端和边缘端的AI业务而设计,于2018年正式推出,其基于百度自主研发先进XPU架构,旨在通过软硬件的协同创新,量级的提高计算效能,为各产业智能领域提供易用、高效、安全、稳定的智能计算产品。
昆仑1代处理器采用14nm工艺、16GB HBM先进内存和2.5D封装解决方案,提供高达512GB/s的内存带宽,在低于150W功率下可实现256TOPS的INT8处理能力。自推出以来,昆仑芯1代已被部署和应用于诸多AI应用场景。
2021年8月18日,百度创始人、董事长兼CEO李彦宏在百度世界大会上宣布第2代自研AI芯片——昆仑芯2正式发布。
昆仑芯2的性能、通用性、易用性较1代产品均有显著增强。该芯片搭载自研的第二代XPU架构,相比1代性能提升2-3倍。整数精度(INT8)算力达到256TOPS,半精度(FP16)为128TFLOPS,最大功耗为120W。
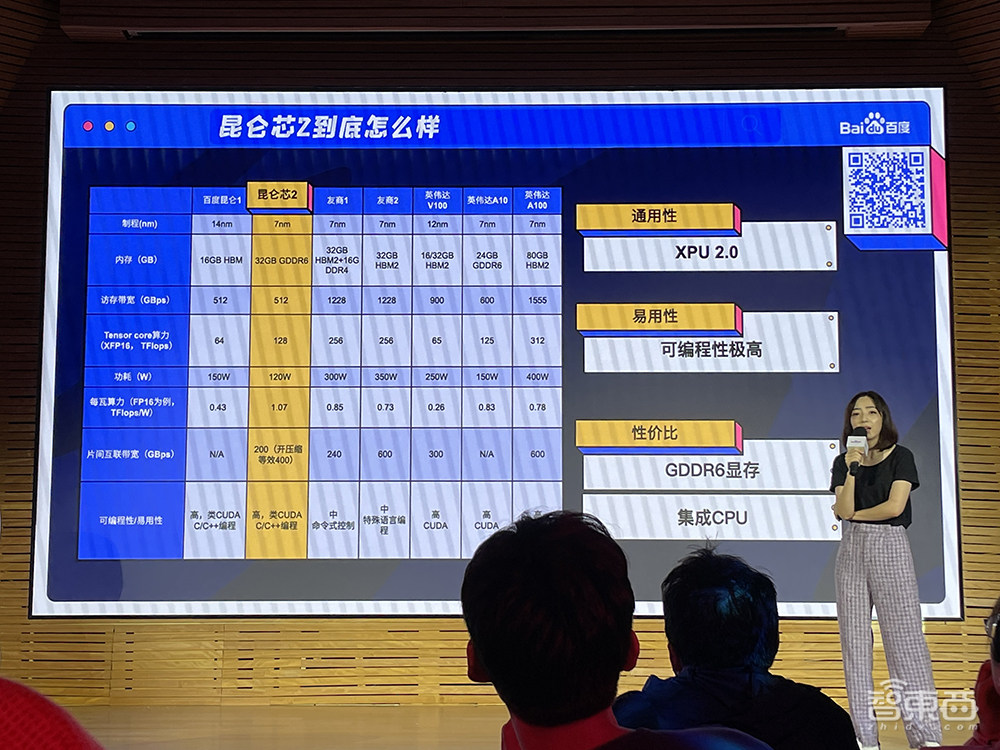
硬件设计上,该芯片是国内首款采用GDDR6显存的通用AI芯片。此外,昆仑芯2还高度集成了Arm CPU算力,并支持高速互联、安全和虚拟化。
软件架构上,昆仑芯2大幅迭代了编译引擎和开发套件,支持C和C++编程,可编程性国内领先、对标全球业界最先进水平。
场景方面,昆仑芯2领先的设计使产品可以适用云、端、边等多场景,可应用于互联网核心算法、智慧城市、智慧工业等领域,并还将赋能高性能计算机集群、生物计算、智能交通、无人驾驶等更广泛空间。
四、已在百度内部大规模应用
宋春晓分享说,人均算力值是促进社会经济进步的重要指标。百度判断算力是未来社会发展的生产力,芯片是算力的来源。就像电力奠定工业社会发展的基石一样,算力将成为智能社会的基石。
百度也正利用其自身AI能力帮助传统产业提升经济效率,以及赋能新产业来创造新的经济价值。而性能更强的昆仑芯将起到有力支撑。
据悉,昆仑芯片已在百度内部得到大规模应用,通过引入无损低精度推理的方案,软硬件的优化设计,既发挥了定点计算的效率优势,又避免了精度损失。昆仑芯片在引入过程中改良了编程模型、动态优化缓存分配、数据流重构等一系列创新技术,充分挖掘算力和架构的优势。
在引入昆仑芯片后,百度搜索业务效果在各个指标上都得到了大幅提升,性能相比原有GPU FP32和FP16有2倍以上的提升,替代万片以上GPU和相关服务器等,TCO节省上亿降低固定资本投入。这也使业务能有更多的算力资源进行新算法开发&迭代。
在工业质检领域,百度昆仑同样得到广泛应用。传统工业质检基于图形学特征提取的方法,质检质量受制于鲁棒性差、光源和背景变化,而深度学习方法可以满足如今对产品零件复杂度高、规模大、产品代际更新快等特点的需求。
在部署了百度昆仑的智能工厂,机器自动对物体表面的缺陷进行大小、位置、形状的检测,任何微小的瑕疵都能够被直接标记。算法机同时处理24个模型,处理完所有流程仅需480毫秒;通过深度学习算法对于各种缺陷进行学习后,能准确识别产品的全部33类缺陷,漏检率控制在0.1%以内,并能使全检出货达到AQL 0.4标准。
该设备相对于标传统视觉检测的同类机型,投资回报率是传统机型的6.5倍。
结语:独立融资后,昆仑芯迈向下一征程
除了拥有自研XPU架构及多项自主设计,昆仑芯AI芯片也同飞腾等多款国产通用处理器、麒麟等多款国产操作系统以及百度自研的飞桨深度学习框架完成了端到端的适配,拥有软硬一体的全栈国产AI能力。
在独立融资后,昆仑芯科技不仅有望获得更多外部资金用于研发投入,也能将此前更多在百度内部应用所积累的技术及落地经验向更广泛的用户输出。
